
Реферат за темою випускної роботи
Зміст
- 1. Мета і завдання
- 2. Актуальність теми
- 3. Передбачувана наукова новизна
- 4. Заплановані практичні результати
- 5. Огляд дослідженьі розробок за темою
- 5.1 Глобальнийй рівень
- 5.2 Національний рівень
- 5.3 Локальний рівень
- 6. Стислий виклад особистих результатів
- 6.1 Модель персоналізації і алгоритм управління контентом веб-сайту на основі оцінки потреб користувача
- 6.2 Загальні відомості про алгоритм CLOPE
- 6.3 Застосування алгоритму CLOPE для кластеризації пошукових профелів
- 6.4 Алгоритм управління контентом з крахуванням постійних потреб користувача
- 7. Напрями покращення алгоритмічного забезпечення
- Висновки
- Список джерел
1. Мета і завдання
Мета роботи полягає у розробці моделі персоналізації сайту, заснованої на аналізі постійних і поточних потребах користувачів. Для досягнення мети пропонується ввести в модель кінцевого користувача його пошуковий профіль і враховувати пошукові профілі всієї аудиторії сайту в моделі персоналізації.
Для досягнення поставленої мети не обходимо вирішення наступних завдань:
1. Провести аналіз існуючих сервісів персоналізації і методів релевантного надання для користувача контенту.
2. Вибрати алгоритм кластеризації пошукових і навігаційних профілів користувача.
Розробити модель персоналізації і алгоритм управління контентом веб-сайту на основі оцінки потреб користувача.
2. Актуальність теми
З розвитком мережі Інтернет росте кількість великих сайтів з великою кількістю сторінок, гіперпосилань і складною структурою навігації. Інформаційна перевантаженість сторінок і їх висока функціональність призводять до того, що користувачам стає складніше орієнтуватися, знаходити і здійснювати вибір (релевантної) інформації, що цікавить. Для сучасних великих Інтернет-бібліотек, інтернет-магазинів, державних Веб-порталів, сайтів турагенств, пошукових сервісів і т. д. існує актуальне завдання ефективної навігаційної і пошукової підтримки користувачів. Цю задачу можна вирішувати шляхом персоналізації вмісту відповідно до потреб і особливостей поведінки кінцевого користувача.
Персоналізація веб-сторінок дозволяє кардинально змінити відношення сайту до своїх відвідувачів. В результаті не лише користувач "спілкуватиметься" з веб-сторінкою, але і сам сайт звертатиметься до будь-кого хто потрапив на сторінку, не як до частини загальної маси, а як до конкретної людини, що має свої особисті інтереси – персонально.
Послуги з персоналізації сайтів, їх автоматизованій адаптації під очікування відвідувачів на ринку інтернет-маркетингу існують давно. Проте, унаслідок складності в технічній реалізації процесів персоналізації до цих робіт притягуються не сторонні організації, а власні програмісти. Сторонні сервіси (наприклад Adobe Digital Marketing Suite или Google Analytics + Siteapps.com) виконують обмежене число дій з персоналізації сайту, які зазвичай недостатньо для помітного підвищення ефективності сайту.
Для якісної персоналізації сайту необхідно використати інформацію не лише про маркетингові якості відвідувача, але і інформацію з CRM і інших внутрішніх баз даних кожного конкретного підприємства. В цьому випадку з'являється набагато більше метрик і вимірів для опису сегменту відвідувача і виконання правила персоналізації.
Передбачається, що, відвідуючи сайт, кінцевий користувач намагається задовольнити деяку відому йому сукупність потреб. Причому одні потреби можуть мати постійний характер незалежно від частоти сеансів, а інші ні. Виходячи з цього, потреби поділяються на постійні (не залежать від сеансу) і поточні (залежать від сеансу). Очевидно, що підходи до персоналізації, повинні враховувати характер потреб користувача.
При персоналізації, що враховує постійні потреби, як правило зберігається історія пошукових запитів і проглянутих сторінок користувача (навігаційний профіль). Виявлення раніше непроглянутих кінцевим користувачем сторінок, але що задовольняють його постійним потребам може здійснювати з урахуванням сукупності пошукових запитів, що мали місце у того або іншого користувача з схожими навігаційними профілями.
Прикладом персоналізації на основі поточних потреб є популярні нині рекомендаційні системи, які працюють на основі пошукових профілів користувачів. При цьому часто компанії використовують спеціально створені, вбудовані у веб-сайт рекомендаційні системи. Для інтеграції рекомендаційної системи з вибраним веб-сайтом потрібні координальные зміни його системи управління даними (CMS). Одним з прогресивних підходів до спрощення інтеграції рекомендаційних систем з сайтами є використання SaaS- технології (Software as a service).
Недоліком існуючих засобів персоналізації є орієнтація тільки на поточні потреби користувачів, що знижує точність сформованих системою персоналізації рекомендацій. У зв'язку з цим актуальним є завдання розробки комбінованої моделі персоналізації і алгоритмів управління контентом сайтів, що враховують постійні і поточні потреби користувачів.
3. Передбачувана наукова новизна
Модель персоналізації і алгоритм управління контентом сайтів, що враховують його постійні і поточні потреби, на основі комбінації навігаційного і пошукового профілю користувача.
4. Заплановані практичні результати
На основі розробленої моделі і алгоритмів запропонована система персоналізації, яка може інтегруватися з веб-сайтами для підвищення ефективності доступу до релевантної для користувача інформації.
5. Огляд дослідженьі розробок за темою
5.1 Глобальний рівень
Багато компаній пропонують сьогодні послуги з персоналізації. Розглянемо коротку характеристику доступних сьогодні інструментів, які орієнтовані на зручну інтеграцію з веб-сайтом і не вимагають кваліфікованого програмування.
Сервіс Personyze [1] створений для сегментування відвідувачів сайту в режимі реального часу, а також для надання їм персоналізованного і оптимізованного контенту, що основується на їх демографічних, поведінкових і історичних характеристиках. Personyze пропонує найрозширенішу розширену SaaS платформу на ринку персоналізації сайтів і сегментації користувачів в режимі реального часу. Відразу після додавання коду можна в реальному часі бачити звіти про поведінку користувачів на сайті. Усі відвідувачі автоматично розподіляються по сегментах відповідно до їх місця розташування, джерелом відвідувань (включаючи конкретні ключові запити), демографічними даними, діями на сайті і т. д. – всього біля 50 метрик. Як тільки встановлена відповідність відвідувача і сегменту, Personyze виконує необхідні персоналізуючі дії, що дозволяють вам міняти будь-який фрагмент контенту сайту, будь то додавання банера, зміна картинки, зміна тексту, додавання рекомендованих продуктів і багато що інше. Відвідувач бачитиме оптимізовану під нього версію сайту. Сервіс зручний тим, що дозволяє працювати з окремими сегментами і надавати деталізовані звіти по кожному з них.
Творці Monoloop [2] сконцентровані на контролі за купівельним циклом. Встановлений на сайт, їх сервіс відстежує поведінку кожного відвідувача сайту, упізнає його у момент наступного відвідування і відповідно до цього міняє під нього певні елементи сайту. Monoloop автоматично створює профіль для кожного нового клієнта і дозволяє вибудовувати виразну і послідовну кампанію по роботі з ним. Сервіс запам'ятовує, що саме цікавить покупця, і може запропонувати інші відповідні товари з схожих категорій. Плюс він розуміє, на якому етапі ухвалення рішення про купівлю знаходиться покупець, і радить, що можна зробити, щоб підштовхнути покупця до купівлі.
Gravity [3] стартап покоління Web 3.0 – це версія веб, що має на увазі персоналізацію інтернету для кожного користувача. Він позиціонує себе як сервіс, що пропонує унікальний персоналізований досвід, який допомагає користувачам знаходити найцікавіший контент на основі їх індивідуальних потреб. На початковому етапі сервіс був орієнтований на кінцевих споживачів, але нині зосереджений тільки на B2B (рекламодавці і видавці). Персоналізація Gravity полягає в застосуванні різних фільтрів в режимі "реального часу" до інформації, доступної користувачам в пошуку і соціальних медіа. Запатентована Gravity технологія створює Interest Graph на базі інтересів, переваг і звичок користувача, і дозволяє власникам сайтів запропонувати своїм читачам редакторський і рекламний контент, що відповідає їх інтересам.
Persuasion API [4] відрізняється від інших сервісів персоналізації тим, що робить акцент на застосуванні прийомів психології переконання. Ставши їх клієнтами, ви автоматично отримуєте безкоштовний курс, що пояснює, як саме можна впливати на потенційних покупців. Наприклад, можна давити на терміновість, використати думку авторитету або прив'язати соціальний елемент. Ще одна особливість Persuasion API – уміння автоматично міняти тактику, якщо перша не спрацювала. Сервіс відстежує поведінку користувача, причому навіть якщо він заходить на сайт з різних девайсів, і записує їх в його профайл. Усіх потенційних і реальних клієнтів можна сегментувати і застосовувати до окремого сегменту або конкретного користувача відповідний тип переконання. Потім можна проаналізувати, на які групи які акції діють краще, хто у результаті більше купує, і використати вдалі стратегії надалі.
У роботі [5] запропонована масова рекомендаційна система (МРС), що не вимагає перепрограмування CMS, яка легко інтегрується у веб-сайт. Обробка призначеної для користувача інформації, що поступає, здійснюється на основі SaaS-технології (Software as a service) – на веб-сайті встановлюється тільки результуючий інтерфейс (блок рекомендованих посилань), а зберігання і обробка призначених для користувача даних здійснюється на сторонньому сервері МРС. Для установки МРС необхідно усього лише зареєструватися на веб-сайті проекту, настроїти зовнішній вигляд блоку посилань і вставити отриманий html-код і javascript-код в потрібне місце свого веб-сайту.
У статті [6] розглядається проблема поліпшення пошукових і навігаційних систем. Для її вирішення пропонується використати інформаційний портрет користувача. Описується метод побудови і застосування такого портрету, який заснований на ключових словах. Наводяться результати експериментів, що показують його працездатність. Робиться висновок про те, що системи, що використовують інформаційний портрет дають кращі результати, ніж системи без персоніфікації.
5.2 Національний рівень
На національному рівні роботи із створення засобів персоналізації Web сайтів і рекомендаційних систем ведуться в університетах і академічних інститутах.
У роботі [7] розглянуто питання розробки рекомендаційної системи з використанням комбінованого колаборативного підходу для інформаційного онлайн ресурсу.
У роботі [8] проведений аналіз сучасних пошукових систем, а також систем надання рекомендацій. Вибраний явний збір даних. Розроблена і програмно реалізована адаптивна пошукова система, яка базується на явному зборі даних про уподобання користувача.
У роботі [9] проведений аналіз існуючих методів інформаційного пошуку і запропонована процедура фільтрації по схожості образів основному грунтовану на вже розглянутому матеріалі. Головна ідея полягає в тому, щоб для кожного образу заздалегідь вичислити більшість схожих на нього. Тоді для створення рекомендацій користувачеві досить буде знайти ті зразки, яким він виставив високі оцінки, і створити зважений список зразків, які були б максимально схожими на ці. Коллоборативная фільтрація використовує схожість думок різних користувачів для видачі рекомендацій по об'єктах. Вона грунтується на тому факті, що людські пристрасті не розподіляються випадковим чином: в думках групи людей простежуються загальні тенденції.
5.3 Локальний рівень
На локальному рівні, в межах ДонНТУ, наукові розробки в області рекомендаційних систем і персоналізації є новими, проте є ряд робіт по близькому напряму пов'язаному з кластеризацією текстових документів [10-11].
6. Стислий виклад особистих результатів
6.1 Модель персоналізації і алгоритм управління контентом веб-сайту на основі оцінки потреб користувача
Розглядається варіант персоналізації веб-сайту, що припускає автоматичне надання конкретному користувачеві посилань на сторінки з інформацією, що цікавить його. При відвідуванні сайту користувач намагається задовольнити свої потреби в інформації, причому деяка інформація може бути потрібна йому в кожному сеансі, а до деякої він може звертатися, тільки в поточному сеансі. З урахуванням цього безліч рекомендованих системою посилань можна представити в наступному вигляді:
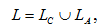
де L – множина рекомендованих кінцевому користувачеві посилань;
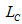 – множина посилань на сторінки, що задовольняють постійні потреби;
– множина посилань на сторінки, що задовольняють постійні потреби;
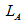 – множина посилань на сторінки, що задовольняють поточні потреби.
– множина посилань на сторінки, що задовольняють поточні потреби.
Множина посилань може складатися як з раніше за проглянутих  , так і непроглянутих сторінок
, так і непроглянутих сторінок 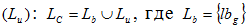 – множина g-их посилань на проглянуті кінцевим користувачем сторінки, що відповідають постійним потребам.
– множина g-их посилань на проглянуті кінцевим користувачем сторінки, що відповідають постійним потребам.
 – множина j-их посилань на непроглянуті кінцевим користувачем сторінки, що відповідають постійним потребам.
– множина j-их посилань на непроглянуті кінцевим користувачем сторінки, що відповідають постійним потребам.
Розрахунок приналежності раніше проглянутої сторінки  множині
множині 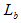 пропонується здійснювати на основі коефіцієнту лінійної кореляції між порядковим номером сеансу, що мали місце у кінцевого користувача, і кількістю сеансів, в яких була проглянута аналізована сторінка:
пропонується здійснювати на основі коефіцієнту лінійної кореляції між порядковим номером сеансу, що мали місце у кінцевого користувача, і кількістю сеансів, в яких була проглянута аналізована сторінка:
 ,(1)
,(1) де  – коефіцієнт лінійної кореляції для сторінки ;
– коефіцієнт лінійної кореляції для сторінки ;
b – кількість сеансів;
l – порядковий номер сеансу,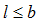 ;
;
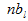 – кількість сеансів, в яких мав місце перегляд сторінки .
– кількість сеансів, в яких мав місце перегляд сторінки .
Якщо є яскраво виражений кореляційний зв'язок 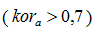 , то відповідно до шкали Чеддока заноситься в множину і ранжирується відповідно до величини зв'язку.
, то відповідно до шкали Чеддока заноситься в множину і ранжирується відповідно до величини зв'язку.
Виявлення сторінок, які раніше не були видимі конкретним користувачем, але що задовольняють його постійним потребам, можна здійснювати з урахуванням сукупності пошукових запитів (пошукового профілю), що мали місце у інших користувачів.
Пошуковий запит є формалізованим на природній для користувача мові описом його потреби, тому до користувачів зі схожими потребами можна віднести таких користувачів, у яких схожі пошукові профілі. Можна припустити, що найбільш вагомі сторінки, які були проглянуті користувачами з схожими пошуковими профілями, можуть відноситися до сфери їх загальних постійних інтересів. Щоб виявити такі сторінки необхідно вирішити наступні завдання:
- провести кластеризацію пошукових профелів;
- розширити пошуковий профіль на основі відповідного кластера;
- виявити найбільш важливі сторінки за розширеним пошуковим профелем.
Приклад кластерів для двомірного випадку наведений на рис. 1.

Рисунок 1. Приклад кластерів для простих пошукових профелів
(анімація: 7 кадрів, 12 циклів повтору, 19Kb)
Кластеризацію пошукових профелів, як і усі вказані завдання, можна виконувати в офф-лайн режимі. В цьому випадку ініціація процесу кластеризації не залежить від моменту звернення користувача. Запуск процесу можна робити періодично в заздалегідь розраховані періоди часу, коли сервер найменш завантажений. При виборі алгоритму кластеризації необхідно враховувати обмеженість часових і обчислювальних ресурсів.
Відповідно до особливостей масиву пошукових профелів, що обробляється за допомогою кластеризації, виділені наступні основні вимоги до алгоритму кластеризації:
- робота з категорійними даними;
- автоматичне визначення оптимальної кількості кластерів;
- висока швидкість обробки великих об'ємів даних;
- стійкість до викидів;
- мінімальне призначене для користувача налаштування;
- детермінованість.
При виборі порівнювалися наступні алгоритми кластеризації: CURE, BIRCH, MST, k-means, PAM, CLOPE, HCM, Fuzzy C-means, WaveCluster. Загальна характеристика алгоритмів приведена в табл. 1.
Таблица 1. Характеристики методів кластеризації.
| Метод | Переваги | Недоліки |
| CURE | – кластеризація високого рівня навіть за наявності викидів;
– виділення кластерів складної форми і різних розмірів; – має лінійно залежні вимоги до місця зберігання даних і тимчасову складність для даних високої розмірності. |
– працює тільки з числовими даними;
– необхідність в завданні порогових значень і кількості кластерів. |
| BIRCH | – двоступінчата кластеризація;
– кластеризація великих об'ємів даних; – працює на обмеженому об'ємі пам'яті; – є локальним алгоритмом; – може працювати при одному скануванні вхідного набору даних; – дані можуть бути неоднаково розподілені по простору; – обробляє області з великою щільністю як єдиний кластер. |
– працює тільки з числовими даними;
– добре виділяє тільки кластери опуклої або сферичної форми; – необхідність в завданні порогових значень. |
| MST | – працює з великими наборами довільних даних;
– виділяє кластери довільної форми (опуклою і увігнутою форм); – вибирає з декількох оптимальних рішень краще. |
– чутливий до викидів. |
| k-means | – простота використання;
– швидкість роботи; – зрозумілість і прозорість алгоритму. |
– чутливий до викидів;
– повільна робота на великих об'ємах; – необхідно задавати кількість кластерів; – неможливість застосування на даних, де є пересічні кластери; – не гарантується досягнення глобального мінімуму; – робота алгоритму сильно залежить від вибраних початкових центрів кластерів, оптимальне значення яких не може бути відоме заздалегідь. |
| PAM | – простота використання;
– швидкість роботи; – зрозумілість і прозорість алгоритму; – менш чутливий до викидів порівняно з k – means. |
– необхідно задавати кількість кластерів;
– повільна робота на великих базах даних. |
| CLOPE | – кластеризація величезних наборів категорийных даних;
– масштабованість; – швидкість роботи; – якість кластеризації, що досягається використанням глобального критерію оптимізації на основі максимізації градієнта висоти гістограми кластера; – легко розраховується і інтерпретується; – малий об'єм ресурсів; – автоматично підбирає кількість кластерів; – регулюється одним параметром - коефіцієнтом відштовхування. |
|
| HCM | – легкість реалізації;
– обчислювальна простота. |
– завдання кількості кластерів;
– відсутність гарантії в знаходженні оптимального рішення. |
| Fuzzy C-means | – нечіткість при визначенні об'єкту в кластер дозволяє класифікувати пограничні об'єкти. | – обчислювальна складність;
– завдання кількості кластерів; – невизначеність з викидами. |
| WaveCluster | – може виявляти кластери довільних форм;
– не чутливий до шумів. |
– складність реалізації;
– застосуємо тільки до даних низької розмірності. |
Аналіз алгоритмів показує, що з усіх розглянутих тільки CLOPE задовольняє необхідним вимогам.
6.2 Загальні відомості про алгоритм CLOPE
CLOPE запропонований в 2002 році групою китайських вчених [12]. При цьому він забезпечує більш високу продуктивність і кращу якість кластеризації порівняно з багатьма ієрархічними алгоритмами.
Під терміном транзакція розуміється деякий довільний набір об'єктів: список ключових слів статті, товари, куплені в супермаркеті, безліч симптомів пацієнта, характерні фрагменти зображення і так далі. Завдання кластеризації транзакційних даних полягає в отриманні такого розбиття усієї безлічі транзакцій, щоб схожі транзакції опинилися в одному кластері, а що відрізняються один від одного - в різних кластерах.
У основі алгоритму лежить ідея максимізації глобальної функції вартості, яка підвищує близькість транзакцій в кластерах за допомогою збільшення параметру кластерної гістограми. Суть алгоритму розглянемо на простому прикладі з 5 транзакцій: {(a,b), (a,b,c), (a,c,d), (d,e), (d,e,f)}. Нехай необхідно порівняти наступні два розбиття на кластери:
(1) {{ab, abc, acd}, {de, def}}
(2) {{ab, abc}, {acd, de, def}}
Для першого і другого варіантів розбиття в кожному кластері розрахуємо кількість входжень в нього кожного елементу транзакції, а потім вичислимо висоту (H) і ширину (W) кластера. Наприклад, кластер {ab, abc, acd} має входження a: 3, b: 2, c: 2 з H=2 і W=4. Для полегшення розуміння на рис. 2 ці результати показані геометрично у вигляді гістограм.
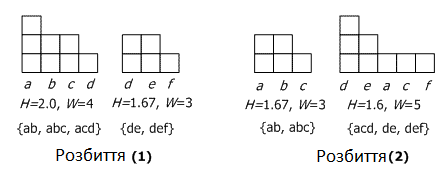
Рисунок 2. Гістограми двох розбиттів
Якість двох розбиття оцінимо, проаналізувавши їх висоту H і ширину W. Кластери {de, def} і {ab, abc} мають однакові гістограми, отже, рівноцінні. Гістограма для кластера {ab, abc, acd} містить 4 різні елементи і має площу 8 блоків (H=2.0, H/W=0.5), а кластер {acd, de, def} – 5 різних елементів з такою ж площею (H=1.6, H/W=0.32). Очевидно, що розбиття (1) краще, оскільки забезпечує більше накладення транзакцій один на одного (відповідно, параметр H там вище).
На основі такої очевидної і простої ідеї геометричних гістограм і працює алгоритм CLOPE (англ.: Clustering with sLOPE).
Кожен кластер C має наступні характеристики:
– D(C) – множина унікальних об'єктів;
– Occ(i,C) – кількість входжень (частота) об'єкту і в кластер C;
–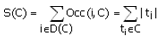 ;
;
– W(C) = |D(C)|;
– H(C) = S(C)/W(C).
Гістограмою кластера C називається графічне зображення його розрахункових характеристик: по осі OX відкладаються об'єкти кластера в порядку убування величини Occ (i, C), а сама величина Occ (i, C) - по осі OY (рис. 3).

Рисунок 3. Ілюстрація гістограми кластера
6.3 Застосування алгоритму CLOPE для кластеризації пошукових профелів
Розглянемо алгоритм CLOPE стосовно завдання кластеризації пошукових профелів.
Нехай:
 – множина пошукових профелів;
– множина пошукових профелів;
 – множина f-их пошукових запитів m-ого пошукового профіля;
– множина f-их пошукових запитів m-ого пошукового профіля;
 – множина кластерів, разбиваюча множину пошукових профелів
– множина кластерів, разбиваюча множину пошукових профелів  так, що
так, що  і
і 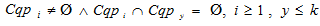 .
.
Кожний кластер 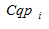 описується наступними характеристиками:
описується наступними характеристиками:
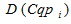 – множина унікальних пошукових запитів;
– множина унікальних пошукових запитів;
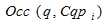 – частота вхожень пошукового запиту q в кластер .
– частота вхожень пошукового запиту q в кластер .
Завдання кластеризації зводиться до знаходження такого розбиття безлічі пошукових профелів на кластери, при якому глобальна функція вартості має максимальне значення:
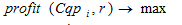 , (2)
, (2)где 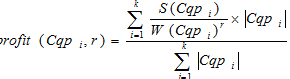 – глобальна функція вартості;
– глобальна функція вартості;
 – площа, яка зайнята гістограммою кластера;
– площа, яка зайнята гістограммою кластера;
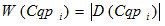 – ширина гістограмми кластера ;
– ширина гістограмми кластера ;
r – коефіцієнт відштовхування, позитивне натуральне число, r=2.
За допомогою параметра r, названого авторами CLOPE коефіцієнтом відштовхування (repulsion), регулюється рівень схожості транзакцій усередині кластера, і, як наслідок, фінальна кількість кластерів. Цей коефіцієнт підбирається користувачем. Чим більше r, тим нижче рівень схожості і тим більше кластерів буде згенеровано.
В результаті кластеризації пошуковий профіль кінцевого користувача опиниться в певному кластері  окажется в определенном кластере
окажется в определенном кластере 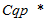 .
.
6.4 Алгоритм управління контентом з урахуванням постійних потреб користувача
При відвідуванні сайту, який користувач просмотрює у зв'язку з постійними інформаційними потребами, система управління контентом, що використовує персоналізацію, повинна пред'явити користувачеві список рекомендованих для перегляду сторінок, що включає дві групи посилань:
1) на вже раніше проглянуті сторінки для постійних потреб;
2) на нові сторінки, які не проглянуті, але можуть містити потрібну інформацію для постійних потреб.
Розглянемо алгоритм формування списку.
Формування першої групи посилань.
Крок 1. Для пред'явлення користувачеві не проглянутих сторінок, що відповідають постійній інформаційній потребі, робиться розширення його пошукового профілю. Для цього пошукові запити, що входять до складу кластера , ранжируються по частоті їх входження в кластер. У розширений пошуковий профіль 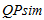 вибирається деяка кількість (lim) пошукових запитів з найбільшою частотою входження:
вибирається деяка кількість (lim) пошукових запитів з найбільшою частотою входження:
 , причому
, причому  , (3)
, (3)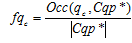 – частотність пошукового запиту
– частотність пошукового запиту 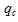 в кластері .
в кластері .
Крок 2. Далі формується безліч посилань  на сторінки, які були проглянуті іншими користувачами в сесіях з пошуковими запитами з кластера . Ранжирування посилань здійснюється відповідно до частотності пошукового запиту
на сторінки, які були проглянуті іншими користувачами в сесіях з пошуковими запитами з кластера . Ранжирування посилань здійснюється відповідно до частотності пошукового запиту  і релевантністю сторінки:
і релевантністю сторінки:
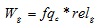 ,
, де 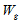 – вага посилання на сторінку
– вага посилання на сторінку 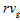 ;
;
– частотність пошукового заппиту ;
 – релевантність g-ої стрінки.
– релевантність g-ої стрінки.
Релевантність g-ої стрінки розраховується як відношення суми скалярних оцінок, отриманих в a-ої сессії до кількості сессій, в яких було зафиксовано звернення до g-ої сторінки:
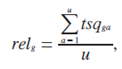
де u – кількість сессій, у яких мав місце перегляд g-ої стрінки;
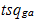 – оцінка релевантності g-ої сторінки для a-ої сессії [13].
– оцінка релевантності g-ої сторінки для a-ої сессії [13].
Оцінка релевантна грунтована на моделі переваг, представленій безліччю індикаторів виду:
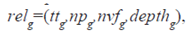
де 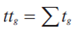 – сумарний час перебування на сторінці;
– сумарний час перебування на сторінці;
npg – кількість звернень до сторінки;
nvfg – кількість проглянутих користувачем фрагментів g-ої сторінки;
depthg – глибина просмотру g-ої стрінки;
Формування другої групи посилань.
Крок 1. Розрахунок приналежності раніше проглянутих сторінок постійним інтересам користувача. Для цього по (1) розраховується коефіцієнт лінійної кореляції між порядковим номером сеансів, що мали місце у користувача, і кількістю сеансів, в яких була проглянута аналізована сторінка. Сторінка належить інтересам користувача, якщо .
Крок 2. Ранжирування посилань на сторінки відповідно до величиною кореляційного зв'язку.
7. Напрями вдосконалення алгоритмічного забезпечення
Надалі передбачається розробити модель і засоби управління контентом для задоволення поточних потреб користувачів шляхом зіставлення поточного запиту з кластерами пошукових профелів, що об'єднують в собі користувачів з найбільш схожими потребами.
Висновки
Виконано аналіз методів кластеризації великих об'ємів даних і вибраний метод відповідний для вирішення завдання кластеризації пошукових профелів. Розроблений масштабований алгоритм, орієнтований на застосування в системах персоналізації для Web порталів. В результаті кластеризації встановлюються близькі пошукові профілі користувачів і на основі цього виявляються раніше не проглянуті користувачем сторінки що відповідають його постійним інформаційним потребам. Розроблене алгоритмічне забезпечення може використовуватися в системах персоналізації сайтів для представлення користувачам релевантного контенту.
При написанні даного реферату магістерська робота ще не завершена. Остаточне завершення: грудень 2014 року. Повний текст роботи та матеріали по темі можуть бути отримані у автора або його керівника після зазначеної дати.
Список джерел
- Personyze [Електроний ресурс]. – Режим доступу: http://www.personyze.ru
- Monoloop [Електроний ресурс]. – Режим доступу: https://www.monoloop.com
- Gravity [Електроний ресурс]. – Режим доступу: https://www.gravity.com
- Persuasion API [Електроний ресурс]. – Режим доступу: http://www. persuasionapi.com
- Царев А.Г. Массовая рекомендательная система для веб-сайтов на основе SAAS-технологии. / А.Г. Царев, Г.К. Сафаралиева, А.Н. Андреева, В.А. Казакова // Труды II международной научно-практической интернет-конференции – Пенза: Издательство Пензенского филиала РГУИТП, 2010. – 374-375 c.
- Широков А.В. Разработка модели информационного портрета пользователя для персонифицированного поиска [Електроний ресурс]. – Режим доступу: http://download.yandex.ru/IMAT2007/shirokov.pdf
- Радчук О.В. Деякі питання розробки рекомендаційної системи для інформаційного сайту. / О.В. Радчук, Технічні науки // Інноваційні технології, 2013.
- Маслова З.І. Розроблення та програмна реалізація адаптивної пошукової системи для електронного журналу / З.І. Маслова, В.С. Коваленко // Вісник Сумського державного університету. Серія Технічні науки. – №3, 2011. – 122-125 c.
- Лєсна Н.С. Методи пошуку та фільтрації інформації з використанням методу колаборативної фільтрації. / Н.С. Лєсна, С.М. Гайдамака // Системи обробки інформації. –№5, 2013. – 112 с.
- Егошина А.А., Линкин В.О., Арбузова О.В. – Система извлечения информации об однотипных объектах из массивов текстовых документов [Електроний ресурс]. – Режим доступу: http://masters.donntu.ru/2013/fknt/linkin/library/linkin.htm
- Егошина А.А. Использование алгоритма кластеризации lsa/lsi для решения задачи автоматического построения онтологий. / А.А. Егошина, Е.В. Орлова, Р.И. Дмуховский // Информационные управляющие системы и компьютерный мониторинг (ИУС-2012) / Материалы международной научно-технической конференции студентов и молодых учёных. – Донецк, ДонНТУ – 2012, 173-176 c.
- Yang Y. CLOPE: A fast and Effective Clustering Algorithm for Transactional Data In Proc of SIGKDD’02 / Y. Yang, H. Guan, J. You // July 23-26, – Edmonton, Alberta, Canada, 2002
- Царев А.Г. Модель индикатора предпочтений конечного пользователя веб-сайта на основе многокритериальной комплексной оценки альтернатив. / А.Г. Царев // Мониторинг. Наука и технологии. – №3, 2010. – 68-69 с.
- Monoloop [Електроний ресурс]. – Режим доступу: https://www.monoloop.com