
Abstract
Content
- Introduction
- 1. Relevance of the topic
- 2. Purpose and objectives of the study
- 3. Research and Development Overview
- 3.1. The method of segmentation of handwritten text based on the construction of structural models
- 3.2. The Viterbi method
- Conclusion
- List of sources
Introduction
Intelligent systems based on artificial neural networks (ANN) can successfully solve the problems of pattern recognition, prediction, optimization, associative memory and control. Other, more traditional approaches to solving these problems are known, but they do not have the necessary flexibility beyond limited conditions. ANNs provide promising alternative solutions and many applications benefit from their use.
The capabilities of artificial neural networks for pattern recognition are widely used to work with any text. For example, these ANN capabilities are successfully used in the digitization of paper books, journals, manuscripts, and also simply when it is necessary to transfer any text into electronic format.
1. Relevance of the topic
To date, many systems have been developed that demonstrate the capabilities of artificial neural networks: networks capable of representing text phonetically, recognizing handwritten letters, and compressing images. Most powerful networks that focus on character and sound recognition are based on the principle of back extension, which is a systematic approach for training multilayer networks. Neural networks that work according to the above principle have replaced systems that consisted of a single layer of artificial neurons and were used for a wide class of tasks, including for organizing artificial vision. However, such systems also have significant drawbacks. First of all, it is that there is no guarantee that the network can be trained in finite time.
Segmentation of a string into characters is one of the most important steps in the process of optical character recognition (OCR), in particular, in optical recognition of document images. Line segmentation is the decomposition of an image containing a sequence of characters into fragments containing individual characters.
The importance of segmentation is due to the fact that most modern optical text recognition systems are based on classifiers (including neural networks) of individual characters, and not words or text fragments. In such systems, errors of incorrect slicing between characters are usually the cause of the lion's share of errors in the final recognition. [1]
2. Purpose and objectives of the study
The aim of the study is to develop a system of character-by-character segmentation of a merged handwritten text using a neural network.
The main objectives of the study:
- Analysis of the subject area and scope of the system.
- Review of existing text segmentation methods and similar systems.
- Evaluating the effectiveness of existing text segmentation methods and choosing the most effective one.
- A thorough analysis of the principles of operation and the possibilities of the chosen method for the implementation of the system.
- Implementation of the system using the selected method.
3. Research and Development Overview
Solving the problem of recognizing individual handwritten characters is much easier than solving a similar recognition problem for characters that are part of a handwritten text.[2] ] In this case, it is necessary not only to solve the problem of optical recognition of handwritten characters, but also the problem of segmentation of handwritten text – the separation of individual characters and their connecting elements from it.
The segmentation process is complicated by the distortions of character outlines characteristic of many handwriting when combining their graphical representation with the subsequent and previous characters.[3]
3.1. The method of segmentation of handwritten text based on the construction of structural models
The input data for the developed algorithm should be images with word styles, and the output data should be data that allows you to unambiguously determine the way the image pixels are divided into segments, each of which corresponds to a separate character.
Analysis of the requirements for the segmentation algorithm of the handwritten word style. To perform segmentation of the handwritten text, it is necessary to analyze the original character outline, determining whether each of the areas of the graphical representation of the handwritten text section belongs to a specific character. It is not possible to consider all possible distributions of areas of graphic representation of a section of a handwritten character due to the huge number of different distributions even for a raster representation of the style. [4]
The previously considered algorithm for constructing a structural model of the outline of a single character can be applied to construct a structural model of the outline of a whole word.[5] As in the case of individual characters, in this case it is necessary to first perform skeletonization of the original character outline.
During the operation of the algorithm, the selection of structural components will be performed, including key points and bends, from the location of which you can start when choosing boundaries that separate the areas of the outline of successive characters of the segmented text.
If we consider examples of structural models of individual words in handwritten text, we can highlight several visual features of these models.
First of all, it is worth noting that most of the dividing lines between adjacent letters of a word can be drawn through the middle of the connecting edge. Moreover, any of the ends of such an edge can be either a key point or a bend. On fig. 1, you can see the cases where both ends are a key point, as well as the case where one of the ends is a bend.

Fig. 1. One of the variants of segmentation of the word section
There are also images for which a segmentation option is possible, in which the dividing line can be drawn through key points or bends. This is possible in cases where there is no need to use connecting elements when drawing (Fig. 2).
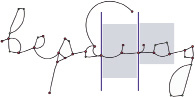
Fig. 2. Segmentation of a word with dividing lines passing through key points
An analysis of the structural models of individual words in the handwritten text showed that the points of interest are key points, bends, as well as the midpoints of the edges connecting them.
It is not always possible to separate adjacent characters with only vertical lines. Sometimes the graphical representation of one character may be partially above or below the graphical representation of its adjacent character. Such cases are possible not only because of the peculiarities of the graphical representation of individual characters, but also because of the handwriting features associated with a greater degree of inclination of the letters.
Based on the results of the above observations, it is possible to formulate a list of requirements for the handwritten text segmentation algorithm: the ability to take into account the presence of connecting elements between adjacent characters in the image; the possibility of assigning individual sections of the connecting elements to the outline of the connected symbols; the use of non-vertical straight lines as lines separating adjacent characters; taking into account the possible difference in the inclination of the styles of various characters in one word.
As previously noted, the points of interest for selecting boundary locations between adjacent word characters are keypoints, bends, and centers of connecting edges. However, it is possible to specify a dividing line passing through some point of interest only by selecting the second point.
To solve the segmentation problem, it was assumed that the choice of the second point can also be made from a set of points of interest.The process of constructing a set of lines, a subset of which will eventually become dividing lines, can be represented as an enumeration of all possible points of interest and the enumeration of a pair of each of them points to draw a line. For definiteness, we can assume that the lower of the two points is initially traversed, and any line considered will subsequently be given by a vector from the lower point to the upper one. With this approach, each straight line divides the plane of the structural model into two half-planes: left and right. For the most part, the elements of the structural model belonging to the right half-plane refer to the part of the word to the right of the dividing line, and the remaining ones, respectively, to the part to the left of the dividing line.
It is worth noting that clarifications will be made below, why not all points of the half-planes can be assigned to the corresponding parts. It is easy to see that as a result of the previously described enumeration, O(K2) straight lines will be obtained, which can be dividing lines during segmentation, where K is the number of points of interest in the structural model. The performance of any segmentation algorithm based on a given set of lines, one way or another, will depend on the size of this set. Therefore, it makes sense to weed out as many obviously incorrect lines as possible, which cannot be dividing lines.An analysis of the available structural models of handwritten words made it possible to identify three types of straight lines that can not be considered as possible connecting lines: horizontal or near-horizontal straight lines; lines that are formed by a vector that intersects at least one connecting edge at exactly one point; lines that intersect more than two connecting edges.
Further, for the chosen straight line, a clear principle should be formulated, according to which it is necessary to determine whether each of the elements of the structural model belongs to the left or right part of this straight line of this model. To do this, one should rely not only on the geometric characteristics of the straight line, but also on the location of the ends of the vector that defines this straight line. As mentioned earlier, the vector defining the line is directed from bottom to top. In such a case, we can clearly define two values y1 and y2, coordinates on the vertical y-axis between which the vector lies. If the value of the y-coordinate of a key point or bend is between the values y1 and y2, then its belonging to the left or right part of the dividing line is determined by whether the given point is to the left or to the right of the generating vector. For the remaining points, we can formulate the following algorithm for determining belonging to the left or right side.
3.2. The Viterbi method
The line segmentation algorithm is based on finding the optimal sequence of text and slotted areas within the vertical zones of the Viterbi algorithm application path. Then, the text line is processed by a separator, the drawing is applied and, finally, the connected components turn the image into text lines. Word segmentation is based on a gap metric that uses the soft cost-benefit objective function of a linear SVM separating successive connectivity components.
The algorithms have been tested for dataset benchmarking, handwriting segmentation, and have outperformed the participating algorithms in terms of execution speed. less stable than line extraction methods and can be classified as projections in the Hugh smear method.[6] Approaches based on global recognition predictions for text segmentation are very effective for printed documents. However, they can be used to correct skew in documents with a constant skew angle.[7] Howe based methods for processing documents with changing the skew angle between lines of text are not very efficient when the skew of a text line varies across its width.[8]
Thus, it is possible apply the "Piece Overhang" method, which can deal with both types of text angle skew.[9] On the other hand, "piecewise" projection is sensitive to size changes in text lines and significant spaces between successive words. These phenomena too negatively affect the effectiveness of blur methods.[10] In such cases, the results of two adjacent zones can be ambiguous, affecting line separators across the width of the document. To cope with these problems, it is necessary to enter a smooth version of the projection segment profiles of each zone as an instance of text and slot regions (text regions).[11] Then you need to requalify this area by applying HMM composition, which improves the statistics from the entire page of the document. Starting from left to right through the text, the introduced zone separator variables will take into account their proximity and local density foregrounds. In this article, the Viterbi algorithm will be applied as a decoding of the convolutional text and its subsequent splitting into segments. Convolutional texts are often used as inner codes in concatenated coding schemes. The reliability of the system as a whole depends to a large extent on the efficiency of their decoding. Therefore, for their decoding, it is necessary to use a time-consuming, but optimal rule in terms of error probability - decoding by maximum likelihood. The decisive advantage of convolutional texts over block codes is the possibility of using a very effective maximum likelihood decoding procedure - the Viterbi algorithm. The document images in the datasets cover a wide range of occurrences that occur in handwriting, presented in Figure 3.
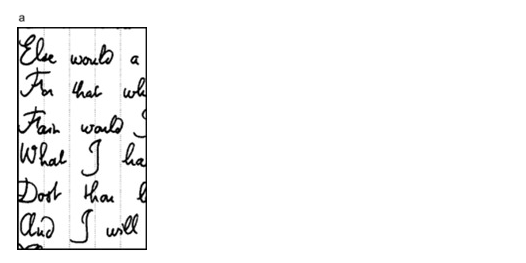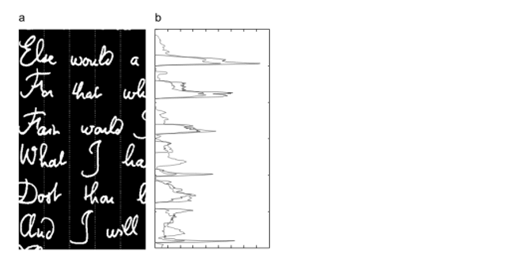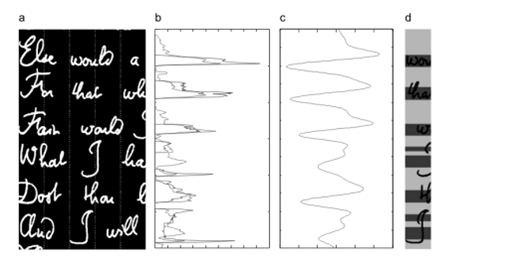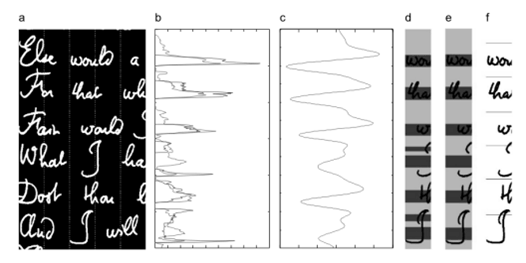 Fig. 3 A data set characterizing a person's handwriting
Fig. 3 A data set characterizing a person's handwriting
(animation, 7 frames, 146kb)
The Viterbi algorithm works as follows: 1. Initialization. The number of the tier t = 0. The metric of the zero node is equal to zero, an "empty" path is assigned to this node. 2. For tiers with numbers t = 1, ..., L, the following calculations are performed for each of the nodes on tier t: a. Find the metric of each of the paths leading to the node as the sum of the metrics of the preceding nodes and edges connecting the predecessor nodes to this node. b. Find the path with the minimum metric and we attribute this metric to this node. c. The path leading to the node is calculated by appending to the path leading to the selected preceding node an information symbol corresponding to the transition from the predecessor node to this node. 3. The path corresponding to a single node on the L tier is given to the recipient as a result of decoding.
Conclusion
In the course of the work carried out, the most used methods of handwritten text segmentation were considered, namely: the Viterbi method and the segmentation method based on the construction of structural models. The main properties, advantages and disadvantages of these methods are identified, and the principle of their operation is analyzed.
List of sources
- Петцольд, Ч. Код. Тайный язык информатики / Ч. Петцольд и др. – М.: Триумф, 2015. – 315 c.
- Корман, Т. Х. Алгоритмы. Построение и анализ / Т. Х. Корман и др. – М.: Лучшие книги, 2015. – 170 c.
- Рашид, Т. Создаем нейронную сеть / Т. Рашид. – М.: Вильямс, 2016. – 18 c.
- Гудфеллоу, Я. Deep Learning / Я. Гудфеллоу, И. Бенджио, А. Курвилль. – М.: The MIT Press, 2017. – 652 c.
- Сегаран, Т. Programming Collective Intelligence / Т. Сегаран. – Москва: Символ-Плюс, 2011. – 375 c.
- Z. Razak, K. Zulkiflee, и др, Off-line handwriting text line segmentation: a review / Z. Razak, – International Journal of Computer Science and Network Security, 2008. 12–20с.
- Yanikoglu, Segmentation of off-line cursive handwriting using linear programming / B. Yanikoglu, P.A. Sandon, – Pattern Recognition, 1998. 1825–1833с.
- G. Louloudis, Text line detection in unconstrained handwritten documents using a block-based Hough transform approach / G. Louloudis, B. Gatos, C. Halatsis, –Proceedings of International Conference on Document Analysis and Recognition, 2007. 599–603с.
- H. Chou, Y. Chu, F. Chang, Estimation of skew angles for scanned documents based on piecewise covering by parallelograms / H. Chou, – Pattern Recognition, 2007. 443–455с.
- M. Arivazhagan, H. Srinivasan, S. Srihari, A statistical approach to line segmentation in handwritten documents / M. Arivazhagan, – Proceedings of SPIE 2007, 65с.
- D.J. Kennard, W.A. Barrett, Separating lines of text in free-form handwritten historical documents, / D.J. Kennard, – in: Proceedings of International Workshop on Document Image Analysis for Libraries, 2006, 12–23с.