
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования, планируемые результаты
- 3. Обзор исследований и разработок
- 3.1 Обзор международных источников
- 3.2 Обзор национальных источников
- 3.3 Обзор локальных источников
- 4. Подход к сжатию русского текста с использованием удалённо размещаемых словарей
- Выводы
- Список источников
Введение
В течение последних трёх десятилетий произошёл резкий скачок в развитии сети Интернет и её распространении – увеличении количества, подключённых к ней компьютеров. В совокупности с растущим количеством пользователей, это привело к значительному увеличению объёмов передаваемой и хранимой информации.
В связи с продолжающимся ростом глобальных сетей и расширением спектра предоставляемых ими услуг при экспоненциальном росте числа пользователей сетей, а также успешно выполняемыми проектами по переводу в цифровой вид содержимого огромных хранилищ информации, в частности библиотек, выставочных залов и художественных галерей, следует ожидать, что объемы хранимой и передаваемой по системам связи информации будут продолжать увеличиваться с такой же или даже еще большей скоростью [1]. Этот процесс ставит новые задачи, требующие своего решения – такие объёмы информации необходимо хранить, обрабатывать и передавать в наиболее компактном виде. Отсюда возникает задача сжатия информации различных типов, в том числе и текстовой.
1. Актуальность темы
За десятилетия развития компьютерных технологий задача сжатия данных с разной степенью успешности решалась различными архиваторами. Разная степень успешности обусловлена тем, что архиваторы, хоть и разрабатываются для решения одной общей задачи (сжатия данных), имеют заведомо отличающиеся подходы к её решению и принимают различные типы данных в качестве исходных. Таким образом, архиваторы бывают как общего назначения (работают с разными типами данных), так и предназначенными для конкретных типов данных.
Архиваторы общего назначения сжимают текстовые данные, но справляются с этой задачей менее эффективно нежели специализированные текстовые компрессоры. Однако, многие текстовые архиваторы носят в основном исследовательский, а не практический характер, такие решения могут требовать значительного количества времени на компрессию и декомпрессию данных, что делает их повседневное использование затруднительным. В свою очередь, среди пригодных для практического применения текстовых архиваторов отсутствуют решения, которые используют удалённо размещаемые словари. Поэтому задача сжатия тестовых данных и поиск новых путей её решения важны и актуальны.
2. Цель и задачи исследования, планируемые результаты
Целью работы является разработка собственного метода и алгоритмов сжатия русского текста с использованием удаленно размещаемых словарей.
Для достижения поставленной цели планируется решить следующие задачи:
- Выполнить анализ существующих методов сжатия текстовых данных.
- Составить частотные словари для наиболее употребляемых слов русского языка.
- Разработать собственные алгоритмы сжатия русского текста.
- Дать оценку целесообразности использования разработанного программного средства для сжатия русского текста.
Результатом работы является программное обеспечение для сжатия русского текста, разработанное в соответствии с предлагаемыми алгоритмами.
Научная новизна работы: впервые предложен метод сжатия русскоязычного текста, отличающийся использованием удалённо размещаемых словарей, что позволило сократить объём архива, содержащего текстовые данные на русском языке.
3. Обзор исследований и разработок
Сжатие информации – проблема, имеющая достаточно давнюю историю, гораздо более давнюю, нежели история развития вычислительной техники, которая обычно шла параллельно с историей развития проблемы кодирования и шифровки информации [2]. Развитие вычислительной техники требует пересматривать старые алгоритмы сжатия, разрабатывать новые и адаптировать их под разнообразные технические устройства с различной вычислительной способностью и различными каналами связи. Поэтому задача исследования и разработки новых методов сжатия данных интересует специалистов во всём мире, и они активно занимаются её решением.
3.1 Обзор международных источников
Зарубежные специалисты принимают активное участие в исследованиях по сжатию текстовых данных. Стоит отметить интересный факт, многие из таких работ касаются сжатия арабского текста.
В статье [3] Сингх М. и Сингх Н. сравнивают алгоритмы сжатия текста: алгоритмы Хаффмана, Шеннона-Фано, арифметический, LZ, LZW. Они отмечают, что существует три типа текста, которые обрабатываются мультимедийным компьютером, а именно: неформатированный текст, форматированный текст и гипертекст. В текстовом файле слова преобразуются в коды, имеющие длину 2 и 3. Наиболее часто используемые слова используют код длины 2, а остальные используют код длины 3 для улучшения сжатия. Кодовые слова выбираются таким образом, что пробелы между словами в исходном текстовом файле могут быть удалены полностью, сохраняя значительное количество места.
Соори Х., Плэтос Дж., Снэсель В. и Абдулла Х. в статье [4] отмечают, что арабский язык является шестым самым распространенным языком в мире. Более того, арабский алфавит является вторым наиболее широко используемым алфавитом по всему миру. Поэтому компьютерная обработка арабского языка или арабского алфавита становится все более важной задачей. В области сжатия текста были разработаны несколько подходов к сжатию текста. Первым и наиболее интуитивным является сжатие на основе символов, которое подходит для небольших файлов. Другой подход, называемый сжатием на основе слов, хорошо подходит для очень длинных файлов. Третий подход основывается на слогах, он использует слог в качестве базового элемента. Алгоритмы для разбиения на слоги английских, немецких и текстов других европейских языков хорошо известны, но такие алгоритмы для арабского языка и их использование при сжатии текста не были глубоко исследованы. В этой статье описывается новый и очень простой алгоритм для разбиения на слоги арабских текстов и его использование при их сжатии.
В статье [5] Абу Джрай Э. проводит оценку эффективности методов LZW и BWT для различных категорий арабских текстовых файлов разных размеров, исследует возможности использования морфологических признаков арабского языка для повышения эффективности методов LZW. Он обнаружил, что улучшенный LZW является лучшим вариантом для всех категорий арабских текстов.
Рэтор И., Пэнди Р. и Ахирвар М. в статье [6] утверждают, что с ростом спроса на передачу и хранение текста, в результате появления сетевых технологий, сжатие текста приобрело собственный импульс к развитию. Они запланировали совершенно новую технику для простого сжатия текста, особенно вдохновленную идеями стеганографии Питмана. Предлагается более продвинутая стратегия кодирования, которая может обеспечить высокие коэффициенты сжатия и высокую степень безопасности для всех возможных способов атаки при передаче. Основная идея компрессии – преобразовать текст в некоторую промежуточную форму, которая может быть сжата с более высокой эффективностью и надежной кодировкой, которая использует естественную избыточность языка при создании этого преобразования.
3.2 Обзор национальных источников
В Российской Федерации проблема сжатия текстовых данных также актуальна. Она находит отражение в работах, посвящённых разработке архиваторов, анализу имеющихся алгоритмов сжатия и поиску путей их усовершенствования.
Над разработкой архиватора задумались Бондаренко В. В., Козич В. Г. и Баженов Р. И. Они написали статью [7], в которой описали создание приложения, реализующего GZip сжатие при помощи алгоритма Deflate. Целью работы они называют экономию пространства на жестком диске, а также хранение нескольких файлов в одном архиве для последующей передачи через Интернет. Выбранный ими метод позволяет сжать данные любого типа, но особую эффективность он имеет в отношении текстовых данных.
Задачей сжатия текстовых данных заинтересовались Кабальнов Ю. С., Максимов С. В. и Калентьева М. Б. В их работе [8] предложен путь улучшения сжатия текстовой информации на основе лексических правил и применения контекстно-словарного сжатия. Тем самым открывается возможность применения предложенных моделей для создания поисковых систем нового поколения. Показано, что применение лексических правил даёт возможность семантического анализа содержания текстов, смыслового поиска информации, формирования электронных архивов.
Шубович В. Г. выполнил оценку эффективности и классификации алгоритмов обратимого сжатия в своей работе [9].
Исследованиями в области сжатия текстовой информации занимаются Журавка А. В. и Шевченко Л. П. В их работе [10] описываются результаты исследования основной идеи оборотного сжатия текстовой информации и последовательностей дискретных данных статистическим методом арифметического кодирования. В статистическом сжатии каждому символу присваивается код, основанный на вероятности его появления в тексте. Предлагается алгоритм решения данной задачи.
3.3 Обзор локальных источников
Проблеме сжатия данных посвящены следующие работы магистров Донецкого национального технического университета:
- Кремешная О. А. «Разработка компьютеризированной системы сжатия информации, полученной в результате научных экспериментов, для долговременного хранения» [11];
- Козленко Д. А. «Исследование алгоритмов сжатия информации и выбор оптимального из них для архивации данных в среде системы автоматизации раскроем проката на НЗС» [12];
- Бойко А. В. «Проектирование компьютерной подсистемы сжатия данных методом генетического программирования» [13];
- Краморенко Е. Г. «Методы и алгоритмы сжатия информации для передачи и хранения сенсорных данных» [14].
Стоит отметить, что разработкой программных средств сжатия русского текста с использованием удаленно размещаемых словарей никто из них не занимался.
4. Подход к сжатию русского текста с использованием удалённо размещаемых словарей
Сжатие данных представляет собой алгоритмическое преобразование информации, в ходе которого уменьшается её объём. Сжатие может быть с потерями и без потерь. Разрабатываемое программное обеспечение для сжатия русского текста с использованием удалённо размещаемых словарей должно обеспечивать сжатие без потерь, то есть архиватор должен восстанавливать сжатый русский текст к его первоначальному состоянию без каких-либо изменений.
Идея работы разрабатываемого архиватора состоит в замене слов, знаков препинания и специальных символов исходного текста соответствующими им кодами (уникальной последовательностью бит). Чем чаще встречается слово, тем меньшим количеством бит оно кодируется.
Слова, символы и их коды хранятся в словарях и отсортированы по уменьшению частоты вхождения. Словари хранятся в базе данных на сервере и каждый из них предназначен для хранения определённых слов и символов. Таким образом, на сервере располагаются следующие словари:
1) словарь для имён собственных;
2) словарь для знаков препинания;
3) словарь для специальных терминов;
4) словарь для предлогов, частиц, союзов и междометий;
5) общий словарь для остальных слов.
Распределение слов и знаков по нескольким словарям вместо одного имеет свой весомый практический смысл – это позволит кодировать слова и символы одинаковыми, наиболее короткими последовательностями бит, что улучшит степень сжатия текста.
Словари хранят следующую информацию о слове: идентификатор (номер) слова, само слово, частоту встречаемости слова и код слова. Для создания базы данных словарей и заполнения их необходимыми данными необходимо разработать вспомогательную программу – синтаксический анализатор (парсер). Данная программа должна выполнить следующие действия:
1) определить частоту вхождения слов, знаков препинания в рассматриваемом тексте (для получения оптимальной информации о частоте встречаемости слов и символов необходимо обработать парсером не менее 100 тестов объёмом выше 20000 слов);
2) внести слова и частоту их встречаемости в соответствующие словари;
3) отсортировать слова по частоте их встречаемости;
4) на основе частоты встречаемости слова определить его код алгоритмом Хаффмана.
Рассмотрим простой пример, иллюстрирующий работу алгоритма Хаффмана. Пусть задан текст, в котором слово «сутки» встречается 5 раз, слово «много» встречается 8 раз, слово «после» встречается 3 раза, слово «через» встречается 1 раз, слово «тихий» встречается 4 раза и слово «также» встречается 6 раз. Построение кодового дерева по алгоритму Хаффмана состоит из следующих этапов:
1) из имеющихся слов выбираются два с наименьшими значениями встречаемости;
2) создается вершина дерева и эти два слова становятся ее родителями;
3) в вершину записывается сумма встречаемости её родителей;
4) пункты 1-3 выполняются, пока все слова не станут родителями вершины дерева;
5) отмечается путь к каждой вершине дерева (направо – 1, налево – 0).
Полученные последовательности являются кодами, соответствующими каждому слову. Кодовое дерево представлено на рис. 1.
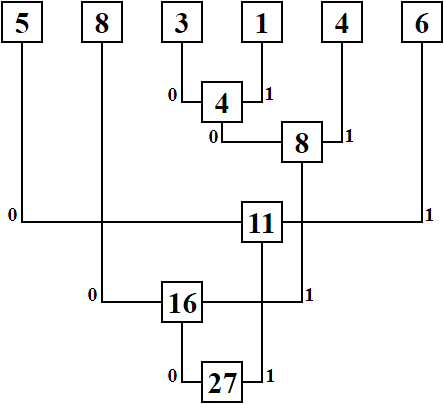
Рисунок 1 – Кодовое дерево алгоритма Хаффмана
Таким образом, каждому слову будет соответствовать уникальный код (см. табл. 1).
Таблица 1 – Слова и соответствующие им коды
| Слово | Частота встречаемости | Код |
| много | 8 | 00 |
| также | 6 | 11 |
| сутки | 5 | 10 |
| тихий | 4 | 011 |
| после | 3 | 0100 |
| через | 1 | 0101 |
Разрабатываемый архиватор представляет собой клиент-серверное приложение. Клиентская часть разбивает исходный текст на слова, знаки препинания и отправляет их серверу. Сервер, в свою очередь, находит в базе данных словарей код, соответствующий слову, знаку препинания и возвращает его клиенту вместе с идентификатором словаря, из которого он был взят. Процесс обмена информацией между клиентской и серверной частями приложения представлен на рис. 2.
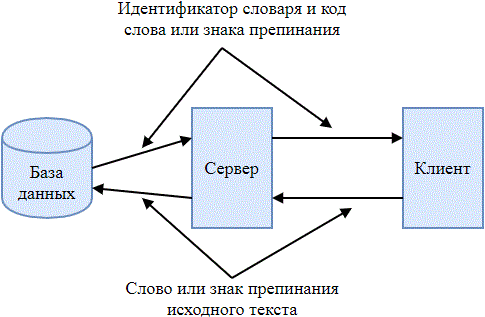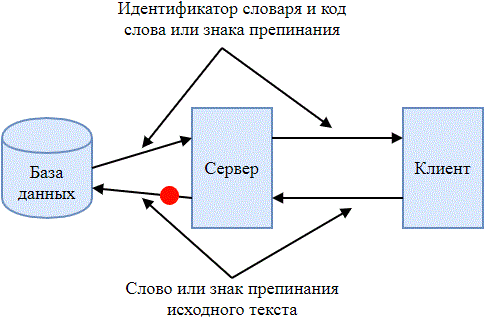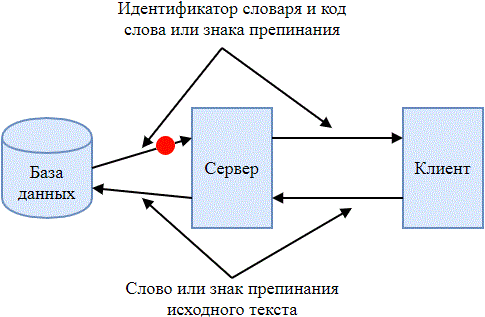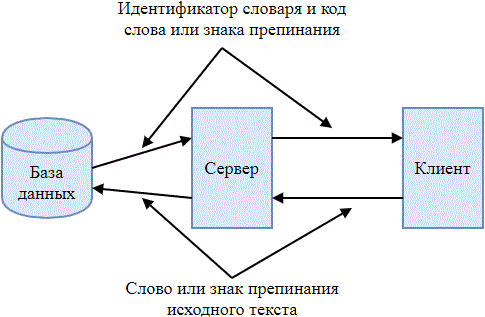
Рисунок 2 – Процесс обмена информацией между клиентской и серверной частями приложения
(анимация: 10 кадров, 7 циклов повторения, 46 килобайт)
Клиентская часть приложения упаковывает в архив полученные от сервера данные. Идентификаторы словарей имеют фиксированную длину, равную 3 бита, а коды слов и знаков препинания имеют, соответственно, динамическую длину. Таким образом, полученный архив является последовательностью бит, в котором последовательно записаны идентификатор словаря и код слова или знака препинания. Разархивирование происходит схожим образом: последовательность бит сжатого текста разбивается на идентификаторы словарей и коды слов или знаков препинания, клиент отправляет их серверу. Сервер возвращает слово или знак препинания, которые соответствуют коду, находящемуся в словаре с заданным идентификатором.
Выводы
На основании изученного материала можно сделать вывод, что задачей сжатия текстовой информации интересуются учёные во всём мире. Они ведут исследования в этой сфере и предлагают свои пути решения данной проблемы. Однако, их разработки носят экспериментальный характер, не введены в массовое практическое использование, нет подхода к сжатию текста, который можно было бы считать стандартом. Поэтому поиски новых решений имеют смысл и будут продолжаться. Также стало ясно, что среди представленных работ отсутствуют идеи, которые используют удалённо размещаемые словари.
В результате проделанной работы были определены задачи, которые необходимо решить в ходе разработки программного обеспечения для сжатия русского текста с использованием удалённо размещаемых словарей. Ожидается, что описанный подход позволит добиться хорошей степени сжатия русскоязычных тестовых данных, за счёт хранения статистических словарей не в архиве с сжатым текстом, а на сервере.
На момент написания данного реферата магистерская работа еще не завершена. Окончательное завершение: май 2019 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Список источников
- Ратушняк О. А. Методы сжатия данных без потерь с помощью сортировки параллельных блоков [Электронный ресурс]. – Режим доступа: http://www.dissercat.com/content/metody-szhatiya-dannykh-bez-poter-s-pomoshchyu-sortirovki-parallelnykh-blokov.
- Обзор методов сжатия данных [Электронный ресурс]. – Режим доступа: http://www.compression.ru/arctest/descript/methods.htm.
- Singh M., Singh N. A study of various standards for text compression techniques [Электронный ресурс]. – Режим доступа: http://www.academia.edu/6671724/a_study_of_various_standards_for_text_compression_techniques.
- Soori H., Platos J., Snasel V., Abdulla H. Simple rules for syllabification of arabic texts [Электронный ресурс]. – Режим доступа: https://link.springer.com/chapter/10.1007/978-3-642-22389-1_9.
- Abu Jrai E. Efficiency lossless data techniques for arabic text compression [Электронный ресурс]. – Режим доступа: https://pdfs.semanticscholar.org/edd3/b182db340980746f8910ec1c35b02cc76521.pdf.
- Rathore Y., Pandey R., Ahirwar M. Digital shorthand based text compression [Электронный ресурс]. – Режим доступа: http://www.academia.edu/11704694/Digital_Shorthand_Based_Text_Compression.
- Бондаренко В. В., Козич В. Г., Баженов Р. И. Разработка программы для сжатия данных методом GZip [Электронный ресурс]. – Режим доступа: http://web.snauka.ru/issues/2016/04/66586.
- Кабальнов Ю. С., Максимов С. В., Калентьева М. Б. Контекстно-словарное сжатие текстовой информации на основе лексических правил [Электронный ресурс]. – Режим доступа: https://cyberleninka.ru/article/v/kontekstno-slovarnoe-szhatie-tekstovoy-informatsii-na-osnove-leksicheskih-pravil.
- Шубович В. Г. Анализ, классификация и моделирование алгоритмов сжатия [Электронный ресурс]. – Режим доступа: http://www.dslib.net/mat-modelirovanie/analiz-klassifikacija-i-modelirovanie-algoritmov-szhatija.html.
- Журавка А. В., Шевченко Л. П. Основные тенденции статистического метода арифметического кодирования текстовой информации и последовательностей дискретных данных [Электронный ресурс]. – Режим доступа: https://cyberleninka.ru/article/v/osnovnye-tendentsii-statisticheskogo-metoda-arifmeticheskogo-kodirovaniya-tekstovoy-informatsii-i-posledovatelnostey-diskretnyh.
- Кремешная О. А. Разработка компьтеризированной системы сжатия информации, полученной в результате научных экспериментов, для долговременного хранения [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2004/kita/kremeshnaya/.
- Козленко Д. А. Исследование алгоритмов сжатия информации и выбор оптимального из них для архивации данных в среде системы автоматизации раскроем проката на НЗС [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2005/fvti/kozlenko/.
- Бойко А. В. Проектирование компьютерной подсистемы сжатия данных методом генетического программирования [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2005/kita/boiko/index.htm.
- Краморенко Е. Г. Методы и алгоритмы сжатия информации для передачи и хранения сенсорных данных [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2013/fknt/kramorenko/index.htm.