
Abstract
Content
- Introduction
- 1. Survey of research and developments
- 2. Review of research reinforcement learning in the world
- 3. Formalization of autonomous agent control problem in animat-like environment
- 4. Analysis of the various Q-learning algorithms for optimizing the management of autonomous agent
- 5. Experimental researches
- Conclusion
- References
Introduction
Improving intellectuality of agents now is a major problem, both for the creators of autonomous robots, and for developers of artificial intelligence . The task of adapting to an unfamiliar environment for the most goals. Such standard techniques as finite state machines or expert systems with product architecture dis not very well suited for agent control in an unfamiliar environment, especially if the environment is nonstationary [1].
More suitable method is a method of reinforcement learning. It allows an autonomous agent to learn from their own experience without the intervention of the developer. For controlling agent in a dynamic environment, small and medium-scale is well suited one of the variants of reinforcement learning – Q-learning algorithm [2].
1. Survey of research and developments
The research can be used both in robotics and the developer of artificial intelligence in computer games. Both the industry enough actual at the moment. However, achieving the optimal strategy of behavior in a dynamic environment – a problem not enough studied. Classical methods of intelligent agents require training by computer programmer, and they are not suitable for time-varying environment. Therefore, the development of alternative methods is important enough at the moment [3].
2. Review of research reinforcement learning in the world
Now active work in the direction of "adaptive behavior" conducted by foreign researchers such as JA Meyer, R. Pfeiffer, S. Nolfi, R. Brooks, and J. Edelman. In Russia modeling of adaptive behavior lead only a few groups of researchers led by V.A. Nepomnyashchikh, A.A. Zhdanov, A. Samarin, L.A. Stankevich [4].
3. Formalization of autonomous agent control problem in animat-like environment
The environment in which were carried out experiments with the animat in this paper presented in Figure 1. This environment is a closed space in which the animat placed. Space is limited from four sides of wall in the center of each side of which is hollow, containing "food". The task of animat – to find "food" for the least amount of steps.
Figure 1 uses the following notation: the wall (W), food
(F) and the empty
space (-).
Robot has 8 sensors that determine the contents of adjacent cells. Thus, the state of the robot is determined only by the state of neighboring cells and coded clockwise, starting from the north.
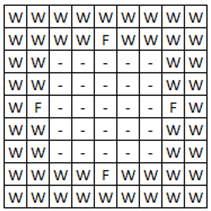
Fig. 1. Animat-like environment
In total 17 different possible states of the robot, given the fact that nine central cells are encoded by a single state.
At any time, animat can move in one of 8 possible directions: 1 – north 2 – north – east, 3 – east, 4 – south-east, 5 – south, 6 – south-west, 7 – west 8 – north - west.
The principles of interaction between the robot and environment are follows:
1) if the cell in which the robot moves, is empty, the environment allows it to move into the cell.
2) if the cell in which the robot moves, has a wall, the environment does not allow it to move into the cell and the robot gets punishment (negative reward).
3) If the cell in which the robot moves, contains "food", the environment allows the robot to move into it and the robot gets a reward.
4. Analysis of the various Q-learning algorithms for optimizing the management of autonomous agent.
Q-learning algorithm was proposed by Watkins (Watkins) in 1989 [5].
This algorithm works with the Q-function which arguments are the state and action. This allows an iterative method to construct the Q-functionand thereby find the optimal control policy. The purpose of learning is to maximize the reward r. Expression for updating the Q-function has the following form:
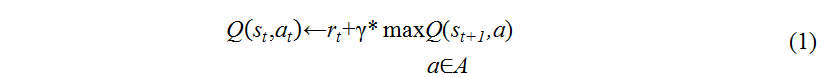
Ratings of Q-values are stored in two-dimensional table, the inputs of which are state and action.
There are two types of the Q-learning – interactive learning algorithm and back-propagation algorithm [6].
In the interactive learning algorithm, Q-value adjustment of the table made after each action of animat. Thus, in one iteration to the current Q-value adjustment to influences only the value of Q-factor of the next state. The algorithm is described interactive learning in Figure 2.
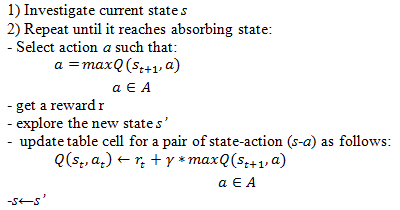
Fig. 2. Interactive algorithm of Q-learning
When using the back-propagation algorithm, updating Q-values performed only after the agent reaches the absorbing state (finding food). The algorithm described in Figure 3.

Fig. 3. Back-propagation Q-learning algorithm
5. Experimental researches
The environment in which experiments was made, is a non-Markov, or belongs to a class 2 according to the classification used by Wilson in [7], because the sensory input data is not always sufficient to uniquely determine the action that should make the robot in the direction of the nearest "food" .This is because in the center of the environment is empty space, and if the robot is in one of the 9 central cells, it receives the same sensory information.
Researches were conducted in an environment described in the section "Formalization of autonomous agent control problem in animat-like environment". The learning rates γ = 0.02 and λ = 0.9 used for training.
The criteria for assessing the quality of training agent will provide the amount of steps from start point to the food from each cell. The minimum amount of this steps is 46. The scheme of transitions with a minimum number of steps shown in Figure 4. In this case, the maximum distance from the initial position to the "food" – 5 steps.
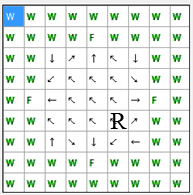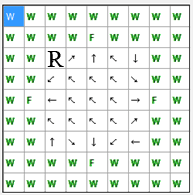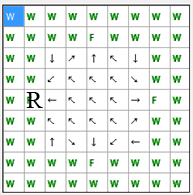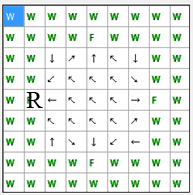
Fig. 4. The scheme of transitions with a minimum number of steps to the "food" (animation: file size – 13.0 КBytes, the number of images – 9, the number of repeat – 5, size – 193 х 195)
The dependence of the sum of transitions to the "food" on the number of training iterations for both algorithms is shown in Figure 5.
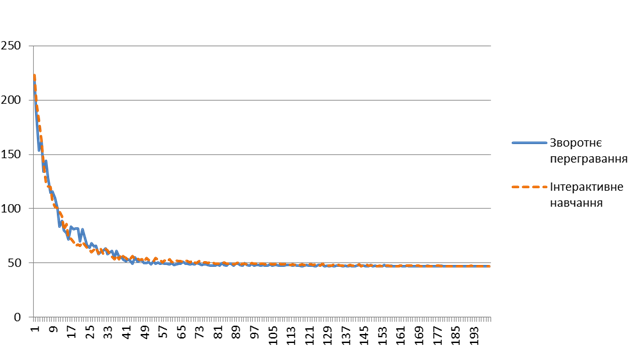
Fig. 5. Comparison of the effectiveness of back-propagation learning algorithm and interactive learning.
As can be seen from the graph, both algorithms can achieve learning behavior strategy, which is close to optimal already for 50 iterations. The optimal strategy for both algorithms reach at 200 iterations.
Conclusion
Comparing the two algorithms of Q-learning – back-propagation algorithm and interactive learning algorithm – it turned out that both of them enough effective for learning agent the goal in a strange environment. Both of back-propagation algorithm and algorithm of interactive learning converge to the optimal behavior in a relatively small number of iterations.
References
1. Пocпeлoв
С.М., Бoндаренкo И.Ю. Анализ проблем моделирования интеллектуального поведения
персонажей в компьютерных играх // Сб. тр. междунар. научно-техн. конференции
Информатика и компьютерные технологии 2010
. – Донецк: ДонНТУ. – 2010
2. Р. С. Саттон, Э. Г. Барто. Обучение с подкреплением. –М. Бином. – 2012, 400 с.
3. Д. Борн. Искусственный интеллект: в чём загвоздка? // 3DNews Daily Digital Digest [Электронный ресурс]. – Режим доступа: URL: http://www.3dnews.ru/news/iskusstvennii_intellekt_v_chshm_zagvozdka/
4. Мосалов О.П. Модели адаптивного поведения на базе эволюционных и нейросетевых методов. –М. Бином. – 2007, 110 с.
5. Watkins, C., Dayan P., “Q-Learning”, // In: Machine Learning 8, Kluwer Academic Publishers, Boston, 1992 – pp. 279-292.
6. Пocпeлoв
С.М., Бoндаренкo И.Ю. Разработка модели интеллектуального поведения персонажа в
компьютерной игре robocode на основе метода нейродинамического программирования.
// Сб. тр. междунар. научно-техн. конференции Информационные управляющие
системы и компьютерный мониторинг 2011
. – Донецк: ДонНТУ. – 2011
7. Wilson S. W., “The Animat Path to AI. // In: From Animals to Animats: Proceeding of the First International Conference on the Simulation of Adaptive Behavior, Cambridge, MA: The MIT Press/Bradford Books, 1991.