
Реферат по теме выпускной работы
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: май 2021 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования
- 3. Обзор исследований и разработок
- 4. Обзор системы управления трафиком и технологий V2V, V2I, I2V в концепции развития Smart City
- 5. Идентификация движения транспортного средства
- 6. Обзор программных интерфейсов для параллельного выполнения алгоритмов на GPU
- 6.1 Программный интерфейс для параллельного выполнения алгоритмов на GPU CUDA
- 6.2 Программный интерфейс для параллельного выполнения алгоритмов на GPU OpenCL
- 6.3 Программный интерфейс для параллельного выполнения алгоритмов на GPU Direct compute
- 6.4 Выбор программного интерфейса для параллельного выполнения алгоритма на GPU
- Выводы
- Список источников
Введение
В современном мире существует большое количество проблем, связанных с обеспечением безопасности движения транспортных средств, одним из способов решения данной проблемы является увеличение количества транспортных потоков. Особенно эта проблема применяется к большим городам, где на улицах выполняют движение несколько сотен тысяч, а в некоторых случаях и миллионов автомобилей и других транспортных средств, тем самым повышая шанс на появление аварийной ситуации на дорогах. В связи с этим большое распространение получил или системы, которые выполняют просчет и построение траектории, которая будет наиболее безлопастной и не создаст проблем окружающим. Так многие компании занялись вопросом о создании автономного транспортного средства (АТС), суть которого будет, управление им без посредственного участия человека, что должно понизить уровень дорожно-транспортных происшествий и других аварийных ситуаций. В магистерской работе выполняется исследование подсистемы идентификации параметров движения АТС, суть которой определить траекторию движения АТС зная его параметры, которые были получены во время его движения. Так как подсистема требует больших ресурсов из-за того, что все действия будут происходить во время движения в режиме реального времени, то для наиболее точной и эффективной ее работы будут использоваться высокопроизводительные вычислительные замеры, которые выполняются параллельно на GPU. В магистерской работе выполняется анализ эффективности работы подсистемы идентификации параметров АТС и ее реализация на параллельной архитектуре.
1. Актуальность темы
Актуальность заключается в повышении уровня безопасности и организации дорожного движения. Одним из направлений является снижение влияния человеческого фактора посредством применения современных компьютерных систем и внедрения различных автономных транспортных средств. А также увеличить эффективность данной подсистемы, так как при малом ее быстродействии, работа становится менее полезной, что может привести к некоторым последствиям. В магистерской работе рассматриваются вопросы обеспечения быстродействия работы подсистемы идентификации параметров движения АТС.
2. Цель и задачи исследования
Целью работы является провести анализ эффективности работы подсистемы идентификации параметров движения АТС, реализованной на параллельных архитектурах.
В магистерской работе будут решены следующе задачи:
- Разработать подсистему идентификации параметров движения АТС, используя параллельные системы;
- Провести анализ различных существующих параллельных архитектур и выбрать самую эффективную для реализации подсистемы.
3. Обзор исследований и разработок
В мире уже несколько лет активно многие компании занимаются разработкой, моделированием и тестированием автоматизированных систем, на основе которых будут выполнять свое движение беспилотные транспортные средства, как легковые, так и грузовые, наземные, воздушные и другие. Наиболее активно данным вопросом занимаются такие большие компании как Tesla, Google, BMW вместе с китайским поисковиком Baidu, General Motors, Audi и другие. Изучив данную тему более глубоко выяснилось, что практически все крупные автомобильные бренды самостоятельно или в связке с другими, выполняют разработку и тестируют свои системы. Но не только автомобильные компании разрабатывают подобные системы, вопросом моделирования и разработкой подсистем занимаются многие ВУЗы в мире, в этот список входит и наш ДонНТУ, где на кафедре компьютерной инженерии занимаются сотрудники: ст. пр. Кривошеев Сергей Васильевич, профессор Аноприенко Александр Яковлевич [1, 2, 3, 4].
4. Обзор системы управления трафиком и технологий Vehicle-to-vehicle(V2V), Vehicle-to-infrastructure(V2I), Invisible-to-Visible(I2V) в концепции развития Smart City
По данным ВОЗ, половина населения планеты проживает в городах, а по прогнозу ООН, к 2050 г. около 85% населения Земли предпочтет городской образ жизни. На долю горожан будет приходиться около 80% мирового ВВП. В России по информации на сентябрь 2019г. 74% населения – это жители городов. Стремительная урбанизация – вызов для муниципалитетов, которые должны создать условия для ожидаемого качества жизни, особенно с точки зрения комфорта и безопасности. Это очень непростая задача, ведь городская инфраструктура уже сейчас работает с предельной нагрузкой, а с ростом численности населения мегаполисов возникает угроза ее краха. Для решения этой проблемы создана концепция умного города – Smart City [5].
Для того что бы система беспилотного транспорта в мегаполисах функционировала максимально эффективно должна быть сформирована городская дорожно-транспортная инфраструктура, которая обеспечивает покрытие объектов транспортной инфраструктуры сетями нового поколения и датчиками. Кроме того, в концепции Smart City, планируется организованы парковочные зоны и заправочные станции для беспилотного транспорта [6].
Беспилотный автомобиль через сеть взаимодействует с окружающей средой и объектами Smart City, поэтому выделяют несколько систем: автомобиль-автомобиль (vehicle-to-vehicle, V2V), автомобиль - инфраструктура (vehicle-to-infrastructure, V2I) и (Invisible-to-Visible), которая позволяет водителям видеть невидимое
. На рисунке 1 показан план обеспечения разработки систем обеспечивающие АТС эффективное передвижение по городу.
V2V – это система беспроводной связи, которая позволяет двум транспортным средствам взаимодействовать методом обмена информацией о состояниях на дорогах, исключая при этом участие человека. Таким образом данная система дает право автомобилю узнать информацию о скорости движения, местонахождении и т.д. другого автомобиля в режиме Онлайн [7].
V2I – является система беспроводной связи, которая похожа на V2V, но в ней транспортное средство обменивается информацией с объектами инфраструктуры, например, со светофорами, дорожными знаками и т.д. А также получать информацию и в обратном направлении[8].
I2V – является новой технологией которая была разработана компанией Nissan, данная система собирает и анализирует данные, поступающие от внутренних и наружных датчиков (в том числе установленных на других автомобилях), а также информацию, хранящуюся в облачном сервисе. Благодаря этому система контролирует обстановку вокруг машины и прогнозирует, что ее ждет на пути следования.
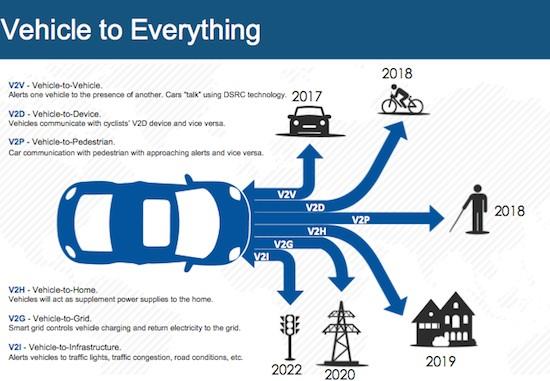
Рисунок 1. План обеспечения разработки систем обеспечивающие АТС эффективное передвижение по городу
5. Идентификация движения транспортного средства
Идентификация параметров движения транспортного средства (ТС) является одним из методов, который обеспечивает автономное передвижение ТС. Данный способ выполняется при помощи вычислений математическим методом наименьших квадратов (МНК). Этот метод показал свою эффективность по сравнению с другими, поэтому он и лег в основу подсистемы. Работа МНК в системе заключается в том, что, получив начальные данные, производится выбор полином для построения уравнения регрессионного анализа, которое бывает нескольких видов (гиперболическое, квадратичное и др.). Большое значение имеет количество коэффициентов, которое будет использовано для идентификации параметров движения АТС, так как каждое уравнение имеет разное количество параметров. На рисунке 2 показан принцип работы численного метода метода наименьщих квадратов (МНК).
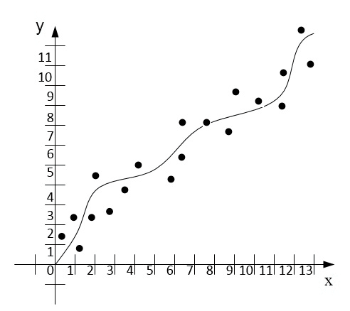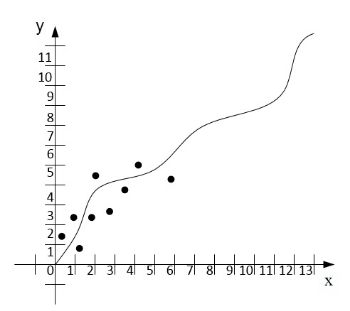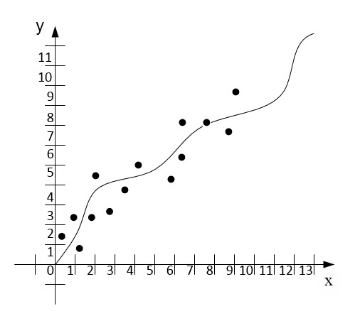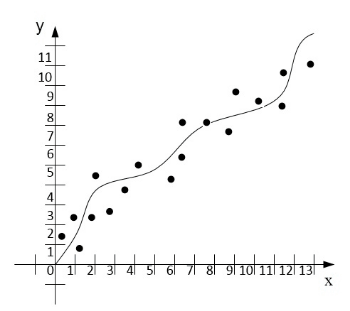
Рисунок 2. Принцип работы численного метода метода наименьщих квадратов
(анимация: 13 кадров, 155 килобайт)
Для моделирования наиболее точной траектории движения ТС, необходимо использовать параллельные вычисления, так как с их помощью процесс идентификации станет наиболее эффективным, что позволит системе работать быстрее и точнее определять дальнейший путь передвижения АТС. Так как в систему приходит и вычисляется большое количество параметров, из которых необходимо получить коэффициенты с помощью уравнений методом наименьших квадратов, то использоваться параллельное выполнение алгоритмов программы будет для вычисления их, что в общем даст эффективное построение траектории.
6. Обзор программных интерфейсов для параллельного выполнения алгоритмов на GPU
Одним из перспективных направлений в области параллельной глобальной оптимизации является использование графических ускорителей (GPU), востребованных в решении целого ряда вычислительно трудоемких задач. Однако в области глобальной оптимизации потенциал графических ускорителей до конца еще не раскрыт. Вычисления на GPU — это использование GPU для вычисления технических, научных, бытовых задач. Вычисление на GPU заключает в себе использование CPU и GPU с разнородной выборкой между ними, а именно: последовательную часть программ берет на себя CPU, в то время как трудоёмкие вычислительные задачи остаются GPU. Благодаря этому происходит распараллеливание задач, которое приводит к ускорению обработки информации и уменьшает время выполнения работы, система становиться более производительной и может одновременно обрабатывать большее количество задач, чем ранее. Однако, чтобы добиться такого успеха одной лишь аппаратной поддержкой не обойтись, в данном случае необходима поддержка ещё и программного обеспечения, что бы приложение могло переносить наиболее трудоёмкие вычисления на GPU [9].
Есть несколько причин почему GPU эффективнее: во-первых, CPU имеет лишь небольшое (до 16 в передовых моделях) число ядер, работающих на высокой тактовой частоте независимо друг от друга. Каждое ядро CPU является мощным вычислительным устройством. GPU же, напротив, работает на низкой тактовой частоте и имеет сотни более простых вычислительных элементов. Во-вторых, значительную долю кристалла CPU занимает быстродействующая кеш-память, в то время как практически весь GPU состоит из арифметико-логических блоков. Поэтому GPU особенно эффективны в задачах, число арифметических операций в которых велико по сравнению с операциями над памятью. Применительно к методам глобальной оптимизации операцией, которую можно эффективно реализовать на GPU, является параллельное вычисление сразу многих значений целевой функции. Естественно, что для этого требуется реализовать на GPU процедуру вычисления значения функции. Пересылки данных от CPU к GPU будут минимальные: требуется лишь передать на GPU координаты точек испытаний и получить обратно значения функции в этих точках. Функции, определяющие обработку результатов испытаний в соответствии с алгоритмом и требующие работы с большим объемом накопленной поисковой информации, могут быть эффективно реализованы на CPU [10]. Схема информационных обменов в GPU-алгоритме изображена на рисунке 3.
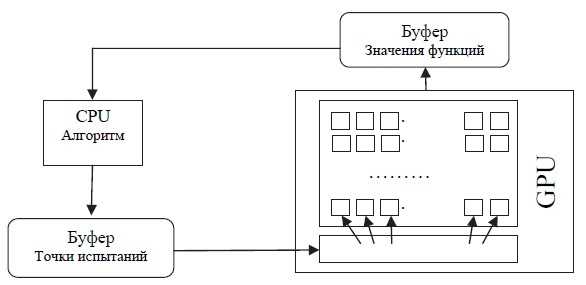
Рисунок 3. Схема информационных обменов в GPU-алгоритме
Существуют несколько программных интерфейсов для параллельного выполнения алгоритмов на GPU, ниже приведено описание самых известных из них таких как CUDA, OpenCL и Direct compute.
6.1 Программный интерфейс для параллельного выполнения алгоритмов на GPU CUDA
Технология CUDA — это программно-аппаратная вычислительная архитектура Nvidia, основанная на расширении языка Си, которая даёт возможность организации доступа к набору инструкций графического ускорителя и управления его памятью при организации параллельных вычислений. CUDA помогает реализовывать алгоритмы, выполнимые на графических процессорах видеоускорителей [11].
Хотя трудоёмкость программирования GPU при помощи CUDA довольно велика, она ниже, чем с ранними GPGPU решениями. Такие программы требуют разбиения приложения между несколькими мультипроцессорами подобно MPI программированию, но без разделения данных, которые хранятся в общей видеопамяти. И так как CUDA программирование для каждого мультипроцессора подобно OpenMP программированию, оно требует хорошего понимания организации памяти. Но, конечно же, сложность разработки и переноса на CUDA сильно зависит от приложения [11].
Основные ограничения CUDA:
- Отсутствие поддержки рекурсии для выполняемых функций;
- Минимальная ширина блока в 32 потока;
- Закрытая архитектура CUDA, принадлежащая Nvidia.
6.2 Программный интерфейс для параллельного выполнения алгоритмов на GPU OpenCL
В отличии от nVidia CUDA, AMD Stream и т.п., в OpenCL изначально закладывалась мультиплатформенность, т.е. OpenCL программа должна без изменений в коде работать на GPU разных типов (разных производителей). Такая программа без изменений должна работать даже на CPU без GPU, хотя в этом случае она может выполняться существенно медленнее чем на GPU [12].
OpenCL — программа работает с т.н. платформами. Платформа — это программный пакет, который поставляется соответствующим разработчиком аппаратных средств. Каждая платформа включает в себя ICD (Installable Client Driver) — программный интерфейс OpenCL для работы с устройствами, которые эта платформа поддерживает [12]. Схему работы OpenCL программы с аппаратурой изображен на рисунке 4.
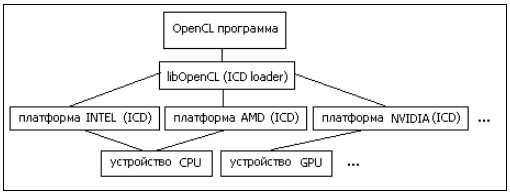
Рисунок 4. Схема работы OpenCL программы с аппаратурой
Модель платформы дает высокоуровневое описание гетерогенной системы. Центральным элементом данной модели выступает понятие хоста - первичного устройства, которое управляет OpenCL-вычислениями и осуществляет все взаимодействия с пользователем. Хост всегда представлен в единственном экземпляре, в то время как OpenCL-устройства, на которых выполняются OpenCL-инструкции могут быть представлены во множественном числе. OpenCL-устройством может быть CPU, GPU, DSP или любой другой процессор в системе, поддерживающийся установленными в системе OpenCL-драйверами. OpenCL-устройства логически делятся моделью на вычислительные модули, которые в свою очередь делятся на обрабатывающие элементы. Вычисления на OpenCL-устройствах в действительности происходят на обрабатывающих элементах [13].
6.3 Программный интерфейс для параллельного выполнения алгоритмов на GPU Direct compute
Впервые технология DirectCompute появилась в 11-ой версии DirectX, а потом уже была адаптирована под 10-ую и 9-ую. До ее появления разработчикам графических приложений приходилось разрываться между CUDA и FileStream – аналогичным технологиями от NVIDIA и AMD. С выходом же DirectX 11 все стало куда проще [14].
DirectCompute — это набор API, предназначенный для организации вычислений на GPU. То есть при помощи данной технологии задачи по расчету сложных графических эффектов переносятся с центрального процессора на те, что интегрированы в видеокарты. Использование данной функции DirectX не просто позволяет разгрузить CPU – в ряде случаев ориентированные на вычислительные шейдеры GPU справляются с расчетами куда быстрее и эффективней, чем процессоры общего назначения [14].
6.4 Выбор программного интерфейса для параллельного выполнения алгоритма на GPU
Проведя обзор всех доступных программно-вычислительных архитектур, в качестве программного интерфейса для паралельного выполнения алгоритма на GPU была выбрана Nvidia CUDA. CUDA — это более зрелая технология с достаточно развитым toolchain разработкой. Большие научные сообщества как правило предпочитают использовать CUDA (не в последнюю очередь ввиду того, что NVIDIA инвестирует в данную технологию и под ее исполнение существует большое количество библиотек). В OpenCL есть совместимость с устройствами помимо видеокарт NVIDIA и пользоваться ей чуть менее удобно. В целом же, обе технологии очень близки друг к другу. Писать эффективный код и под CUDA, и под другую сложно.
Также CUDA имеет преимущества перед традиционным подходом к GPGPU вычислениям по сравнению с другими программными интерфейсами:
- Интерфейс программирования приложений CUDA основан на стандартном языке программирования Си с расширениями, что упрощает процесс изучения и внедрения архитектуры CUDA;
- CUDA обеспечивает доступ к разделяемой между потоками памяти размером в 16 Кб на мультипроцессор, которая может быть использована для организации кэша с широкой полосой пропускания, по сравнению с текстурными выборками;
- Более эффективная передача данных между системной и видеопамятью;
- Отсутствие необходимости в графических API с избыточностью и накладными расходами;
- Линейная адресация памяти, и gather и scatter, возможность записи по произвольным адресам;
- Аппаратная поддержка целочисленных и битовых операций [11].
Выводы
На момент написания данного реферата в рамках проведенных исследований выполнены:
- Обзор программных интерфейсов для параллельного выполнения алгоритмов на GPU;
- Обзор системы управления трафиком и технологий Vehicle-to-vehicle(V2V), Vehicle-to-infrastructure(V2I), Invisible-to-Visible(I2V) в концепции развития Smart City.
Дальнейшие исследования планируется направить на следующие аспекты:
- Реализовать подсистему идентификации параметров движения АТС на параллельных системах;
- Выполнить анализ эффективности работы подсистемы идентификации параметров движения АТС при реализации на различных параллельных системах.
Список источников
- Аноприенко А.Я., Кривошеев С.В., Потапенко В.А. Моделирование процесса обработки информации в интегрированной навигационной системе // Тези доповідей міждержавної науково-методичної конференції
Комп'ютерне моделювання
30 червня – 2 липня 1999 р., м. Дніпродзержинськ. – Дніпродзержинськ. – 1999. С. 114-115. - Кривошеев С.В. Исследование эффективности параллельных архитектур вычислительных систем для расчета параметров движения транспортного средства // Научные труды Донецкого национального технического университета. Выпуск № 1(10)-2(11). Серия
Проблемы моделирования и автоматизации проектирования
. – Донецк, ДонНТУ, 2012. С. 207-214. - Аноприенко А.Я., Кривошеев С.В. Моделирование динамики речного судна на базе системы Matlab/Simulink //
Прогрессивные технологии и системы машиностроения
: Международный сборник научных трудов. – Донецк: ДонГТУ, 2000. Вып. 9. С. 13-20. - Аноприенко А.Я., Кривошеев С.В. Разработка подсистемы моделирования движения судна по заданной траектории // Научные труды Донецкого национального технического университета. Выпуск 12. Серия
Вычислительная техника и автоматизация
. – Донецк, ДонГТУ, ООО «Лебедь», 1999. С. 197-202. - Умный транспорт как часть экосистемы технологий умного города [Электронный ресурс]. // Secuteck – Режим доступа: https://www.secuteck.ru/articles/umnyj-transport-kak-chast-ehkosistemy-tekhnologij-umnogo-goroda
- Цифровая мобильность [Электронный ресурс]. // 2030.mos – Режим доступа: https://2030.mos.ru/n/n3/
- Евстигнеев И. А., Шмытинский В. В. Вопросы взаимодействия беспилотных транспортных средств с дорожной инфраструктурой // Транспорт Российской Федерации. Журнал о науке, практике, экономике. 2019. №6 (85).
- Connected Car: V2V, V2I, V2X, V2P, V2G, V2D. Стандартизация, возможности и темпы развития умных автомобилей в России и в мире [Электронный ресурс]. // 1234g – Режим доступа: http://1234g.ru/novosti/v2v-v2i-v2x-v2p-v2g-v2d-connected-car
- Параллельные вычисления на GPU NVIDIA или суперкомпьютер в каждом доме [Электронный ресурс]. // NvWorld – Режим доступа: https://nvworld.ru/articles/cuda-parralel-for-home/
- Лебедев И.Г., Баркалов К.А. Реализация параллельного алгоритма глобального поиска на GPU // Вестник ПНИПУ. Аэрокосмическая техника – Пермь: ПНИПУ, 2014. Выпуск 39 С. 64–82.
- Nvidia CUDA ? неграфические вычисления на графических процессорах [Электронный ресурс]. // IXBT – Режим доступа: https://www.ixbt.com/video3/cuda-1.shtml
- Технология параллельного программирования OpenCL [Электронный ресурс]. // Mechanoid – Режим доступа:http://mechanoid.su/parallel-opencl.html
- Казённов, А.М. Основы технологии CUDA и OpenCL /А.М. Казённов. — Москва: Московский физико-технический институт, 2013. — 65с.
- Direct Compute технология [Электронный ресурс]. // NBC12 – Режим доступа:https://nbc12.ru/to-note/item/37-directcompute