
Реферат за темою випускної роботи
Зміст
- Вступ
- 1. Актуальність теми
- 2. Мета і задачі дослідження та заплановані результати
- 3. Огляд досліджень та розробок
- 3.1 Огляд міжнародних джерел
- 3.2 Огляд національних джерел
- 3.3 Огляд локальних джерел
- 4. Підхід до стиснення російського тексту з використанням віддалено розміщених словників
- Висновки
- Список джерел
Вступ
Протягом останніх трьох десятиліть стався різкий стрибок у розвитку мережі Інтернет та її поширенні – збільшенні кількості підключених до неї комп'ютерів. У сукупності зі зростаючою кількістю користувачів, це призвело до значного збільшення обсягів інформації, що передається та зберігається.
У зв'язку з триваючим зростанням глобальних мереж і розширенням спектра надаваних ними послуг при експоненційному зростанні числа користувачів мереж, а також успішними проектами з перекладу в цифровий вигляд вмісту величезних сховищ інформації, зокрема бібліотек, виставкових залів і художніх галерей, слід очікувати, що обсяги збереженої і переданої системами зв'язку інформації будуть продовжувати збільшуватися з такою ж або навіть ще більшою швидкістю [1]. Цей процес ставить нові завдання, що вимагають свого вирішення – такі обсяги інформації необхідно зберігати, обробляти і передавати в найбільш компактному вигляді. Звідси виникає завдання стиснення інформації різних типів, в тому числі і текстової.
1. Актуальність теми
За десятиліття розвитку комп'ютерних технологій завдання стиснення даних з різним ступенем успішності вирішувалася різними архиваторами. Різна ступінь успішності зумовлена тим, що архіватори, хоч і розробляються для вирішення однієї загальної задачі (стиснення даних), мають явно відмінні підходи до її вирішення і приймають різні типи даних в якості вихідних. Таким чином, архіватори бувають як загального призначення (працюють з різними типами даних), так і призначеними для конкретних типів даних.
Архіватори загального призначення стискають текстові дані, але виконують це завдання менш ефективно ніж спеціалізовані текстові компресори. Однак, багато текстових архіваторів носять в основному дослідний, а не практичний характер, такі рішення можуть вимагати значної кількості часу на компресію і декомпресію даних, що робить їх повсякденне використання незручним. У свою чергу, серед придатних для практичного застосування текстових архиваторів відсутні рішення, які використовують віддалено розміщувані словники. Тому завдання стиснення тестових даних і пошук нових шляхів його вирішення важливі і актуальні.
2. Мета і задачі дослідження та заплановані результати
Метою роботи є розробка власного методу і алгоритмів стиснення російського тексту з використанням віддалено розміщених словників.
Для досягнення поставленої мети планується вирішити наступні завдання:
- Виконати аналіз існуючих методів стиснення текстових даних.
- Скласти частотні словники для найбільш уживаних слів російської мови.
- Розробити власні алгоритми стиснення російського тексту.
- Дати оцінку доцільності використання розробленого програмного засобу для стиснення російського тексту.
Результатом роботи є програмне забезпечення для стиснення російського тексту, розроблене відповідно до пропонованих алгоритмів.
Наукова новизна роботи: вперше запропонований метод стиснення російськомовного тексту, що відрізняється використанням віддалено розміщених словників, що дозволило скоротити обсяг архіву, що містить текстові дані російською мовою.
3. Огляд досліджень та розробок
Стиснення інформації – проблема, що має досить давню історію, набагато давнішу, ніж історія розвитку обчислювальної техніки, яка зазвичай йшла паралельно з історією розвитку проблеми кодування і шифрування інформації [2]. Розвиток обчислювальної техніки вимагає переглядати старі алгоритми стиснення, розробляти нові і адаптувати їх під різноманітні технічні пристрої з різною обчислювальної здатністю і різними каналами зв'язку. Тому завдання дослідження і розробки нових методів стиснення даних цікавить фахівців в усьому світі, і вони активно займаються його вирішенням.
3.1 Огляд міжнародних джерел
Зарубіжні фахівці беруть активну участь в дослідженнях зі стиснення текстових даних. Варто відзначити цікавий факт, більша частина таких робіт стосується стиснення арабського тексту.
У статті [3] Сінгх М. і Сінгх Н. порівнюють алгоритми стиснення тексту: алгоритми Хаффмана, Шеннона-Фано, арифметичний, LZ, LZW. Вони відзначають, що існує три типи тексту, які обробляються мультимедійним комп'ютером, а саме: звичайний текст, форматований текст і гіпертекст. У текстовому файлі слова перетворюються в коди, що мають довжину 2 і 3. Найбільш часто використовувані слова використовують код довжини 2, а решта використовують код довжини 3 для поліпшення стиснення. Кодові слова вибираються таким чином, що прогалини між словами в вихідному текстовому файлі можуть бути видалені повністю, зберігаючи значну кількість місця.
Соор Х., Плетос Дж., Снесель В. і Абдулла Х. в статті [4] відзначають, що арабська мова є шостою за поширеністю мовою в світі. Більш того, арабський алфавіт є другим найбільш широко використовуваним алфавітом по всьому світу. Тому комп'ютерна обробка арабської мови або арабського алфавіту стає все більш важливим завданням. В області стиснення тексту були розроблені кілька підходів до стиснення тексту. Першим і найбільш інтуїтивним є стиснення на основі символів, яке підходить для невеликих файлів. Інший підхід, званий стисненням на основі слів, добре підходить для дуже довгих файлів. Третій підхід ґрунтується на складах, він використовує склад в якості базового елементу. Алгоритми для розбиття на склади англійських, німецьких і текстів інших європейських мов добре відомі, але такі алгоритми для арабської мови та їх використання при стисненні тексту не були глибоко досліджені. У цій статті описується новий і дуже простий алгоритм для розбиття на склади арабських текстів та його використання при їх стисненні.
У статті [5] Абу Джрай Е. проводить оцінку ефективності методів LZW і BWT для різних категорій арабських текстових файлів різних розмірів, досліджує можливості використання морфологічних ознак арабської мови для підвищення ефективності методів LZW. Він виявив, що покращений LZW є найкращим варіантом для всіх категорій арабських текстів.
Ретор І., Пенді Р. і Ахірвар М. в статті [6] стверджують, що з ростом попиту на передачу і зберігання тексту, в результаті появи мережевих технологій, стиснення тексту набуло власний імпульс до розвитку. Вони запланували абсолютно нову техніку для простого стиснення тексту, особливо натхненну ідеями стеганографії Питмана. Пропонується більш просунута стратегія кодування, яка може забезпечити високі коефіцієнти стиснення і високу ступінь безпеки для всіх можливих способів атаки при передачі. Основна ідея компресії – перетворити текст в деяку проміжну форму, яка може бути стиснута з більш високою ефективністю і надійним кодуванням, яка використовує природну надмірність мови при створенні цього перетворення.
3.2 Огляд національних джерел
У Російській Федерації проблема стиснення текстових даних також актуальна. Вона знаходить відображення в роботах, присвячених розробці архиваторів, аналізу наявних алгоритмів стиснення і пошуку шляхів їх удосконалення.
Над розробкою архиватора задумалися Бондаренко В. В., Козіч В. Г. і Баженов Р. І. Вони написали статтю [7], в якій описали створення додатка, що реалізує GZip стиснення за допомогою алгоритму Deflate. Метою роботи вони називають економію простору на жорсткому диску, а також зберігання декількох файлів в одному архіві для подальшої передачі через Інтернет. Обраний ними метод дозволяє стиснути дані будь-якого типу, але особливу ефективність він має відносно текстових даних.
Завданням стиснення текстових даних зацікавилися Кабальнов Ю. С., Максимов С. В. та Калентьєва М. Б. В їх роботі [8] запропонований шлях поліпшення стиснення текстової інформації на основі лексичних правил і застосування контекстно-словникового стиснення. Тим самим відкривається можливість застосування запропонованих моделей для створення пошукових систем нового покоління. Показано, що застосування лексичних правил дає можливість семантичного аналізу змісту текстів, смислового пошуку інформації, формування електронних архівів.
Шубович В. Г. виконав оцінку ефективності та класифікації алгоритмів оборотного стиску в своїй роботі [9].
Дослідженнями в області стиснення текстової інформації займаються Журавка О. В. та Шевченко Л. П. В їх роботі [10] описуються результати дослідження основної ідеї оборотного стиснення текстової інформації і послідовностей дискретних даних статистичним методом арифметичного кодування. У статистичному стисненні кожному символу присвоюється код, заснований на ймовірності його появи в тексті. Пропонується алгоритм вирішення даного завдання.
3.3 Огляд локальних джерел
Проблемі стиснення даних присвячені наступні роботи магістрів Донецького національного технічного університету:
- Кремешна О. О.
Розробка комп'теризованої системи стиску інформації, отриманої під час проведення научних експериментів, для тривалого зберігання
[11]; - Козленко Д. О.
Дослідження алгоритмів стиску информації та вибір оптимального з них для архівації даних у середовищі системи автоматизації розкроєм прокату на НЗС
[12]; - Бойко А. В.
Проектування комп'ютерної підсистеми стиску даних методом генетичного програмування
[13]; - Краморенко Є. Г.
Методи й алгоритми стиснення інформації для передачі та зберігання сенсорних даних
[14].
Варто відзначити, що розробкою програмних засобів стиснення російського тексту з використанням віддалено розміщених словників ніхто з них не займався.
4. Підхід до стиснення російського тексту з використанням віддалено розміщених словників
Стиснення даних являє собою алгоритмічне перетворення інформації, в ході якого зменшується її обсяг. Стиснення може бути з втратами і без втрат. Розроблюване програмне забезпечення для стиснення російського тексту з використанням віддалено розміщених словників має забезпечувати стиск без втрат, тобто архіватор повинен відновлювати стислий російський текст до його первісного стану без будь-яких змін.
Ідея роботи розроблюваного архиватора полягає в заміні слів, знаків пунктуації та спеціальних символів вихідного тексту відповідними їм кодами (унікальної послідовністю біт). Чим частіше зустрічається слово, тим меншою кількістю біт воно кодується.
Слова, символи і їх коди зберігаються в словниках і відсортовані по зменшенню частоти входження. Словники зберігаються в базі даних на сервері і кожен з них призначений для зберігання певних слів і символів. Таким чином, на сервері розташовуються такі словники:
1) словник для власних назв;
2) словник для розділових знаків;
3) словник для спеціальних термінів;
4) словник для прийменників, часток, спілок і вигуків;
5) загальний словник для інших слів.
Розподіл слів і знаків з кількох словників замість одного має свій вагомий практичний сенс – це дозволить кодувати слова і символи однаковими, найбільш короткими послідовностями біт, що поліпшить ступінь стиснення тексту.
Словники зберігають наступну інформацію про слова: ідентифікатор (номер) слова, саме слово, частоту зустрічальності слова і код слова. Для створення бази даних словників і заповнення їх необхідними даними необхідно розробити допоміжну програму - синтаксичний аналізатор (парсер). Дана програма повинна виконати наступні дії:
1) визначити частоту входження слів, знаків пунктуації в розглянутому тексті (для отримання оптимальної інформації про частоту слів і символів необхідно обробити парсером не менше 100 тестів об'ємом вище 20000 слів);
2) внести слова і частоту їх зустрічальності в відповідні словники;
3) впорядкувати слова за частотою їх зустрічальності;
4) на основі частоти виникнення слова визначити його код алгоритмом Хаффмана.
Розглянемо простий приклад, який ілюструє роботу алгоритму Хаффмана. Нехай заданий текст, в якому слово доба
зустрічається 5 разів, слово багато
зустрічається 8 разів, слово після
зустрічається 3 рази, слово через
зустрічається 1 раз, слово тихий
зустрічається 4 рази і слово також
зустрічається 6 разів. Побудова кодового дерева за алгоритмом Хаффмана складається з наступних етапів:
1) з наявних слів вибираються два з найменшими значеннями зустрічальності;
2) створюється вершина дерева і ці два слова стають її батьками;
3) в вершину записується сума зустрічальності її батьків;
4) пункти 1-3 виконуються, поки всі слова не стануть батьками вершини дерева;
5) відзначається шлях до кожної вершини дерева (праворуч – 1, ліворуч – 0).
Отримані послідовності є кодами, що відповідають кожному слову. Кодове дерево представлено на рис. 1.
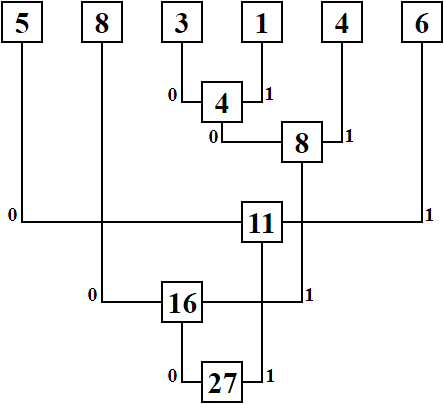
Рисунок 1 – Кодове дерево алгоритму Хаффмана
Таким чином, кожному слову буде відповідати унікальний код (див. табл. 1).
Таблиця 1 – Слова і відповідні їм коди
| Слово | Частота зустрічальності | Код |
| багато | 8 | 00 |
| також | 6 | 11 |
| доба | 5 | 10 |
| тихий | 4 | 011 |
| після | 3 | 0100 |
| через | 1 | 0101 |
Розроблюваний архіватор є клієнт-серверний додаток. Клієнтська частина розбиває вихідний текст на слова, розділові знаки і відправляє їх сервера. Сервер, в свою чергу, знаходить в базі даних словників код, відповідний слову, знаку пунктуації та повертає його клієнту разом з ідентифікатором словника, з якого він був узятий. Процес обміну інформацією між клієнтською і серверною частинами додатку представлений на рис. 2.

Рисунок 2 – Процес обміну інформацією між клієнтської і серверної частинами програми
(анімація: 10 кадрів, 7 циклів повторення, 46 кілобайт)
Клієнтська частина програми упаковує в архів отримані від сервера дані. Ідентифікатори словників мають фіксовану довжину, рівну 3 бітам, а коди слів і знаків пунктуації мають, відповідно, динамічну довжину. Таким чином, отриманий архів є послідовністю біт, в якому послідовно записані ідентифікатор словника і код слова або розділового знака. Розархівація відбувається схожим чином: послідовність біт стислого тексту розбивається на ідентифікатори словників і коди слів або знаків пунктуації, клієнт відправляє їх сервера. Сервер повертає слово або знак пунктуації, які відповідають коду, що знаходиться в словнику із заданим ідентифікатором.
Висновки
На підставі вивченого матеріалу можна зробити висновок, що завданням стиснення текстової інформації цікавляться вчені в усьому світі. Вони ведуть дослідження в цій сфері і пропонують свої шляхи вирішення даної проблеми. Однак, їх розробки носять експериментальний характер, не введені в масове практичне використання, немає підходу до стиснення тексту, який можна було б вважати стандартом. Тому пошуки нових рішень мають сенс і триватимуть. Також стало ясно, що серед представлених робіт відсутні ідеї, які використовують віддалено розміщені словники.
В результаті проведеної роботи були визначені завдання, які необхідно вирішити в ході розробки програмного забезпечення для стиснення російського тексту з використанням віддалено розміщених словників. Очікується, що описаний підхід дозволить домогтися гарного ступеня стиснення російськомовних тестових даних, за рахунок зберігання статистичних словників не в архіві з стисненим текстом, а на сервері.
На момент написання даного реферату магістерська робота ще не завершена. Остаточне завершення: травень 2019 року. Повний текст роботи та матеріали з теми можуть бути отримані у автора або його керівника після зазначеної дати.
Список джерел
- Ратушняк О. А. Методы сжатия данных без потерь с помощью сортировки параллельных блоков [Электронный ресурс]. – Режим доступа: http://www.dissercat.com/content/metody-szhatiya-dannykh-bez-poter-s-pomoshchyu-sortirovki-parallelnykh-blokov.
- Обзор методов сжатия данных [Электронный ресурс]. – Режим доступа: http://www.compression.ru/arctest/descript/methods.htm.
- Singh M., Singh N. A study of various standards for text compression techniques [Электронный ресурс]. – Режим доступа: http://www.academia.edu/6671724/a_study_of_various_standards_for_text_compression_techniques.
- Soori H., Platos J., Snasel V., Abdulla H. Simple rules for syllabification of arabic texts [Электронный ресурс]. – Режим доступа: https://link.springer.com/chapter/10.1007/978-3-642-22389-1_9.
- Abu Jrai E. Efficiency lossless data techniques for arabic text compression [Электронный ресурс]. – Режим доступа: https://pdfs.semanticscholar.org/edd3/b182db340980746f8910ec1c35b02cc76521.pdf.
- Rathore Y., Pandey R., Ahirwar M. Digital shorthand based text compression [Электронный ресурс]. – Режим доступа: http://www.academia.edu/11704694/Digital_Shorthand_Based_Text_Compression.
- Бондаренко В. В., Козич В. Г., Баженов Р. И. Разработка программы для сжатия данных методом GZip [Электронный ресурс]. – Режим доступа: http://web.snauka.ru/issues/2016/04/66586.
- Кабальнов Ю. С., Максимов С. В., Калентьева М. Б. Контекстно-словарное сжатие текстовой информации на основе лексических правил [Электронный ресурс]. – Режим доступа: https://cyberleninka.ru/article/v/kontekstno-slovarnoe-szhatie-tekstovoy-informatsii-na-osnove-leksicheskih-pravil.
- Шубович В. Г. Анализ, классификация и моделирование алгоритмов сжатия [Электронный ресурс]. – Режим доступа: http://www.dslib.net/mat-modelirovanie/analiz-klassifikacija-i-modelirovanie-algoritmov-szhatija.html.
- Журавка А. В., Шевченко Л. П. Основные тенденции статистического метода арифметического кодирования текстовой информации и последовательностей дискретных данных [Электронный ресурс]. – Режим доступа: https://cyberleninka.ru/article/v/osnovnye-tendentsii-statisticheskogo-metoda-arifmeticheskogo-kodirovaniya-tekstovoy-informatsii-i-posledovatelnostey-diskretnyh.
- Кремешная О. А. Разработка компьтеризированной системы сжатия информации, полученной в результате научных экспериментов, для долговременного хранения [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2004/kita/kremeshnaya/.
- Козленко Д. А. Исследование алгоритмов сжатия информации и выбор оптимального из них для архивации данных в среде системы автоматизации раскроем проката на НЗС [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2005/fvti/kozlenko/.
- Бойко А. В. Проектирование компьютерной подсистемы сжатия данных методом генетического программирования [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2005/kita/boiko/index.htm.
- Краморенко Е. Г. Методы и алгоритмы сжатия информации для передачи и хранения сенсорных данных [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2013/fknt/kramorenko/index.htm.