
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования, планируемые результаты
- 3. Дискретная марковская модель кластера без предоставления доступа к ресурсам
- Выводы
- Список источников
Введение
В современном мире существует большое количество задач, требующих применения мощных вычислительных систем (ВС).
Одним из примеров вычислительных систем с распределенной обработкой являются кластеры [1–4]. Кластерные вычислительные системы по критерию совместного использования дискового пространства классифицируются следующим образом: с совместным использованием дискового пространства и без предоставления доступа к ресурсам [2].
При проектировании и эксплуатации распределенных ВС возникает проблема рационального использования ресурсов вычислительной среды. Для эффективного решения этой проблемы используются непрерывные [5–7] или дискретные аналитические модели [8], и для каждого класса решаемых задач определяются основные параметры вычислительной среды.
Непрерывные модели являются менее трудоемкими и применяются для сложного класса исследуемых структур. Дискретная модель Маркова, в сравнении с непрерывной – более точно отражает работу вычислительной среды и позволяет эффективно распараллелить вычислительные структуры [9].
Анализ кластерных систем с помощью дискретной модели при большом количестве решаемых задач на ВС требует больших временных затрат, так как количество состояний дискретной Марковской модели комбинаторно возрастает при увеличении количества задач.
1. Актуальность темы
В настоящее время одним из основных направлений в ведущих странах мира является создание и применение современных суперкомпьютеров. Развитие параллельных вычислительных систем обусловлено необходимостью эффективно решать задачи большой размерности. Эффективность использования вычислительных систем зависит не только от производительности процессоров, на базе которых построена система, а и от пропускной способности ее каналов связи. Поэтому одной из самых важных задач является анализ эффективности функционирования многопроцессорных систем.
Благодаря развитию вычислительных систем появились такие задачи как сбалансированность нагрузки, определение узких мест в вычислительной системе, обеспечение заданного времени отклика при работе большого количества пользователей и т.д.
Работы в области параллельных вычислительных структур являются актуальными и требуют дальнейшего развития в связи с большим количеством создаваемых суперкомпьютеров.
Разработанный аппарат аналитического моделирования вычислительных структур позволяет проектировать параллельные структуры для решения задач большой размерности, которые не могут быть эффективно реализованы на однопроцессорных ЭВМ.
Исследования, проведенные в магистерской работе, направлены на анализ, повышение эффективности, оптимизацию кластерных систем.
2. Цель и задачи исследования, планируемые результаты
Цель работы состоит в разработке методов повышения эффективности функционирования кластерных систем на основе использования результатов аналитических моделей с учетом соответствия классу решаемых задач выбранной топологии кластера.
Задачи исследования:
- разработка марковской модели функционирования кластерных систем и усовершенствование существующих методов расчета основных характеристик функционирования кластерных систем;
- разработка параллельного алгоритма марковской модели функционирования кластерных систем с учетом особенностей их структуры и класса решаемых задач.
Объектом исследования является кластерная система без предоставления доступа к ресурсам.
Предметом исследования являются аналитические модели анализа высокопроизводительных вычислительных систем.
Методы исследования. Решение сформулированных в магистерской работе задач базируется на использовании методов теории случайных процессов, вычислительной математики, теории графов. Проверку полученных результатов планируется осуществить путем проведения вычислительных экспериментов на вычислительных структурах в системах имитационного моделирования.
3. Дискретная марковская модель кластера без предоставления доступа к ресурсам
В данной модели каждый узел в кластере имеет свою собственную память, все узлы используют дисковую подсистему. Узлы в кластере обращаются к дисковой подсистеме по системной шине. Вычислительные задачи равномерно распределяются по нескольким объединенным в сеть компьютерам.
В упрощенной структуре кластера без предоставления доступа к ресурсам (см. рис. 1) время передачи данных (см. рис. 2) по шине включили во время обслуживания на серверах и дисках, соответственно. Структура состоит из M рабочих станций пользователей, N1 серверов, выполняющие различные приложения, N2 дисков, на которых хранится база данных.
Представим серверы и диски приборами, время обслуживания которых имеет геометрическое распределение со средним параметром qi (i=1,…,N1+N2+1) – вероятностью завершения обслуживания заявки (соответственно, ri=1-qi – вероятность продолжения обслуживания заявки).
Управляющий сервер распределяет пользовательские заявки каждого из
М пользователей и с вероятностью 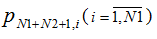 посылает запрос к одному из N1 серверов,
которые, в свою очередь, обрабатывая этот запрос обращаются к одному из N2 дисков с вероятностью
посылает запрос к одному из N1 серверов,
которые, в свою очередь, обрабатывая этот запрос обращаются к одному из N2 дисков с вероятностью
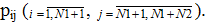
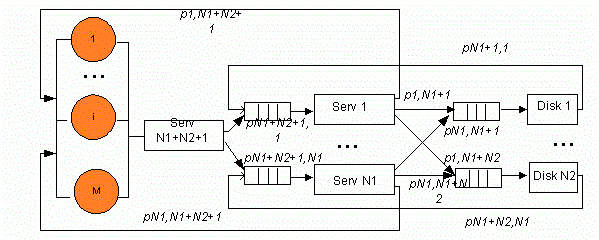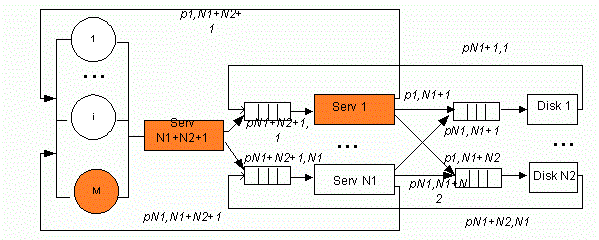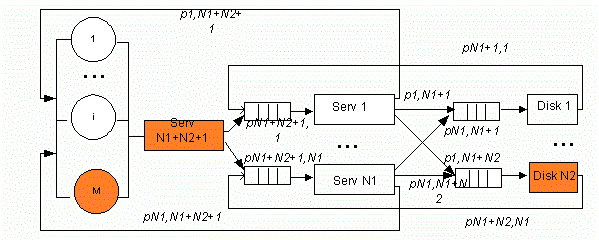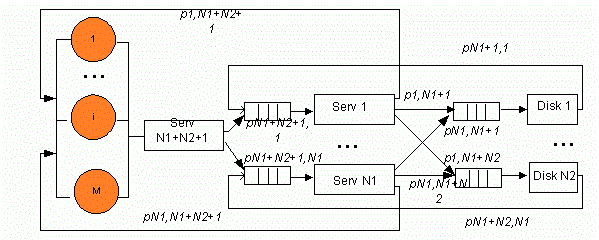
Рисунок 1 – Структурная схема кластера без предоставления доступа к ресурсам (Анимация: количество кадров: 9, количество циклов повторения: 6, размер: 137 Кбайт)
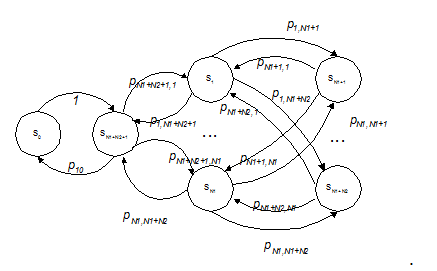
Рисунок 2 – Граф передач модели кластера без предоставления доступа к ресурсам
Для построения дискретной модели такой вычислительной системы определим все возможные состояния. За состояние системы примем размещение М заявок по N1+N2+1 узлам
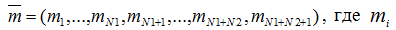 – количество задач в i-ом узле (всего узлов N=N1+N2+1). Обозначим множество состояний через
– количество задач в i-ом узле (всего узлов N=N1+N2+1). Обозначим множество состояний через
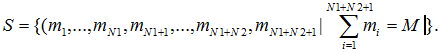 Число L всевозможных состояний системы равно числу размещений M задач по N узлам и определяется по формуле:
Число L всевозможных состояний системы равно числу размещений M задач по N узлам и определяется по формуле:
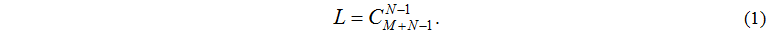
Количество устройств в каждом узле задается вектором 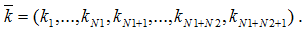
Определим переходные вероятности для каждой пары состояний 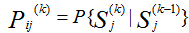 , т.е. вероятности перехода из состояния Si, в котором она находилась на (k-1)-м шаге, в состояние Sj на k-м шаге.
, т.е. вероятности перехода из состояния Si, в котором она находилась на (k-1)-м шаге, в состояние Sj на k-м шаге.
Для произвольного состояния 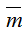 введем вектор
введем вектор 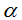 , s-я компонента которого
, s-я компонента которого
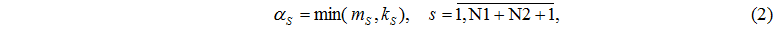
определяет число загруженных устройств в s-м узле обработки задач. Для определения возможности перехода из произвольного состояния в произвольное состояние
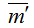 найдем вектор
найдем вектор
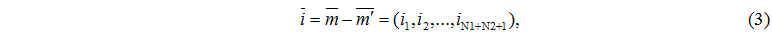
каждая компонента 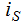 которого представляет изменение числа задач в s-ом узле.
Если >0, то на рассматриваемом переходе из узла s должны уйти минимум
задач. Если < 0, то в узел s должны прийти
|| задач. При любом переходе из
число задач, обслуженных s-м узлом обработки, не может быть больше
которого представляет изменение числа задач в s-ом узле.
Если >0, то на рассматриваемом переходе из узла s должны уйти минимум
задач. Если < 0, то в узел s должны прийти
|| задач. При любом переходе из
число задач, обслуженных s-м узлом обработки, не может быть больше 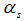 , т.е.
, т.е.
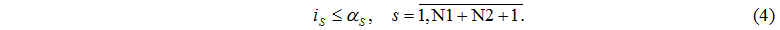
Определим множество J номеров узлов обработки, в которых < 0, т.е.
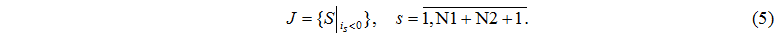
Если 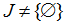 , то величины
, то величины 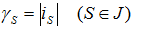 определяют минимально возможное
число программ, которые поступают к тем узлам обработки, номера s которых принадлежат множеству J. Число программ, поступивших в
один из таких узлов s равно ||. Количество поступивших задач к главному серверу от серверов не может превышать количества работающих серверов
определяют минимально возможное
число программ, которые поступают к тем узлам обработки, номера s которых принадлежат множеству J. Число программ, поступивших в
один из таких узлов s равно ||. Количество поступивших задач к главному серверу от серверов не может превышать количества работающих серверов
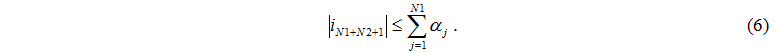
Аналогично, количество поступивших задач к дискам от серверов не может превышать количества работающих серверов
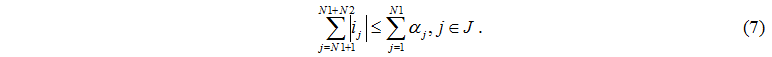
От серверного узла задачи поступают и к управляющему серверу, и к дискам, поэтому общее количество ушедших задач не превышает количества работающих серверов
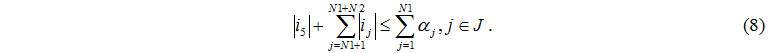
Количество поступивших задач к серверам не превышает количества работающих дисков и задачи, поступившей от управляющего сервера
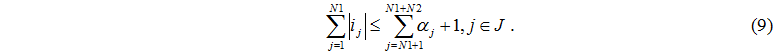
Если  , то
, то 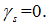
Рассмотрим частный случай:
N = 5 – количество устройств,
N1 = 2 – количество вычислительных серверов
N2 = 2 – количество дисков
M = 5 – количество задач.
Определим число L всевозможных состояний системы:
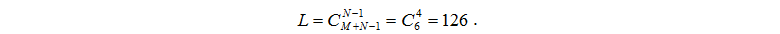
Переход  возможен, если соблюдаются условия (6-9).
возможен, если соблюдаются условия (6-9).
Рассмотрим случай i5=1 – управляющий сервер завершил обработку одной задачи, следовательно, обработка требуется на одном из вычислительных серверов.
Допустим, другие устройства продолжают обработку задач, и обмен не требуется, тогда вероятность перехода между двумя состояниями:
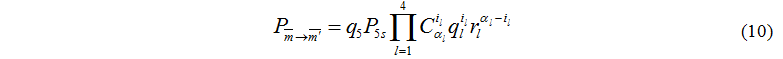
Рассмотрим второй вариант, когда i5=1 – управляющий сервер завершил обработку одной задачи, другие устройства также завершили обработку задач, следовательно, необходимо учесть возможность обмена задачами между вычислительными серверами и дисковыми устройствами.
Сформулируем условия формирования множества для обмена задачами:
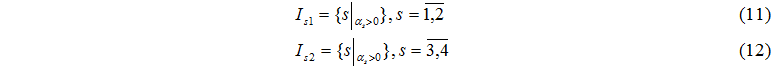
Множество Is1 содержит номера вычислительных серверов, а множество Is2 – номера дисков, которые в данном такте могут завершить обработку задачи.
Обмен может быть осуществлен при условии (13):
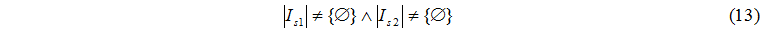
Построим множество событий для обмена задачами:
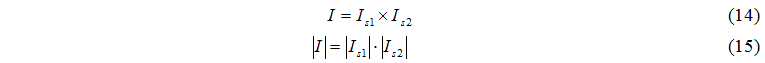
Элемент множества I имеет следующий вид:
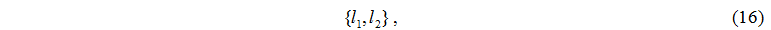
где l1 - номер серверного узла,
l2 - номер дискового узла.
Тогда вероятность перехода между двумя состояниями:
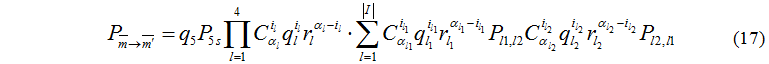
Рассмотрим случай i5=0, возможны три варианта обмена задачами:
1) между управляющим сервером и вычислительными серверами;
2) между вычислительными серверами и дисковыми устройствами;
3) между управляющим сервером и вычислительными серверами, а также вычислительными серверами и дисковыми устройствами.
Сформулируем условия формирования множества для обмена задачами:
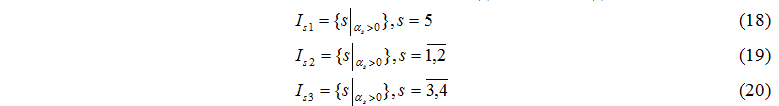
Множество Is1 содержит номер управляющего сервера, Is2 – номера вычислительных серверов, а множество Is3 – номера дисков, которые в данном такте могут завершить обработку задачи.
Обмен может быть осуществлен при условии (21):
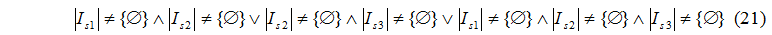
Построим множество событий для обмена задачами:
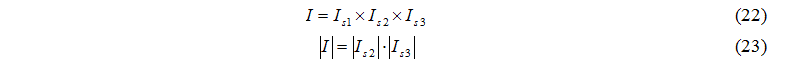
Элемент множества I имеет следующий вид:
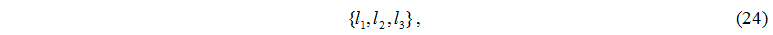
где l1 – номер управляющего сервера,
l2 – номер серверного узла,
l3 – номер дискового узла.
Для определения вектора стационарных состояний надо решить систему линейных алгебраических уравнений (СЛАУ)
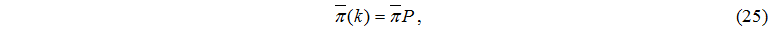
соответствующую рассмотренной марковской модели.
Используя стационарные вероятности можно вычислить основные характеристики вычислительной среды [10]:
Среднее число занятых устройств в s-м узле определяется по формуле:
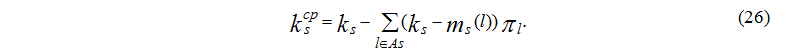
Загрузка устройств определяется по следующей формуле:
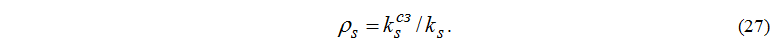
Среднего числа задач, находящихся в s-м узле:
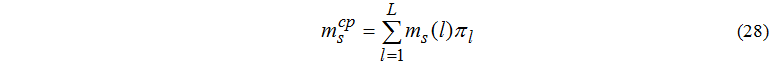
Среднее число задач, находящихся в очереди к s-му узлу:
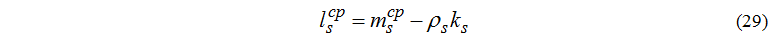
Если анализируется конкретный вид кластера для решения определенного класса задач, то с помощью этих характеристик можно определить эффективность вычислительной среды (в зависимости от критерия: равномерная загрузка всех узлов, минимальное время отклика и т.д.).
Для кластера без предоставления доступа к ресурсам (см. рис. 1) построен параллельный алгоритм дискретной марковской модели (см. рис. 3).

Рисунок 3 – Схема параллельного алгоритма Марковской модели
Эффективность параллельного алгоритма стремится к единице (см. рис. 4) при росте размерности задачи, что свидетельствует об оптимальности распараллеливания этих алгоритмов.
Для подбора оптимального коэффициента мультипрограммирования можно использовать методику [11], в которой предлагается критерий сбалансированности, составляющие которого цена простоя оборудования и штраф за задержку выполнения запроса.
Рассмотренные в [11] способы оптимизации состава и структур высокопроизводительных ВС можно использовать для проектирования ВС, причем при большом коэффициенте мультипрограммирования – только численным (градиентным) или c использованием метода средних.
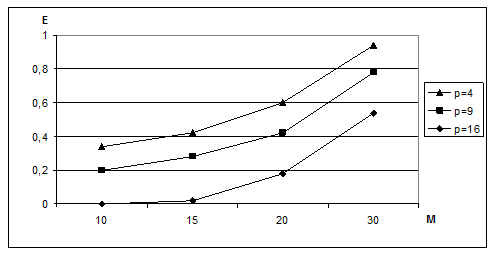
Рисунок 4 – Зависимость эффективности параллельного алгоритма от размерности вычисляемой задачи
Таким образом, использование вероятностных моделей при проектировании, эксплуатации и оптимизации вычислительных систем позволяет вырабатывать рекомендации по рациональному использованию ресурсов этой вычислительной среды.
Выводы
Разработана дискретная марковская модель кластерной вычислительной системы без предоставления доступа к ресурсам с ограниченным количеством задач, которую можно использовать для оценки эффективности параллельных вычислительных структур. В том числе, вычислять основные характеристики вычислительной среды: загрузку устройств; среднее количество занятых устройств в s-м узле; среднее число задач, которые находятся в очереди к s-му узлу; среднее время пребывания и ожидания в s-м узле; среднее время пребывания и ожидания в системе.
Предложена параллельная реализация марковской модели кластерной вычислительной системы, эффективность которой стремится к единице при большой размерности задачи.
Список источников
- Шнитман В. Современные высокопроизводительные компьютеры. Информационно-аналитические материалы центра информационных технологий / В. Шнитман [Электронный ресурс]. Режим доступа: http://www.citforum.ru/hardware/svk/contents.shtml.
- Спортак М., Франк Ч., Паппас Ч. и др. Высокопроизводительные сети. Энциклопедия пользователя. – К.:«ДиаСофт», 1998.-432с.
- Corbalan J., Martorell X., Labarta J. Performance-Driven Processor Allocation //IEEE Transactions on Parallel and Distributed Systems, vol. 16, No. 7, July 2005, PP.599-611
- Oleszkiewicz J., Xiao L., Liu Y. Effectively Utilizing Global Cluster Memory for Large Data-Intensive Parallel Programs //IEEE Transactions on Parallel and Distributed Systems, vol. 17, No. 1, Jan. 2006, PP.66-77
- Авен О. И. и др. Оценка качества и оптимизация вычислительных систем. – М.: Наука, 1982,-464с.
- Cremonesi P., Gennaro C. Integrated Performance Models for SPMD Applications and MIMD Architectures //IEEE Transactions on Parallel and Distributed Systems, vol. 13, No. 7, Jul. 2002, PP.745-757
- Varki Е. Response Time Analysis of Parallel Computer and Storage Systems //IEEE Transactions on Parallel and Distributed Systems, vol. 12, No. 11, Nov. 2001, PP.1146-1161
- Клейнрок Л. Вычислительные системы с очередями. – М.:Мир, 1979, 600с. Последовательно - параллельные вычисления: Пер. с англ. - М.: Мир, 1985.-456 с.
- Фельдман Л.П., Михайлова Т.В. Параллельный алгоритм построения дискретной марковской модели /Высокопроизводительные параллельные вычисления на кластерных системах. Материалы четвертого Международного научно-практического семинара и Всероссийской молодежной школы. /Под редакцией член-корреспондента РАН В.А. Сойфера. – Самара, 2004. – С. 249-255.
- Фельдман Л.П., Михайлова Т.В. Оценка эффективности кластерных систем с использованием моделей Маркова. //Известия ТРТУ. Тематический выпуск: Материалы Всероссийской научно-технической конференции с международным участием «Компьютерные технологии в инженерной и управленческой деятельности». – Таганрог: ТРТУ, 2002. – №2 (25). – С. 50-53.
- Фельдман Л.П., Михайлова Т.В. Способы оптимизации состава и структуры высокопроизводительных вычислительных систем //Научные труды Донецкого государственного технического университета. Серия «Информатика, кибернетика и вычислительная техника»(ИКВТ-2001).- Донецк: ДонГТУ.- 2000. C. 80-85.