
Реферат по теме выпускной работы
Содержание
- 1. Цель и задачи
- 2. Актуальность темы
- 3. Предполагаемая научная новизна
- 4. Планируемые практические результаты
- 5. Обзор исследований и разработок теме
- 5.1 Глобальный уровень
- 5.2 Национальный уровень
- 5.3 Локальный уровень
- 6. Краткое изложение собственных результатов
- 6.1 Модель персонализации и алгоритм управления контентом веб-сайта на основе оценки потребностей пользователя
- 6.2 Общие сведения об алгоритме CLOPE
- 6.3 Применение алгоритма CLOPE для кластеризации поисковых профилей
- 6.4 Алгоритм управления контентом с учетом постоянных потребностей пользователя
- 7. Направления совершенствования алгоритмического обеспечения
- Выводы
- Список источников
1. Цель и задачи
Цель работы состоит в разработке модели персонализации сайта, основанной на анализе постоянных и текущих потребностей пользователей. Для достижения цели предлагается ввести в модель конечного пользователя его поисковый профиль и учитывать поисковые профили всей аудитории сайта в модели персонализации.
Для достижения поставленной цели не обходимо решение следующих задач:
1. Провести анализ существующих сервисов персонализации и методов предоставления релевантного для пользователя контента.
2. Выбрать алгоритм кластеризации поисковых и навигационных профилей пользователя.
3. Разработать модель персонализации и алгоритм управления контентом веб-сайта на основе оценки потребностей пользователя.
2. Актуальность темы
C развитием сети Интернет растет количество крупных сайтов с большим количеством страниц, гиперссылок и сложной структурой навигации. Информационная перегруженность страниц и их высокая функциональность приводят к тому, что пользователям становится сложнее ориентироваться, находить и осуществлять выбор интересующей (релевантной) информации. Для современных крупных Интернет-библиотек, Интернет-магазинов, государственных Веб-порталов, сайтов турагенств, поисковых сервисов и т.д. существует актуальная задача эффективной навигационной и поисковой поддержки пользователей. Эту задачу можно решать путем персонализации содержимого в соответствии с потребностями и особенностями поведения конечного пользователя.
Персонализация веб-страниц позволяет кардинально изменить отношение сайта к своим посетителям. В результате не только пользователь будет «общаться» с веб-страницей, но и сам сайт будет обращаться к любому, попавшему на страницу, не как к части общей массы, а как к конкретному человеку, имеющему свои личные интересы – персонально.
Услуги по персонализации сайтов, их автоматизированной адаптации под ожидания посетителей на рынке интернет-маркетинга существуют давно. Однако, по причине сложности в технической реализации процессов персонализации к этим работам привлекаются не сторонние организации, а собственные программисты. Сторонние сервисы (например Adobe Digital Marketing Suite или Google Analytics + Siteapps.com) выполняют ограниченное число действий по персонализации сайта, которых обычно недостаточно для заметного повышения эффективности сайта.
Для качественной персонализации сайта необходимо использовать информацию не только о маркетинговых качествах посетителя, но и информацию из CRM и других внутренних баз данных каждого конкретного предприятия. В этом случае появляется намного больше метрик и измерений для описания сегмента посетителя и выполнения правила персонализации.
Предполагается, что, посещая сайт, конечный пользователь пытается удовлетворить некоторую известную ему совокупность потребностей. Причем одни потребности могут иметь постоянный характер вне зависимости от частоты сеансов, а другие нет. Исходя из этого, потребности разделяются на постоянные (не зависящие от сеанса) и текущие (сеансозависимые). Очевидно, что подходы к персонализации, должны учитывать характер потребностей пользователя.
При персонализации, учитывающей постоянные потребности, как правило сохраняется история поисковых запросов и просмотренных страниц пользователя (навигационный профиль). Выявление ранее непросмотренных конечным пользователем страниц, но удовлетворяющих его постоянным потребностям может осуществлять с учетом совокупности поисковых запросов, имевших место у того или иного пользователя с похожими навигационными профилями.
Примером персонализации на основе текущих потребностей являются популярные в настоящее время рекомендательные системы, которые работают на основе поисковых профилей пользователей. При этом часто компании используют специально созданные, встроенные в веб-сайт рекомендательные системы. Для интеграции рекомендательной системы с выбранным веб-сайтом необходимы координальные изменения его системы управления данными (CMS). Одним из прогрессивных подходов к упрощению интеграции рекомендательных систем с сайтами является использование SaaS-технологии (Software as a service).
Недостатком существующих средств персонализации является ориентация только на текущие потребности пользователей, что снижает точность сформированных системой персонализации рекомендаций. В связи с этим актуальной является задача разработки комбинированной модели персонализации и алгоритмов управления контентом сайтов, учитывающих постоянные и текущие потребности пользователей.
3. Предполагаемая научная новизна
Модель персонализации и алгоритм управления контентом сайтов, учитывающие его постоянные и текущие потребности, на основе комбинации навигационного и поискового профиля пользователя.
4. Планируемые практические результаты
На основе разработанной модели и алгоритмов предложена система персонализации, которая может интегрироваться с веб-сайтами для повышения эффективности доступа к релевантной для пользователя информации.
5. Обзор исследований и разработок по теме
5.1 Глобальный уровень
Многие компании предлагают сегодня услуги по персонализации. Рассмотрим краткую характеристику доступных сегодня инструментов, которые ориентированы на удобную интеграцию с веб-сайтом и не требуют квалифицированного программирования.
Сервис Personyze [1] создан для сегментирования посетителей сайта в режиме реального времени, а также для предоставления им персонализированного и оптимизированного контента, основанного на их демографических, поведенческих и исторических характеристиках. Personyze предлагает самую расширенную SaaS платформу на рынке персонализации сайтов и сегментации пользователей в режиме реального времени. Сразу после добавления кода можно в реальном времени видеть отчёты о поведении пользователей на сайте. Все посетители автоматически распределяются по сегментам в соответствии с их местоположением, источником посещений (включая конкретные ключевые запросы), демографическими данными, действиями на сайте и т.д. – всего около 50 метрик. Как только установлено соответствие посетителя и сегмента, Personyze выполняет необходимые персонализирующие действия, позволяющие вам менять любой фрагмент контента сайта, будь то добавление баннера, изменение картинки, изменение текста, добавление рекомендованных продуктов и многое другое. Посетитель будет видеть оптимизированную под него версию сайта. Сервис удобен тем, что позволяет работать с отдельными сегментами и предоставлять детализированные отчёты по каждому из них.
Создатели Monoloop [2] сконцентрированы на контроле за покупательским циклом. Установленный на сайт, их сервис отслеживает поведение каждого посетителя сайта, узнаёт его в момент следующего посещения и в соответствии с этим меняет под него определённые элементы сайта. Monoloop автоматически создаёт профиль для каждого нового клиента и позволяет выстраивать внятную и последовательную кампанию по работе с ним. Сервис запоминает, что именно интересует покупателя, и может предложить другие подходящие товары из схожих категорий. Плюс он понимает, на каком этапе принятия решения о покупке находится покупатель, и советует, что можно сделать, чтобы подтолкнуть покупателя к покупке.
Gravity [3] стартап поколения Web 3.0 — это версия веба, подразумевающая персонализацию интернета для каждого пользователя. Он позиционирует себя как сервис, предлагающий уникальный персонализированный опыт, который помогает пользователям находить наиболее интересный контент на основе их индивидуальных потребностей. На начальном этапе сервис был ориентирован на конечных потребителей, но в настоящее время сосредоточен только на B2B (рекламодатели и издатели). Персонализация Gravity заключается в применении различных фильтров в режиме «реального времени» к информации, доступной пользователям в поиске и социальных медиа. Запатентованная Gravity технология создает Interest Graph на базе интересов, предпочтений и привычек пользователя, и позволяет владельцам сайтов предложить своим читателям редакторский и рекламный контент, соответствующий их интересам.
Persuasion API [4] отличается от остальных сервисов персонализации тем, что делает акцент на применении приёмов психологии убеждения. Став их клиентами, вы автоматически получаете бесплатный курс, объясняющий, как именно можно влиять на потенциальных покупателей. Например, можно давить на срочность, использовать мнение авторитета или привязать социальный элемент. Ещё одна особенность Persuasion API — умение автоматически менять тактику, если первая не сработала. Сервис отслеживает поведение пользователя, причём даже если он заходит на сайт с различных девайсов, и записывает их в его профайл. Всех потенциальных и реальных клиентов можно сегментировать и применять к отдельному сегменту или конкретному пользователю соответствующий тип убеждения. Затем можно проанализировать, на какие группы какие акции действуют лучше, кто в итоге больше покупает, и использовать удачные стратегии в дальнейшем.
В работе [5] предложена массовая рекомендательная система (МРС), не требующая перепрограммирования CMS, которая легко интегрируется в веб-сайт. Обработка поступающей пользовательской информации осуществляется на основе SaaS-технологии (Software as a service) — на веб-сайте устанавливается только результирующий интерфейс (блок рекомендуемых ссылок), а хранение и обработка пользовательских данных осуществляется на стороннем сервере МРС. Для установки МРС необходимо всего лишь зарегистрироваться на веб-сайте проекта, настроить внешний вид блока ссылок и вставить полученный html-код и javascript-код в нужное место своего веб-сайта.
В статье [6] рассматривается проблема улучшения поисковых и навигационных систем. Для ее решения предлагается использовать информационный портрет пользователя. Описывается метод построения и применения такого портрета, основанный на ключевых словах. Приводятся результаты экспериментов, показывающих его работоспособность. Делается вывод о том, что системы, использующие информационный портрет дают лучшие результаты, чем системы без персонификации.
5.2 Национальный уровень
На национальном уровне работы по созданию средств персонализации Web сайтов и рекомендательных систем ведутся в университетах и академических институтах.
В работе [7] рассмотрен вопрос разработки рекомендательной системы с использованием комбинированного колаборативних подхода для информационного онлайн ресурса.
В работе [8] проведен анализ современных поисковых систем, а также систем предоставления рекомендаций. Выбранный явный сбор данных. Разработана и программно реализована адаптивная поисковая система, которая базируется на явном сборе данных о предпочтениях пользователя.
В работе [9] проведен анализ существующих методов информационного поиска и предложена процедура фильтрации по схожести образов основном основанную на уже рассмотренном материале. Главная идея заключается в том, чтобы для каждого образа заранее вычислить большинство похожих на него. Тогда для создания рекомендаций пользователю достаточно будет найти те образцы, которым он выставил высокие оценки, и создать взвешенный список образцов, которые были бы максимально похожими на эти. Коллоборативная фильтрация использует сходство мнений различных пользователей для выдачи рекомендаций по объектам. Она основывается на том факте, что человеческие пристрастия не распределяются случайным образом: в мыслях группы людей прослеживаются общие тенденции.
5.3 Локальный уровень
На локальном уровне, в пределах ДонНТУ, научные разработки в области рекомендательных систем и персонализации являются новыми, однако есть ряд работ по близкому направлению связанному с кластеризацией текстовых документов [10-11].
6. Краткое изложение собственных результатов
6.1 Модель персонализации и алгоритм управления контентом веб-сайта на основе оценки потребностей пользователя
Рассматривается вариант персонализации веб-сайта, предполагающий автоматическое предоставление конкретному пользователю ссылок на страницы с интересующей его информацией. При посещении сайта пользователь пытается удовлетворить свои потребности в информации, причем некоторая информация может требоваться ему в каждом сеансе, а к некоторой он может обращаться, только в текущем сеансе. С учетом этого множество рекомендуемых системой ссылок можно представить в следующем виде:
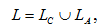
где L — множество рекомендуемых конечному пользователю ссылок;
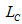 — множество ссылок на страницы, удовлетворяющих постоянные потребности;
— множество ссылок на страницы, удовлетворяющих постоянные потребности;
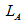 — множество ссылок на страницы, удовлетворяющих текущие потребности.
— множество ссылок на страницы, удовлетворяющих текущие потребности.
Множество ссылок может состоять как из ранее просмотренных  , так и непросмотренных страниц
, так и непросмотренных страниц 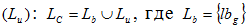 — множество g-ых ссылок на просмотренные конечным пользователем страницы, отвечающих постоянным потребностям.
— множество g-ых ссылок на просмотренные конечным пользователем страницы, отвечающих постоянным потребностям.
 — множество j-ых ссылок на непросмотренные конечным пользователем страницы, отвечающих постоянным потребностям.
— множество j-ых ссылок на непросмотренные конечным пользователем страницы, отвечающих постоянным потребностям.
Расчет принадлежности ранее просмотренной страницы  множеству
множеству 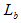 предлагается осуществлять на основе коэффициента линейной корреляции между порядковым номером сеанса, имевших место у конечного пользователя, и количеством сеансов, в которых была просмотрена анализируемая страница:
предлагается осуществлять на основе коэффициента линейной корреляции между порядковым номером сеанса, имевших место у конечного пользователя, и количеством сеансов, в которых была просмотрена анализируемая страница:
 , (1)
, (1) где  — коэффициент линейной корреляции для страницы;
— коэффициент линейной корреляции для страницы;
b — количество сеансов;
l — порядковый номер сеанса,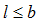 ;
;
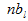 — количество сеансов, в которых имел место просмотр страницы .
— количество сеансов, в которых имел место просмотр страницы .
Если имеется ярко выраженная корреляционная связь 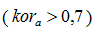 , то в соответствии со шкалой Чеддока заносится в множество и ранжируется в соответствии с величиной связи.
, то в соответствии со шкалой Чеддока заносится в множество и ранжируется в соответствии с величиной связи.
Выявление страниц, которые ранее не просматривались конкретным пользователем, но удовлетворяющих его постоянным потребностям, можно осуществлять с учетом совокупности поисковых запросов (поискового профиля), имевших место у иных пользователей.
Поисковый запрос является формализованным на естественном для пользователя языке описанием его потребности, поэтому к пользователям с похожими потребностями можно отнести таких пользователей, у которых похожи поисковые профили. Можно предположить, что наиболее весомые страницы, которые были просмотрены пользователями с похожими поисковыми профилями, могут относиться к сфере их общих постоянных интересов. Чтобы выявить такие страницы необходимо решить следующие задачи:
- провести кластеризацию поисковых профилей;
- расширить поисковый профиль на основе соответствующего кластера;
- выявить наиболее важные страницы по расширенному поисковому профилю.
Пример кластеров для двухмерного случая приведен на рис. 1.

Рисунок 1 Пример кластеров для простейших поисковых профилей
(анимация: 7 кадров, 12 циклов повторений, 19Kb)
Кластеризацию поисковых профилей, как и все указанные задачи, можно выполнять в офф-лайн режиме. В этом случае инициация процесса кластеризации не зависит от момента обращения пользователя. Запуск процесса можно производить периодически в заранее рассчитанные периоды времени, когда сервер наименее загружен. При выборе алгоритма кластеризации необходимо учитывать ограниченность временных и вычислительных ресурсов.
В соответствии с особенностями массива поисковых профилей, обрабатываемого посредством кластеризации, выделены следующие основные требования к алгоритму кластеризации:
- работа с категорийными данными;
- автоматическое определение оптимального количества кластеров;
- высокая скорость обработки больших объемов данных;
- стойкость к выбросам;
- минимальная пользовательская настройка;
- детерминированность.
- Personyze [Электронный ресурс]. – Режим доступа: http://www.personyze.ru
- Monoloop [Электронный ресурс]. – Режим доступа: https://www.monoloop.com
- Gravity [Электронный ресурс]. – Режим доступа: https://www.gravity.com
- Persuasion API [Электронный ресурс]. – Режим доступа: http://www. persuasionapi.com
- Царев А.Г. Массовая рекомендательная система для веб-сайтов на основе SAAS-технологии. / А.Г. Царев, Г.К. Сафаралиева, А.Н. Андреева, В.А. Казакова // Труды II международной научно-практической интернет-конференции – Пенза: Издательство Пензенского филиала РГУИТП, 2010. – 374-375 c.
- Широков А.В. Разработка модели информационного портрета пользователя для персонифицированного поиска [Электронный ресурс]. – Режим доступа: http://download.yandex.ru/IMAT2007/shirokov.pdf
- Радчук О.В. Деякі питання розробки рекомендаційної системи для інформаційного сайту. / О.В. Радчук, Технічні науки // Інноваційні технології, 2013.
- Маслова З.І. Розроблення та програмна реалізація адаптивної пошукової системи для електронного журналу / З.І. Маслова, В.С. Коваленко // Вісник Сумського державного університету. Серія Технічні науки. – №3, 2011. – 122-125 c.
- Лєсна Н.С. Методи пошуку та фільтрації інформації з використанням методу колаборативної фільтрації. / Н.С. Лєсна, С.М. Гайдамака // Системи обробки інформації. –№5, 2013. – 112 с.
- Егошина А.А., Линкин В.О., Арбузова О.В. – Система извлечения информации об однотипных объектах из массивов текстовых документов [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2013/fknt/linkin/library/linkin.htm
- Егошина А.А. Использование алгоритма кластеризации lsa/lsi для решения задачи автоматического построения онтологий. / А.А. Егошина, Е.В. Орлова, Р.И. Дмуховский // Информационные управляющие системы и компьютерный мониторинг (ИУС-2012) / Материалы международной научно-технической конференции студентов и молодых учёных. – Донецк, ДонНТУ – 2012, 173-176 c.
- Yang Y. CLOPE: A fast and Effective Clustering Algorithm for Transactional Data In Proc of SIGKDD’02 / Y. Yang, H. Guan, J. You // July 23-26, – Edmonton, Alberta, Canada, 2002
- Царев А.Г. Модель индикатора предпочтений конечного пользователя веб-сайта на основе многокритериальной комплексной оценки альтернатив. / А.Г. Царев // Мониторинг. Наука и технологии. – №3, 2010. – 68-69 с.
- Monoloop [Электронный ресурс]. – Режим доступа: https://www.monoloop.com
При выборе сравнивались следующие алгоритмы кластеризации: CURE, BIRCH, MST, k-means, PAM, CLOPE, HCM, Fuzzy C-means, WaveCluster. Общая характеристика алгоритмов приведена в табл.1.
Таблица 1. Характеристики методов кластеризации
Метод
Достоинства
Недостатки
CURE
– кластеризация высокого уровня даже при наличии выбросов;
– выделение кластеров сложной формы и различных размеров;
– обладает линейно зависимыми требованиями к месту хранения данных и временную сложность для данных высокой размерности.– работает только с числовыми данными;
– необходимость в задании пороговых значений и количества кластеров.
BIRCH
– двухступенчатая кластеризация;
– кластеризация больших объемов данных;
– работает на ограниченном объеме памяти;
– является локальным алгоритмом;
– может работать при одном сканировании входного набора данных;
– данные могут быть неодинаково распределены по пространству;
– обрабатывает области с большой плотностью как единый кластер.– работает только с числовыми данными;
– хорошо выделяет только кластеры выпуклой или сферической формы;
– необходимость в задании пороговых значений.
MST
– работает с большими наборами произвольных данных;
– выделяет кластеры произвольной формы (выпуклой и вогнутой форм);
– выбирает из нескольких оптимальных решений лучшее.
– чувствителен к выбросам.
k-means
– простота использования;
– скорость работы;
– понятность и прозрачность алгоритма.
– чувствителен к выбросам;
– медленная работа на больших объёмах;
– необходимо задавать количество кластеров;
– невозможность применения на данных, где есть пересекающиеся кластеры;
– не гарантируется достижение глобального минимума;
– работа алгоритма сильно зависит от выбранных начальных центров кластеров, оптимальное значение которых не может быть известно заранее.
PAM
– простота использования;
– скорость работы;
– понятность и прозрачность алгоритма;
– менее чувствителен к выбросам в сравнении с k-means.
– необходимо задавать количество кластеров;
– медленная работа на больших базах данных.
CLOPE
– кластеризация огромных наборов категорийных данных;
– масштабируемость;
– скорость работы;
– качество кластеризации, что достигается использованием глобального критерия оптимизации на основе максимизации градиента высоты гистограммы кластера;
– легко рассчитывается и интерпретируется;
– малый объём ресурсов;
– автоматически подбирает количество кластеров;
– регулируется одним параметром - коэффициентом отталкивания.
HCM
– легкость реализации;
– вычислительная простота.
– задание количества кластеров;
– отсутствие гарантии в нахождении оптимального решения.
Fuzzy C-means
– нечеткость при определении объекта в кластер позволяет классифицировать пограничные объекты.
– вычислительная сложность;
– задание количества кластеров;
– неопределённость с выбросами.
WaveCluster
– может обнаруживать кластеры произвольных форм;
– не чувствителен к шумам.
– сложность реализации;
– применим только к данным низкой размерности.
Анализ алгоритмов показывает, что из всех рассмотренных только CLOPE удовлетворяет необходимым требованиям.
6.2 Общие сведения об алгоритме CLOPE
CLOPE предложен в 2002 году группой китайских ученых [12]. При этом он обеспечивает более высокую производительность и лучшее качество кластеризации в сравнении с многими иерархическими алгоритмами.
Под термином транзакция понимается некоторый произвольный набор объектов: список ключевых слов статьи, товары, купленные в супермаркете, множество симптомов пациента, характерные фрагменты изображения и так далее. Задача кластеризации транзакционных данных состоит в получении такого разбиения всего множества транзакций, чтобы похожие транзакции оказались в одном кластере, а отличающиеся друг от друга — в разных кластерах.
В основе алгоритма лежит идея максимизации глобальной функции стоимости, которая повышает близость транзакций в кластерах при помощи увеличения параметра кластерной гистограммы. Суть алгоритма рассмотрим на простом примере из 5 транзакций: {(a,b), (a,b,c), (a,c,d), (d,e), (d,e,f)}. Пусть необходимо сравнить следующие два разбиения на кластеры:
(1) {{ab, abc, acd}, {de, def}}
(2) {{ab, abc}, {acd, de, def}}
Для первого и второго вариантов разбиения в каждом кластере рассчитаем количество вхождений в него каждого элемента транзакции, а затем вычислим высоту (H) и ширину (W) кластера. Например, кластер {ab, abc, acd} имеет вхождения a:3, b:2, c:2 с H=2 и W=4. Для облегчения понимания на рис. 2 эти результаты показаны геометрически в виде гистограмм.
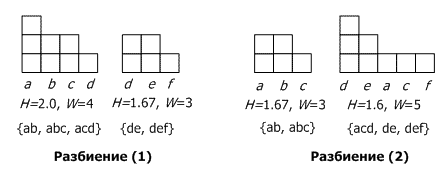
Рисунок 2. Гистограммы двух разбиений
Качество двух разбиений оценим, проанализировав их высоту H и ширину W. Кластеры {de, def} и {ab, abc} имеют одинаковые гистограммы, следовательно, равноценны. Гистограмма для кластера {ab, abc, acd} содержит 4 различных элемента и имеет площадь 8 блоков (H=2.0, H/W=0.5), а кластер {acd, de, def} – 5 различных элементов с такой же площадью (H=1.6, H/W=0.32). Очевидно, что разбиение (1) лучше, поскольку обеспечивает большее наложение транзакций друг на друга (соответственно, параметр H там выше).
На основе такой очевидной и простой идеи геометрических гистограмм и работает алгоритм CLOPE (англ.: Clustering with sLOPE).
Каждый кластер C имеет следующие характеристики:
– D(C) – множество уникальных объектов;
– Occ(i,C) – количество вхождений (частота) объекта i в кластер C;
– 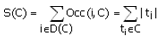 ;
;
– W(C) = |D(C)|;
– H(C) = S(C)/W(C).
Гистограммой кластера C называется графическое изображение его расчетных характеристик: по оси OX откладываются объекты кластера в порядке убывания величины Occ(i,C), а сама величина Occ(i,C) – по оси OY (рис. 3).

Рисунок 3. Иллюстрация гистограммы кластера
6.3 Применение алгоритма CLOPE для кластеризации поисковых профилей
Рассмотрим алгоритм CLOPE применительно к задаче кластеризации поисковых профилей.
Пусть:
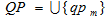 – множество поисковых профилей;
– множество поисковых профилей;
 – множество f-ых поисковых запросов m-ого поискового профиля;
– множество f-ых поисковых запросов m-ого поискового профиля;
 – множество кластеров, разбивающее множество поисковых профилей
– множество кластеров, разбивающее множество поисковых профилей 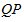 так, что
так, что  и
и 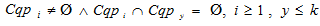 .
.
Каждый кластер 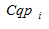 описывается следующими характеристиками:
описывается следующими характеристиками:
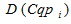 – множество уникальных поисковых запросов;
– множество уникальных поисковых запросов;
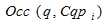 – частота вхождений поискового запроса q в кластер .
– частота вхождений поискового запроса q в кластер .
Задача кластеризации сводится к нахождению такого разбиения множества поисковых профилей на кластеры, при котором глобальная функция стоимости имеет максимальное значение:
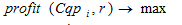 , (2)
, (2)где 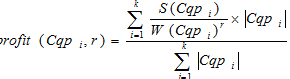 – глобальная функция стоимости;
– глобальная функция стоимости;
 – площадь, занимаемая гистограммой кластера;
– площадь, занимаемая гистограммой кластера;
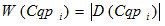 – ширина гистограммы кластера ;
– ширина гистограммы кластера ;
r – коэффициент отталкивания, положительное натуральное число, r=2 .
С помощью параметра r, названного авторами CLOPE коэффициентом отталкивания (repulsion), регулируется уровень сходства транзакций внутри кластера, и, как следствие, финальное количество кластеров. Этот коэффициент подбирается пользователем. Чем больше r, тем ниже уровень сходства и тем больше кластеров будет сгенерировано.
В результате кластеризации поисковый профиль конечного пользователя 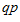 окажется в определенном кластере
окажется в определенном кластере 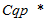 .
.
6.4 Алгоритм управления контентом с учетом постоянных потребностей пользователя
При посещении сайта, который просматривается пользователем в связи с постоянными информационными потребностями, система управления контентом, использующая персонализацию, должна предъявить пользователю список рекомендуемых для просмотра страниц, включающий две группы ссылок:
1) на уже ранее просмотренные страницы для постоянных потребностей;
2) на новые страницы, которые не просмотрены, но могут содержать нужную информацию для постоянных потребностей.
Рассмотрим алгоритм формирования списка.
Формирование первой группы ссылок.
Шаг 1. Для предъявления пользователю не просмотренных страниц, соответствующих постоянной информационной потребности, производится расширение его поискового профиля. Для этого поисковые запросы, входящие в состав кластера , ранжируются по частоте их вхождения в кластер. В расширенный поисковый профиль 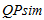 выбирается некоторое количество (lim) поисковых запросов с наибольшей частотой вхождения:
выбирается некоторое количество (lim) поисковых запросов с наибольшей частотой вхождения:
 , причем
, причем  , (3)
, (3)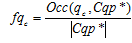 – частотность поискового запроса
– частотность поискового запроса 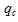 в кластере .
в кластере .
Шаг 2. Далее формируется множество ссылок  на страницы, которые были просмотрены другими пользователями в сессиях с поисковыми запросами из кластера . Ранжирование ссылок осуществляется в соответствии с частотностью поискового запроса
на страницы, которые были просмотрены другими пользователями в сессиях с поисковыми запросами из кластера . Ранжирование ссылок осуществляется в соответствии с частотностью поискового запроса  и релевантностью страницы:
и релевантностью страницы:
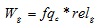 ,
, где 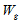 – вес ссылки на страницу
– вес ссылки на страницу 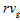 ;
;
– частотность поискового запроса ;
 – релевантность g-ой страницы.
– релевантность g-ой страницы.
Релевантность g-ой страницы рассчитывается как отношение суммы скалярных оценок, полученных в a-ой сессии к количеству сессий, в которых было зафиксировано обращение к g-ой странице:
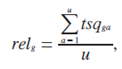
где u – количество сессий, в которых имел место просмотр g-ой страницы;
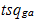 – оценка релевантности g-ой страницы для a-ой сессии [13].
– оценка релевантности g-ой страницы для a-ой сессии [13].
Оценка релевантности основана на модели предпочтений, представленной множеством индикаторов вида
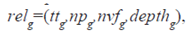
где 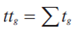 – суммарное время пребывания на странице;
– суммарное время пребывания на странице;
npg – количество обращений к странице;
nvfg – количество просмотренных пользователем фрагментов g-ой страницы;
depthg – глубина просмотра g-ой страницы;
Формирование второй группы ссылок.
Шаг 1. Расчет принадлежности ранее просмотренных страниц постоянным интересам пользователя. Для этого по (1) расчитывается коэффициент линейной корреляции между порядковым номером сеансов, имевших место у пользователя, и количеством сеансов, в которых была просмотрена анализируемая страница. Страница принадлежит интересам пользователя, если .
Шаг 2. Ранжирование ссылок на страницы в соответствии с величиной корреляционной связи.
7. Направления совершенствования алгоритмического обеспечения
В дальнейшем предполагается разработать модель и средства управления контентом для удовлетворения текущих потребностей пользователей путем сопоставления текущего запроса с кластерами поисковых профилей, объединяющих в себе пользователей с наиболее схожими потребностями.
Выводы
Выполнен анализ методов кластеризации больших объемов данных и выбран метод подходящий для решения задачи кластеризации поисковых профилей. Разработан масштабируемый алгоритм, ориентированный на применение в системах персонализации для Web порталов. В результате кластеризации устанавливаются близкие поисковые профили пользователей и на основе этого выявляются ранее не просмотренные пользователем страницы соответствующие его постоянным информационным потребностям. Разработанное алгоритмическое обеспечение может использоваться в системах персонализации сайтов для представления пользователям релевантного контента.
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: декабрь 2014 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.