
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Научная и практическая значимость
- 2. Обзор исследований обучения с подкреплением в мире
- 3. Формализация задачи управления автономным агентом в анимат-подобной среде
- 4. Анализ различных алгоритмов Q-обучения для оптимизации управления автономным агентом
- 5. Экспериментальные исследования
- Выводы
- Список литературы
Введение
Повышение уровня интеллектуальности агентов в настоящее время является одной из важнейших проблем, как для создателей автономных роботов, так и для разработчиков искусственного интеллекта в целом. Задача приспособления к незнакомой окружающей среде для выполнения поставленных целей является наиболее. Такие стандартные методы, как конечные автоматы или экспертные системы с продукционной архитектурой не слишком хорошо подходят для управления агентом в незнакомой среде, особенно если среда является нестационарной [1].
Более подходящим методом является метод обучения с подкреплением. Он позволяет автономному агенту обучаться на основе собственного опыта без вмешательства разработчика. Для управления агентом в динамической среде небольшой и средней размерности хорошо подходит один из вариантов обучения с подкреплением – алгоритм Q-обучения [2].
1. Научная и практическая значимость
Данные исследования могут применяться как в робототехнике, так и в компьютерных играх для разработки персонажей с элементами искусственного интеллекта. Обе отрасли достаточно актуальны на данных момент. Однако достижение оптимальной стратегии поведения в динамической среде – задача недостаточно изученная. Классические методы управления интеллектуальными агентами требуют обучения их программистом, при этом они не достаточно хорошо подходят для изменяющейся во времени среды. Поэтому разработка альтернативных методов является достаточно важной на данный момент [3].
2. Обзор исследований обучения с подкреплением в мире
В настоящее время активные работы в рамках направления Адаптивное поведение
ведутся такими зарубежными исследователями, как Ж.-А. Мейер,
Р. Пфейфер, С. Нолфи,
Р. Брукс, Дж. Эдельман.
В
Росии моделирование адаптивного
поведения ведут только немногие группы исследователей под руководством В.А. Непомнящих,
А.А. Жданова, А.И. Самарина, Л.А. Станкевича [4].
3. Формализация задачи управления автономным агентом в анимат-подобной среде
Среда, в которой производились эксперименты с аниматом в данной работе,
представлена на рисунке 1. Данная среда представляет собой замкнутое
пространство, в которое помещается анимат. Пространство ограничено с четырёх
сторон стеной, в центре которой с каждой стороны есть углубление, содержащее
пищу
. Задача анимата – найти пищу
за наименьшее количество шагов.
На рисунке 1 используются следующие условные обозначения: стена (W), пища
(F)
и пустое пространство(-).
Робот имеет 8 сенсоров, определяющих содержимое смежных с ним ячеек. Таким образом, состояние робота определяется только состоянием соседних ячеек и кодируется по ходу часовой стрелки, начиная с севера.
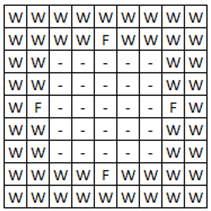
Рис. 1. Анимат-подобная среда
Всего возможно 17 различных состояний робота, учитывая то, что 9 центральных клеток кодируются одним состоянием.
В каждый момент времени анимат может двигаться в одном из 8-ми возможных направлений: 1 – север, 2 – северо – восток , 3 – восток , 4 – юго- восток , 5 – юг, 6 – юго- запад, 7 – запад, 8 – северо – запад.
Принципы взаимодействия робота и среды таковы:
1) если ячейка, в которую перемещается робот, пустая, то среда позволяет ему переместиться в эту ячейку.
2) если ячейка, в которую перемещается робот, содержит стену, то среда не позволяет ему переместиться в эту ячейку и робот получает наказание (отрицательное вознаграждение).
3) если ячейка, в которую перемещается робот, содержит пищу
, то среда
позволяет роботу в неё переместиться и робот получает вознаграждение.
4. Анализ различных алгоритмов Q-обучения для оптимизации управления автономным агентом
Алгоритм Q-обучения был предложен Воткинсом (Watkins) в 1989 году [5].
Данный алгоритм работает с Q-функцией, аргументами которой являются состояние и действие. Это позволяет итерационным способом построить Q-функцию и тем самым найти оптимальную политику управления. Целью обучения является максимизация награды r. Выражение для обновления Q-функции имеет следующий вид:
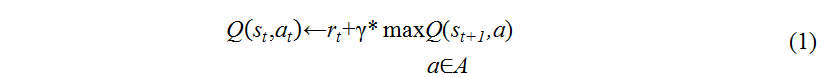
Оценки Q-значений хранятся в 2-х мерной таблице, входами которой являются состояние и действие.
Существует два вида алгоритма Q-обучения – алгоритм интерактивного обучения и алгоритм обратного переигрывания [6].
В алгоритме интерактивного обучения, подстройка Q-значений таблицы производится после каждого действия анимата. Таким образом, при одной итерации на текущее подстраивание Q-значения влияет только значение Q-фактора следующего состояния. Это может оказаться минусом, т.к. для нахождения длинных стратегий может потребоваться много итераций. Однако интерактивное обучение позволяет менять свое поведение сразу после выполнения определенных действий. Алгоритм интерактивного обучения описан на рисунке 2.

Рис. 2. Алгоритм интерактивного Q-обучения
При использовании алгоритма обратного переигрывания, обновление Q-значений производится только после того, как агент достигнет поглощающего состояния (нахождение пищи). Поэтому агент после каждого шага должен запоминать текущее состояние, выбранное действие и непосредственную награду. После достижения агентом поглощающего состояния, у него должен быть сформирован список всех совершенных переходов. Этот список прокручивается в обратном порядке и осуществляется коррекция Q-функции. Алгоритм описан на рисунке 3.

Рис. 3. Алгоритм Q-обучения с обратным переигрыванием
Алгоритм обратного переигрывания отличается от алгоритма интерактивного обучения тем, что на каждую подстройку Q-значения влияют все последующие значения Q-фактора, что позволяет находить оптимальную стратегию за меньшее количество итераций.
5. Экспериментальные исследования
Среда, в которой производятся эксперименты, является немарковской, или принадлежит к классу 2 по классификации, используемой Вильсоном в [7], т. к. данных сенсорного входа не всегда достаточно для однозначного определения действия, которое должен совершить робот в направлении ближайшей “пищи”. Это происходит потому, что в центре данной среды имеется пустое пространство, и, находясь в одной из 9-ти центральных ячеек, робот получает одинаковую сенсорную информацию.
Исследования проводились в среде, описанной в разделе Формализация задачи
управления автономным агентом в анимат-подобной среде
. Для обучения
использовались коэффициенты обучения γ=0.02 и λ=0.9.
Критерием оценки качества обучения агента будет служить сумма шагов от начальной
точки до пищи с каждой клетки пространства. Минимальная такая сумма составит 46
шагов. Схема переходов при минимальном количестве шагов изображена на рисунке 4.
В этом случае, максимальное расстояние от начального положения до пищи
составит 5 шагов.
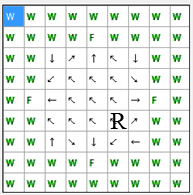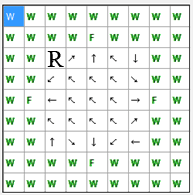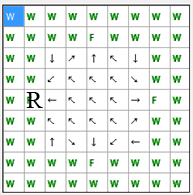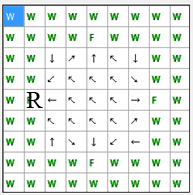
Рис. 4. Схема переходов при минимальном количестве шагов до пищи
(анимация: объем – 13.0 КБайт, количество кадров – 9, количество циклов повторов – 5, размер – 193 х 195)
График, показывающий зависимость суммы переходов к пище
от количества
обучающих итераций для обоих алгоритмов изображен на рисунке 5.

Рис. 5. Сравнение эффективности обучения алгоритмов обратного переигрывания и интерактивного обучения
Как видно из графика, оба алгоритма обучения позволяют достичь стратегии поведения, близкой к оптимальной, уже на 50 итерации. Оптимальной стратегии оба алгоритма достигают при 200 итераций.
Выводы
При сравнении двух алгоритмов Q-обучения – обратного переигрывания и интерактивного обучения – оказалось, что оба они достаточно эффективны для обучения агента достижению цели в незнакомой среде. И алгоритм обратного переигрывания, и алгоритм интерактивного обучения сходятся к оптимальному поведению за достаточно небольшое количество итераций.
Список источников
1. Пocпeлoв
С.М., Бoндаренкo И.Ю. Анализ проблем моделирования интеллектуального поведения
персонажей в компьютерных играх // Сб. тр. междунар. научно-техн. конференции
Информатика и компьютерные технологии 2010
. – Донецк: ДонНТУ. – 2010
2. Р. С. Саттон, Э. Г. Барто. Обучение с подкреплением. –М. Бином. – 2012, 400 с.
3. Д. Борн. Искусственный интеллект: в чём загвоздка? // 3DNews Daily Digital Digest [Электронный ресурс]. – Режим доступа: URL: http://www.3dnews.ru/news/iskusstvennii_intellekt_v_chshm_zagvozdka/
4. Мосалов О.П. Модели адаптивного поведения на базе эволюционных и нейросетевых методов. –М. Бином. – 2007, 110 с.
5. Watkins, C., Dayan P., “Q-Learning”, // In: Machine Learning 8, Kluwer Academic Publishers, Boston, 1992 – pp. 279-292.
6. Пocпeлoв
С.М., Бoндаренкo И.Ю. Разработка модели интеллектуального поведения персонажа в
компьютерной игре robocode на основе метода нейродинамического программирования.
// Сб. тр. междунар. научно-техн. конференции Информационные управляющие
системы и компьютерный мониторинг 2011
. – Донецк: ДонНТУ. – 2011
7. Wilson S. W., “The Animat Path to AI. // In: From Animals to Animats: Proceeding of the First International Conference on the Simulation of Adaptive Behavior, Cambridge, MA: The MIT Press/Bradford Books, 1991.