
Калинин Александр Сергеевич
Институт информатики и искусственного интеллекта
Кафедра систем искусственного интеллекта
Специальность «Системы искусственного интеллекта»
Модели и алгоритмическое обеспечение для средств автоматизации построения онтологий
Научный руководитель: к.т.н., доц. Вороной Сергей Михайлович
Реферат
Содержание
Цели и задачи
Актуальность темы работы
Предполагаемая научная новизна
Планируемые практические результаты
Глобальный обзор исследований и разработок
Национальный обзор исследований и разработок
Локальный обзор исследований и разработок
Cобственные результаты
Выводы
Литература
1 Цели и задачи [К содержанию]
Целью исследования является разработка методов и алгоритмического обеспечения для автоматического построения онтологий. Осуществление поставленной цели возможно при выполнении таких задач:
- рассмотреть и изучить основные особенности семантических технологий и перспективы их развития;
- проанализировать методы, модели и алгоритмы построения онтологий;
- определить проблемные места разработки онтологий.
2 Актуальность темы работы [К содержанию]
Развитие наукоемких отраслей человеческой деятельности в современном обществе сопровождается возрастанием роли компьютерных технологий. Сейчас значительно увеличивается поток информации, поэтому появилась необходимость поиска новых способов ее хранения, представления, формализации и систематизации, а также автоматической обработки. Огромный интерес вызывают системы, способные без участия человека извлечь какие-либо сведения из текста (семантические связи). Как результат, на фоне вновь возникающих потребностей развиваются новые технологии, призванные решить заявленные проблемы. Наряду с World Wide Web появляется его расширение, Semantic Web, в котором гипертекстовые страницы снабжаются дополнительной разметкой, несущий информацию о семантике элементы, которые включаются в страницы [1]. Неотъемлемым компонентом семантического веб является понятие онтологии, описывающей содержание семантической разметки.
Онтологии являются удобным средством представления и хранения знаний, поэтому развитие алгоритмической базы для создания, обновления и поддержки онтологий, является весьма актуальной задачей в настоящее время.
3 Предполагаемая научная новизна [К содержанию]
В данной научной работе, в рамках проводимых исследований, предполагается провести анализ существующих методов построения онтологий, выявить их недостатки, а также предложить новый метод автоматического построения отологий.
4 Планируемые практические результаты [К содержанию]
В практическом плане, проводимые исследования, должны принести результат в виде четко сформулированного алгоритма автоматического построения онтологии, с учетом недостатков алгоритмов-предшественников.
Алгоритм должен будет отвечать таким требованиям:
- самодостаточность;
- высокая эффективность;
- максимальная простота;
- легкость в применении.
5 Глобальный обзор исследований и разработок [К содержанию]
Методы автоматического построения онтологий можно условно разделить на три основные группы в зависимости от области заимствования основного подхода: методы, основанные на подходах из области искусственного интеллекта, статистические методы и методы, которые используют лингвистические подходы.
5.1 Подход на основе лексико-синтаксических шаблонов [К содержанию]
Данный подход относится к группе методов автоматического построения онтологий, использующие лингвистические средства. Для построения онтологий следует активно использовать все уровни анализа естественного языка: морфологию, синтаксис и семантику. Таким образом, для автоматического построения онтологии автором используется один из методов семантического анализа текстов на естественном языке - лексико-синтаксические шаблоны [2].
Как метод семантического анализа лексико-синтаксические шаблоны давно используются в компьютерной лингвистике и представляют собой характерные высказывания и конструкции определенных элементов языка.
Данная методика семантического анализа не является специализированным для определенной предметной области.
На основе лексико-синтаксических шаблонов выделяются онтологические конструкции. Например, из предложения «Студент - это человек, который учится в университете» [2], система выделит классы «студент», «человек» и отношение «subclass-of» между ними.
Лексико-синтаксические шаблоны как метод семантического анализа текстов на естественном языке - в случае большого объема коллекции шаблонов - является эффективным средством для автоматического построения онтологий.
Лексико-синтаксические шаблоны представляют собой характерные выражения (словосочетания и обороты), конструкции из определенных элементов языка. Такие шаблоны позволяют построить семантическую модель, соответствующую тексту, к которому они применяются.
Как метод семантического анализа, лексико-синтаксические шаблоны используются в компьютерной лингвистике более 20-ти лет.
Лексические отношения можно описать с помощью метода интерпретации образцов (шаблонов). Такой метод использует иерархию шаблонов, состоящих главным образом из индикаторов части речи и групповых символов.
Было выявлено значительное количество шаблонов для идентификации отношения гипонимы [3]. Используя шаблоны на большом корпусе текстов одной тематики, можно построить «достаточно адекватную» таксономию понятий соответствующей предметной области. В ее шаблонах как элементы используются, например, понятие именной группы (NP), знаки препинания, конкретные слова.
Таким образом, шаблон «NP {, NP} * {,} and other NP», где NP - в языковую обозначения именной группы, определяет отношение гипонимии, которое продемонстрировано на части предложения «... temples, treasuries, and other important civic buildings ... ». С помощью указанного шаблона могут быть выявлены следующие отношения: hyponym (\ temple , \ civic building) hyponym (\ treasury , \ civic building).
В настоящее время разработан язык для записи лексико-синтаксических шаблонов (LSPL). Элементами шаблонов для наиболее точного описания, могут быть:
- литералы, т.е. конкретные лексемы;
- определенные части речи;
- определенные грамматические конструкции;
- условия, уточняющие грамматические характеристики рассматриваемых элементов.
Разработанные шаблоны применяются для анализа научно-технических документов. Для их обработки, кроме традиционных словарей (терминологического и морфологического), используется словарь общенаучных слов и выражений, лексико-синтаксические шаблоны типовых фраз научного языка.
Например, предложение: «По результатам генерации форм, слова были разбиты на группы, названные профилями» с помощью разработанной методики формализации авторы записывают так: Ng «,» Pa <Названный> T <: case = ins>; Ng.gender = Pa.gender; Ng.number = Pa.number = T.number>.
5.2 Подход на основе системы продукций [К содержанию]
Данный подход относится к группе методов автоматического построения онтологий, в основе которых лежат подходы из области искусственного интеллекта.
Эффективное автоматическое построение онтологий может быть основано на способности методов искусственного интеллекта к изъятию из текста элементов знаний и их нетривиальной переработки.
Анализ области естественно-языковой обработки текста показывает преобладание использования различных правил при решении задач в рассматриваемой предметной области. Данный факт, а также декларативный характер представления методов автоматического построения онтологий, обосновывает применение системы продукций в качестве модели представления знаний о методе [4].
Для создания методов автоматического построения онтологий автор разрабатывает модель генерации системы продукций (на основе применения генетического программирования), модель генерации преобразователей (на основе генетического и автоматного программирования), модель генерации систем логического вывода (также на основе генетического и автоматного программирования) и модель аппарата активации продукций (на основе применения автоматного программирования).
Таким образом, автором метода предлагается модель автоматического построения онтологий в виде системы продукций и применении генетического и автоматного программирования для создания необходимых моделей.
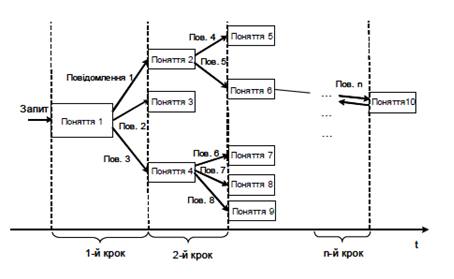
Автор предлагает схемы для анализа текстов (рисунок 5.1) и для построения онтологий предметной области (рисунок 5.2).
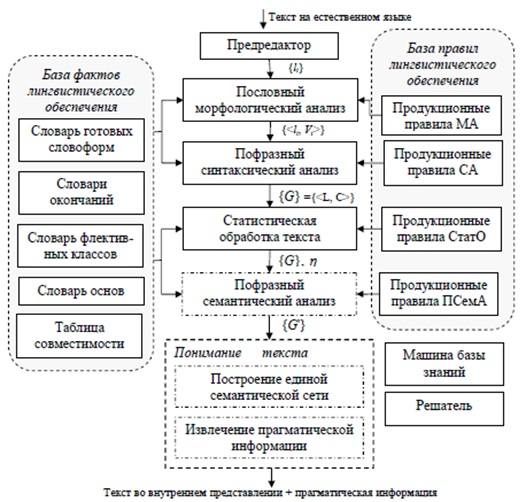
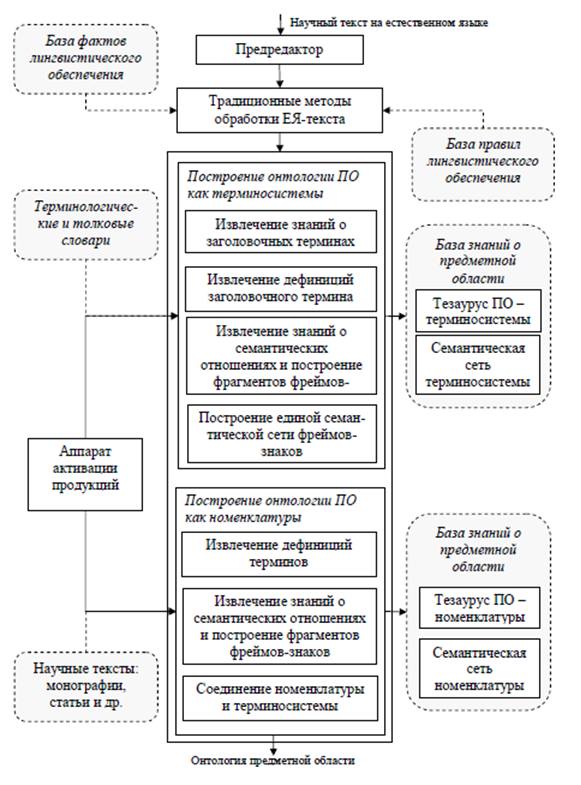
5.3 Подход на основе статистических методов [К содержанию]
Подготовка коллекции
Одной из особенностей работы с текстами на естественном языке является необходимость обязательной предварительной обработки данных.
Процесс обработки может быть достаточно трудоемким и обычно состоит из нескольких этапов, приведенных ниже.
- Приведение документов к единому формату.
- Токенизация.
- Стемминг (лемматизация).
- Удаление стоп-слов.
Однако не всегда есть необходимость в проведении всех вышеперечисленных этапов [5].
В результате предварительной обработки каждый документ коллекции характеризуется вектором типов данного документа и их частотой встречаемости.
Ранее отмечалось, что особенности коллекции влияют на качество онтологии. Для улучшения получаемой онтологии, нужно провести предварительную кластеризацию документов коллекции таким образом, чтобы в один кластер попадали тематически близкие документы, а дальнейшую работу проводить отдельно с каждым полученным кластером.
Стоит заметить, что какие-либо специальные требования к алгоритму кластеризации отсутствуют. В качестве алгоритма используется Contextual Document Clustering [6], что дает хорошие результаты на больших текстовых коллекциях.
Определение классов онтологии
На первом этапе построения онтологии требуется выделить входящие в ее состав классы.
Ранее было отмечено, что понятия лингвистической онтологии строго связаны с терминами. Таким образом, данная задача сводится к определению терминов рассматриваемой предметной области. Алгоритмы извлечения терминов из текстов на естественном языке можно разделить на две группы: статистические и лингвистические [7].
Однако первые обладают определенным преимуществом, поскольку их использование не зависит от лингвистических особенностей конкретного языка.
Подход к извлечению терминов в данной статье является преимущественно статистическим. Тем не менее, предполагается, что существующие статистические методы могут показать лучшие результаты, если дополнить их определенными эвристиками.
Предварительно в качестве базовых эвристик предлагается использовать следующие.
- Имя класса содержит хотя бы одно существительное.
- Общеупотребительные слова по сравнению с терминами обладают большей частотой встречаемости, приблизительно равной в различных предметных областях.
- Количество информации термина из нескольких слов больше, чем количество информации отдельных слов, входящих в его состав.
На первом этапе в каждой коллекции документов выделяют существительные и определяют их частоту встречаемости. Следовательно, в результате использования (1), число предполагаемых классов значительно сокращается.
На втором этапе выделяют термины, состоящие из одного слова. На основании выдвинутой эвристики (2), сравниваются частоты встречаемости различных существительных в рамках одной коллекции, также проводится оценка пересечения различных коллекций по используемым существительным.
Однако статистические данные — не единственный источник классов онтологии.
Терминологические словари также могут стать источниками знаний при формировании ядра онтологии. В случае работы с коллекциями неспециализированных в конкретной области документов возможно использование существующих разработанных экспертами онтологий (например, для английского языка — онтологии WordNet).
Наконец, на третьем этапе на основе взаимной информации могут быть выделены термины, состоящие из нескольких слов. Стоит отметить, что в данном случае используется эвристика (3). Для случая двухсложных терминов получаем, что взаимная информация определяется по формуле 5.1:
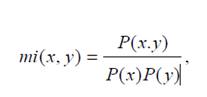 (5.1)
(5.1)где x и y представляют собой отдельные слова термина;
P(x) – частота встречаемости x;
P(x, y) – частота совместной встречаемости x и y.
Выделенные описанным выше образом термины будут представлять собой классы будущей онтологии.
Таким образом, предлагаемый подход может быть отнесен к группе статистических методов.
Предполагается, что выдвинутые эвристики (в том числе, что в состав имени класса должно входить существительное), являются достаточно универсальными и не ограничивают применение метода только русским языком [8].
Определение отношений между классами
Представляется, что этап выделения отношений между классами создаст наибольшие трудности. В связи с чем, первоначально имеет смысл говорить об автоматическом построении не произвольной прикладной онтологии, а тезауруса (таксономии с терминами).
В качестве базовых отношений, действующих между терминами, определим отношения «is-a» и «synonym-of».
Для выделения отношения «is-a» можно воспользоваться количественным подходом к информации. Для этого еще раз воспользуемся сделанным в предыдущем пункте предположением (3).
Очевидно, что термин, находящийся на более низком уровне иерархии, обладает большим количеством информации, чем обобщающий термин.
Так, в примере из предыдущего раздела, количество информации термина «флейта пикколо» будет больше, чем количество информации термина «флейта». Следовательно, последний термин может являться надклассом первого. Однако для установления какого-либо отношения между терминами, знания только о количестве информации, которое они в себе содержат, недостаточно [8].
Предположим, что для каждого полученного на первом этапе термина вычислено соответствующее ему количество информации. Определение того, связаны ли два различных термина с разным количеством информации отношением «is-a», можно проводить двумя способами.
Первый способ основывается на предположении, что частные термины содержат в своем составе слова из более общих терминов. Например, «блок флейта» и «флейта пикколо», содержат в себе термин «флейта». С учетом проведенного выше анализа по количеству информации этих терминов, вполне обоснованным выглядит предположение об установлении отношения «is-a» между ними (а именно, флейта пикколо «is-a» флейта).
Второй способ основывается на понятии «контекста слова». Согласно [4] контекст слова может быть определен как условная вероятность P(Y|x), где Y — переменная величина, принимающая значения из словаря коллекции, а x — искомое слово [8].
Понятие контекста может быть расширено до «контекста термина». Тогда x будет представлять собой искомый термин, который в общем случае может состоять из нескольких слов, а переменная величина Y будет принимать значения из словаря терминов, встречающихся в рассматриваемой коллекции документов.
Иначе говоря, под контекстом термина будем понимать некоторое множество слов, которые встречаются одновременно с данным.
В случае если у терминов нет общих слов, но совпадает контекст, и при этом они обладают разным количеством информации, имеет смысл говорить об отношении «is-a» между ними.
Возвращаясь к примеру, можно предположить, что в рассматриваемом отрывке описанные условия будут выполняться для терминов «музыкальный инструмент» и «флейта». Контекст их употребления будет совпадать, в то время как количество информации последнего термина окажется выше.
Если контекст слов совпадает, но количество информации терминов приблизительно равное, то вероятнее всего между терминами действует отношение синонимии, т.е. отношение «synonym-of ».
Предложенный подход позволяет выделить только базовые отношения, необходимые для построения таксономии, однако возможно расширение подхода для выделения других отношений [8].
6 Национальный обзор исследований и разработок [К содержанию]
На национальном уровне исследования в области онтологий хорошо представлены в статье Литвина В.В. «Задачи оптимизации структуры и содержания онтологии и методы их разрешения».
Способность интеллектуальной системы принимать обоснованные решения (отвечать) по вопросам, которые ставят перед ней разработчики и пользователи, предполагает наличие в системе онтологии, которая обеспечивала бы обоснованность таких решений. В частности, логичность выводов, одинаковый ответ на одинаковые, но по-разному сформулированные вопросы. Такая онтология должна удовлетворять требованиям целостности.
Понятие целостности объединяет признаки или требования, среди которых:
- контролируемая избыточность;
- связность графу онтологии;
- отсутствие взаимоотрицающих утверждений.
В системах, основанных на знаниях, при дополнении их онтологии может возникать избыточность, которая заключается в присутствии дублирующих структур: понятий и утверждений, выраженных через связи между понятиями. Когда избыточное знание необходимо, такие системы осуществляют контроль избыточности.
Связность графа онтологии - свойство, которое означает, что между любыми двумя вершинами такого графа существует простая цепь. Связность свидетельствует, что все элементы БЗ находятся в пределах досягаемости интеллектуальной системы и могут быть задействованы при генерации отклика на обращения к ней. Во время упорядочивания и редукции онтологии система должна контролировать сохранение условий связности ее графа и не допускать операций, которые это условие нарушают..
Проверку на связность графа можно осуществить с помощью следствий из теоремы об оценке количества ребер путем определения количества вершин и количества компонентов связности. Если обозначить р и q – количество вершин и ребер графа соответственно, то должны выполняться такие два условия:
1) если q1> (р-1) (р-2) / 2, то граф связный;
2) в связном графе р-1 <= q <= р (р-1) / 2.
При внесении изменений - дополнение онтологии новыми элементами, модификации, удаления элементов - система должна выполнять проверку на ее целостность, т.е. отсутствие в ней дублирующих и / или взаимоотрицающих утверждений. Эту процедуру можно реализовать через механизм выявления противоположных по смыслу отзывов тестовым их сравнением (сопоставлением) в случае последовательного логического инвертирования одного из утверждений-отзывов методом резолюций. В случае совпадения прямого и инвертированного утверждений система получает сигнал о нарушении целостности и необходимости устранения противоречия утверждений. В случае выявления взаимопротиворечащих утверждений, конфликт устраняется удалением того из них, для которого важность ниже.
В случае превышения ожидаемого по контексту количества отзывов, система генерирует процедуру обобщения понятий, которые дали такой отзывкоторые дали такой отзыв, или их свойств-обработчиков с целью редукции онтологии.
Базу знаний считают внутренне согласованной, если выполняются следующие условия:
1) классы, экземпляры и их атрибуты имеют уникальные имена в пределах области определения;
2) все классы в таксономии связаны иерархическими связями «IЅ-А», на высшем уровне таксономической иерархии содержится только один базовый класс;
3) все классы содержат хотя бы один объект-экземпляр определенного класса, что обеспечивает функциональность фреймовой модели представления знаний;
4) все обработчики сообщений понятий онтологии на момент их вызова имеют определенные атрибуты (конкретные значения формальных параметров).
Некоторые признаки и требования, которые содержит понятие целостности (контролируемая избыточность, связность графа, отсутствие взаимоотрицающих утверждений), учтены при формировании ограничений на структуру онтологии и оптимизационные задачи.
Ограничения на физический объем памяти
Система должна быть реализована на базе определенного программно-аппаратного комплекса, для которого существует реальное ограничение на объем оперативной памяти. С другой стороны, чрезмерный рост объема БЗ замедляет ее быстродействие, что может иметь решающее значение в случае систем, работающих в реальном масштабе времени.
На этапе первичного формирования онтологии ИСППР в момент ее создания подобная проблема не возникает, однако при эксплуатации отведенный объем физической памяти заполняется, поэтому приходится прибегать к процедурам высвобождение той ее части, которая используется системой наименее эффективно. Итак, система работает попеременно в двух режимах:
1) дополнения онтологии новыми знаниями;
2) извлечение из онтологии информации, которая по определенным признакам составляет для пользователя наименьшую ценность
Одним из подходов к выбору признаков, идентифицирующих знания, которые целесообразно исключить из онтологии, является взвешивание понятий и связей между ними во время их добавления и использования во время эксплуатации системы.
Для поддержания системы в рабочем состоянии нужно оставлять определенный объем свободной оперативной памяти. В работе выбрано 10% общего объема. Если во время наполнения этот контрольный показатель превышен, система переходит в режим оптимизации, во время которой выполняется последовательный отбор и удаление из онтологии тех ее элементов, для которых отношения важности к занимаемому в оперативной памяти месту будет минимально (формула 6.1):
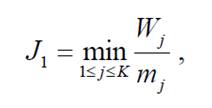 (6.1)
(6.1)где Wj - важность элемента Сј;
mj - место элемента Сј в оперативной памяти;
К - количество понятий онтологии.
Время отклика на внешнее обращение
Быстродействие, которое определяется временем ИСППР на внешнее обращение, можно оценить по максимальному количеству дуг графа онтологии в возможной траектории распространения сообщения между понятиями, которые задействованы в случае генерирования отклика. Простую и эффективную оценку быстродействия системы, обозначенной таким образом, дает эксцентриситет вершин графа онтологии (рис. 6.1).
Эксцентриситет Еј вершины Сј в связном графе G – это максимальное расстояние от вершины Сј другим вершин в графе G (формула 6.2). Тогда плохое быстродействие системы [10]:
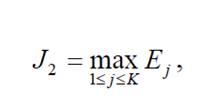 (6.2)
(6.2)где Еј - эксцентриситет вершины Сј в связном графе G;
К - количество понятий онтологии.
Полнота онтологии системы
Полноту онтологии можно определить как средний процент нетривиальных ответов на внешние запросы к системе. Под тривиальным понимается ответ, который не дает его получателю новой информации, в частности к тривиальным можно отнести ответ типа «Информация отсутствует».
Оценить процент нетривиальных ответов определенной системы может другая тестовая интеллектуальная система, полноту которой мы знаем, или человек-эксперт.
Оптимизации подлежит приведенная полнота онтологии, как отношение полноты онтологии к количеству ее понятий. Если количество понятий сравниваемых онтологий или БЗ одинаковые, что имеет место в случае их наращивания во время эксплуатации, достаточно сравнивать только их полноту.
Принцип определения полноты онтологии основывается на методике сравнения и оценки поисковых систем, предложенной Американским институтом стандартов (NIST) - одним из авторитетных органов стандартизации информационных технологий в США. Методика использует корпус тестовых вопросов и документов, накопленных в течение конференций по оценке систем текстового поиска, проводимых NIST.
Такой критерий является интегральным и не позволяет выполнять регулярную оптимизацию структуры онтологии на его основе, а предназначен для оценки и сравнения функционирования информационных систем в целом.
Сбалансированность предметной области
Во время автоматической перестройки онтологии возможны случаи, что в результате детализация понятий ПО, представлена количеством классов, подклассов, их экземпляров и свойств, для одного класса может значительно отличаться от отображения другого класса. Сбалансированность ПО выражается в равномерном представлении ее отдельных разделов в онтологии. Требование сбалансированности может быть перед коммерческими универсальными ИСППР, сферу применения которых нельзя априорно определить.
Формальным критерием сбалансированности подачи понятие класса в онтологии ИСППР может служить дисперсия важности его подклассов (формула 6.3):
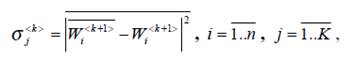 (6.3)
(6.3)где 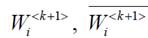 - важность и усредненная важность подклассов k +1- уровня, соответственно;
- важность и усредненная важность подклассов k +1- уровня, соответственно;
n-количество подклассов в j-классе;
N - количество классов в онтологии.
При оптимизации онтологии критерий сбалансированности можно использовать при выборе тематики образцовых текстов для дополнения онтологии. В этой работе алгоритм оптимизации содержания онтологии не содержит такой критерий к целевой функции, поэтому подробно не рассматривается [10].
7 Локальный обзор исследований и разработок [К содержанию]
Донецкий национальный технический университет также ведет разработки в сфере построения онтологий. В статье Григорьева А.В., Павловского Е.В. «Анализ методов построения онтологий для построения экспертных систем по синтезу моделей сложных систем в САПР» рассматриваются существующие онтологии в разных предметных областях, предлагается онтологический подход для создания сайтов (рисунок 7.1) [11].
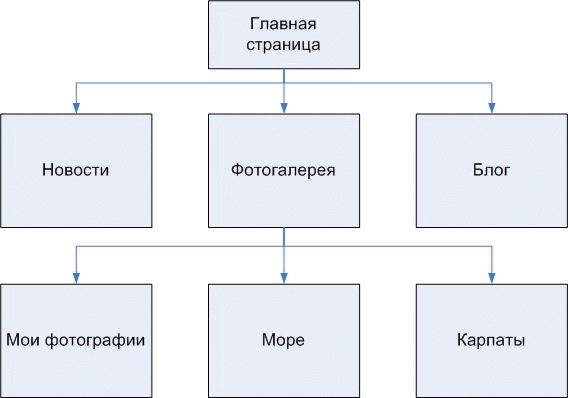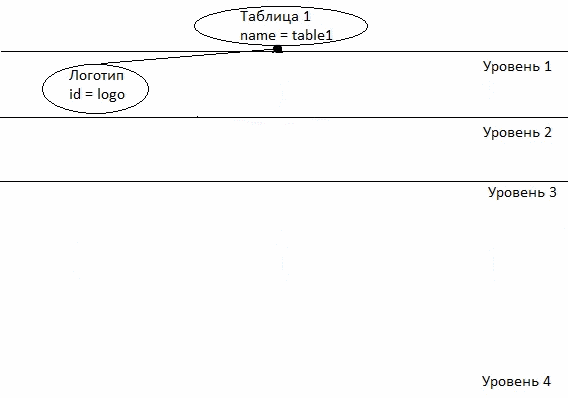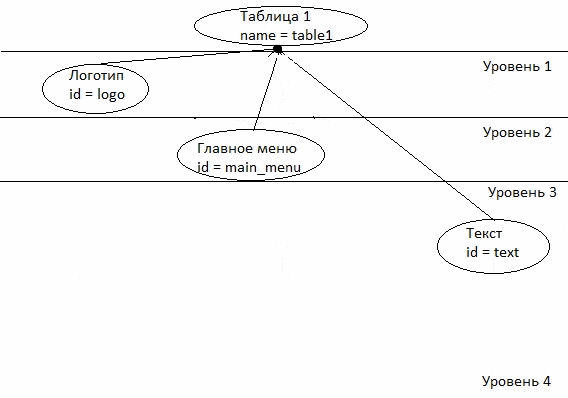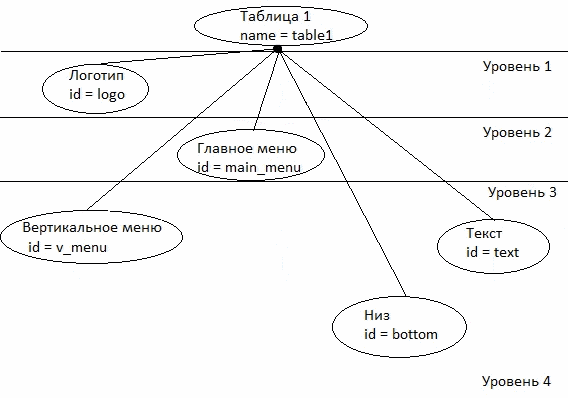
8 Собственные результаты [К содержанию]
На данной стадии исследования в области построения онтологий выделена основная проблематика данной темы, достоинства и недостатки существующих методов. Ведутся исследования по улучшению методов автоматического построения онтологий.
9 Выводы [К содержанию]
Представленные в данной научно-исследовательской работе методы автоматического построения онтологий дают разработчикам широкий выбор, однако, следует отметить, что данные методы не лишены недостатков.
Применение продукционных правил обеспечивает следующие преимущества: простота и высокое быстродействие; модульность - каждое правило описывает небольшой, относительно независимый блок знаний; удобство модификации – старые правила можно изменять и заменять на новые относительно независимо от других правил; ясность - знания в виде правил легко формулируются и воспринимаются экспертами; прозрачность - использование правил облегчает реализацию способности системы к объяснению принятых решений и полученных результатов; возможность постепенного наращивания – добавление правил в базу знаний происходит относительно независимо от других правил. Среди недостатков можно выделить недостаточную семантическую связность между правилами.
Подход на основе лексико-синтаксических шаблонов не является специализированной на определенную предметную область и это является его достоинством, однако можно отметить, что лексико-синтаксические шаблоны как метод семантического анализа текстов на естественном языке – в случае небольшого объема коллекции шаблонов – является не очень эффективным средством для автоматического построения онтологий.
Статистический подход также является достаточно универсальными и не ограничивает применение метода только русским языком, подход позволяет выделить только базовые отношения, необходимые для построения онтологии, что является его недостатком.
Следующей стадией научно-исследовательской работы, исходя из указанной проблематики, предполагается усовершенствование существующих методов, для получения более адекватных результатов
Литература [К содержанию]
- Н.С. Константинова, О.А. Митрофанова Онтологии как системы хранения знаний. [Электронный ресурс] – Режим доступа: http://window.edu.ru/resource/795/58795/files/68352e2-st08.pdf
- Рабчевский Е. А. Автоматическое построение онтологий на основе лексико-синтаксических шаблонов для информационного поиска / Е.А. Рабчевский // В кн.: «Электронные библиотеки: перспективные методы и технологии, электронные коллекции»: сб. науч. тр. 11й Всероссийской научной конференции RCDL-2009. – Петрозаводск, 2009. – С. 69–77.
- Marti A. Hearst, Automatic Acquisition of Hyponyms from Large Text Corpora // Proceedings of the 14th conference on Computational linguistics - Volume 2, Pages: 539 - 545 , Nantes, France, Association for Computational Linguistics, Morristown, NJ, USA, 1992.
- Найханова Л. В. Методы и модели автоматического построения онтологий на основе генетического и автоматного программирования / Л. В. Найханова. – Красноярск, 2008. – 36 с.
- Weiss, S. M., Indurkhya, N., Zhang, T., and Damerau, F. J. Text Mining: predictive methods for analyzing unstructured information. Springer, 2005.
- Dobrynin, V., Patterson, D. W., and Rooney, N. Contextual Document Clustering. [Электронный ресурс] – Режим доступа: http://www.sophiasearch.com/uploads/documents/contextual_document_clustering.pdf
- Syafrullah, M., and Salim, N. Improving Term Extraction Using Particle Swarm Optimization Techniques. // Journal of Computer Science. 2010. Vol. 6. № 3. Pp. 323–329.
- Мозжерина Е.С. Автоматическое построение онтологии по коллекции текстовых документов. [Электронный ресурс] – Режим доступа: http://rcdl.ru/doc/2011/paper45.pdf.
- Свами М. Графы, сети и алгоритмы / М. Свами, К. Тхуласираман. – М.: Наука, 1984.
- Литвин В.В. Задачі оптимізації структури та змісту онтологій та методи їх розв’язування. [Электронный ресурс] – Режим доступа: http://www.nbuv.gov.ua/portal/natural/Vnulp/ISM/2011_715/19.pdf
- Григорьев А.В., Павловский Е.В. «Анализ методов построения онтологий для построения экспертных систем по синтезу моделей сложных систем в САПР». [Электронный ресурс] – Режим доступа: http://www.nbuv.gov.ua/portal/natural/Npdntu_ota/2011_21/article_21_13.pdf