Введение
Социальные сети в настоящее время стали основным средством общения, поддержки и развития социальных контактов, поиска, хранения, редактирования и классификации информации, творческой деятельности и выполнения множества других задач. Не смотря на разнообразие взглядов и предпочтений людей, в сети возникает повторение опубликованного материала. Это связано в первую очередь с таксономическим и фолксономическим подходами классификации данных.
Недостаток таксономического подхода в том, что объект в таком можно привязать только к одному узлу, то есть становится невозможным при помощи такой структуры описать все необходимые качества этого объекта. В связи с этим очевидно копирование этого же объекта в другой узел с описанием других качеств.
Фолксономический подход лишен этого недостатка - можно привязать объект к любым узлам. Однако, в последнем подходе отсутствует всяческая структура, т.е. нет элементарных отношений (род-вид) между узлами. Таким образом, нельзя выявить объекты, носящие более общий или более частный характер. Это также является значительным недостатком для сервисов видеохостинга с огромными объемами информации, что снижает эффективность поиска и приводит к созданию копий файлов. [5][4]
Следует отметить, что количество копий видеоматериалов, размещенных на одном видеосервисе или социальной сети, напрямую зависит от популярности видеоролика и тенденций моды. Из личных исследований было выявлено, что «популярный» видеоматериал размещен на одном видеосервисе от 5 до 20 раз, и лишь 1-2 видеоролика из них отличаются качеством видеоизображения, при объемах видеоматериалов крупных сетевых сервисов это значительный объем дискового пространства, измеряемый в терабайтах. Также увеличивает объем хранимых данных использование технологии RAID 10 на серверах, и CDN-сети доставки контента. [5]
Цель и задачи исследования
Целью работы является уменьшение стоимости хранения и увеличение быстродействия работы серверов видеосервисов, путем выявления схожего видеоматериала. Для достижения поставленной цели в процессе исследований необходимо:
-
Рассмотреть и изучить существующие методы поиска идентичных видеофайлов;
-
Выполнить анализ работы алгоритмов сжатия видеоматериала;
- Разработать алгоритм захвата и преобразования видеоматериала в некоторую последовательность кадров;
- Разработать алгоритм распознавания и классификации полученных последовательностей.
- Оценить сложность реализации разработанной системы, и определить области ее эффективного применения
Актуальность
Актуальность работы определяется популярностью социальных сетей и видеохостингов. Разработанная система позволит во много раз сократить объем неэфективного использования устройств хранения. А удаление повторяющихся видеороликов являеться одной из самых актуальных задач оптимизации видеохостингов.
Предполагаемая научная новизна
Для поиска идентичных видеофайлов на видеохостингах применяют хеширование или расчет контрольной суммы. Данные процессы занимают длительное время поэтому однажды высчитанная хеш – сумма фиксируется в базе данных для дальнейшего использования. Данный метод не позволяет анализировать видеоряд данных и неспособен определить равные по содержимому, но разные по размеру, кодеку сжатия, разрешению файлы.
Разрабатываемая система позволяет на основании данных полученных из видеоряда сравнивать между собой видеоролики используя системы распознавания образов, и делать предположения о степени схожести данного видеоматериала. Данная система имеет абсолютно новый алгоритм выявления видеоматериала, неимеющий на данный момент аналогов, как в СНГ так и в мировом сообществе.
Планируемые практические результаты
В ходе магистерской работы планируется разработка автоматизированной системы распознавания образов. Ее основными задачами будет:
- Формирование набора исходных данных
- Представление полученного набора исходных данных, как результат измерений для подлежащего распознаванию объекта
- Классификация и идентификация объекта с использованием оптимальной решающей процедуры
- Поиск и удаления видеофайлов идентифицированных как равнозначные или очень похожие
В результате планируется получить web-приложение, которое будет реализовано с использованием нескольких технологиий:
- PHP - эта технология используеться для построения серверных страниц с динамически формируемой информацией хранящейся в БД.
- MYSQL - база данных которая будет хранить как результаты работы, так и результаты класификации объектов.
- JavaScript - будет использоваться для повышения удобства пользовательского интерфейса системы
- С++ - разрабатываемая библиотека, которая будет выполняться на веб-сервере Appache с использованием библиотек FastCGI . Использование компилированного кода позволит во много раз ускорить работы системы.
Обзор исследований и разработок по теме
По результатам поиска среди материалов портала магистров ДонНТУ были найдены работы схожие по решаемым задачам, но, однако среди них как выбранные методы решения, так и областью применения с данной работой существенно отличаются. Их разработали:
Исаенко А. П.,
Дрига К. В.,
Сова А. А..
Хотя в Украине и в данный момент не были разработаны производственные системы распознавания образов. В Российской федерации данный рынок IT решений. Многие специалисты и различные компании разрабатывают системы распознавания образов для решения различных задач, особое внимание заслужили: Вахитов А. с разработкой системы видеонаблюдения , компания “Малленом” с разработкой системы “Видеонаблюдение на транспорте”
За рубежом разработкой системы распознавания образов занимаеться крупные компании, такии как: Philips, Sony, Samsung, Lexus, Toyota, Siemens.В разрабатываемых системах существенно отличаются области применения, главная цель систем снижение ошибок связанных с человеческим фактором и решение задач ранее решаемых только человеком.
Решение задач исследования
Задача Формирование набора исходных данных
Данная задача представляет начальный этап работы системы. На данном этапе происходит захват серии кадров видеофильма в заданных временных интервалах в конце сцен. (рис. 1)
 Рисунок 1 - Захват кадров видеоматериала
Рисунок 1 - Захват кадров видеоматериала
Затем захваченные изображения приводится к единому разрешению, например 700x400(рис. 2а). Это необходимо, так как различные
видеоролики могут быть обрезаны, уменьшены или увеличены третьими лицами или их разрешение может не соответствовать рабочему.
Далее кадр переводится в градации серого(рис. 2б) необходимость преобразования к серому заключается как в экономии места хранения результатов измерения(один пиксель изображения может кодироваться 1 байтом информации, значение серого от (0..255), так
и в исключении возможности использования различных цветовых пространств кодирования видеоматериала. Затем
кадр нормализуется (рис. 2в) и размывается алгоритмом размытия по Гауссу (рис. 2г). Данные действия
исправляют как артефакты сжатия, так и выравнивание неравномерно распределенных уровней изображения.
 Рисунок 2 - А-Обрезка 700x400, Б-Перевод в градации серого, В-Нормализация изображения, Г- размытие по Гауcсу
Рисунок 2 - А-Обрезка 700x400, Б-Перевод в градации серого, В-Нормализация изображения, Г- размытие по Гауcсу
Задача представления исходных данных
Задача представления исходных данных, подразумевает получение результатов измерений подлежащих распознаванию объекта. Каждая измеренная величина является некоторой "характеристикой" образа или объeкта. В данной системе 1 кадр состоит из 64 образов. Каждый образ это 1/64 часть равномерно разделенного изображения. Процесс разделения изображения представлен на (рис 3). [1][2][3]
 Рисунок 3 - Процесс получения образца
Рисунок 3 - Процесс получения образца
Анимация:объем – 100 КБ; размер – 216х173; количество кадров – 50;
количество циклов повторения – бесконечное
В таком случае в датчике может быть успешно использована измерительная сетчатка, подобно приведенной на рис 4. Если сетчатка состоит из матрицы (m,n) элементов, то результаты измерений можно представить в виде матрицы образа. [1]
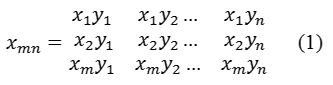 Рисунок 4 -Представление результатов измерений
Рисунок 4 -Представление результатов измерений
где каждый элемент Xmn, принимает, например, значение [0,255] (1 byte). Как уже упоминалось преобразование в градацию серого позволило кодировать пиксель изображение 1 байтом. [6][7]
Классификация и идентификация объекта с использованием оптимальной решающей процедуры
После того как все данные во всех классах собраны и представлены собранные о подлежащих распознаванию образах, представлены точками. Выполним алгоритм соответствия кадров (рис. 5) . Если в результате сравнения коэфициент соответствие составил более 0.7 можно утверждать что данные видеозаписи одинаковые. [10][12]
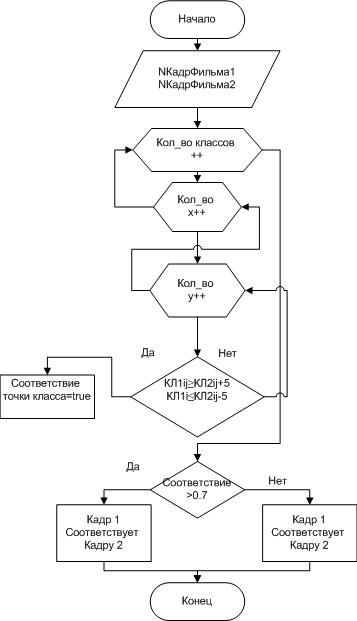 Рисунок 5 - Алгоритм
Рисунок 5 - Алгоритм соответствия кадров.
Вывод
Высокая степень дублирования видеоматериалов, располагающихся на серверах, приводит к их излишней загруженности. Т.о., задача определения и удаления схожих видеоматериалов является актуальной.
Сделано предположение, что сравнение видеоматериалов на похожесть наиболее логично производить на основании сравнения кадров, взятых из этих видеоматериалов преобразованных особым образом таким как: переводом к градациям серого, нормализации и фильтрации изображения, для того чтобы увеличить точность распознавания.
Выделены группы методов, способных решать данную задачу. Предлагается использовать метод, использующий теорию распознавания образов, основанный на исследовании свойств разделенного на части изображения.
Предложенный алгоритм решения задачи позволит, значительно сократить объемы дискового пространства, тем самым позволив уменьшить затраты компаний предоставляющих услуги видеохостинга, что повысит эффективность их работы.
Список использованной литературы
-
Распознавание образов - применение на практике.
-
Сайт о распознавании образов
-
Распознавание образов и анализ сцен
-
Архитектура YouTube
-
Википедия. Краткая информация об многих технологиях
-
Pattern Recognition. Finding and Recognizing Patterns in Data
-
Системы распознавания образов
-
Image-Based Face Recognition Algorithms
-
Лапонина О.Р. Криптографические основы безопасности. Лаборатория знаний, Интернет-университет информационных технологий. М.: Бином, 2009. — 536 c.
-
Рутковская Д., Пилиньский М., Рутковский Л.
Нейронные сети, генетические алгоритмы и нечеткие системы.
М.: Горячая линия -Телеком, 2006. - 452 с
-
Колерс П., Мюррей Д. Распознавание образов. М.: Мир, 1970. - 288 с.
-
Эдвард А. Патрик
Основы теории распознавания образов. М. : "Советское радио", 1980.- 864 с.
При написании данного автореферата магистерская работа еще не завершена. Дата окончательного завершения работы: декабрь 2011 г. Полный текст работы и материалы по теме могут быть получены у автора или его научного руководителя после указанной даты.

