
Реферат за темою випускної роботи
Зміст
- Вступ
- 1. Наукова і практична значимість
- 2. Огляд досліджень навчання з підкріпленням у світі
- 3. Формалізація задачі управління автономним агентом в анімат-подібному середовищі
- 4. Аналіз різних алгоритмів Q-навчання для оптимізації управління автономним агентом
- 5. Експериментальні дослідження
- Висновок
- Список літератури
Вступ
Підвищення рівня інтелектуальності агентів нині є однією з найважливіших проблем, як для творців автономних роботів, так і для розробників штучного інтелекту в цілому. Завдання пристосування до незнайомого навколишнього середовища для виконання поставлених цілей є найбільш актуальною. Такі стандартні методи, як кінцеві автомати або експертні системи з продукційної архітектурою, не дуже добре підходять для управління агентом в незнайомому середовищі, особливо якщо середовище нестаціонарне [1].
Більш придатним методом є метод навчання з підкріпленням. Він дозволяє автономному агенту навчатися на основі власного досвіду без втручання розробника. Для управління агентом в динамічному середовищі невеликої та середньої розмірності добре підходить один з варіантів навчання з підкріпленням - алгоритм Q-навчання [2].
1. Наукова і практична значимість
Дослідження можуть застосовуватися як в робототехніці, так і розробниками штучного інтелекту в комп'ютерних іграх. Обидві галузі досить актуальні на даних момент. Проте досягнення оптимальної стратегії поведінки в динамічному середовищі – завдання недостатньо вивчене. Класичні методи управління інтелектуальними агентами вимагають навчання їх програмістом, при цьому вони не підходять для мінливого в часі середовища. Тому розробка альтернативних методів є досить важливою на даний момент [3].
2. Огляд досліджень навчання з підкріпленням у світі
В даний час активні роботи в рамках напрямку Адаптивне поводження
ведуться
такими зарубіжними дослідниками, як Ж.-А. Мейер, Р. Пфейфер, С. Нолфі, Р. Брукс,
Дж. Едельман. У Росії моделювання адаптивної поведінки ведуть лише окремі групи
дослідників під керівництвом В.А. Непомнящих, А.А. Жданова, А.І. Самаріна, Л.А.
Станкевича
[4].
3. Формалізація задачі управління автономним агентом в анімат-подібному середовищі
Середовище, в якому здійснювалися експерименти з аніматом у даній роботі,
представлена на рисунку 1. Дане середовище уявляє собою замкнутий простір, в
яку міститься анімат. Простір обмежений з чотирьох сторін стіною, у центрі якої
з кожної сторони є поглиблення, що містить їжу
. Завдання анімата – знайти їжу
за найменшу кількість кроків.
На рисунку 1 використовуються наступні умовні позначення: стіна (W), їжа
(F) і
порожній простір (-).
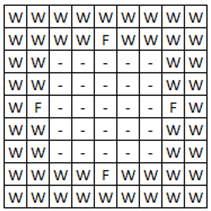
Рис. 1. Анімат-подібне середовище
Усього можливо 17 різноманітних станів робота, враховуючи те, що 9 центральних клітин кодуються одним станом.
У кожен момент часу анімат може рухатися в одному із 8-ми можливих напрямків: 1 – північ, 2 – північний схід, 3 – схід, 4 – південний схід, 5 – південь, 6 – південний захід, 7 – захід, 8 – північний захід.
Принципи взаємодії робота і середовища такі:
1) якщо осередок, до якої рухається робот, порожня, то середовище дозволяє йому переміститися в цей осередок.
2) якщо осередок, до якої рухається робот, містить стіну, то середовище не дозволяє йому переміститися в цей осередок і робот отримує покарання (негативну винагороду).
3) якщо осередок, до якої рухається робот, містить їжу
, то середовище дозволяє
роботу до нього переміститися і робот отримує винагороду.
4. Аналіз різних алгоритмів Q-навчання для оптимізації управління автономним агентом
Алгоритм Q-навчання був запропонований Воткінсом (Watkins) у 1989 році [5].
Даний алгоритм працює з Q-функцією, аргументами якої є стан і дія. Це дозволяє ітераційним чином побудувати Q-функцію і тим самим знайти оптимальну політику управління. Метою навчання є максимізація нагороди r. Вираз для поновлення Q-функції має наступний вигляд:

Оцінки Q-значень зберігаються в 2-х мірній таблиці, входами якої є стан і дія.
Існує два види алгоритму Q-навчання – алгоритм інтерактивного навчання і алгоритм зворотнього перегравання [6].
В алгоритмі інтерактивного навчання, підстроювання Q-значень таблиці проводиться після кожної дії анімата. Таким чином, при одній ітерації на поточне підстроювання Q-значення впливає тільки значення Q-фактора наступного стану. Алгоритм інтерактивного навчання описаний на рисунку 2.

Рис. 2. Алгоритм інтерактивного Q-навчання
При використанні алгоритму зворотнього перегравання, оновлення Q-значень здійснюється тільки після того, як агент досягне поглинаючого стану (знаходження їжі). Алгоритм описаний на рисунку 3.

Рис. 3. Алгоритм Q-навчання зі зворотним переграванням
Алгоритм зворотнього перегравання відрізняється від алгоритму інтерактивного навчання тим, що на кожне підстроювання Q-значення впливають всі наступні значення Q-фактора, що дозволяє знаходити оптимальну стратегію за меншу кількість ітерацій.
5. Експериментальні дослідження
Середовище, у якому здійснюються експерименти, є немарківським, або належить до класу 2 по класифікації, що використовується Вільсоном в [7], тому що даних сенсорного входу не завжди достатньо для однозначного визначення дії, що має здійснити робот до напрямку найближчої "їжі" . Це відбувається тому, що до центрі даного середовища є порожній простір, і, знаходячись в одній із 9-ти центральних осередків, робот отримує однакову сенсорну інформацію.
Дослідження проводилися у середовищі, описаній у розділі Формалізація задачі
управління автономним агентом у анімат-подібному середовищі
. Для навчання
використовувалися коефіцієнти навчання γ = 0.02 і λ = 0.9.
Критерієм оцінювання якості навчання агента буде служити сума кроків від
початкової точки до їжі з кожної клітини простору. Мінімальна така сума
складатиме 46 кроків. Схема переходів при мінімальній кількості кроків зображена
на рисунку 4. В цьому випадку, максимальна відстань від початкового положення до
їжі
складе 5 кроків.
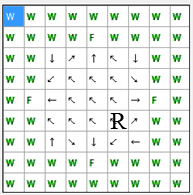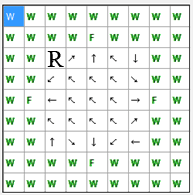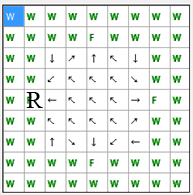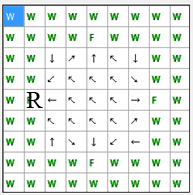
Рис. 4. Схема переходів при мінімальній кількості кроків до "їжі" (анімація: обсяг – 13.0 КБайт, кількість кадрів – 9, кількість циклів повтору – 5, розмір – 193 х 195)
Графік, що показує залежність суми переходів до їжі
від кількості навчальних
ітерацій для обох алгоритмів зображений на рисунку 5.
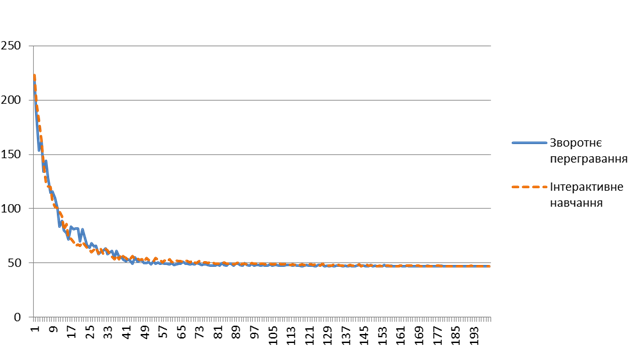
Рис. 5. Порівняння ефективності навчання алгоритмів зворотнього перегравання та інтерактивного навчання
Як видно з графіка, обидва алгоритма навчання дозволяють досягти стратегії поведінки, близької до оптимальної, вже на 50 ітерації. Оптимальної стратегії обидва алгоритму досягають при 200 ітерацій.
Висновок
Під час порівняння двох алгоритмів Q-навчання – зворотнього перегравання та інтерактивного навчання – виявилося, що обидва вони достатньо ефективні для навчання агента досягненню мети у незнайомому середовищі. І алгоритм зворотнього перегравання, і алгоритм інтерактивного навчання сходяться до оптимального поведінки за досить невелику кількість ітерацій.
Список літератури
1. Пocпeлoв
С.М., Бoндаренкo И.Ю. Анализ проблем моделирования интеллектуального поведения
персонажей в компьютерных играх // Сб. тр. междунар. научно-техн. конференции
Информатика и компьютерные технологии 2010
. – Донецк: ДонНТУ. – 2010
2. Р. С. Саттон, Э. Г. Барто. Обучение с подкреплением. –М. Бином. – 2012, 400 с.
3. Д. Борн. Искусственный интеллект: в чём загвоздка? // 3DNews Daily Digital Digest [Электронный ресурс]. – Режим доступа: URL: http://www.3dnews.ru/news/iskusstvennii_intellekt_v_chshm_zagvozdka/
4. Мосалов О.П. Модели адаптивного поведения на базе эволюционных и нейросетевых методов. –М. Бином. – 2007, 110 с.
5. Watkins, C., Dayan P., “Q-Learning”, // In: Machine Learning 8, Kluwer Academic Publishers, Boston, 1992 – pp. 279-292.
6. Пocпeлoв
С.М., Бoндаренкo И.Ю. Разработка модели интеллектуального поведения персонажа в
компьютерной игре robocode на основе метода нейродинамического программирования.
// Сб. тр. междунар. научно-техн. конференции Информационные управляющие
системы и компьютерный мониторинг 2011
. – Донецк: ДонНТУ. – 2011
7. Wilson S. W., “The Animat Path to AI. // In: From Animals to Animats: Proceeding of the First International Conference on the Simulation of Adaptive Behavior, Cambridge, MA: The MIT Press/Bradford Books, 1991.