Метою дослідження є вивчення паралельних методів розпізнавання мови і розробка програмної системи розпізнавання усної мови, що функціонує в реальному часі. Для досягнення мети необхідно вирішити наступні завдання:
- проаналізувати існуючі паралельні засоби розпізнавання мовлення
- проаналізувати існуючі технології розпаралелювання комп'ютерних програм
- розробити алгоритм розпізнавання та здійснити його розпаралелювання для SIMD-архітектури
- розробити програму для розпізнавання мови в реальному часі
Технології розпізнавання мови все щільніше входять в наше життя, надаючи зручний засіб управління найрізноманітнішими електронними пристроями - управління голосом. На жаль, розпізнавання мови - завдання дуже ресурсномістке і вимагає високих обчислювальних потужностей, доступ до яких найчастіше обмежений (наприклад, у мобільних пристроях). Крім того, процес розпізнавання є тривалим за часом, в той час, як кінцеві користувачі пристроїв очікують швидкої реакції системи на команди.
Для прискорення обчислень можна використовувати розпаралелювання алгоритмів
З усього вищесказаного випливає, що дослідження паралельних методів розпізнавання усній мові, є на сьогоднішній день актуальною науковою проблемою.
У даній магістерській роботі будуть розглянуті методи автоматичного розпізнавання усній промови засобами технологій OpenMP і CUDA. Технологія CUDA є молодою технологією та її потенціал поки що слабо вивчений. Крім того, дослідження розпаралелювання нейронних мереж на графічних картах теж є молодими.
В результаті даної роботи планується створення програмної системи, здатної здійснювати розпізнавання мови в реальному часі. Крім того, буде здійснено створення бібліотеки, що полегшує моделювання штучних нейронних мереж і реалізацію нейромережевих обчислень.
Дослідженням методів розпізнавання усної мови та їх реалізацією на паралельних архітектурах займаються співробітники Microsoft Research: Frank Seide, Gang Li і Dong Yu [7].
Також дослідження з розпізнавання мови ведуть корпорації Google і Apple.
Лідер в області мовних технологій в Україні - відділ розпізнавання звукових образів Міжнародного науково-навчального центру інформаційних технологій і систем. З кінця 1960х років у відділі (тоді при Інституті Кібернетики) під керівництвом Вінцюк Т.К. ведуться роботи по розпізнаванню мови [6].
У Донецьку розпізнаванням мови займаються у відділі розпізнавання мовних образів Державного інституту штучного інтелекту і в Донецькому національному технічному університеті.
У ДонНТУ дослідження в даній області проводять асистент кафедри прикладної математики та інформатики Бондаренко І.Ю. і доцент кафедри Прикладної математики і інформатікі, кандидат технічних наук Федяєв О.І. [8]
Сучасні системи розпізнавання мовлення загального призначення в основному засновані на прихованих марковських моделях. Це статистичні моделі, які виводять послідовність символів. СММ використовуються в розпізнаванні мови, оскільки мовний сигнал можна розглядати як кусочно-стаціонарний сигнал. На коротких часових інтервалах (наприклад, 10 мілісекунд) мова може бути апроксимована як стаціонарний процес. Ще одна причина, по якій СММ користуються популярністю, полягає в тому, що вони можуть бути навчені автоматично і їх використання є простим.
Підхід динамічної деформації часу раніше використовувався повсюдно, але зараз його витіснили приховані марківські моделі. Динамічна деформація часу є алгоритмом для вимірювання подібності між двома послідовностями, які можуть змінюватися в часі або швидкості. Наприклад, подібність в рухах при ходьбі буде виявлена навіть якщо в одному відео людина йшла повільно, а в іншому швидше, і навіть якщо буде прискорення і уповільнення в ході одного спостереження. DTW може бути застосована до відео, аудіо та графіки. Насправді, будь-які дані, які можуть бути перетворені в лінійне уявлення можуть бути проаналізовані за допомогою DTW. [10]
Штучні нейронні мережі (ШНМ) - математичні моделі, а також їх програмні або апаратні реалізації, побудовані за принципом організації та функціонування біологічних нейронних мереж - мереж нервових клітин живого організму. Це поняття виникло при вивченні процесів, що протікають в мозку, і при спробі змоделювати ці процеси. Першою такою спробою були нейронні мережі Маккалока й Піттса. Згодом, після розробки алгоритмів навчання, створювані моделі стали використовувати в практичних цілях: в задачах прогнозування, для розпізнавання образів, в завданнях управління та ін.
ШНМ представляють собою систему з'єднаних і взаємодіючих між собою простих процесорів (штучних нейронів). Такі процесори зазвичай досить прості, особливо в порівнянні з процесорами, що використовуються в персональних комп'ютерах. Кожен процесор подібної мережі має справу тільки з сигналами, які він періодично отримує, і сигналами, які він періодично посилає іншим процесорам. І тим не менш, будучи з'єднаними в досить велику мережу з керованою взаємодією, такі локально прості процесори разом здатні виконувати досить складні завдання.
З точки зору машинного навчання, нейронна мережа являє собою окремий випадок методів розпізнавання образів, дискримінантного аналізу, методів кластеризації і т. п. З математичної точки зору, навчання нейронних мереж - це Багатопараметричне завдання нелінійної оптимізації. З точки зору кібернетики, нейронна мережа використовується в задачах адаптивного управління і як основа алгоритмів для робототехніки. З точки зору обчислювальної техніки та програмування, нейронна мережа - спосіб ефективного розпараллелювання завдань. А з точки зору штучного інтелекту, ШНМ є основою філософської течії коннектівізма і основним напрямком в структурному підході з вивчення можливості побудови (моделювання) природного інтелекту за допомогою комп'ютерних алгоритмів.
Нейронні мережі не програмуються в звичному розумінні цього слова, вони навчаються. Можливість навчання - одна з головних переваг нейронних мереж перед традиційними алгоритмами. Технічно навчання полягає в знаходженні коефіцієнтів зв'язків між нейронами. У процесі навчання нейронна мережа здатна виявляти складні залежності між вхідними даними і вихідними, а також виконувати узагальнення. Це означає, що у разі успішного навчання мережа зможе повернути вірний результат на підставі даних, які були відсутні в навчальній вибірці, а також неповних та/або «зашумленних», частково перекручених даних [5].
Які засоби необхідні програмісту для створення паралельної програми? Взагалі кажучи, відповідь залежить від того, на який клас паралельних обчислювальних систем розрахована майбутня програма. Для систем із загальною пам'яттю класичним є підхід, заснований на використанні потоків. Для кластерів, де кожен обчислювальний вузол працює під управлінням власної операційної системи, паралельній програмі, що представляє собою набір процесів, потрібні механізми передачі даних через мережу. Для систем, що мають потужні графічні чіпи, ідеальним варіантом буде GPGPU. Гібридні системи - кластери з SMP-вузлами і графічними картами - змушують шукати компроміс між відносною простотою створення паралельної програми тільки на основі процесів (приносимо в жертву швидкість обміну даними між ними), або використанням і процесів, і потоків, і GPGPU відразу (виграємо в продуктивності на кожному вузлі, але витрачаємо значно більше зусиль на етапі розробки).
У кожному з розглянутих вище випадків розробнику не обійтися без підтримки з боку операційної системи, яка повинна надати необхідний API для роботи з потоками, примітиви синхронізації, механізми для обміну даними між процесами, що виконуються як на одному обчислювальному вузлі, так і на різних, як на процесорах, так і на відеочіпах. Тим не менш, незважаючи на те, що така підтримка існує - найбільш поширені операційні системи (зокрема сімейств Windows і Linux) мають цілком достатній рівень реалізації всіх необхідних механізмів - розробка паралельної програми тільки з їх допомогою - заняття, порівнянне за складністю з написанням послідовної програми на асемблері. Наслідком описаних обставин стала поява як окремих інструментів, що підтримують процес створення паралельних програм, починаючи від відладчиків і складальників трас виконання і закінчуючи провісниками очікуваної ефективності, так і спеціальних технологій розробки, що пропонують підтримку або у вигляді бібліотек функцій (підхід MPI), або на рівні компілятора (підхід OpenMP), або на рівні драйверів (CUDA, OpenCL, GLSL).
При всьому багатстві вибору існуючих та створюваних знову засобів розробки паралельних програм, починаючи від мов програмування і закінчуючи бібліотеками, що пропонують готові реалізації типових обчислювальних завдань, реальних альтернатив на сьогоднішній момент досить небагато, і кожній з них притаманні свої обмеження.
Найбільш загальним способом створення паралельних програм для систем із загальною пам'яттю є використання потоків. При цьому функціональний паралелізм легко забезпечується написанням різних потокових функцій, а паралелізм за даними реалізується завдяки загальному віртуальному адресному просторові процеса, до якого всі потоки мають доступ. Працювати з потоками програміст може, як використовуючи API операційної системи, так і створивши власну бібліотеку потоків. Останній підхід у ряді випадків може забезпечити більшу швидкодію програми за рахунок менших накладних витрат, але значно більш трудомісткий. Розробка паралельної програми на основі потоків, особливо в разі паралелізму за даними, передбачає вирішення завдання синхронізації і подолання низки можливих проблем: взаємного блокування, тупиків, гонок даних і т.д. Метою при цьому є одержання коректних результатів виконуваних обчислень, наприклад, недопущення читання з оперативної пам'яті порції даних одним потоком в той момент, коли інший потік здійснює запис цих даних.
Операційні системи надають необхідні засоби для вирішення всіх завдань, що виникають в багатопотоковому програмуванні: критичні секції, ознаки блокування, семафори, мьютекс, події і т.д. Однак грамотне використання цих механізмів вимагає суттєвих зусиль, оскільки відсутність необхідної синхронізації доступу до даних тягне за собою, як мінімум, неправильні результати, а в гіршому випадку призводить до аварійного завершення програми. У той же час, надмірна синхронізація веде до зниження ефективності і масштабованості паралельної програми.
Завдання, які повинен вирішити програміст, який розробляє паралельну програму для системи з загальною пам'яттю, у багатьох випадках ідентичні, а значить, їх реалізацію можна перекласти на компілятор, що і пропонує стандарт OpenMP, що специфікує набір директив компілятора (для мов C, C++ та Fortran), функцій бібліотеки (для тих же мов) і змінних оточення. OpenMP можна розглядати як високорівневу надбудову над POSIX або Windows Threads (чи аналогічними бібліотеками потоків).
На даний момент існують реалізації стандарту OpenMP в компіляторах від багатьох виробників.
Перевагами OpenMP є:
- Простота використання - розробник не створює нову паралельну програму, а додає в текст послідовної програми необхідні директиви і, можливо, виклики бібліотечних функцій, що вказують компілятору способи розподілу обчислень і даних між потоками, а також доступу до них. Головною ідеєю OpenMP є розпаралелювання циклів, що зазвичай несуть основне обчислювальне навантаження.
- Гнучкість - OpenMP надає розробнику досить великі можливості контролю над поведінкою паралельної програми.
- Повторне використання - OpenMP-програма в багатьох випадках може бути використана як звичайна послідовна, якщо необхідно забезпечити її виконання на однопроцесорній платформі. При цьому, щоб позбутися від реалізації OpenMP у виконуваному модулі, досить перезібрати його послідовним компілятором. Директиви OpenMP будуть проігноровані, а виклики функцій бібліотеки можуть бути замінені на заглушки, текст яких наведено в специфікаціях стандарту.
Створення паралельних програм з використанням стандарту OpenMP та відповідних компіляторів у багатьох випадках дає не меншу ефективність, ніж програмування в потоках, і вимагає суттєво менше зусиль від розробника, однак OpenMP працює тільки в SMP-системах.
Паралельне програмування для систем з розподіленою пам'яттю (кластерів) не має в достатній мірі високорівневої (на зразок потоків) підтримки в операційних системах. Пряму роботу з сокетами для реалізації обміну даними між процесами паралельної програми не віднесеш до зручних підходів.
Стандарт MPI надає механізм побудови паралельних програм в моделі обміну повідомленнями, характерною для розробки програм, орієнтованих на кластерні системи. Стандарт специфікує набір функцій і вводить певний рівень абстракції на основі повідомлень, типів, груп і комунікаторів, віртуальних топологій. Існують стандартні "прив'язки" MPI до мов С, С + +, Fortran. Реалізації стандарту MPI є практично для всіх суперкомп'ютерних платформ, а також кластерів на основі робочих станцій UNIX\Linux та Windows. В даний час MPI - інтерфейс зі свого класу, що найбільш широко використовується і динамічно розвивається.
До позитивних моментів MPI можна віднести:
- Переносимість - MPI дозволяє значною мірою знизити гостроту проблеми переносимості паралельних програм між різними комп'ютерними системами - паралельна програма, розроблена на алгоритмічній мові C або Fortran з використанням бібліотеки MPI, як правило, буде працювати на будь-яких обчислювальних платформах, для яких є реалізація стандарту.
- Підвищення ефективності - MPI сприяє підвищення ефективності паралельних обчислень, оскільки в даний час практично для кожного типу обчислювальних систем існують реалізації стандарту, в максимальному ступені враховують можливості використовуваного комп'ютерного обладнання.
Основним підходом до побудови MPI-програм є явний розподіл даних і обчислень між процесами, а також обмін повідомленнями для передачі даних, в силу чого MPI-програма часто суттєво відрізняється від програми послідовної, а в деяких випадках навіть не може виконуватися в однопроцессному варіанті. І звичайно, створення та налагодження MPI-програм вимагає значно більших зусиль, ніж створення послідовної програми, що вирішує ту ж задачу.
Обчислення на GPU або GPGPU (General-purpose computing on graphics processing units, графічні обчислення загального призначення) полягають у використанні GPU (графічного процесора) для універсальних обчислень в галузі науки та проектування.
GPU обчислення представлені спільним використанням CPU і GPU в гетерогенній моделі обчислень. Стандартна частина програми виконується на CPU, а більш вимоглива до обчислень частина обробляється з GPU прискоренням. З точки зору користувача додаток працює швидше, тому що він використовує високу продуктивність GPU для підвищення своєї продуктивності.
Історія графічних чіпів почалася з графічних конвеєрів з фіксованою функціональністю. Поступово їх програмованість все зростала, і, врешті-решт, nVidia представила перший GPU, або графічний процесор. У 1999-2000 роках фахівці в комп'ютерній області та науковці в таких сферах, як отримання медичних зображень і електромагнетизм, перейшли на GPU для обчислювальних програм загального призначення. Вони виявили, що висока продуктивність обчислень з плаваючою точкою графічних процесорів значно прискорювала роботу наукових програм. Це стало початком потужного руху, що називається GPGPU або обчислення загального призначення на GPU.
В даний час, найпоширенішими технологіями GPGPU є шейдерна мова GLSL і технології CUDA і OpenCL.
GLSL (OpenGL Shading Language, шейдерний мова OpenGL), також відомий як GLslang, є високорівневої шейдерною мовою, що заснована на мові програмування Сі. Він був створений OpenGL ARB, щоб дати розробникам більш прямий контроль над відеокартою без використання асемблера чи апаратно-залежних мов.
Шейдери на GLSL, суть - просто шматки С-подібного коду, що компилюється драйвером на етапі виконання в байткод і передається на GPU для виконання. Важливий момент: GLSL допускає використання процедур і розуміє цикли (особливо в розгорнутому вигляді), але заперечує рекурсію (позначається відсутність стека).
Переваги GLSL:
- кроссплатформена сумісність на декількох операційних системах, включаючи GNU/Linux, Windows, MacOS.
- шейдерні програми можуть бути використані на будь-якій карті, що підтримує GLSL.
- кожен постачальник обладнання включає підтримку цієї мови в драйвера своїх пристроїв, що дозволяє створювати код, оптимізований під будь-яку архітектуру.
У 2006-2007 компанія NVIDIA зробила революцію в GPGPU і прискорила обчислення завдяки новій архітектурі масивно паралельних обчислень CUDA. Архітектура CUDA складається із сотень процесорних ядер, які працюють у зв'язці, щоб разом впоратися з набором даних у додатку.
CUDA (Compute Unified Device Architecture) - програмно-апаратна архітектура, що дозволяє робити обчислення з використанням графічних процесорів NVIDIA, що підтримують технологію GPGPU. Архітектура CUDA вперше з'явилася на ринку з виходом чіпа NVIDIA восьмого покоління - G80 і присутня у всіх наступних серіях графічних чіпів, які використовуються в родинах прискорювачів GeForce, Quadro і Tesla.
CUDA SDK дозволяє програмістам реалізовувати на спеціальному спрощеному діалекті мови програмування Сі алгоритми, здійсненні на графічних процесорах NVIDIA і включати спеціальні функції в текст програми на Сі. CUDA дає розробнику можливість на свій розсуд організовувати доступ до набору інструкцій графічного прискорювача і управляти його пам'яттю, організовувати на ньому складні паралельні обчислення.
Первісна версія CUDA SDK була представлена 15 лютого 2007 року. В основі CUDA API лежить мова Сі з деякими обмеженнями. Для успішної трансляції коду на цій мові, до складу CUDA SDK входить власний Сі-компілятор командного рядка nvcc компанії Nvidia. Компілятор nvcc створений на основі відкритого компілятора Open64 і призначений для трансляції host-коду (головного, керуючого коду) і device-коду (апаратного коду) (файлів з розширенням .cu) в об'єктні файли, придатні в процесі складання кінцевої програми або бібліотеки в будь якому середовищі програмування, наприклад в NetBeans.
Використовує grid-модель пам'яті, кластерне моделювання потоків і SIMD інструкції. Застосуємо в основному для високопродуктивних графічних обчислень і розробок NVIDIA-сумісного графічного API. Включена можливість підключення до додатків, що використовують OpenGL і Microsoft Direct3D 9. Створений у версіях для Linux, Mac OS X, Windows.
Переваги
У порівнянні з традиційним підходом до організації обчислень загального призначення за допомогою можливостей графічних API, у архітектури CUDA відзначають наступні переваги в цій області:
- Інтерфейс програмування додатків заснований на стандартній мові програмування Сі з деякими обмеженнями. На думку розробників, це повинно спростити і згладити процес вивчення архітектури CUDA.
- Колективна між потоками пам'ять (shared memory) розміром в 16 Кб може бути використана під організований користувачем кеш з більш широкою смугою пропускання, ніж при вибірці зі звичайних текстур
- Більш ефективні транзакції між пам'яттю центрального процесора і відеопам'яттю
- Повна апаратна підтримка цілочисельних і побітових операцій
Обмеження
- Всі функції, здійсненні на пристрої, не підтримують рекурсії (у версії CUDA Toolkit 3.1 підтримує покажчики і рекурсію) і мають деякі інші обмеження
- Архітектуру CUDA підтримує і розвиває тільки виробник Nvidia
OpenCL (від англ. Open Computing Language - розширювана мова обчислень) - фреймворк для написання комп'ютерних програм, пов'язаних з паралельними обчисленнями на різних графічних (англ. GPU) і центральних процесорах (англ. CPU). У фреймворк OpenCL входить мова програмування, яка базується на стандарті C99, і інтерфейс програмування додатків (англ. API). OpenCL забезпечує паралелізм на рівні інструкцій і на рівні даних і є реалізацією техніки GPGPU. OpenCL є повністю відкритим стандартом, його використання не обкладається ліцензійними відрахуваннями.
Мета OpenCL полягає в тому, щоб доповнити OpenGL і OpenAL, які є відкритими галузевими стандартами для тривимірної комп'ютерної графіки і звуку, користуючись можливостями GPU. OpenCL розробляється і підтримується некомерційним консорціумом Khronos Group, до якого входять багато крупних компаній, включаючи Apple, AMD, Intel, NVidia, ARM, Sun Microsystems, Sony Computer Entertainment та інші.
Переваги:
- Працює на будь-якому обладнанні
Недоліки:
- Більш низька, порівняно з CUDA, швидкість обчислення
- Відсутність підтримки покажчиків на функції, рекурсії, бітових полів, масивів змінної довжини (VLA), стандартних заголовків файлів
Розпізнавання мовлення в даній роботі ми будемо проводити за допомогою штучних нейронних мереж. Даний вибір обумовлений:
- хорошою здатністю нейромереж до навчання та самонавчання,
- їх високим природним паралелізмом.
Розпаралелювання буде здійснюватись за допомогою технологій OpenMP і CUDA. Технологія OpenMP була обрана завдяки простоті її використання, а також з-за широкої поширеності багатоядерних процесорів. Технологія CUDA обрана через здатність забезпечити високу швидкість обчислень.
Розпізнавання мовлення - це багаторівнева задача розпізнавання образів, в якій акустичні сигнали аналізуються і структуруються в ієрархію структурних елементів (наприклад, фонем), слів, фраз і пропозицій [4]. Кожен рівень ієрархії може передбачати деякі тимчасові константи, наприклад, можливі послідовності слів або відомі види вимови, які дозволяють зменшити кількість помилок розпізнавання на більш низькому рівні. Чим більшою кількістю апріорної інформації про вхідний сигнал ми володіємо, тим якісніше можемо його обробити та розпізнати.
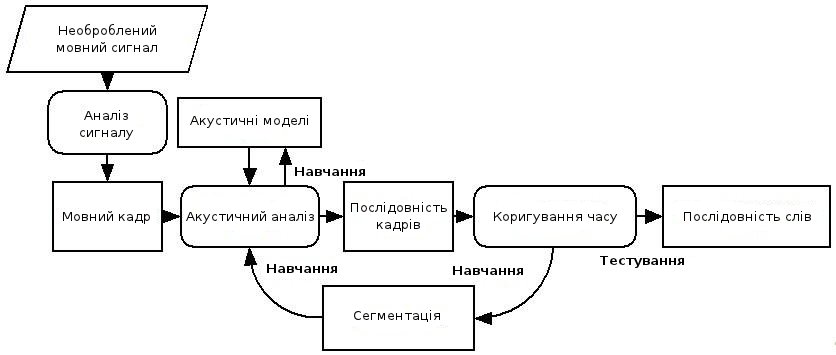
Мал. 1 - Структура системи розпізнавання мовлення
Структура стандартної системи розпізнавання мови показана на малюнку [3]. Розглянемо основні елементи цієї системи.
Необроблена мова. Зазвичай, потік звукових даних, записаний з високою дискретизацією (16 КГц при запису з мікрофону або 8 КГц при запису з телефонної лінії).
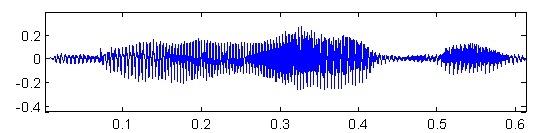
Мал. 2 - Необроблений мовний сигнал (вісь X - час, вісь Y - амплітуда сигналу)
Аналіз сигналу. Первісний сигнал повинен бути спочатку трансформований і стиснутий для полегшення подальшої обробки. Є різні методи для добування корисних параметрів і стиснення вихідних даних у десятки разів без втрати корисної інформації. Найбільш використовувані методи: аналіз Фур'є; лінійне пророкування мови; кепстральний аналіз.
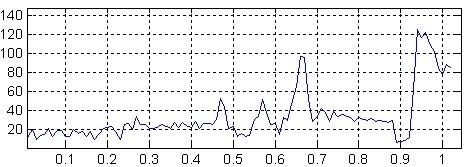
Мал. 3 - Результат спектрального аналізу (вісь X - частота, вісь Y - потужність сигналу)
Мовні кадри. Результатом аналізу сигналу є послідовність мовних кадрів. Зазвичай, кожен мовний кадр - це результат аналізу сигналу на невеликому відрізку часу (близько 20-25 мс.), що містить інформацію про цю ділянку. Для поліпшення якості розпізнавання, в кадри може бути додана інформація про першу або другу похідну значень їх коефіцієнтів для опису динаміки зміни мови.
Акустичні моделі. Для аналізу складу мовних кадрів потрібно набір акустичних моделей. Розглянемо дві найбільш поширені з них. Шаблонна модель. У якості акустичної моделі виступає якимось чином збережений приклад структурної одиниці, що розпізнається (слова, команди). Варіативність розпізнавання такою моделлю досягається шляхом збереження різних варіантів вимови одного й того ж елемента (безліч дикторів багато разів повторюють одну і ту ж команду). Використовується, в основному, для розпізнавання слів як єдиного цілого (командні системи). Модель станів. Кожне слово моделюється імовірнісним автоматом, в якому кожен стан являє собою набір звуків. Цей підхід використовується у більш масштабних системах.
Акустичний аналіз. Полягає у зіставленні різних акустичних моделей до кожного кадру мови. В результаті утворюється матриця зіставлення послідовності кадрів і безлічі акустичних моделей. Для шаблонної моделі, ця матриця являє собою набір Євклідових відстаней між шаблонним і розпізнаваним кадром (тобто обчислюється, як сильно відрізняється отриманий сигнал від записаного шаблону і знаходиться шаблон, який найбільше підходить до отриманого сигналу). Для моделей станів, матриця складається з ймовірностей того, що даний стан може згенерувати даний кадр.
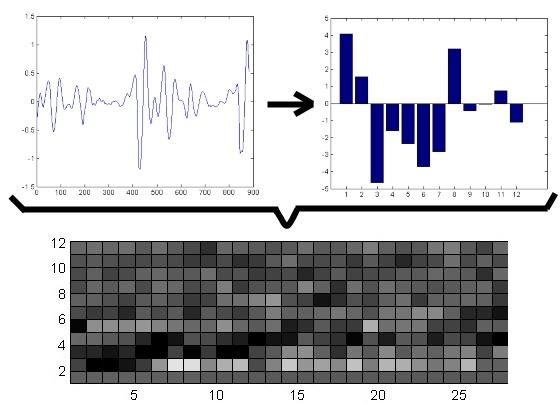
Мал. 4 – Акустичний аналіз (на графіках зліва направо: 1) мовний кадр, вісь X - час, вісь Y - амплітуда, 2) акустична модель, вісь X - стан, вісь Y - амплітуда, 3) спектрально-часовий образ, вісь X - час, вісь Y - частота, більш світлі комірки показують більшу інтенсивність)
Коригування часу. Використовується для обробки тимчасової варіативності, що виникає при вимові слів (наприклад, "розтягування" або "з'їдання" звуків).
Як правило, повний опис мовного сигналу тільки його спектром неможливий. Поряд зі спектральною інформацією, необхідна ще й інформація про динаміку мови. Для її отримання використовуються дельта-параметри, що представляють собою похідні за часом від основних параметрів.
Отримані таким чином параметри мовного сигналу вважаються її первинними ознаками і подаються на вхід нейронної мережі, на виході якої будуть відповідні сигналу фонеми. Потім фонеми збираються в слова і пропозиції.
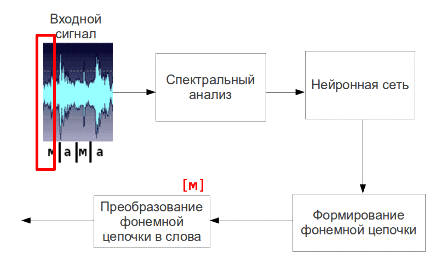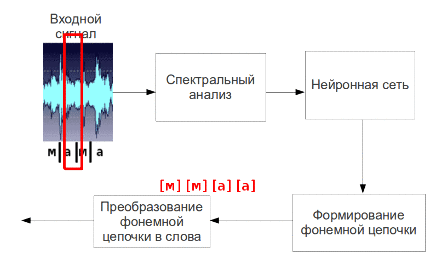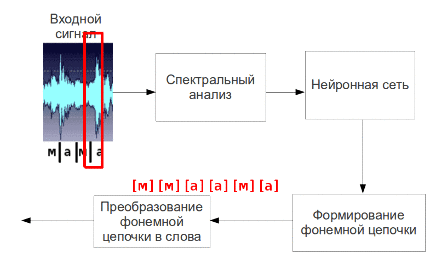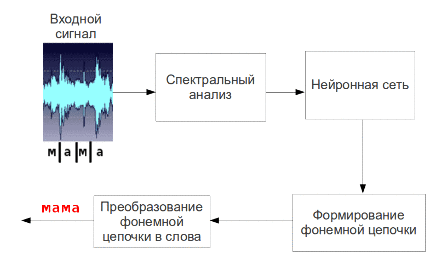
Мал. 5 - Процес пофонемного розпізнавання мови (анімація: 9 кадрів, 4.5 секунди, 7 повторів, обсяг 137.5 КБ)
На даний момент вже реалізована бібліотека для моделювання штучних нейронних мереж, яка виробляє послідовні обчислення. Також виконано її часткове розпаралелювання за технологією Nvidia CUDA [1] [9].
У роботі були проаналізовані існуючі методи розпізнавання мови і технології розпаралелювання програм. Були обрані штучні нейронні мережі як метод розпізнавання, а також технології OpenMP і CUDA для збільшення швидкодії [2]. Планується написання програми, що забезпечує розпізнавання мови в реальному часі.
- Шатохин Н. А., Реализация нейросетевых алгоритмов средствами видеокарты с помощью технологии Nvidia CUDA. // Информатика и компьютерные технологии / Материалы V международной научно-технической конференции студентов, аспирантов и молодых ученых — 24-26 ноября 2009 г., Донецк, ДонНТУ. - 2009. - 521 с.
Прочитать статью из моей библиотеки - PDF
- Шатохин Н.А., Бондаренко И.Ю. Сравнительный анализ эффективности распараллеливания нейроалгоритма распознавания речи на вычислительных архитектурах OPENMP и CUDA // Інформаційні управляючі системи та комп’ютерний моніторинг (ІУС КМ - 2011) / II Всеукраїнська науково-технічна конференція студентів, аспірантів та молодих вчених, 11-13 квітня 2011 р., м. Донецьк : зб. доп. у 3 т./ Донец. націонал. техн. ун-т; редкол.: Є.О. Башков (голова) та ін. – Донецьк: ДонНТУ, 2011. - Т.3. - 301 с.
Прочитать статью из моей библиотеки - HTML
- Фролов А., Фролов Г. Синтез и распознавание речи. Современные решения. [Электронный ресурс] — 2003. - Режим доступа: http://www.frolov-lib.ru/books/hi/index.html
- Алексеев В. Услышь меня, машина. / В. Алексеев // Компьютерра, - 1997. - №49.
- Уоссермен Ф. Нейрокомпьютерная техника: Теория и практика. - Изд. "Мир". - 1992. - 185 с.
- Винцюк Т.К. Анализ, распознавание и интерпретация речевых сигналов. - К.: Наукова Думка, - 1987. -262 с.
- Сейд Ф, Ли Г., Ю Д. Транскрипция разговорной речи с помощью контекстно-зависимой глубокой нейронной сети [электронный ресурс] — 2011. - Режим доступа: http://research.microsoft.com/pubs/153169/CD-DNN-HMM-SWB-Interspeech2011-Pub.pdf
- И. Ю. Бондаренко, О. И. Федяев, К. К. Титаренко. Нейросетевой распознаватель фонем русской речи на мультипроцессорной графической плате // Искусственный интеллект. - №3. - 2010. - 176 с.
- Д. В. Калитин. Использование технологии CUDA фирмы Nvidia для САПР нейронных сетей // Устойчивое инновационное развитие: проектирование и управление – №4. – 2009. – С. 16-19.
Прочитать статью из моей библиотеки - PDF
- Вригли С. Распознавание речи с помощью динамической деформации времени. [Электронный ресурс] – 1998. - Режим доступа: http://www.dcs.shef.ac.uk/~stu/com326/index.html.
Важливо
На момент написання даного реферату магістерська робота ще є не завершеною. Передбачувана дата завершення: 1 грудня 2011 р., через що повний текст роботи, а також матеріали по темі можуть бути отримані у автора або його керівника тільки після зазначеної дати.

