
Реферат за темою випускної роботи
Зміст
- Вступ
- 1. Актуальність теми
- 2. Мета і завдання дослідження та заплановані результати
- 3. Дискретна марківська модель кластера без надавання доступу до ресурсів
- Висновки
- Перелік посилань
Вступ
У сучасному світі існує велика кількість завдань, що потребують застосування потужних обчислювальних систем (ОС).
Одним із прикладів обчислювальних систем із розподільною обробкою є кластери [1–4]. Кластерні обчислювальні системи за критерієм спільного використання дискового простору класифікуються наступним чином: із спільним використанням дискового простору та и без надавання доступу до ресурсів [2].
Під час проектування та експлуатації розподільних ОС виникає проблема раціонального використання ресурсів обчислювального середовища. Для ефективного розв’язання цієї проблеми використовуються безперервні [5–7] або дискретні аналітичні моделі [8], та для кожного класу розв’язуваних завдань визначаються основні параметри обчислювального середовища.
Безперервні моделі є менш трудомісткими та використовуються для складного класу досліджуваних структур. Дискретна модель Маркова, у порівнянні з безперервною – більш точно відображає роботу обчислювального середовища та дозволяє ефективно розпаралелювати обчислювальні структури [9].
Аналіз кластерних систем за допомогою дискретної моделі під час розв’язання на ОС великої кількості завдань потребує великих часових витрат, так як кількість станів дискретної марківскої моделі комбінаторно збільшується під час збільшення кількості завдань.
1. Актуальність теми
У теперішній час одним із головних напрямків у провідних країнах світу є створення і застосування сучасних суперкомп’ютерів. Розвиток паралельних обчислювальних систем обумовлений необхідністю ефективно розв’язувати завдання великої розмірності. Ефективність використання обчислювальних систем залежить не тільки від продуктивності процесорів, що входять до складу системи, а і від пропускної спроможності її каналів зв’язку. Тому однією із найбільш важливих завдань є аналіз ефективності функціонування багатопроцесорних систем.
Завдяки розвитку обчислювальних систем з’явилися такі завдання як збалансованість навантаження, визначення вузьких місць в обчислювальній системі, забезпечення заданого часу відповіді при роботі великої кількості користувачів і т.д.
Роботи в області паралельних обчислювальних структур є актуальними та потребують подальшого розвитку у зв’язку з великою кількістю створюваних суперкомп’ютерів.
Розроблений апарат аналітичного моделювання обчислювальних структур дозволяє проектувати паралельні структури для розв’язання завдань великої розмірності, які не можуть бути ефективно реалізованими на однопроцесорних ЕОМ.
Дослідження, проведені у магістерській роботі, направлені на аналіз, підвищення ефективності, оптимізацію кластерних систем.
2. Мета і задачі дослідження та заплановані результати
Мета роботи полягає у розробці методів підвищення ефективності функціонування кластерних систем на основі використання результатів аналітичних моделей з урахуванням відповідності класу розв’язуваних завдань вибраної топології кластера.
Задачі дослідження:
- розробка марківської моделі функціонування кластерних систем та вдосконалення існуючих методів розрахунку основних характеристик функціонування кластерних систем;
- розробка паралельного алгоритму марківської моделі функціонування кластерних систем з урахуванням особливостей їх структури та класу розв’язуваних завдань.
Об’єктом дослідження є кластерна система без надавання доступу до ресурсів.
Предметом дослідження є аналітичні моделі аналізу високопродуктивних обчислювальних систем.
Методи дослідження. Розв’язання сформульованих у магістерській роботі завдань базується на використанні методів теорії випадкових процесів, обчислювальної математики, теорії графів. Перевірку отриманих результатів планується здійснити шляхом проведення обчислювальних експериментів на обчислювальних структурах у системах імітаційного моделювання.
3. Дискретна марківська модель кластера без надавання доступу до ресурсів
В даній моделі кожен вузол у кластері має свою власну пам’ять, усі вузли використовують дискову підсистему. Вузли у кластері звертаються до дискової підсистеми за допомогою системної шини. Обчислювальні завдання рівномірно розподіляються серед декількох об’єднаних у мережу комп’ютерів.
У спрощеній структурі кластера без надавання доступу до ресурсів (див. рис. 1) час передачі даних (див. рис. 2) за допомогою шини включили до часу обслуговування на серверах та дисках, відповідно. Структура складається з M робочих станцій користувачів, N1 серверів, виконуючих різноманітні прикладення, N2 дисків, на яких зберігається база даних.
Уявимо сервери та диски прикладами, час обслуговування яких має геометричне розподілення із середнім параметром qi (i=1,…,N1+N2+1) – ймовірністю завершення обслуговування заявки (відповідно, ri=1-qi – ймовірність продовження обслуговування заявки).
Керуючий сервер розподіляє заявки кожного з
М користувачів із ймовірністю 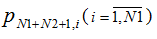 надсилає запит до одного з N1 серверів,
які, у свою чергу, обробляючи цей запит звертаються до одного з N2 дисків з ймовірністю
надсилає запит до одного з N1 серверів,
які, у свою чергу, обробляючи цей запит звертаються до одного з N2 дисків з ймовірністю
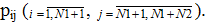
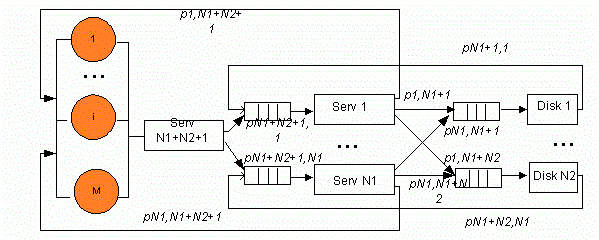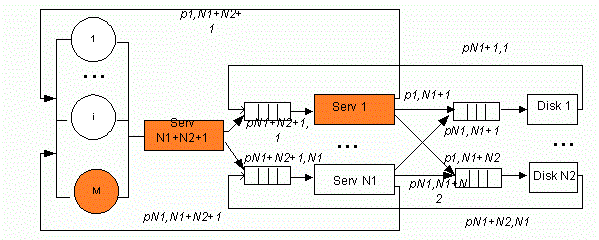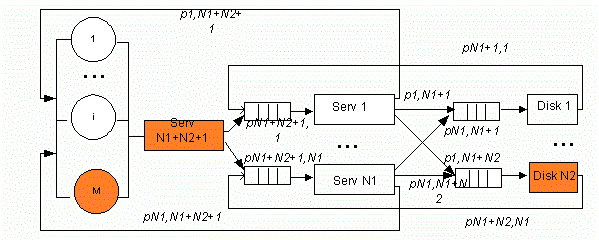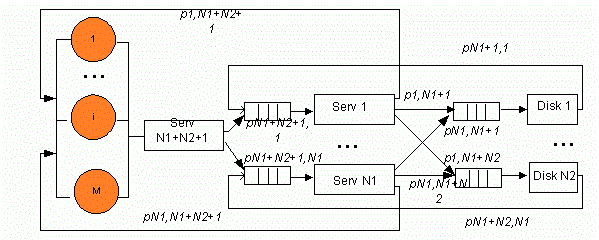
Рисунок 1 – Структурна схема кластера без надавання доступу до ресурсів (Анімація: кількість кадрів: 9, кількість циклів повторення: 6, розмір: 137 Кбайт)
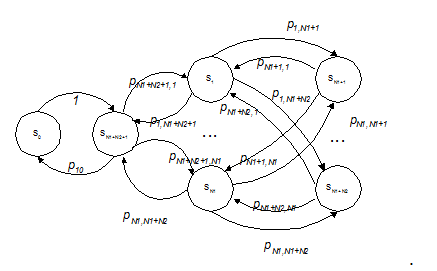
Рисунок 2 – Граф передач моделі кластера без надавання доступу до ресурсів
Для побудови дискретної моделі такої обчислювальної системи визначимо усі можливі стани. За стан системи приймемо розміщення М заявок по N1+N2+1 вузлах
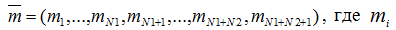 – кількість завдань в i-ім вузлі (усього вузлів N=N1+N2+1). Визначимо множину станів через
– кількість завдань в i-ім вузлі (усього вузлів N=N1+N2+1). Визначимо множину станів через
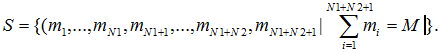 Кількість L усіляких станів системи дорівнює кількості розміщень M завдань по N вузлах и визначається формулою:
Кількість L усіляких станів системи дорівнює кількості розміщень M завдань по N вузлах и визначається формулою:
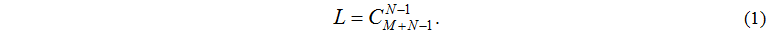
Кількість пристроїв у кожному вузлі задається вектором 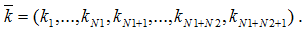
Визначимо перехідні ймовірності для кожної пари станів 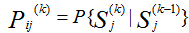 , тобто ймовірності переходу зі стану Si, в котрому вона находилася на (k-1)-м кроці, у стан Sj на k-м кроці.
, тобто ймовірності переходу зі стану Si, в котрому вона находилася на (k-1)-м кроці, у стан Sj на k-м кроці.
Для довільного стану 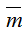 введемо вектор
введемо вектор 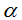 , s-а компонента якого
, s-а компонента якого
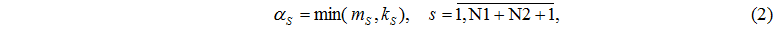
визначає кількість завантажених пристроїв в s-му вузлі обробки завдань. Для визначення можливості переходу з довільного стану у довільний стан
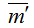 знайдемо вектор
знайдемо вектор
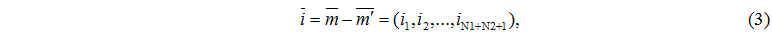
кожна компонента 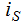 якого являє змінення кількості завдань в s-му вузлі.
Якщо >0, то на розглянутому переході з вузла s повинні піти мінімум
завдань. Якщо < 0, то у вузол s повинні прийти
|| завдань. При будь-якому переході з
кількість завдань, обслугованих s-м вузлом обробки, не може бути більш ніж
якого являє змінення кількості завдань в s-му вузлі.
Якщо >0, то на розглянутому переході з вузла s повинні піти мінімум
завдань. Якщо < 0, то у вузол s повинні прийти
|| завдань. При будь-якому переході з
кількість завдань, обслугованих s-м вузлом обробки, не може бути більш ніж 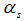 , тобто
, тобто
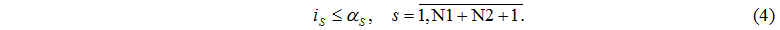
визначимо множину J номерів вузлів обробки, в яких < 0, тобто
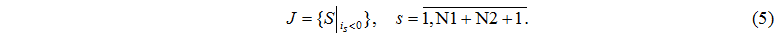
Якщо 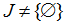 , то величини
, то величини 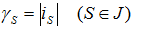 визначають мінімально можливу
кількість програм, які надходять до тих вузлів обробки, номера s яких належать множині J. Кількість програм, що надійшли до
одного з таких вузлів s дорівнює ||. Кількість завдань що надійшли до головного серверу від серверів не може перевищувати кількості працюючих серверів
визначають мінімально можливу
кількість програм, які надходять до тих вузлів обробки, номера s яких належать множині J. Кількість програм, що надійшли до
одного з таких вузлів s дорівнює ||. Кількість завдань що надійшли до головного серверу від серверів не може перевищувати кількості працюючих серверів
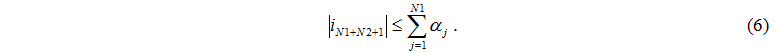
Аналогічно, кількість завдань, що надійшли до дисків від серверів не може перевищувати кількості працюючих серверів
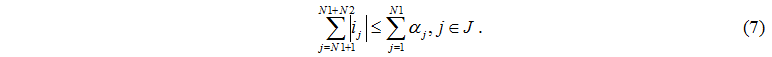
Від серверного вузла завдання надходять і до керуючого сервера, і до дискам, тому загальна кількість завдань що пішли не перевищує кількості працюючих серверів
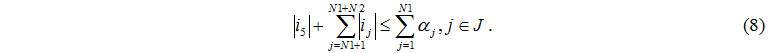
Кількість завдань, що надійшли до серверів не перевищує кількості працюючих дисків та завдання, що надійшло від керуючого сервера
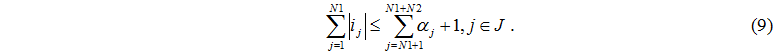
Якщо 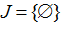 , то
, то 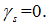
Розглянемо окремий випадок:
N = 5 – кількість пристроїв,
N1 = 2 – кількість обчислювальних серверів
N2 = 2 – кількість дисків
M = 5 – кількість завдань.
Визначимо кількість L усіляких станів системи:
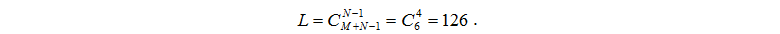
Перехід  можливий, якщо виконуються умови (6-9).
можливий, якщо виконуються умови (6-9).
Розглянемо випадок i5=1 – керуючий сервер завершив обробку одного завдання, отже, обробка потребується на одному із обчислювальних серверів.
Припустимо, інші пристрої продовжують обробку завдань, та обмін не потребується, тоді ймовірність переходу між двома станами:
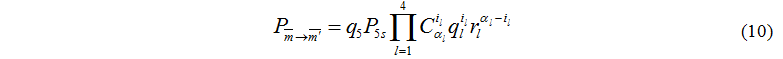
Розглянемо другий варіант, коли i5=1 – керуючий сервер завершив обробку одного завдання, інші пристрої також завершили обробку завдань, отже, необхідно урахувати можливість обміну завданнями між обчислювальними серверами и дисковими пристроями.
Сформулюємо умови формування множини для обміну завданнями:
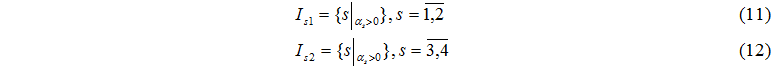
Множина Is1 містить номери обчислювальних серверів, а множина Is2 – номери дисків, які у даному такті можуть завершити обробку завдання.
Обмін може бути здійсненим за умови (13):
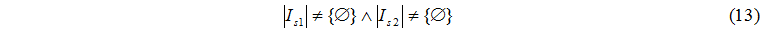
Побудуємо множину подій для обміну завданнями:
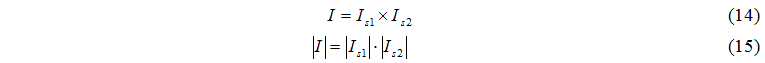
Елемент множини I має наступний вигляд:
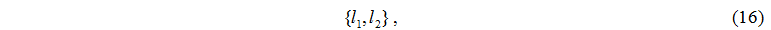
де l1 - номер серверного вузла,
l2 - номер дискового вузла.
тоді ймовірність переходу між двома станами:
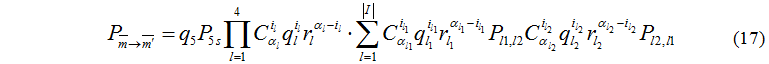
Розглянемо випадок i5=0, можливі три варіанти обміну завданнями:
1) між керуючим сервером та обчислювальними серверами;
2) між обчислювальними серверами та дисковими пристроями;
3) між керуючим сервером та обчислювальними серверами, а також обчислювальними серверами та дисковими пристроями.
Сформулюємо умови формування множини для обміну завданнями:
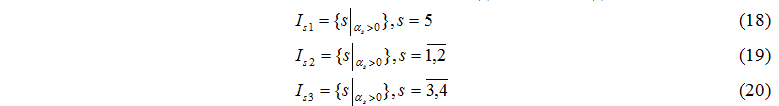
Множина Is1 містить номер керуючого сервера, Is2 – номери обчислювальних серверів, а множина Is3 – номери дисків, які в даному такті можуть завершити обробку завдання.
Обмін може бути здійсненим за умови (21):
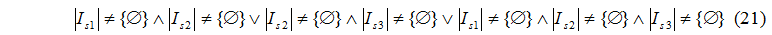
Побудуємо множину подій для обміну завданнями:
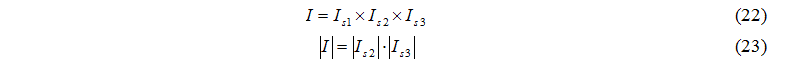
Елемент множини I має наступний вигляд:
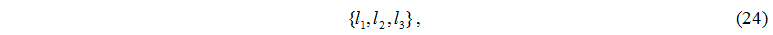
де l1 – номер керуючого сервера,
l2 – номер серверного вузла,
l3 – номер дискового вузла.
Для визначення вектора стаціонарних станів потрібно розв’язати систему лінійних алгебраїчних рівнянь
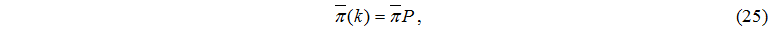
що відповідає розглянутій марківській моделі.
Використовуючи стаціонарні ймовірності можливо розрахувати основні характеристики обчислювального середовища [10]:
Середню кількість зайнятих пристроїв в s-му вузлі визначається формулою:
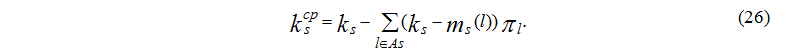
Завантаження пристроїв визначається наступною формулою:
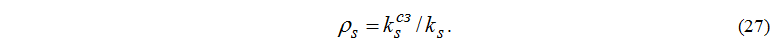
Середню кількість завдань, що знаходяться в s-му вузлі:
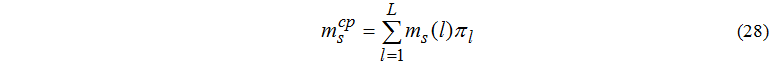
Середню кількість завдань, що знаходяться у черзі до s-го вузла:
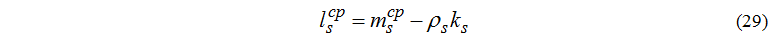
Якщо аналізується певний різновид кластера для розв’язання певного класу завдань, то за допомогою цих характеристик можливо визначити ефективність обчислювального середовища (у залежності від критерія: рівномірне завантаження усіх вузлів, мінімальний час відповіді і т.д.).
Для кластера без надавання доступу к ресурсів (див. рис. 1) побудований паралельний алгоритм дискретної марківської моделі (див. рис. 3).

Рисунок 3 – Схема паралельного алгоритму марківської моделі
Ефективність паралельного алгоритму прагне до одиниці (див. рис. 4) при зростанні розмірності завдання, що свідчить про оптимальність розпаралелювання цих алгоритмів.
Для підбору оптимального коефіцієнта мультипрограмування можливо використовувати методику [11], в якій пропонується критерій збалансованості, складові якого ціні простою обладнання та штраф за затримку виконання запита.
Розглянуті у [11] способи оптимізації складу та структур високопродуктивних ОС можливо використовувати для проектування ОС, причому при більшому коефіцієнті мультипрограмування – тільки чисельним (градієнтним) або з використанням методу середніх.
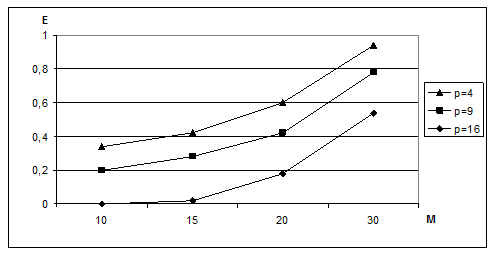
Рисунок 4 – Залежність ефективності паралельного алгоритму від розмірності обчислюваного завдання
Таким чином, використання імовірнісних моделей при проектуванні, експлуатації та оптимізації обчислювальних систем дозволяє виробляти рекомендації з раціонального використання ресурсів цього обчислювального середовища.
Висновки
Розроблена дискретна марківська модель кластерної обчислювальної системи без надавання доступу до ресурсів з обмеженою кількістю завдань, яку можливо використовувати для оцінки ефективності паралельних обчислювальних структур. В тому числі, розраховувати основні характеристики обчислювального середовища: завантаження пристроїв; середню кількість зайнятих пристроїв в s-му вузлі; середню кількість завдань, які знаходяться у черзі до s-го вузла; середній час перебування та очікування в s-му вузлі; середній час перебування й очікування у системі.
Запропонована паралельна реалізація марківської моделі кластерної обчислювальної системи, ефективність якої прагне до одиниці при більшій розмірності завдання.
Перелік посилань
- Шнитман В. Современные высокопроизводительные компьютеры. Информационно-аналитические материалы центра информационных технологий / В. Шнитман [Электронный ресурс]. Режим доступа: http://www.citforum.ru/hardware/svk/contents.shtml.
- Спортак М., Франк Ч., Паппас Ч. и др. Высокопроизводительные сети. Энциклопедия пользователя. – К.:«ДиаСофт», 1998.-432с.
- Corbalan J., Martorell X., Labarta J. Performance-Driven Processor Allocation //IEEE Transactions on Parallel and Distributed Systems, vol. 16, No. 7, July 2005, PP.599-611
- Oleszkiewicz J., Xiao L., Liu Y. Effectively Utilizing Global Cluster Memory for Large Data-Intensive Parallel Programs //IEEE Transactions on Parallel and Distributed Systems, vol. 17, No. 1, Jan. 2006, PP.66-77
- Авен О. И. и др. Оценка качества и оптимизация вычислительных систем. – М.: Наука, 1982,-464с.
- Cremonesi P., Gennaro C. Integrated Performance Models for SPMD Applications and MIMD Architectures //IEEE Transactions on Parallel and Distributed Systems, vol. 13, No. 7, Jul. 2002, PP.745-757
- Varki Е. Response Time Analysis of Parallel Computer and Storage Systems //IEEE Transactions on Parallel and Distributed Systems, vol. 12, No. 11, Nov. 2001, PP.1146-1161
- Клейнрок Л. Вычислительные системы с очередями. – М.:Мир, 1979, 600с. Последовательно - параллельные вычисления: Пер. с англ. - М.: Мир, 1985.-456 с.
- Фельдман Л.П., Михайлова Т.В. Параллельный алгоритм построения дискретной марковской модели /Высокопроизводительные параллельные вычисления на кластерных системах. Материалы четвертого Международного научно-практического семинара и Всероссийской молодежной школы. /Под редакцией член-корреспондента РАН В.А. Сойфера. – Самара, 2004. – С. 249-255.
- Фельдман Л.П., Михайлова Т.В. Оценка эффективности кластерных систем с использованием моделей Маркова. //Известия ТРТУ. Тематический выпуск: Материалы Всероссийской научно-технической конференции с международным участием «Компьютерные технологии в инженерной и управленческой деятельности». – Таганрог: ТРТУ, 2002. – №2 (25). – С. 50-53.
- Фельдман Л.П., Михайлова Т.В. Способы оптимизации состава и структуры высокопроизводительных вычислительных систем //Научные труды Донецкого государственного технического университета. Серия «Информатика, кибернетика и вычислительная техника»(ИКВТ-2001).- Донецк: ДонГТУ.- 2000. C. 80-85.