
Калінін Олександр Сергійович
Iнститут iнформатики i штучного iнтелекту
Кафедра систем штучного iнтелекту
Спеціальність «Системи штучного інтелекту»
Моделі та алгоритмічне забезпечення для засобів автоматизації побудови онтологій
Науковий керівник: к.т.н., доц. Вороной Сергiй Михайлович
Реферат
Зміст
Цілі і завдання
Актуальність теми роботи
Запропонована наукова новизна
Заплановані практичні результати
Глобальний огляд досліджень і розробок
Націольний огляд досліджень і розробок
Локальний огляд досліджень і розробок
Власні результати
Висновки
Література
1 Цілі і завдання [До змісту]
Метою дослідження є розробка методів та алгоритмічного забезпечення для автоматичної побудови онтологій. Здійснення поставленої мети можливо при виконанні таких завдань:
- розглянути та вивчити основні особливості семантичних технологій і перспективи їх розвитку;
- проаналізувати методи, моделі та алгоритми побудови онтологій;
- визначити проблемні місця розробки онтологій.
2 Актуальність теми роботи [До змісту]
Розвиток наукоємних галузей людської діяльності в сучасному суспільстві супроводжується зростанням ролі комп'ютерних технологій. Зараз значно збільшується потік інформації, з'явилася необхідність пошуку нових способів її зберігання, подання, формалізації та систематизації, а також автоматичної обробки. Величезний інтерес викликають системи, здатні без участі людини витягти будь-які відомості з тексту (семантичні зв'язки). Як результат, на тлі знову виникаючих потреб розвиваються нові технології, покликані вирішити заявлені проблеми. Поряд з World Wide Web з'являється його розширення, Semantic Web, в якому гіпертекстові сторінки забезпечуються додатковою розміткою, що несе інформацію про семантику елементів, які включаються до сторінки. Невід'ємним компонентом семантичного веб є поняття онтології, яка описує зміст семантичної розмітки [1].
Онтології є зручним засобом представлення та зберігання знань, тому розвиток алгоритмічної бази для створення, оновлення та підтримки онтологій, є досить актуальним завданням на даний час.
3 Запропонована наукова новизна [До змісту]
У даній науковій роботі, в рамках проведених досліджень, передбачається провести аналіз існуючих методів побудови онтологій, виявити їх недоліки, а також запропонувати новий метод автоматичної побудови отології.
4 Заплановані практичні результати [До змісту]
У практичному плані, що проводяться дослідження, мають принести результат у вигляді чітко сформульованого алгоритму автоматичної побудови онтології, з урахуванням недоліків алгоритмів-попередників.
Алгоритм повинен буде відповідати таким вимогам:
- самодостатність;
- висока ефективність;
- максимальна простота;
- легкість у застосуванні.
5 Глобальний огляд досліджень і розробок [До змісту]
Методи автоматичної побудови онтологій можна умовно розділити на три основні групи в залежності від області запозичення основного підходу: методи, засновані на підходах з області штучного інтелекту, статистичні методи і методи, які використовують лінгвістичні підходи.
5.1 Підхід на основі лексико-синтаксичних шаблонів [До змісту]
Даний підхід належить до групи методів автоматичної побудови онтологій, що використовують лінгвістичні засоби. Для побудови онтологій слід активно використовувати всі рівні аналізу природної мови: морфологію, синтаксис і семантику. Таким чином, для автоматичної побудови онтології автором використовується один з методів семантичного аналізу текстів природною мовою – лексико-синтаксичні шаблони [2].
Як метод семантичного аналізу лексико-синтаксичні шаблони давно використовуються у комп'ютерній лінгвістиці і являють собою характерні висловлювання та конструкції певних елементів мови.
Дана методика семантичного аналізу не є спеціалізованою для певної предметної області.
На основі лексико-синтаксичних шаблонів виділяються онтологічні конструкції. Наприклад, з речення «Студент – це людина, яка навчається в університеті» [2], система виділить класи «студент», «людина» і ставлення «subclass-of» між ними.
Лексико-синтаксичні шаблони як метод семантичного аналізу текстів природною мовою – у разі великого обсягу колекції шаблонів – є ефективним засобом для автоматичної побудови онтологій.
Лексико-синтаксичні шаблони представляють собою характерні висловлювання (словосполучення і обороти), конструкції з певних елементів мови. Такі шаблони дозволяють побудувати семантичну модель, відповідну тексту, до якого вони застосовуються.
Як метод семантичного аналізу, лексико-синтаксичні шаблони використовуються у комп'ютерній лінгвістиці більше 20-ти років.
Лексичні відносини можна описати за допомогою методу інтерпретації зразків (шаблонів). Такий метод використовує ієрархію шаблонів, які складаються головним чином з індикаторів частини мови і групових символів.
Було виявлено значну кількість шаблонів для ідентифікації відносини гіпоніми [3]. Використання шаблонів на великому корпусі текстів однієї тематики, можна побудувати «досить адекватну» таксономію понять відповідної предметної області. У її шаблонах як елементи використовуються, наприклад, поняття іменної групи (NP), знаки пунктуації, конкретні слова.
Таким чином, шаблон «NP {, NP} * {,} and other NP», де NP – у мовне позначення іменної групи, визначає ставлення гіпонімії, яке продемонстровано на частини речення «... temples, treasuries, and other important civic buildings ... ». За допомогою зазначеного шаблону можуть бути виявлені наступні відносини: hyponym (\ temple , \ civic building); hyponym (\ treasury , \ civic building).
В даний час розроблена мова для запису лексико-синтаксичних шаблонів (LSPL). Елементами шаблонів, для найбільш точного опису, можуть бути:
- літерали, тобто конкретні лексеми
- певні частини мови;
- певні граматичні конструкції;
- умови, уточнюючі граматичні характеристики розглянутих елементів.
Розроблені шаблони застосовуються для аналізу науково-технічних документів. Для їх обробки, окрім традиційних словників (термінологічного і морфологічного), використовується словник загальнонаукових слів і висловлювань, лексико-синтаксичні шаблони типових фраз наукової мови.
Наприклад, речення: «По результатам генерации форм, слова были разбиты на группы, названные профилями» за допомогою розробленої методики формалізації автори записують так: Ng «,» Pa<названный> T<:case=ins>; Ng.gender=Pa.gender; Ng.number=Pa.number=T.number>.
5.2 Підхід на основі системи продукцій [До змісту]
Даний підхід належить до групи методів автоматичної побудови онтологій, в основі яких лежать підходи з області штучного інтелекту.
Ефективна автоматична побудова онтологій може бути заснована на здатності методів штучного інтелекту до вилучення з тексту елементів знань та їх нетривіальної обробки.
Аналіз області природно-мовної обробки тексту показує переважання використання різних правил при вирішенні завдань у розглянутій предметній області. Даний факт, а також декларативний характер подання методів автоматичної побудови онтологій, обгрунтовує застосування системи продукцій в якості моделі представлення знань про метод [4].
Для створення методів автоматичної побудови онтологій автор розробляє модель генерації системи продукцій (на основі застосування генетичного програмування), модель генерації перетворювачів (на основі генетичного і автоматного програмування), модель генерації систем логічного висновку (також на основі генетичного і автоматного програмування) і модель апарату активації продукцій (на основі застосування автоматного програмування).
Таким чином, автором методу пропонується модель автоматичної побудови онтологій у вигляді системи продукцій і застосуванні генетичного і автоматного програмування для створення необхідних моделей.
Автор пропонує схеми для аналізу текстів (рисунок 5.1) та для побудови онтологій предметної області (рисунок 5.2).
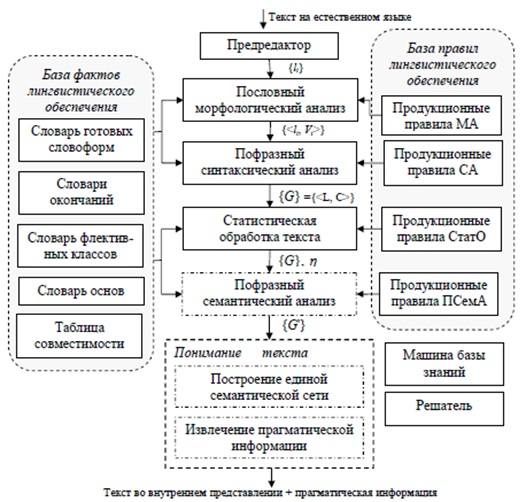
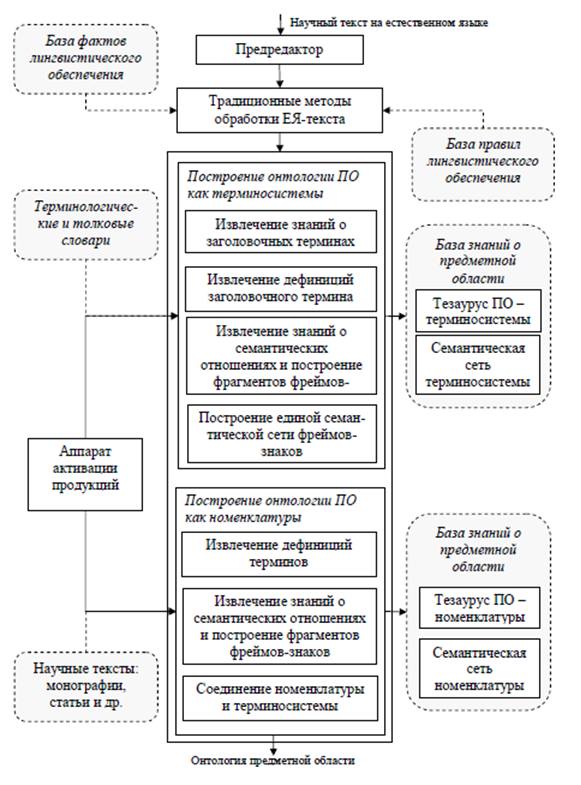
5.3 - Підхід на основі статистичних методів [До змісту]
Підготовка колекції
Однією з особливостей роботи з текстами природною мовою є необхідність обов'язкової попередньої обробки даних.
Процес обробки може бути досить трудомістким і зазвичай складається з декількох етапів, наведених нижче.
- Приведення документів до єдиного формату.
- Токенізація.
- Стеммінг (лемматизація).
- Видалення стоп-слів.
Однак не завжди є необхідність у проведенні всіх перерахованих вище етапів [5].
У результаті попередньої обробки кожен документ колекції характеризується вектором типів даного документа і їх частотою зустрічальності.
Раніше зазначалося, що особливості колекції впливають на якість онтології. Для поліпшення одержуваної онтології, потрібно провести попередню кластеризацію документів колекції таким чином, щоб в один кластер потрапляли тематично близькі документи, а подальшу роботу проводити окремо з кожним отриманим кластером.
Варто зауважити, що які-небудь спеціальні вимоги до алгоритму кластеризації відсутні. У якості алгоритму використовується Contextual Document Clustering [6], що дає гарні результати на великих текстових колекціях.
Визначення класів онтології
На першому етапі побудови онтології потрібно виділити класи, що входять до її складу.
Раніше було відзначено, що поняття лінгвістичної онтології суворо пов'язані з термінами. Таким чином, дана задача зводиться до визначення термінів розглянутої предметної області. Алгоритми вилучення термінів з текстів природною мовою можна розділити на дві групи: статистичні та лінгвістичні [7].
Однак перші володіють певною перевагою, оскільки їх використання не залежить від лінгвістичних особливостей конкретної мови.
Підхід до вилучення термінів у даній статті є переважно статистичним. Тим не менш, передбачається, що існуючі статистичні методи можуть показати кращі результати, якщо доповнити їх певними евристиками.
Попередньо в якості базових евристик пропонується використовувати наступні:
- ім'я класу містить хоча б один іменник.
- загальновживані слова в порівнянні з термінами володіють більшою частотою зустрічальності, приблизно рівною в різних предметних областях;
- кількість інформації терміна з декількох слів більше, ніж кількість інформації окремих слів, що входять до його складу.
На першому етапі в кожній колекції документів виділяють іменники і визначають їх частоту зустрічальності. Отже, в результаті використання евристики «ім'я класу містить хоча б один іменник» число передбачуваних класів значно скорочується.
На другому етапі виділяють терміни, що складаються з одного слова. На підставі висунутої евристики «загальновживані слова в порівнянні з термінами володіють більшою частотою зустрічальності», порівнюються частоти виникнення різних іменників в рамках однієї колекції, також проводиться оцінка перетину різних колекцій, використовуваних іменником.
Проте статистичні дані – не єдине джерело класів онтології.
Термінологічні словники також можуть стати джерелами знань при формуванні ядра онтології. У разі роботи з колекціями неспеціалізованих в конкретній області документів можливе використання існуючих розроблених експертами онтологій (наприклад, для англійської мови – онтології WordNet).
Нарешті, на третьому етапі на основі взаємної інформації можуть бути виділені терміни, що складаються з декількох слів. Варто зазначити, що в даному випадку використовується евристика «кількість інформації терміна з декількох слів більше, ніж кількість інформації окремих слів, що входять до його складу». Для випадку двоскладових термінів отримуємо, що взаємна інформація визначається за формулою 5.1.
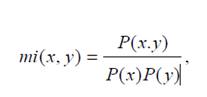 (5.1)
(5.1)де x і y являють собою окремі слова терміна; P(x) та P(y) – частота зустрічальності x та у; P(x, y) – частота спільної зустрічальності x і y.
Виділені описаним вище чином терміни будуть представляти собою класи майбутньої онтології.
Таким чином, запропонований підхід може бути віднесений до групи статистичних методів.
Передбачається, що висунуті евристики (в тому числі, що до складу імені класу повинно входити іменник), є досить універсальними і не обмежують застосування методу тільки російською мовою [8].
Визначення відносин між класами
Видається, що етап виділення відносин між класами створює найбільші труднощі. У зв'язку з чим, спочатку має сенс говорити про автоматичні побудови прикладної онтології, а тезауруса (таксономії з термінами).
Як базові відносин, що діють між термінами, визначимо відносини «is-a» і «synonym-of».
Для виділення відносини «is-a» можна скористатися кількісним підходом до інформації. Для цього ще раз скористаємося зробленим в попередньому пункті припущенням «кількість інформації терміна з декількох слів більше, ніж кількість інформації окремих слів, що входять до його складу».
Очевидно, що термін, що знаходиться на більш низькому рівні ієрархії, володіє великою кількістю інформації, ніж узагальнюючий термін.
Так, у прикладі з попереднього розділу, кількість інформації терміна «флейта пікколо» буде більше, ніж кількість інформації терміна «флейта». Отже, останній термін може бути надкласом першого. Проте для встановлення будь-якого відношення між термінами, знання тільки про кількість інформації, яку вони в собі містять, недостатньо [8].
Припустимо, що для кожного отриманого на першому етапі терміна обчислено відповідна йому кількість інформації. Визначення того, чи пов'язані два різних терміна з різною кількістю інформації ставленням «is-a», можна проводити двома способами.
Перший спосіб ґрунтується на припущенні, що приватні терміни містять в своєму складі слова з більш загальних термінів. Наприклад, «блок флейта» і «флейта пікколо», містять в собі термін «флейта». З урахуванням проведеного вище аналізу за кількістю інформації цих термінів, цілком обґрунтованим виглядає припущення про встановлення відносини «is-a» між ними (а саме, флейта пікколо «is-a» флейта).
Другий спосіб ґрунтується на понятті «контексту слова». Контекст слова може бути визначений як умовна ймовірність P(Y | x), де Y – змінна величина, що приймає значення зі словника колекції, а x – потрібне слово [8].
Поняття контексту може бути розширено до «контексту терміна». Тоді x буде являти собою потрібний термін, який в загальному випадку може складатися з декількох слів, а змінна величина Y буде приймати значення із словника термінів, що зустрічаються в даній колекції документів.
Інакше кажучи, під контекстом терміна будемо розуміти деяку множину слів, які зустрічаються разом з даними.
У разі якщо у термінів немає загальних слів, але збігається контекст, і при цьому вони володіють різною кількістю інформації, має сенс говорити про ставлення «is-a» між ними.
Повертаючись до прикладу, можна припустити, що в розглянутому уривку описані умови будуть виконуватися для термінів «музичний інструмент» і «флейта». Контекст їх вживання буде збігатися, в той час як кількість інформації останнього терміну буде вище.
Якщо контекст слів збігається, але кількість інформації термінів приблизно рівна, то найімовірніше між термінами діє ставлення синонімії, тобто ставлення «synonym-of».
Запропонований підхід дозволяє виділити тільки базові відносини, необхідні для побудови таксономії, проте можливе розширення підходу для виділення інших відносин [8].
6 Націольний огляд досліджень і розробок [До змісту]
На національному рівні дослідження в області онтологій добре представлені в статті Литвина В.В. «Завдання оптимізації структури та змісту онтології і методи їх розв’язування».
Здатність інтелектуальної системи приймати обґрунтовані рішення (давати відповіді) з питань, які ставлять перед нею розробники чи користувачі, передбачає наявність у системи онтології, яка б забезпечувала обґрунтованість таких рішень. Зокрема, логічність висновків, однакову відповідь на однакові, але по-різному сформульовані запитання. Така онтологія повинна задовольняти вимоги цілісності.
Поняття цілісності об’єднує ознаки чи вимоги, серед яких:
- контрольована надлишковість;
- зв’язність графу онтології;
- відсутність взаємозаперечувальних тверджень.
У системах, що ґрунтуються на знаннях, під час доповнення їхньої онтології може виникати надлишковість, яка полягає у присутності дублювальних структур: понять та тверджень, виражених через зв’язки між поняттями. Коли надлишкове знання необхідне, такі системи здійснюють контроль надлишковості.
Зв’язність графу онтології – властивість, яка означає, що між будь-якими двома вершинами такого графу існує простий ланцюг. Зв’язність свідчить, що всі елементи БЗ перебувають у межах досяжності інтелектуальної системи і можуть бути задіяні під час генерування відгуку на звертання до неї. Під час впорядкування та редукції онтології система має контролювати збереження умови зв’язності її графу і не допускати операцій, які цю умову порушують.
Перевірку на зв’язність графу можна здійснити за допомогою наслідків з теореми про оцінення кількості ребер через кількість вершин і кількість компонентів зв’язності [9]. Якщо позначити p та q – число вершин та ребер графу відповідно, то повинні виконуватись такі дві умови:
1) якщо q1> (р-1) (р-2) / 2, то граф зв’язний;
2) у зв’язному графі р-1 <= q <= р (р-1) / 2.
Під час внесення змін ? доповнення онтології новими елементами, модифікації, вилучення елементів ? система повинна виконувати перевірку на її цілісність, тобто відсутність в ній дублювальних і/або взаємозаперечувальних тверджень. Цю процедуру можна реалізувати через механізм виявлення протилежних за змістом відгуків тестовим їх порівнянням (зіставленням) у разі послідовного логічного інвертування одного з тверджень-відгуків методом резолюцій. У разі збігу прямого та інвертованого тверджень система отримує сигнал про порушення цілісності та необхідність усунення суперечності тверджень. У разі виявлення взаємосуперечливих тверджень, конфлікт усувається видаленням того з них, для якого важливість є нижчою.
У разі перевищення очікуваної за контекстом кількості відгуків, система ґенерує процедуру узагальнення понять, що дали такий відгук, або їх властивостей-опрацьовувачів з метою редукції онтології.
Базу знань вважатимемо внутрішньоузгодженою, якщо виконуються такі умови:
1) класи, екземпляри та їхні атрибути мають унікальні імена в межах області визначеності;
2) всі класи в таксономії зв’язані ієрархічними зв’язками «IS-A», на найвищому рівні таксономічної ієрархії міститься лише один базовий клас;
3) всі класи містять принаймні один об’єкт-екземпляр певного класу, що забезпечує функціональність фреймової моделі подання знань;
4) усі опрацьовувачі повідомлень понять онтології на момент їх виклику мають визначені атрибути (конкретні значення формальних параметрів).
Деякі ознаки і вимоги, які містить поняття цілісності (контрольована надлишковість, зв’язність графу, відсутність взаємозаперечувальних тверджень), враховані під час формулювання обмежень на структуру онтології та оптимізаційну задачу.
Обмеження на фізичний об’єм пам’яті
Система має бути реалізована на базі певного програмно-апаратного комплексу, для якого існує реальне обмеження на об’єм оперативної пам’яті. З іншого боку, надмірне зростання об’єму БЗ сповільнює її швидкодію, що може мати вирішальне значення у разі систем, які працюють у реальному масштабі часу.
На етапі первинного формування онтології ІСППР у момент її створення подібна проблема не виникає, проте під час експлуатації відведений об’єм фізичної пам’яті заповнюється, тому доводиться вдаватися до процедур вивільнення тієї її частини, яка використовується системою найменш ефективно. Отже, система працює поперемінно у двох режимах:
1) доповнення онтології новими знаннями;
2) вилучення з онтології інформації, яка за певними ознаками становить для користувача найменшу цінність.
Одним із підходів до вибору ознак, що ідентифікують знання, які доцільно вилучити з онтології, є зважування понять і зв’язків між ними під час їх додавання та використання під час експлуатації системи.
Для підтримання системи у робочому стані треба залишати визначений об’єм вільної оперативної пам’яті. У роботі обрано 10 % загального об’єму. Якщо під час наповнення цей контрольний показник перевищено, система переходить у режим оптимізації, під час якого виконується послідовне вибирання і вилучення з онтології тих її елементів, для яких відношення важливості до займаного в оперативній пам’яті місця буде мінімальним (формула 6.1):
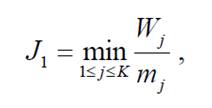 (6.1)
(6.1)Де Wj – важливість елемента Cj ;
mj – місце елемента Cj в оперативній пам’яті;
K – кількість понять онтології.
Час відгуку на зовнішнє звертання
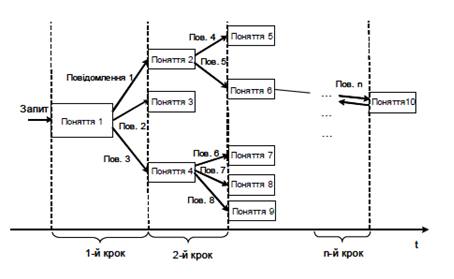
Швидкодію, що визначається часом відгуку ІСППР на зовнішнє звертання, можна оцінити за максимальною кількістю дуг графу онтології у можливій траєкторії поширення повідомлення між поняттями, які задіяні у разі генерування відгуку. Просту та ефективну оцінку швидкодії системи, означеної у такий спосіб, дає ексцентриситет вершин графу онтології (рис. 6.1).
Ексцентриситет Ej вершини Cj у зв’язному графі G – це максимальна відстань від вершини Cj до інших вершин у графі G (формула 6.2). Тоді найгірша швидкодія системи [10]:
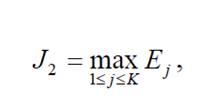 (6.2)
(6.2)де Ej – ексцентриситет вершини Cj у зв’язному графі G, K – кількість понять онтології.
Повнота онтології системи
Повноту онтології можна визначити як середній відсоток нетривіальних відповідей на зовнішні запити до системи. Під тривіальною розумітимемо відповідь, яка не надає її отримувачу нової інформації. Зокрема, до тривіальних можна зарахувати відповідь типу «Інформація відсутня».
Оцінити відсоток нетривіальних відповідей певної системи може інша тестова інтелектуальна система, повноту якої ми знаємо, або людина-експерт.
Оптимізації підлягає приведена повнота онтології, як відношення повноти онтології до кількості її понять. Якщо кількість понять порівнюваних онтологій чи БЗ однакові, що має місце у разі їх насичення під час експлуатації, достатньо порівнювати лише їх повноту.
Принцип визначення повноти онтології ґрунтується на методиці порівняння й оцінювання пошукових систем, запропонованої Американським інтститутом стандартів (NIST) – одним з авторитетних органів стандартизації інформаційних технологій у США. Методика використовує корпус тестових запитань і документів, нагромаджених протягом конференцій з оцінювання систем текстового пошуку (TREC - text retrival evaluation conference), що проводяться NIST.
Такий критерій є інтеґральним і не дає змоги виконувати регулярну оптимізацію структури онтології на його основі, а призначений для оцінювання та порівняння функціонування інформаційних систем загалом.
Збалансованість предметної області
Під час автоматичної розбудови онтології можливі випадки, що в результаті деталізація понять ПО, подана кількістю класів, підкласів, їх екземплярів і властивостей, для одного класу може значно відрізнятися від відображення іншого класу. Збалансованість ПО виражається у рівномірному поданні її окремих розділів в онтології. Вимога збалансованості може бути перед комерційними універсальними ІСППР, сферу застосування яких не можна апріорно визначити.
Формальним критерієм збалансованості подання поняття-класу в онтології ІСППР може слугувати дисперсія важливості його підкласів (формула 6.3):
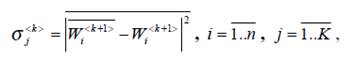 (6.3)
(6.3)де 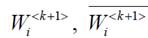 важливість та усереднена важливість підкласів k+1-рівня, відповідно;
важливість та усереднена важливість підкласів k+1-рівня, відповідно;
n -кількість підкласів у j-му класі;
N – кількість класів у онтології.
Під час оптимізації онтології критерій збалансованості можна використовувати під час вибору тематики взірцевих текстів для доповнення онтології. У цій роботі алгоритм оптимізації змісту онтології не містить такий критерій до цільової функції, тому детально не розглядається [10].
7 Локальний огляд досліджень і розробок [До змісту]
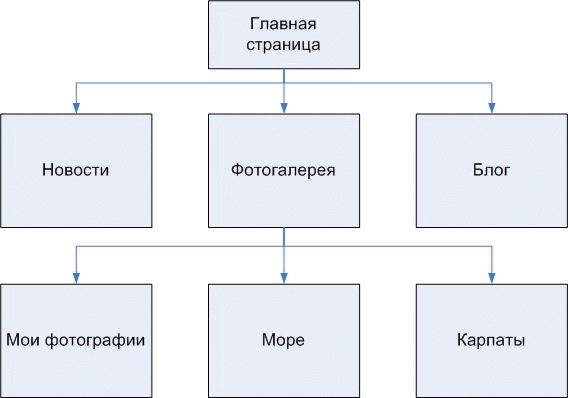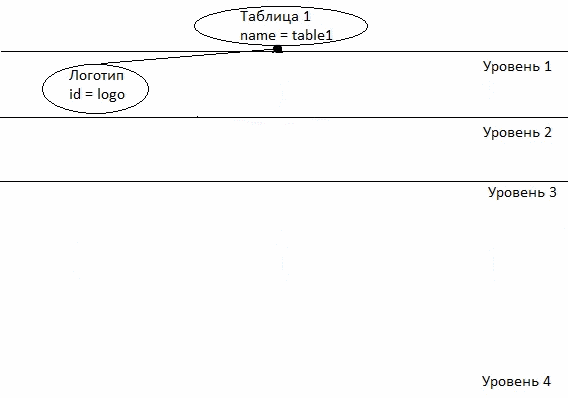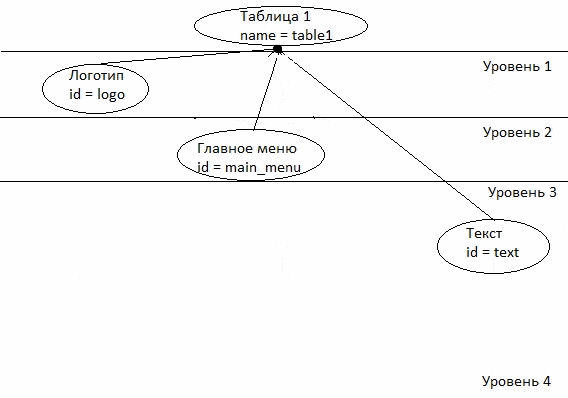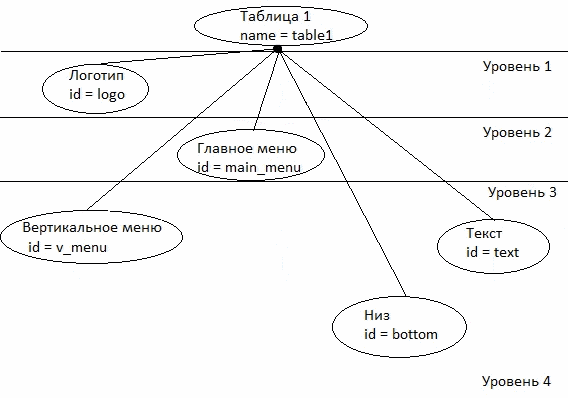
Донецький національний технічний університет також веде розробки в сфері побудови онтологій. У статті Григор'єва А.В., Павловського Є.В. «Аналіз методів побудови онтологій для побудови експертних систем з синтезу моделей складних систем в САПР» розглядаються існуючі онтології в різних предметних областях, пропонується онтологічний підхід для створення сайтів (рисунок 7.1) [11].
8 Власні результати [До змісту]
На даній стадії дослідження в галузі побудови онтологій виділена основна проблематика даної теми, переваги і недоліки існуючих методів. Ведуться дослідження з поліпшення методів автоматичної побудови онтологій.
9 Висновки [До змісту]
Представлені в даній науково-дослідній роботі методи автоматичної побудови онтологій дають розробникам широкий вибір, проте, слід зазначити, що дані методи не позбавлені недоліків.
Застосування продукційних правил забезпечує наступні переваги: простота і висока швидкодія; модульність – кожне правило описує невеликий, відносно незалежний блок знань; зручність модифікації – старі правила можна змінювати і замінювати на нові відносно незалежно від інших правил; ясність – знання у вигляді правил легко формулюються і сприймаються експертами; прозорість – використання правил полегшує реалізацію здатності системи до пояснення прийнятих рішень та отриманих результатів; можливість поступового нарощування – додавання правил в базу знань відбувається відносно незалежно від інших правил. Серед недоліків можна виділити недостатню семантичну зв'язність між правилами.
Підхід на основі лексико-синтаксичних шаблонів не є спеціалізованим на певну предметну область і це є його перевагою, проте можна зазначити, що лексико-синтаксичні шаблони як метод семантичного аналізу текстів природною мовою – у разі невеликого обсягу колекції шаблонів – є не дуже ефективним засобом для автоматичної побудови онтологій.
Статистичний підхід також є досить універсальними і не обмежує застосування методу тільки російською мовою, підхід дозволяє виділити тільки базові відносини, необхідні для побудови онтології, що є його недоліком.
Наступною стадією науково-дослідної роботи, виходячи із зазначеної проблематики, передбачається удосконалення існуючих методів, для отримання більш адекватних результатів.
Література [До змісту]
- Н.С. Константинова, О.А. Митрофанова Онтологии как системы хранения знаний. [Электронный ресурс] – Режим доступа: http://window.edu.ru/resource/795/58795/files/68352e2-st08.pdf
- Рабчевский Е. А. Автоматическое построение онтологий на основе лексико-синтаксических шаблонов для информационного поиска / Е.А. Рабчевский // В кн.: «Электронные библиотеки: перспективные методы и технологии, электронные коллекции»: сб. науч. тр. 11й Всероссийской научной конференции RCDL-2009. – Петрозаводск, 2009. – С. 69–77.
- Marti A. Hearst, Automatic Acquisition of Hyponyms from Large Text Corpora // Proceedings of the 14th conference on Computational linguistics - Volume 2, Pages: 539 - 545 , Nantes, France, Association for Computational Linguistics, Morristown, NJ, USA, 1992.
- Найханова Л. В. Методы и модели автоматического построения онтологий на основе генетического и автоматного программирования / Л. В. Найханова. – Красноярск, 2008. – 36 с.
- Weiss, S. M., Indurkhya, N., Zhang, T., and Damerau, F. J. Text Mining: predictive methods for analyzing unstructured information. Springer, 2005.
- Dobrynin, V., Patterson, D. W., and Rooney, N. Contextual Document Clustering. [Электронный ресурс] – Режим доступа: http://www.sophiasearch.com/uploads/documents/contextual_document_clustering.pdf
- Syafrullah, M., and Salim, N. Improving Term Extraction Using Particle Swarm Optimization Techniques. // Journal of Computer Science. 2010. Vol. 6. № 3. Pp. 323–329.
- Мозжерина Е.С. Автоматическое построение онтологии по коллекции текстовых документов. [Электронный ресурс] – Режим доступа: http://rcdl.ru/doc/2011/paper45.pdf.
- Свами М. Графы, сети и алгоритмы / М. Свами, К. Тхуласираман. – М.: Наука, 1984.
- Литвин В.В. Задачі оптимізації структури та змісту онтологій та методи їх розв’язування. [Электронный ресурс] – Режим доступа: http://www.nbuv.gov.ua/portal/natural/Vnulp/ISM/2011_715/19.pdf
- Григорьев А.В., Павловский Е.В. «Анализ методов построения онтологий для построения экспертных систем по синтезу моделей сложных систем в САПР». [Электронный ресурс] – Режим доступа: http://www.nbuv.gov.ua/portal/natural/Npdntu_ota/2011_21/article_21_13.pdf