
|
|
Бажанова Альона Ігорівна
Факультет: Компьютерних наук та технологій (ФКНТ) |
- Актуальність теми
- Цілі роботи
- Планована наукова новизна
- Заплановані практичні результати
- Дослідження застосування онтологічних моделей для семантичного пошуку
- Аналіз методів семантичної обробки тексту
- Висновок
- Список використаної літератури
Сучасні засоби пошуку, каталогізації, опису текстів не задовольняють наростаючим потребам користувачів. Потрібен їх розвиток у напрямку підвищення ефективності пошуку інформації і спрощення взаємодії з користувачем.
Можливим шляхом вирішення проблеми є створення техніко-информаційних засобів опису сенсу наявних текстів з можливістю подальшого осмисленого пошуку в масиві текстової інформації. Причому великі і постійно зростаючі об'єми текстової інформації вимагають, щоб такі засоби працювали в автоматичному режимі.
Сенс традиційно є суб'єктивною характеристикою тексту. Важко виявити які-небудь математичні методи опису значення текста і окремих його понять. Тому виділення смислових характеристик з реального тексту на природній мові є складним завданням. Проте дослідження в цьому напрямі активно ведуться. Над рішенням названих проблем працюють численні колективи вчених і фахівців у всьому світі, зокрема, консорціум W3C, де реалізується концепція Семантичного Web. Створюється безліч інтелектуальних пошукових систем таких як RetrievalWare, Nigma, Exactus, Sirius та ін.
Не дивлячись на велику кількість пошукових інтелектуальних систем багато проблем, пов'язаних з пошуком інформації, залишаються не вирішеними.
Метою цієї роботи є підвищення ефективності пошуку неструктурованої текстової інформації за запитом користувача на природній мові.
Для досягнення поставленої мети необхідно вирішити наступні завдання:
- Провести аналіз застосування онтологічних моделей для семантичного пошуку інформації і методів семантичної обробки тексту.
- Розробити онтологічну модель для пошуку інформації в області комп'ютерної літератури.
- Розробити алгоритм для автоматизованого розширення онтологій семантичними образами текстів, що зберігаються у бібліотеці.
- Створити комп'ютеризовану систему з можливістю автоматизованого розширення онтологій і коригування тверджень, що автоматично додаються.
- Запропонована онтологічна модель для пошуку неструктурованої текстової інформації в комп'ютерній літературі, яка дозволить отримати повноцінну базу знань в запропонованій предметній області.
- Розроблена комп'ютеризована підсистема з можливістю автоматизованого розширення онтологий і коригування тверджень, що автоматично додаються.
Розроблен алгоритм для автоматизованого розширення онтологий семантичними образами текстів, що дозволяє отримувати дані релевантні запиту користувача.
Результати роботи будуть використані в електронній науковій бібліотеці кафедри АСУ.
Завдання семантичного пошуку в електронній бібліотеці є спрощеним аналогом пошуку інформації в Інтернет, у зв'язку з тим що передбачається, що пошук буде здійснюватися за запитом користувача на природній мові в аналогічному рядку пошуку.
На рис. 1 показана схема семантичного пошуку інформації. Користувач вводить запит, який підлягає лінгвістичному аналізу, розширюється за рахунок використання синонімів, потім перетворюється в ключові слова і вирушає пошуковій машині. Пошукова машина повертає знайдені документи, вони також підлягають лінгвістичній обробці і формуються семантичні образи документів. Образи документів порівнюються з образом запиту, робиться висновок що до релевантності кожного з документів і результати аналізу (документи, які були визнані релевантними) надаються користувачеві [12].
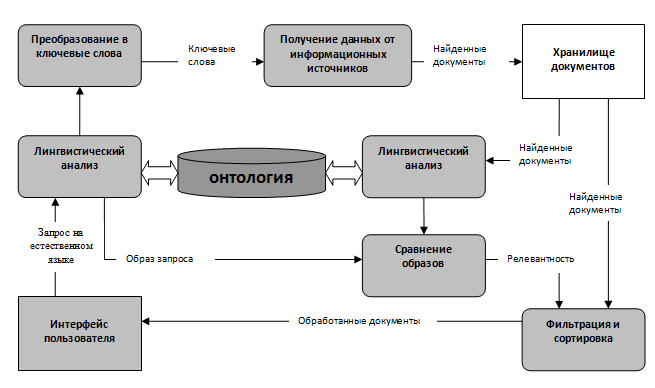
Рис. 1 - Діаграма потоків даних при пошуку
Як бачимо з рисунка, центральне місце у такій моделі пошуку інформації займають онтології. Однак, процес створення онтологій складний прцес. Інформаційні онтології складаються з екземплярів, понять, атрибутів і відношень між ними. Для створення онтології необхідно створити словарь термінів - глассарій, об`єднати терміни спільними зв`язками та потім накласти обмеження на ці зв`язки, що проілюстровано на рисунку 2.

Рис. 2 – Процес створення онтології (анімація: об'єм – 47 КБ, розмір – 534x321, кількість кадрів – 4, затримка між кадрами – 50 мс; затримка між останнім і першим кадрами – 100 мс; кількість циклів повторення – 7)
Для побудови онтологий, необхідно розробити мови їх представлення. При цьому можуть бути використані такі спеціалізовані мови як Resource Description Framework (RDF), Web Ontology Language (OWL) і т. д. Онтології можуть використати різні моделі представлення знань, такі як логіка предикатів (First order logics - FOL), дескриптивна логіка, фреймові моделі (Frames), концептуальні графи і тому подібне. Для створення онтологій можуть використовуватися різні редактори (Protégé, Ontolingua, WebOnto та ін.), які у свою чергу можуть підтримувати різні формати представлення даних (мови), засновані на різних формалізмах (логіках, моделях представлення даних). Ключовим моментом в проектуванні онтології є вибір відповідної мови специфікації онтологій (Ontology specification language) і редактора для роботи з нею.
Онтологічні моделі за час досліджень в цій області зазнали значний розвиток. Нині для створення і підтримки онтологій існує цілий ряд інструментів, які окрім загальних функцій редагування і перегляду виконують підтримку документування онтологій, імпорт і експорт онтологій різних форматів і мов, підтримку графічного редагування, управління бібліотеками онтологий і т. д. [4].
Найбільш відомі інструменти інженерії онтологій, їх основні характеристики представлені в таблиці 1 [3].
Таблиця 1 - Інструменти інженерії онтологий
| Назва параметра | OilEd | OntoEdit | Ontolingua | OntoSaurus | Protégé | WebODE | WebOnto |
| Архітектура програми | 3–х рівнева | 3–х рівнева | Клієнт/сервер | Клієнт/сервер | 3–х рівнева | n-рівнева | Клієнт/сервер |
| Зберігання онтологїй | файли | файли | файли | файли | файли, CУБД | CУБД | файлы |
| Мова ПЗ | Java | Java | Lisp | Lisp | Java | Java | Java + Lisp |
| Осн. мова представлення знань | DAML+OIL | OXML | Ontolingua | LOOM | OKBC | - | OCML |
| Інтерфейс користувача | Лок-не приложение | Лок-не приложение | HTML | HTML | Лок-не приложение | HTML та апплети | Апплети |
Як вже було сказано вище, інструменти інженерії онтологий використовують спеціалізовані мови. Сьогодні виділяють три основні класи мов опису онтології, що показано на рис. 3:
- Традиційні мови специфікації онтології : Ontolingua, CycL і мови, засновані на дескрипционной логіці (такі як LOOM), також мови, засновані на фреймах (OKBC, OCML, Flogic);
- Пізніші мови, засновані на Web -стандартах (XOL, SHOE, UPML);
- Спеціальні мови для обміну онтологією через Web: RDF(S), DAML, OIL, OWL [2].
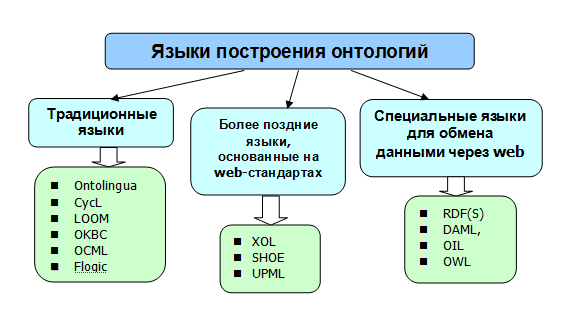
Рис. 3 - Класифікація форматів представлення даних
На сьогодні редактори онтологий, окрім своєї мови, підтримують імпорт і експорт різних форматів данних, виходячи з аналізу їх застосування, витікає, що найчастіше використовуваним форматом представлення даних є RDF(S). Мова RDF має ряд переваг: представляє дані у вигляді rdf -триплетів (суть-об'єкт-предикат), а rdf -схема представляється у вигляді орієнтованого графа, що є зручною для сприйняття формою представлення даних [1].
Виходячи з аналізу основних параметрів різних редакторів онтологій, найбільш прийнятним є редактор Protégé, саме він буде взятий за основу в подальшій роботі. Серед форматів представлення даних, перші позиції зайняв RDF(S), який буде використаний для побудови онтології предметної області електронної бібліотеки кафедри АСУ [1].
Семантична обробка тексту виконується в три етапи: морфологічний, синтаксичний і власне семантичний аналіз (рис. 4). Кожен етап виконує окремий аналізатор зі своїми вхідними і вихідними даними і власними налаштуваннями.
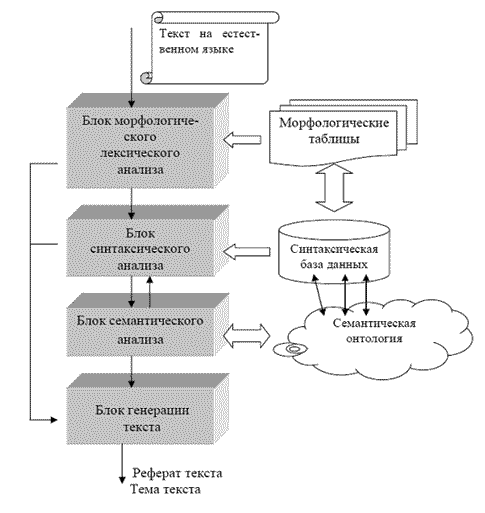
Рис. 4 - Схема лінгвістичного аналізу.
Зважаючи на складність виконання усіх етапів в роботі розглядатися буде тільки блок морфологічного аналізу. Серед методів морфологічного аналізу, що використовуються в лінгвістичних процесорах, можна виділити методи з декларативною і з процедурною орієнтацією.
Основним недоліком декларативних методів є надмірно великий об'єм словника. Достоїнствами методу є простота (і, як наслідок, висока швидкість) аналізу, а також універсальність по відношенню до безлічі усіх можливих словоформ російської мови.
Для процедурних методів час аналізу одного слова може бути істотно вищий, але об'єм використовуваних словників в невеликих системах дозволяє завантажувати словники цілком в оперативну пам'ять. Істотним недоліком процедурних методів є відсутність універсальності. Кожен з цих підходів має свої переваги і недоліки, тому в подальшій роботі використовуватиметься комбінація цих методів для поєднання переваг кожного з них.
У загальному вигляді схема морфологічної обробки тексту представлена на рисунку 5. Заздалегідь необхідно провести лексичний аналіз, тобто перевірити на допустимі символи. На вхід лексичного аналізу подаються речення з тексту по черзі, а на виході перевірений набір слів і розділових знаків.
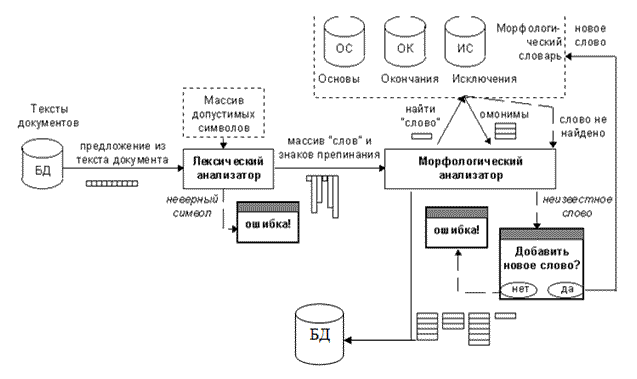
Рис. 5 - Морфологічний розбір тексту.
Опис алгоритму роботи морфологічного аналізатора:
1. На вхід надходить масив "слів", розділових знаків і чисел, виділених з вхідного тексту на етапі лексичного аналізу.
2. Для кожного "слова" аналізатор виконує процедуру пошуку в словнику основ, завантаженому в пам'ять. При цьому шукаються усі основи, з яких може розпочинатися аналізоване слово.
3. Якщо чергова основа задовольняє цій умові, то із словника афіксів витягається рядок, що містить усі можливі афікси для цієї основи.
4. Кожен афікс з цього рядка по черзі приєднується до основи, і результат порівнюється з аналізованим словом.
5. У разі їх точного збігу формується черговий запис в перелік результатів пошуку: за порядковим номером афікса в рядку афіксів визначаються змінні морфологічні параметри слова (наприклад, для іменника - число і відмінок), а за словниковою інформацією цієї основи - його постійні параметри.
6. Якщо в результаті такого пошуку не знайдено жодного успішного варіанту, то проводиться пошук серед виключень. При пошуку серед виключень доводиться переглядати усі словоформи усіх присутніх в словнику виключень. Це займає багато часу, тому пошук серед виключень проводиться тільки у тому випадку, коли не знайдено жодного варіанту серед звичайних основ.
7. Якщо деяка словоформа деякого виключення точно співпадає з аналізованим словом, то за номером словоформи визначаються змінні морфологічні параметри слова, а за словниковою інформацією самого виключення - постійні параметри слова.
8. Якщо після пошуку серед виключень все одно не знайдено жодного варіанту, то перевіряється наявність у аналізованого слова поворотного суфікса "-СЯ", "-СЬ", або приставок "НЕ-", "НИ-".
9. Якщо вони є, то вони відсікаються від аналізованого слова, і процедура пошуку повторюється спочатку. При цьому морфологічні параметри основ модифікуються спеціальною процедурою.
10. У разі, коли усі етапи пошуку дали негативний результат (не знайдено жодного варіанту), користувачеві видається запит на введення нової основи в словник.
11. Декілька записів складається для тих слів, для яких пошук в словнику мав двоякий результат, тобто було знайдено декілька омонімів.
12. Для кожної лексичної одиниці (незалежно від того, одна або декілька записів було для неї сформовано) створюється так званий "масив омонімів", в який включаються усі сформовані записи.
Потреба в онтологиях пов'язана з неможливістю адекватної автоматичної обробки природно-мовних текстів існуючими засобами. Тому, для якісної обробки текстів і пошуку релевантної інформації, необхідно мати детальний опис проблемної області, з множиною логічних зв'язків, які показують співвідношення між термінами області. Використання онтологій дозволяє представити природно-язиковий текст у такому вигляді, що він стає придатним для автоматичної обробки.
У роботі був проведений аналіз існуючих засобів і методів побудови онтологий. В ході аналізу було встановлено, що існує безліч інструментальних засобів, для побудови онтологий, проте не одне з них не дозволяє автоматизувати цей процес. Для побудови онтологий існують різні спеціалізовані мови, які у свою чергу використовують різні моделі представлення знань і засновані на різних логіках. В результаті проведеного аналізу були сформульовані завдання для подальшої роботи, вибрані методи і алгоритми для їх реалізації, сформульована математична постановка завдання побудови онтологій
- Исследование применения онтологических моделей для семантического поиска.
- ОНТОЛОГИИ И ТЕЗАУРУСЫ: [Учебное пособие] / Соловьев В.Д., Добров Б.В., Иванов В.В., Лукашевич Н.В. – Москва: 2006. – 157c.
- Обзор инструментов инженерии онтологий/ О.М. Овдей, Г.Ю. Проскудина // Журнал ЭБ. – 2004 – №4
- Никоненко А.А. Обзор баз знаний онтологического типа// Искусственный интеллект.–2002.–№ 4. – C. 157–163.
- Семантический веб и микроформаты [Електронний ресурс] : Интуит. Лекция — Режим доступу http://www.intuit.ru/department/internet/mwebtech/20/
- Алексей Николаевич Бевзов. Разработка методов автоматического индексирования текстов на естественном языке для информационно-поисковых систем. – М.: ИСО РАН – c. 401- 404
- ИНТЕРАКТИВНЫЕ МЕТОДЫ ФОКУСИРОВКИ И РАСШИРЕНИЯ ПОИСКА В ИНТЕЛЛЕКТУАЛЬНОЙ ПОИСКОВОЙ МАШИНЕ/В. Н. Поляков, Д. А. Бодров, А. В. Точин – М.: Московский Государственный институт стали и сплавов
- Королёв А.Н. Лингвистическое обеспечение информационно-поисковой системы Excalibur RetrievalWare: Аналитический аспект
- Семантический анализ текста на основе лексикосинтаксических шаблонов для информационного поиска. Рабчевский Евгений, Крупов Сергей, Рожков Михаил, Булатова Гульнара – Пермь: Государственный Университет
- Андреев А.М., Березкин Д.В., Брик А.В. Лингвистический процессор для информационно-поисковой системы – М: МГУ
- Анисимов А.В., Марченко А.А. Система обработки текстов на естественном языке.// Искусственный интеллект.–2002.–№ 4. – C. 157–163.
- Марченко О.О. Моделювання семантичного контексту при аналізі текстів на природній мові. Вісник Київського університету. Сер. фіз.-мат. Науки.– 2006. – № 3. – C. 230–235.

ДонНТУ - Портал магістрів