The goal is the research of automatic speech recognition and development of speech recognition system that operates in real time. Among the tasks are the following:
- Analysis of parallel methods for speech recognition
- Analysis of existing technologies parallelization of computer programs
- Choice recognition technology and means for its parallelization and justification of choice
- Development programs for speech recognition in real time
Speech recognition technology is denser part of our lives, providing a convenient tool for managing a variety of electronic devices - voice control. Unfortunately, speech recognition - the task is very demanding and requires high computational power, access to which is often limited (eg mobile devices). In addition, the process of recognition is a long time, while, as end users expect fast response devices in the system command.
To speed up calculations can be used parallel algorithms
From the foregoing it follows that the study of parallel methods for recognizing spoken language is today urgent scientific challenge.
This master's thesis will address methods of automatic speech recognition of spoken parallel technologyes means OpenMP and CUDA. CUDA technology is a young technology and its potential is still poorly understood. In addition, the study of neural networks on parallel graphics cards, too, are young.
As a result of this work is planned to create a software system able to perform speech recognition in real time. In addition, the library will be made to facilitate simulation of artificial neural networks and neural network computing implementation.
The study of oral speech recognition methods and their implementation on parallel architectures employees engaged Microsoft Research: Frank Seide, Gang Li and Dong Yu [7].
Also, speech recognition researching by Google and Apple.
Leader in the field of language technologies in Ukraine - Department of recognition of sound images of the International Research and Training Center of Information Technologies and Systems. Since the late 1960s years in the department (then at the Institute of Cybernetics) led Vintsyuk T.K. are working on speech recognition [6].
In Donetsk, recognition researching by Speech recognition department of the State Institute of Artificial Intelligence and the Donetsk National Technical University.
In DonNTU research in this area spend Assistant Professor of Applied Mathematics and Computer I. Bondarenko and Associate Professor of Applied Mathematics and Computer, Ph.D. O. Fedyayev. [8]
- Hidden Markov Models
- Dynamic deformation time (DTW)
- Artificial neural networks
- Multithread programming
- Technology OpenMP
- MPI Technology
- Computation on GPU
- Language GLSL
- CUDA Technology
- OpenCL technology
Speech Recognition in the present work we carry out using artificial neural networks. This choice is due to good resolution of selfteaching of neural networks and their high natural parallelism.
Parallelization will be implemented through technology OpenMP and CUDA. OpenMP technology was chosen due to its ease of use and because of the wide prevalence of multicore processors. CUDA technology is chosen because of the ability to provide high speed computing.
Speech Recognition - a multilevel pattern recognition task in which acoustic signals are analyzed and structured into a hierarchy of structural elements (eg, phonemes), words, phrases and sentences [4]. Each level of hierarchy may provide some temporary constants, for example, the possible sequence of words or known types of pronunciation, to reduce the number of recognition errors on a lower level. The more we know (or assume) a priori information about the input signal, the better we can handle it and recognize.
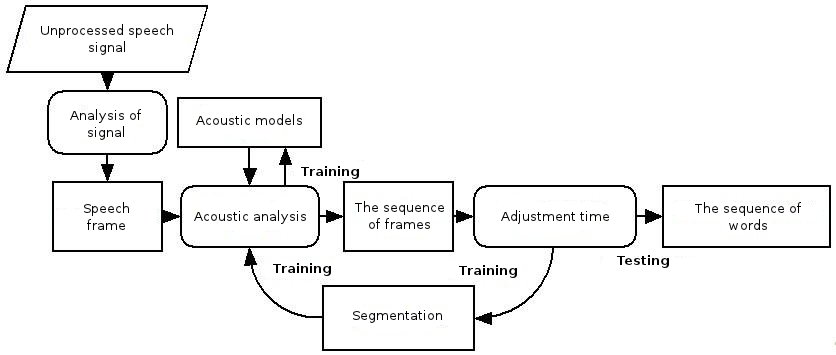
Fig. 1 - Structure of Speech Recognition
The structure of a standard speech recognition system is shown in the figure. Consider the basic elements of this system.
Raw speech. Usually, the flow of audio data recorded with high discretization (16 kHz when recording from a microphone or 8 KHz for recording telephone line).
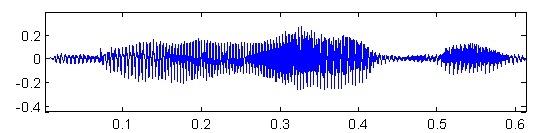
Fig. 2 - coarse speech signal (axis X - time, the axis Y - signal amplitude)
Analysis of the signal. Incoming signal must first be transformed and compressed to facilitate further processing. There are different methods for extraction of parameters and initial data compression dozens of times without losing useful information. The most used methods: Fourier analysis, linear prediction speech; kepstralnyy analysis.
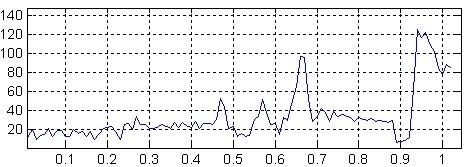
Fig. 3 - Result of spectral analysis (axis X - the frequency, axis Y - signal power)
Language frames. The result is an analysis of the signal sequence of speech frames. Typically, each speech frame - the result of analysis of the signal on a small interval of time (about 20-25 ms.) that contains information about the area. To improve recognition, in the frames can be added about the first or second derivative values of the coefficients to describe the dynamics of language change.
Acoustic model. For the analysis of language training to a set of acoustic models. Consider the two most common ones. Template model. As an acoustic model appears somehow preserved example of a structural unit that is recognized (words, commands). Variation of this model, recognition is achieved by maintaining different versions of pronunciation of the same element (multiple narrators often repeat the same command). Used mainly for word recognition as a whole (command). States model. Each word is modeled by a probabilistic automaton, where each state represents a set of sounds. This approach is used in larger systems.
Acoustic analysis. Consists in comparing different acoustic models for each frame of speech and gives a matrix comparing the sequence of frames and a set of acoustic models. For template model, this matrix is set of the Euclidean distances between the template and be recognized frame (ie, calculated as the received signal is very different from the recorded and template is a template that best fits the received signal). For models based on condition, the matrix consists of the probability that this condition can generate a given frame.
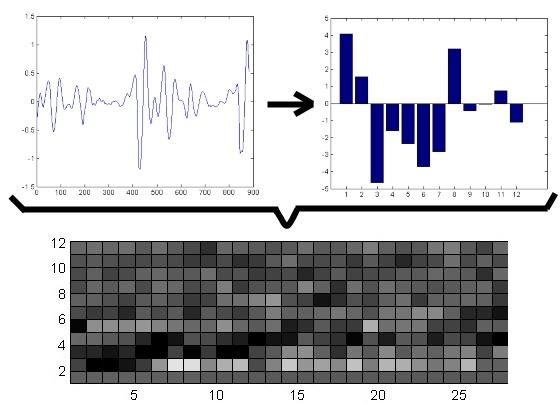
Fig. 4 - acoustic analysis (the graphs from left to right: 1) speech frame, the axis X - time, the axis Y - amplitude, and 2) acoustic model, the axis X - state, the axis Y - amplitude, and 3) spectral-time pattern, the axis X - time, the axis Y - frequency, lighter cells have higher intencity)
Adjustment of time. Used for processing temporal variability that occurs when the pronunciation of words (eg, "stretching" or "eating" sounds).
Typically, a full description of the speech signal only its spectrum is impossible. Along with the spectral information is also needed about the dynamics of language. To get her used delta values that represent the time derivative of the basic parameters.
The resulting parameters of speech signal is considered to be its primary signs and presented to the input of neural network, which will output a signal corresponding phonemes. Then going phonemes into words and suggestions.
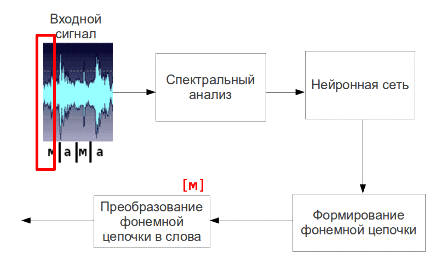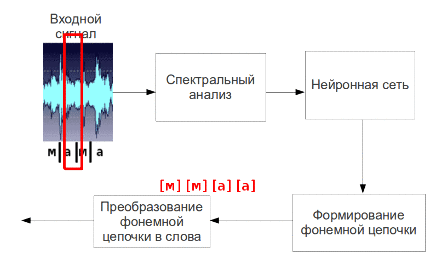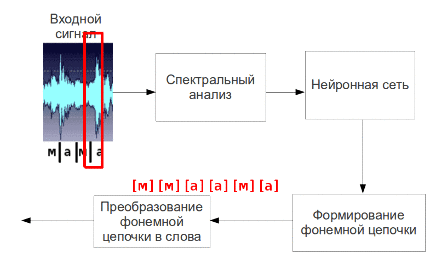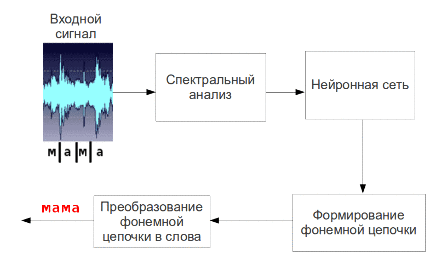
Fig. 5 - The process of phoneme speech recognition (animation: 9 shots, 4.5 seconds, 7 repetitions, the amount of 137.5 KB)
At the moment, already implemented libraries for modeling artificial neural networks, which produces consistent calculation. Also completed its partial parallelization by technology Nvidia CUDA [1] [9].
In this paper we analyzed the existing methods of speech recognition technology and parallel programs. Were selected artificial neural networks as a method of recognition, as well as OpenMP and CUDA technology to increase performance [2]. Planned to write a program that provides speech recognition in real time.
- Шатохин Н. А., Реализация нейросетевых алгоритмов средствами видеокарты с помощью технологии Nvidia CUDA. // Информатика и компьютерные технологии / Материалы V международной научно-технической конференции студентов, аспирантов и молодых ученых — 24-26 ноября 2009 г., Донецк, ДонНТУ. - 2009. - 521 с.
Прочитать статью из моей библиотеки - PDF
- Шатохин Н.А., Бондаренко И.Ю. Сравнительный анализ эффективности распараллеливания нейроалгоритма распознавания речи на вычислительных архитектурах OPENMP и CUDA // Інформаційні управляючі системи та комп’ютерний моніторинг (ІУС КМ - 2011) / II Всеукраїнська науково-технічна конференція студентів, аспірантів та молодих вчених, 11-13 квітня 2011 р., м. Донецьк : зб. доп. у 3 т./ Донец. націонал. техн. ун-т; редкол.: Є.О. Башков (голова) та ін. – Донецьк: ДонНТУ, 2011. - Т.3. - 301 с.
Прочитать статью из моей библиотеки - HTML
- Фролов А., Фролов Г. Синтез и распознавание речи. Современные решения. [Электронный ресурс] — 2003. - Режим доступа: http://www.frolov-lib.ru/books/hi/index.html
- Алексеев В. Услышь меня, машина. / В. Алексеев // Компьютерра, - 1997. - №49.
- Уоссермен Ф. Нейрокомпьютерная техника: Теория и практика. - Изд. "Мир". - 1992. - 185 с.
- Винцюк Т.К. Анализ, распознавание и интерпретация речевых сигналов. - К.: Наукова Думка, - 1987. -262 с.
- Сейд Ф, Ли Г., Ю Д. Транскрипция разговорной речи с помощью контекстно-зависимой глубокой нейронной сети [электронный ресурс] — 2011. - Режим доступа: http://research.microsoft.com/pubs/153169/CD-DNN-HMM-SWB-Interspeech2011-Pub.pdf
- И. Ю. Бондаренко, О. И. Федяев, К. К. Титаренко. Нейросетевой распознаватель фонем русской речи на мультипроцессорной графической плате // Искусственный интеллект. - №3. - 2010. - 176 с.
- Д. В. Калитин. Использование технологии CUDA фирмы Nvidia для САПР нейронных сетей // Устойчивое инновационное развитие: проектирование и управление – №4. – 2009. – С. 16-19.
Прочитать статью из моей библиотеки - PDF
- Вригли С. Распознавание речи с помощью динамической деформации времени. [Электронный ресурс] – 1998. - Режим доступа: http://www.dcs.shef.ac.uk/~stu/com326/index.html.
Importantly
At the time of writing this essay master thesis is still not complete. Estimated completion date: December 1, 2011, through the full text of the work and materials on the topic can be obtained from the author or his head only after that date.

