
Abstract
Content
- 1. Aim and tasks
- 2. Subject urgency
- 3. Supposed scientific novelty
- 4. Planned practical results
- 5. Summary of the results of its own
- 5.1 Model of personalisation and management algorithm by content of web site on the basis of estimation of necessities of user
- 5.2 General information about the algorithm CLOPE
- 5.3 Application of algorithm of CLOPE for a clustering of search profiles
- 5.4 Algorithm of management of a content taking into account constant needs of the user
- 6. Directions of improvement of algorithmic providing
- Conclusions
- Literature
1. Aim and tasks
The purpose of work consists in the development of model of personalisation of a site based on the analysis of constants and the current needs of users. For achievement of the purpose it is offered to enter his search profile into model of the end user and to consider search profiles of all audience of a site in personalisation model.
For achievement of a goal not обходимо solution of the following tasks:
1. Undertake analysis of existing services and personalization methods to provide relevant content to the user.
2. To choose algorithm of a clustering of search and navigation profiles of the user.
3. To develop model of personalisation and algorithm of management of a website content on the basis of an assessment of needs of the user.
2. Subject urgency
With development of the Internet the quantity of large sites with a large number of pages, hyperlinks and difficult structure of navigation grows. Information congestion of pages and their high functionality lead to that to users becomes more difficult to be guided, find and carry out a choice of interesting (relevant) information. For modern large Internet libraries, Online stores, the state Web portals, sites of tour agencies, search services, etc. there is an actual problem of effective navigation and search user support. This problem can be solved by contents personalisation according to requirements and features of behavior of the end user.
Personalisation of web pages allows to change cardinally the attitude of a site towards the visitors. As a result, not only the user will "communicate" with the Web page, but the site itself will appeal to anyone who has got to the page, not as a part of the total mass, but as a particular person having a personal interest – personally.
Services in personalisation of sites, their automated adaptation under expectations of visitors in the market of internet marketing exist long ago. However, because of the complexity in the technical implementation of the personalization processes involved in these works is not a third-party organization, and its own programmers. Third-party services fulfill a limited number of actions to personalize the site, which is usually not enough for a noticeable increase in the efficiency of the site.
For high-quality personalisation of a site it is necessary to use information not only on marketing qualities of the visitor, but also information from CRM and other internal databases of each concrete enterprise. In this case there are much more metrics and measurements for the description of a segment of the visitor and implementation of the rule of personalisation.
It is supposed that, visiting a site, the end user tries to satisfy some set of requirements known to it. And one need can have constant character regardless of the frequency of sessions, and others aren't present. Proceeding from it, requirements are shared into constants (not depending on a session) and current (seansozavisimye). It is obvious that approaches to personalisation, have to consider nature of needs of the user.
At the personalisation considering constant requirements, as a rule the history of search queries and the seen pages of the user remains (a navigation profile). Revealing earlier unvisited by the end user pages, but satisfying the his needs constant may exercise taking into account set of search queries occurring at of this or that user with similar.
An example of personalization based on the current needs are currently popular recommendation systems which are based on the search user profiles. Thus often the companies use specially created, recommendatory systems built in the website. Cardinal changes of its control system by data are necessary for integration of recommendation system into the chosen website (CMS). One of progressive approaches to simplification of integration of recommendatory systems with sites is SaaS-technology use (Software as a service).
The disadvantage of existing tools personalization is targeting only the current user needs, which reduces the accuracy of the generated recommendations personalization system. In this regard the problem of development of the combined model of personalisation and algorithms of management of a content of the sites considering constants and the current needs of users is actual.
3. Supposed scientific novelty
Model of personalisation and algorithm of management of a content of the sites take into account the his constant and current needs, based on a combination of navigation and search user profile.
4. Planned practical results
Based on the developed models and algorithms proposed personalization system that can be integrated with web sites to improve the efficiency of access to relevant information for the user.
5. Summary of the results of its own
5.1 Model of personalisation and management algorithm by content of web site on the basis of estimation of necessities of user
The option of personalisation of the website, assuming automatic granting to the specific user of links to pages with interesting his information is considered. By visiting the site the user is trying to meet their needs for information, and some information may be required by him in each session, and to some it may apply only to the current session. Taking into account it the set recommended by a reference system can be represented as follows:
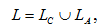
where L – set of links recommended to the end user;
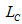 – great number of references to the pages, satisfying constant requirements;
– great number of references to the pages, satisfying constant requirements;
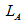 – great number of references to the pages, satisfying the current requirements.
– great number of references to the pages, satisfying the current requirements.
Many links may consist of earlier visited  , and unvisited of pages
, and unvisited of pages 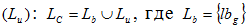 – set of g-ykh of links to the pages seen by the end user, meeting constant requirements.
– set of g-ykh of links to the pages seen by the end user, meeting constant requirements.
 – set of j-ykh of links to the pages not seen by the end user, meeting constant requirements.
– set of j-ykh of links to the pages not seen by the end user, meeting constant requirements.
Calculation of accessory of earlier seen page  to set
to set 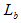 encouraged to implement on the basis of linear correlation coefficient between the ordinal session that took place at the end user, and the number of sessions in which the analyzed page has been viewed:
encouraged to implement on the basis of linear correlation coefficient between the ordinal session that took place at the end user, and the number of sessions in which the analyzed page has been viewed:
 , (1)
, (1) where  – coefficient of linear correlation for the page;
– coefficient of linear correlation for the page;
b – quantity of sessions;
l – serial number of a session,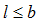 ;
;
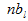 – quantity of sessions in which page viewing took place .
– quantity of sessions in which page viewing took place .
If there is a pronounced correlation 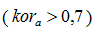 , then in accordance with the scale Cheddoka recorded in the set also it is ranged according to communication size.
, then in accordance with the scale Cheddoka recorded in the set also it is ranged according to communication size.
Revealing pages that earlier were not visible by a particular user, but meeting the needs of its permanent, can be carried out taking into account the totality of search queries (scan profile) that occurred at other users.
The search query is formalized in a natural language description for the user's needs, so for users with similar needs may include those users who have similar profiles search. It is possible to assume that the most powerful pages which were seen by users with similar search profiles, can belong to the sphere of their general constant interests. To reveal such pages it is necessary to solve the following problems:
- to carry out a clustering of search profiles;
- to expand a search profile on the basis of the corresponding cluster;
- to reveal the most important pages on an expanded search profile.
Clustering of search profiles, as well as all specified tasks, it is possible to carry out in an offline a mode. In this case initiation of process of a clustering doesn't depend on the moment of the users access. Start of process can be made periodically during in advance calculated periods of time when the server is least loaded. At a choice of algorithm of a clustering it is necessary to consider limitation of temporary and computing resources.
According to features of an array of the retrieval profiles processed by means of a clustering, the following main requirements to algorithm of a clustering are selected:
- operation with category data;
- automatic detection of optimum quantity of clusters;
- high processing rate of large volumes of data;
- resistance to bursts;
- minimal Customizing;
- determinancy.
- Personyze [Electron resource]. – Access mode: http://www.personyze.ru
- Monoloop [Electron resource]. – Access mode: https://www.monoloop.com
- Gravity [Electron resource]. – Access mode: https://www.gravity.com
- Persuasion API [Electron resource]. – Access mode: http://www. persuasionapi.com
- Царев А.Г. Массовая рекомендательная система для веб-сайтов на основе SAAS-технологии. / А.Г. Царев, Г.К. Сафаралиева, А.Н. Андреева, В.А. Казакова // Труды II международной научно-практической интернет-конференции – Пенза: Издательство Пензенского филиала РГУИТП, 2010. – 374-375 c.
- Широков А.В. Разработка модели информационного портрета пользователя для персонифицированного поиска [Electron resource]. – Access mode: http://download.yandex.ru/IMAT2007/shirokov.pdf
- Радчук О.В. Деякі питання розробки рекомендаційної системи для інформаційного сайту. / О.В. Радчук, Технічні науки // Інноваційні технології, 2013.
- Маслова З.І. Розроблення та програмна реалізація адаптивної пошукової системи для електронного журналу / З.І. Маслова, В.С. Коваленко // Вісник Сумського державного університету. Серія Технічні науки. – №3, 2011. – 122-125 c.
- Лєсна Н.С. Методи пошуку та фільтрації інформації з використанням методу колаборативної фільтрації. / Н.С. Лєсна, С.М. Гайдамака // Системи обробки інформації. –№5, 2013. – 112 с.
- Егошина А.А., Линкин В.О., Арбузова О.В. – Система извлечения информации об однотипных объектах из массивов текстовых документов [Electron resource]. – Access mode: http://masters.donntu.ru/2013/fknt/linkin/library/linkin.htm
- Егошина А.А. Использование алгоритма кластеризации lsa/lsi для решения задачи автоматического построения онтологий. / А.А. Егошина, Е.В. Орлова, Р.И. Дмуховский // Информационные управляющие системы и компьютерный мониторинг (ИУС-2012) / Материалы международной научно-технической конференции студентов и молодых учёных. – Донецк, ДонНТУ – 2012, 173-176 c.
- Yang Y. CLOPE: A fast and Effective Clustering Algorithm for Transactional Data In Proc of SIGKDD’02 / Y. Yang, H. Guan, J. You // July 23-26, – Edmonton, Alberta, Canada, 2002
- Царев А.Г. Модель индикатора предпочтений конечного пользователя веб-сайта на основе многокритериальной комплексной оценки альтернатив. / А.Г. Царев // Мониторинг. Наука и технологии. – №3, 2010. – 68-69 с.
- Monoloop [Electron resource]. – Access mode: https://www.monoloop.com
In case of a choice the following algorithms of a clustering were compared: CURE, BIRCH, MST,k-means, PAM, CLOPE, HCM, Fuzzy C-means, WaveCluster. The total characteristic of algorithms is given in the tab.1.
Table 1 Of the Characteristic of methods of a clustering.
| Method | Pluses | Minuses |
| CURE | – clustering of the high level even in the presence of bursts;
– separation of clusters of the difficult form and different sizes; – possesses linearly dependent requirements to storage location of data and time complexity for data of high dimensionality. |
– works only with numeric data;
– need for the job of threshold values and quantity of clusters. |
| BIRCH | – two-stage clustering;
– clustering of large volumes of data; – works at limited scope of memory; – is local algorithm; – can work in case of one scanning of input pattern of data; – data can be unequally distributed on space; – processes areas with a big density as a uniform cluster. |
– works only with numeric data;
– well selects only clusters of the convex or spherical form; – the need to set thresholds. |
| MST | – works with big sets of arbitrary data;
– selects clusters of arbitrary form (convex and concave forms); – selects from several optimum decisions the best. |
– is sensitive to bursts. |
| k-means | – ease of use;
– operation speed; – clearness and transparency of algorithm; |
– is sensitive to bursts;
– slow operation on large volumes; – it is necessary to set quantity of clusters; – impossibility of application on data where there intersecting clusters; – achievement of a global minimum isn't guaranteed; – algorithm operation strongly depends on the selected initial centers of the clusters which best value can't be known in advance. |
| PAM | – ease of use;
– operation speed; – clearness and transparency of algorithm; – is less sensitive to bursts in comparison with k-means; |
– it is necessary to set quantity of clusters;
– slow operation on big databases. |
| CLOPE | – clustering of huge sets of category data;
– scalability; – operation speed; – quality of a clustering that is reached by use of global criterion of optimization on the basis of maximizing a gradient of height of the histogram of a cluster; – is easily calculated and interpreted; – small volume of resources; – automatically selects quantity of clusters; – is regulated by one parameter - repulsion coefficient. |
|
| HCM | – ease of implementation;
– computing simplicity. |
– it is necessary to set quantity of clusters;
– absence of a warranty in finding of the optimum decision. |
| Fuzzy C-means | – unsharpness in case of an object definition in a cluster allows to classify boundary objects. | – computing complexity;
– set the number of clusters; – uncertainty with bursts. |
| WaveCluster | – can find clusters of arbitrary forms;
– it isn't sensitive to noise. |
– complexity of implementation;
– will apply only to data of low dimensionality. |
The analysis of algorithms shows that from all CLOPE considered only meets necessary requirements.
5.2 General information about the algorithm CLOPE
CLOPE is offered in 2002 by group of the Chinese scientists [12]. Thus it provides higher performance and the best quality of a clustering in comparison with many hierarchical algorithms.
The term transaction refers to some arbitrary set of objects: the list of keywords of article, the goods bought in a supermarket, set of symptoms of the patient, characteristic fragments of the image and so on. The task of a clustering of transactional data consists in receiving such partition of all set of transactions that similar transactions appeared in one cluster, and differing from each other – in different clusters.
At the heart of algorithm the idea of maximizing global costs function which increases closeness of transactions in clusters by means of increase in parameter of the cluster histogram lies. We will consider an essence of algorithm on a simple example from 5 transactions: {(a,b), (a,b,c), (a,c,d), (d,e), (d,e,f)}. Let is necessary to compare the following two partitions on clusters:
(1) {{ab, abc, acd}, {de, def}}
(2) {{ab, abc}, {acd, de, def}}
For the first and second options of partition in each cluster we will calculate number of entrances in it each element of transaction, and then we will calculate height (H) and width (W) of a cluster. For example, cluster {ab, abc, acd} has entrances a:3, b:2, c:2 with H=2 and W=4.
We will estimate quality of two partitions, having analyzed their height of H and W width. Clusters { de, def } and { ab, abc } have identical histograms, therefore, are equivalent. The histogram for a cluster {ab, abc, acd} contains 4 different elements and has the area of 8 units (H=2.0, H/W=0.5), and a cluster { acd, de, def } – 5 different elements with the same area (H=1.6, H/W=0.32). It is obvious that partition (1) is better as provides bigger superimposing of transactions at each other (respectively, parameter H there is higher).
On the basis of such obvious and simple idea of geometrical histograms the algorithm also works CLOPE (engl.: Clustering with sLOPE).
Each cluster of C has the following characteristics:
– D(C) – set of unique objects;
– Occ(i,C) – number of entrances (frequency) of object of i in a cluster of C;
– 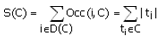 ;
;
– W(C) = |D(C)|;
– H(C) = S(C)/W(C).
Histogram cluster C is a graphic representation of its design characteristics: on the OX axis objects of a cluster in decreasing order of value of Occ (are postponed by i, C) and value of Occ (i, C) – on the OY axis.
5.3 Application of algorithm of CLOPE for a clustering of search profiles
We will consider algorithm of CLOPE in relation to the task of a clustering of retrieval profiles.
Let:
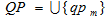 – set of retrieval profiles;
– set of retrieval profiles;
 – set of f-ykh of search queries m-oho retrieval profile;
– set of f-ykh of search queries m-oho retrieval profile;
 – the set of clusters breaking a set of retrieval profiles
– the set of clusters breaking a set of retrieval profiles 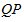 such that
such that  and
and 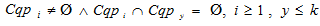 .
.
Each cluster 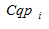 is described by the following characteristics:
is described by the following characteristics:
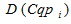 – set of unique search queries;
– set of unique search queries;
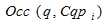 – frequency of entrances of a search query q a cluster .
– frequency of entrances of a search query q a cluster .
The task of a clustering is consolidated to finding of such partition of a set of retrieval profiles on clusters in case of which global costs function has the maximum value:
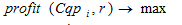 , (2)
, (2)where 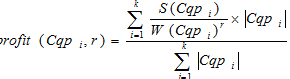 – global costs function;
– global costs function;
 – the space occupied by the histogram of a cluster;
– the space occupied by the histogram of a cluster;
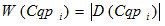 – width of the histogram of a cluster ;
– width of the histogram of a cluster ;
r – repulsion coefficient, the positive natural number, r=2 .
By means of the parameter r called by authors of CLOPE in coefficient of repulsion (repulsion), level of likeness of transactions in a cluster, and, as a result, final quantity of clusters is regulated. This coefficient is selected the user. The more r, the is lower level of likeness and the more clusters will be generated.
As a result of a clustering the retrieval profile of the ultimate user  will appear in a certain cluster
will appear in a certain cluster  .
.
5.4 Algorithm of management of a content taking into account constant needs of the user
In case of visit of a site which is viewed by the user in connection with constant information needs, the content management system using personalisation, shall show to the user the list of the pages recommended for viewing including two groups of links:
1) on already earlier viewed pages for constant needs;
2) on new pages which aren't viewed, but may contain the necessary information for constant needs.
We will consider algorithm of formation of the list.
Formation of the first group of links.
Step 1. For presentation to the user of not viewed pages corresponding to constant information need, extension of its retrieval profile is made. For this purpose search queries which are part of a cluster , are ranged on the frequency of their entrance in a cluster. In an expanded retrieval profile 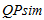 a quantity is selected (lim) search queries with the greatest frequency of entrance:
a quantity is selected (lim) search queries with the greatest frequency of entrance:
 , and
, and  , (3)
, (3)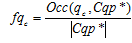 – rate of a search query
– rate of a search query 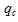 in the cluster .
in the cluster .
Step 2. Further the great number of references is created  on pages which were viewed by other users in sessions with search queries from a cluster . Ranging of links is carried out according to rate of a search query
on pages which were viewed by other users in sessions with search queries from a cluster . Ranging of links is carried out according to rate of a search query  and relevance of the page:
and relevance of the page:
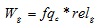 ,
, Where 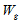 – weight of the link to the page
– weight of the link to the page 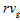 ;
;
– rate of a search query ;
 – relevance g-oh pages.
– relevance g-oh pages.
Relevance g-oh pages is calculated as the relation of the amount of the scalar estimates received in a-oh session to number of sessions in which the appeal to g-oh page was recorded:
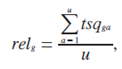
Where u – number of sessions in which viewing g-oh pages took place;
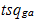 – relevance assessment g-oh pages for a-oh session [13].
– relevance assessment g-oh pages for a-oh session [13].
The assessment of relevance is model-based the preferences, provided by a set of indicators of a look
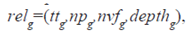
Where 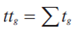 – summary time of stay on the page;
– summary time of stay on the page;
npg – number of appeals to the page;
nvfg – quantity of the fragments viewed by the user g-oh pages;
depthg – viewing depth g-oh pages.
Formation of the second group of links.
Step 1. Calculation of accessory of earlier viewed pages to constant interests of the user. For this purpose on (1) the coefficient of the linear correlation between sequence number of the sessions taking place at the user, and quantity of sessions in which the analysable page was viewed is calculated. The page belongs to interests of the user, if .
Step 2. Ranging of links to pages according to value of correlative communication.
6. Directions of improvement of algorithmic providing
Further it is supposed to develop model and controls a content for satisfaction of the current needs of users by comparison of the current request to clusters of the retrieval profiles integrating in users with the most similar needs.
Conclusions
The analysis of methods of a clustering of large volumes of data is made and the method suitable for the solution of the task of a clustering of retrieval profiles is selected. The scalable algorithm oriented on application in systems of personalisation for Web of portals is developed. As a result of a clustering the close retrieval user profiles are set and on the basis of it the pages not viewed by the user to appropriate his constant information needs come to light earlier. The developed algorithmic support can be used in systems of personalisation of sites for representation to users of a relevant content.
In writing this essay master's work is not yet complete. Final completion: December 2014. Full text of the work and materials on the topic can be obtained from the author or his manager after that date.