
|
|
Alyona Bazhanova
Faculty: Computer Sciences and Technologies (CST) |
- Theme urgency
- Purposes of the work
- Prospective scientific novelty
- Planned practical results
- Research of used ontology models for semantic search
- The conclusion
- The list of the used literature
Modern means of search, cataloguing and description of texts don't satisfy to accruing requirements of users. Their need a direction to increase of efficiency for information search and simplification for interaction with the user was required.
Possible way for decide a problem is creation technical - information means of the description of sense of available texts with possibility of the further intelligent search in a file with the text information. And the big and constantly increasing volumes of the text information demand, that such means worked in an automatic mode.
The sense traditionally is the subjective characteristic of the text. It is difficult to reveal any mathematical methods of the description semantic value of the text and its separate concepts. Therefore allocation of semantic characteristics from the real text in a natural language is a challenge. Nevertheless researches in this direction are actively conducted. Over the decision named to problems numerous collectives of scientists and experts all over the world, in particular, consortium W3C where the concept Semantic Web is realized work. The set of intellectual search engines such as RetrievalWare, Nigma, Exactus, Sirius is created, etc.
Despite an abundance of search intellectual systems they has many problems connected with information search, which remain not solved
The purposeЦелью of the given work is increase efficiency of search in not structured text information on demand of the user in a natural language.
For achieve this puprpose it is necessary to solve following problems:
- To carry out the analysis of application of ontology models for semantic information search and methods of semantic text processing.
- To develop ontology model for information search in the field of the computer literature.
- To develop algorithm for the automated expansion of ontology by semantic value of the texts stored in library.
- To create the computerized system with possibility of the automated expansion of ontology and with ability change automatically added statements.
- The ontology model for search of not structured text information in the computer literature which will allow to receive the high-grade knowledge base.
- The computerized subsystem with possibility of the automated expansion of ontology and updating automatically added statements has been developed.
The algorithm is developed for the automated expansion of ontology by semantic value of the texts, allowing to obtain given relevant to inquiry of the user.
Results of work will be used in electronic scientific library by the department Automated Control Systems.
The problem of semantic search in electronic library is the simplified analog of information search in the Internet since it is supposed that search will be carried out on demand of the user in a natural language in a similar line of search.
On fig. 1 the scheme of semantic information search is shown. The user enters inquiry which is exposed to the linguistic analysis, extends at the expense of use of synonyms, then is transformed to keywords and goes to the search car. The search car returns the found documents, they also are exposed to linguistic analysis and semantic value of documents are formed. Images of documents are compared to image of inquiry, the conclusion about relevance of each of documents becomes and results of the analysis (documents which have been recognized by relevant) are given to the user.
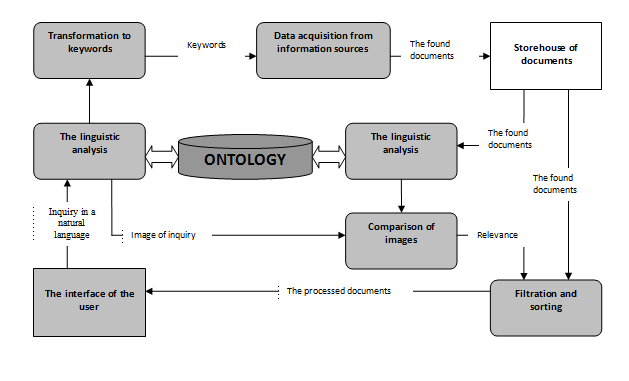
Fig. 1 – the Diagram of data flows by search.
Apparently from figure the central place at such model of information search is occupied with ontology. However, process of creation of ontology is difficult. Information ontology consists of copies, concepts, attributes and relations between them. For creation ontology it is necessary to create the dictionary of terms - glossary, union terms the general communications and then to impose restrictions on these communications that is shown in figure 2.

Fig. 2 – the process for create ontology (animation: volume – 47 КБ, size – 534x321, amount of shots – 100, amount of repeated cycles – 7)
For construction of ontology, it is necessary to develop languages of their representation. Such specialized languages as Resource Description Framework (RDF) can be thus used, Web Ontology Language (OWL) and etc. Ontology can use various models of representation of knowledge, such as logic of predicates (First order logics - FOL), the descriptive logic, frame models (Frames), conceptual columns, etc. For creation of ontology can be used various editors (Protégé, Ontolingua, WebOnto, etc.) which in turn can support various formats the data presentations (languages) based on various formalisms (logicians, data presentation models). The key moment in ontology designing is the choice of corresponding language of the specification of ontology (Ontology specification language) and the editor for work with it.
Ontology models during researches in this area have undergone considerable development. Now for creation and support ontology is variety of tools which editing besides the general functions and viewing carry out support of documenting ontology, import and export ontology in different formats and languages, support graphic editing, management of libraries ontology and etc. [4].
The most well known tools of engineering of ontology, their basic characteristics are presented in table 1 [3].
Table 1 – Tools of engineering of ontology
| Name of parameter | OilEd | OntoEdit | Ontolingua | OntoSaurus | Protégé | WebODE | WebOnto |
| Architecture of aplication | 3 level | 3 level | Client/server | Client/server | 3 level | n level | Client/server |
| Storage of ontologies | file | file | file | file | file, DBMS | DBMS | file |
| Language | Java | Java | Lisp | Lisp | Java | Java | Java + Lisp |
| Main language of representation knowledge | DAML+OIL | OXML | Ontolingua | LOOM | OKBC | - | OCML |
| The interface of the user | Local aplication | Local aplication | HTML | HTML | Local aplication | HTML and Applets | Applets |
As already it was told above, tools of engineering ontology use specialized languages. Today allocate three basic classes of languages to the description ontology that is shown on fig. 3:
- Traditional languages of the specification of ontology: Ontolingua, CycL and the languages based on description logical (such as LOOM), also the languages based on frames (OKBC, OCML, Flogic);
- Later languages based on Web - standards (XOL, SHOE, UPML);
- Special languages for an exchange of ontology through Web: RDF (S), DAML, OIL, OWL [2].
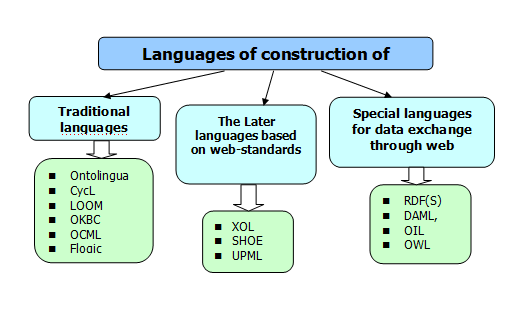
Fig. 3 – Classification of formats of data presentation
For today editors of ontology, except the language, support import and export of the given various formats proceeding from the analysis of their application, follows that a most often used format of data presentation is RDF (S). Language RDF has some advantages: submits data in the form of rdf-triplets (subject-object-predicate), and the rdf-scheme is represented in the useful form [1].
Proceeding from the analysis key parameters of various editors of the ontology, the most comprehensible is editor Protégé, it will be taken for a basis in the further work. Among the data presentation formats, in the lead positions has occupied RDF (S) which will be used for construction of ontology of subject domain of electronic library in department Automated Control Systems [1].
The requirement for ontology is connected with impossibility of adequate automatic processing of natural language texts existing means. Therefore, for qualitative processing of texts and search of the relevant information, it is necessary to have the detailed description of problem area, with set of logic communications which show parities between area terms. Use of ontology allows to present naturally-language text in such kind that it becomes suitable for automatic processing.
In work the analysis of existing means and methods of construction of ontology has been carried out. During the analysis it has been established that there is a set of tool means, for construction of the ontology, however not one of them doesn't allow to automate this process. For construction of ontology there are various specialized languages which in turn use various models of representation of knowledge and are based on various logicians. As a result of the spent analysis problems for the further work have been formulated, methods and algorithms for their realization are chosen, mathematical statement of a problem of construction of ontology has been formulated.
- Исследование применения онтологических моделей для семантического поиска.
- ОНТОЛОГИИ И ТЕЗАУРУСЫ: [Учебное пособие] / Соловьев В.Д., Добров Б.В., Иванов В.В., Лукашевич Н.В. – Москва: 2006. – 157c.
- Обзор инструментов инженерии онтологий/ О.М. Овдей, Г.Ю. Проскудина // Журнал ЭБ. – 2004 – №4
- Никоненко А.А. Обзор баз знаний онтологического типа// Искусственный интеллект.–2002.–№ 4. – C. 157–163.
- Семантический веб и микроформаты [Електронний ресурс] : Интуит. Лекция — Режим доступу http://www.intuit.ru/department/internet/mwebtech/20/
- Алексей Николаевич Бевзов. Разработка методов автоматического индексирования текстов на естественном языке для информационно-поисковых систем. – М.: ИСО РАН – c. 401- 404
- ИНТЕРАКТИВНЫЕ МЕТОДЫ ФОКУСИРОВКИ И РАСШИРЕНИЯ ПОИСКА В ИНТЕЛЛЕКТУАЛЬНОЙ ПОИСКОВОЙ МАШИНЕ/В. Н. Поляков, Д. А. Бодров, А. В. Точин – М.: Московский Государственный институт стали и сплавов
- Королёв А.Н. Лингвистическое обеспечение информационно-поисковой системы Excalibur RetrievalWare: Аналитический аспект
- Семантический анализ текста на основе лексикосинтаксических шаблонов для информационного поиска. Рабчевский Евгений, Крупов Сергей, Рожков Михаил, Булатова Гульнара – Пермь: Государственный Университет
- Андреев А.М., Березкин Д.В., Брик А.В. Лингвистический процессор для информационно-поисковой системы – М: МГУ
- Анисимов А.В., Марченко А.А. Система обработки текстов на естественном языке.// Искусственный интеллект.–2002.–№ 4. – C. 157–163.
- Марченко О.О. Моделювання семантичного контексту при аналізі текстів на природній мові. Вісник Київського університету. Сер. фіз.-мат. Науки.– 2006. – № 3. – C. 230–235.

DonNTU - Master’s Portal