
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования
- 3. Обзор исследований и разработок
- 3.1. Метод сегментации рукописного текста на основе построение структурных моделей
- 3.2. Метод Витерби
- Выводы
- Список источников
Введение
Интеллектуальные системы на основе искусственных нейронных сетей (ИНС) позволяют с успехом решать проблемы распознавания образов, выполнения прогнозов, оптимизации, ассоциативной памяти и управления. Известны и иные, более традиционные подходы к решению этих проблем, однако они не обладают необходимой гибкостью за пределами ограниченных условий. ИНС дают многообещающие альтернативные решения, и многие приложения выигрывают от их использования.
Возможности искусственных нейросетей по распознаванию образов широко применяются для работ с каким-либо текстом. К примеру, данные возможности ИНС успешно используются при оцифровке бумажных книг, журналов, рукописей, а также просто при необходимости перевода любого текста в электронный формат.
1. Актуальность темы
На сегодняшний день разработано много систем, которые демонстрируют возможности искусственных нейронных сетей: сети способные представлять текст фонетически, распознавать рукописные буквы, сжимать изображения. Большинство мощных сетей, которые ориентированы на распознавание символов и звуков берут за основу принцип обратного расширения, который является систематическим подходом для обучения многослойных сетей. Нейронные сети, которые работают по вышеуказанному принципу пришли на смену системам, которые состояли из одного слоя искусственных нейронов и использовались для широкого класса задач, в том числе для организации искусственного зрения. Однако такие системы имеют и существенные недостатки. Прежде всего, это то, что нет гарантии, что сеть может быть обучена за конечное время.
Сегментация строки на символы является одним из важнейших этапов в процессе оптического распознавания символов (OCR), в частности, при оптическом распознавании изображений документов. Сегментацией строки называется декомпозиция изображения, содержащего последовательность символов, на фрагменты, содержащие отдельные символы.
Сегментация строки на символы является одним из важнейших этапов в процессе оптического распознавания символов (OCR), в частности, при оптическом распознавании изображений документов. Сегментацией строки называется декомпозиция изображения, содержащего последовательность символов, на фрагменты, содержащие отдельные символы.
Важность сегментации обусловлена тем обстоятельством, что в основе большинства современных систем оптического распознавания текста лежат классификаторы (в том числе – нейросетевые) отдельных символов, а не слов или фрагментов текста. В таких системах ошибки неправильного проставления разрезов между символами как правило являются причиной львиной доли ошибок конечного распознавания. [1]
2. Цель и задачи исследования
Целью исследования является разработка системы посимвольной сегментации слитного рукописного текста при помощи нейросети.
Основные задачи исследования:
- Анализ предметной области и сферы применения системы.
- Обзор существующих методов сегментации текста и аналогичных систем.
- Оценка эффективности существующих методов сегментации текста и выбор наиболее эффективного из них.
- Доскональный разбор принципов работы и возможностей выбранного метода для реализации системы.
- Реализация системы при помощи выбранного метода.
3. Обзор исследований и разработок
Решать задачу распознавания отдельных рукописных символов существенно проще, чем решать аналогичную задачу распознавания для символов, которые являются частью рукописного текста.[2] В таком случае необходимо не только решать задачу оптического распознавания рукописных символов, но и задачу сегментации рукописного текста – выделения из него отдельных символов и соединяющих их элементов.
Процесс сегментации осложняется характерными для многих почерков искажениями начертаний символов при соединении их графического представления с последующим и предыдущим символами.[3]
3.1. Метод сегментации рукописного текста на основе построение структурных моделей
Входными данными для разработанного алгоритма должны являться изображения с начертаниями слов, а выходными – данные, позволяющие однозначно определить способ разбиения пикселей изображения на сегменты, каждый из которых соответствует отдельному символу.
Анализ требований к алгоритму сегментации начертания рукописного слова Для выполнения сегментации рукописного текста необходимо проанализировать исходное начертание символа, определив принадлежность каждой из областей графического представления участка рукописного текста к определенному символу. Рассмотреть все возможные распределения областей графического представления участка рукописного символа не представляется возможным ввиду огромного количества различных распределений даже для растрового представления начертания.[4]
Рассмотренный ранее алгоритм построения структурной модели начертания отдельного символа можно применить для построения структурной модели начертания целого слова.[5] Как и в случае с отдельными символами, в данном случае необходимо предварительно выполнить скелетизацию исходного начертания символа.
В ходе работы алгоритма будет выполнено выделение структурных составляющих, в том числе ключевых точек и изгибов, от местоположения которых можно отталкиваться при выборе границ, разделяющих области начертания последовательных символов сегментируемого текста.
Если рассмотреть примеры структурных моделей отдельных слов рукописного текста, то можно выделить несколько визуальных особенностей этих моделей.
В первую очередь стоит отметить, что большинство разделительных линий между соседними буквами слова можно провести через середину соединяющего ребра. Причем любым из концов такого ребра может быть как ключевая точка, так и изгиб. На рис. 1 можно увидеть случаи, когда оба конца являются ключевой точкой, а также случай, когда один из концов является изгибом.

Рис. 1. Один из вариантов сегментации участка слова
Существуют и изображения, для которых возможен вариант сегментации, при котором разделительная линия может быть проведена через ключевые точки или изгибы. Такое возможно в случаях, когда при начертании отсутствует необходимость в использовании соединительных элементов (рис. 2).
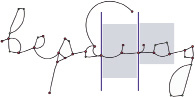
Рис. 2. Сегментация слова с разделительными линиями, проходящими через ключевые точки
Анализ структурных моделей отдельных слов рукописного текста показал, что точками интереса являются ключевые точки, изгибы, а также середины соединяющих их ребер.
Не всегда возможно разделить соседние символы только вертикальными линиями. Иногда графическое представление одного символа может частично находиться над или под графическим представлением соседнего ему символа. Такие случаи возможны не только из-за особенностей графического представления отдельных символов, но и по причине особенностей почерка, связанных с большей степенью наклона букв.
По результатам перечисленных наблюдений можно сформулировать список требований к алгоритму сегментации рукописного текста: возможность учитывать присутствие на изображении соединительных элементов между соседними символами; возможность отнесения отдельных участков соединительных элементов к начертанию соединяемых символов; использование невертикальных прямых в качестве разделяющих соседние символы линий; учет возможного различия наклона начертаний различных символов в одном слове.
Как было ранее отмечено, точками интереса для выбора местоположений границ между соседними символами слова являются ключевые точки, изгибы и центры соединяющих ребер. Однако задать разделяющую прямую, проходящую через некоторую точку интереса, можно, лишь выбрав вторую точку.
Для решения задачи сегментации было сделано предположение о том, что выбор второй точки можно осуществить так же из множества точек интереса. Процесс построения множества прямых, подмножество которых в итоге станет разделяющими линиями, можно представить в виде перебора всех возможных точек интереса и перебора в пару каждой из них точки для проведения прямой. Для определенности можно полагать, что изначально перебирается нижняя из двух точек, а любая рассмотренная прямая будет впоследствии задаваться вектором из нижней точки в верхнюю. При таком подходе каждая прямая разделяет плоскость структурной модели на две полуплоскости: левую и правую. По большей части элементы структурной модели, принадлежащие правой полуплоскости, относятся к части слова справа от разделительной линии, а оставшиеся, соответственно, – к левой от разделительной линии части. Стоит отметить, что далее будут сделаны уточнения, почему не все точки полуплоскостей могут быть отнесены к соответствующим частям.
Несложно заметить, что в результате работы описанного ранее перебора будет получено O(K2) прямых, которые могут являться разделяющими линиями при сегментации, где K – количество точек интереса в структурной модели. Быстродействие любого алгоритма сегментации, опирающегося на данное множество прямых, так или иначе, будет зависеть от размера этого множества. Следовательно, имеет смысл отсеять как можно больше заведомо некорректных прямых, которые не могут являться разделительными линиями. Анализ имеющихся структурных моделей рукописных слов позволил выявить три типа прямых, которые можно не рассматривать в качестве возможных соединяющих линий: горизонтальные или близкие к горизонтальным прямые; прямые, которые образованы вектором, пересекающим хотя бы одно соединяющее ребро ровно в одной точке; прямые, пересекающие более двух соединяющих ребер.
Далее для выбранной прямой следует сформулировать четкий принцип, по которому следует определять принадлежность каждого из элементов структурной модели к левой или правой от данной прямой части этой модели. Для этого следует опираться не только на геометрические характеристики прямой, но и на местоположение концов вектора, которым задается эта прямая. Как уже ранее было сказано, задающий прямую вектор направлен снизу вверх. В таком случае мы можем четко определить два значения y1 и y2 координаты на вертикальной оси Y, между которыми находится вектор. Если значение y-координаты ключевой точки или изгиба находится между значениями y1 и y2, то ее принадлежность к левой или правой от разделительной линии части определяется тем, слева или справа данная точка находится от образующего вектора. Для оставшихся точек можно сформулировать следующий алгоритм определения принадлежности к левой или правой части.
3.2. Метод Витерби
Алгоритм сегментации линии основан на поиске оптимальной последовательности текстовых и щелевых областей в пределах вертикальных зон пути применения алгоритма Витерби. Затем, текстовая строка обрабатывается сепаратором, рисунок наносится и, наконец, подключенные компоненты превращают изображение в текстовые строки. Сегментация слов основываются на разрыве метрики, которая использует целевую функцию мягкой рентабельности линейного SVM, отделяющий последовательные компоненты связности.
Алгоритмы протестированы на бенчмаркинг наборов данных, сегментации почерка и обогнали участвующие алгоритмы по скорости выполнения. менее устойчивыми, нежели методы экстракции линии и могут быть классифицированы как проекции в методе смазывания Хью.[6] Подходы, основанные на глобальных прогнозах распознавания при сегментации текста, очень эффективны для печатных документов. Тем не менее, они могут быть применены для коррекции перекоса в документах с постоянным углом перекоса.[7] Хау методы, основанные для обработки документов с изменением угла перекоса между строками текста не очень эффективны, когда перекос текстовой строки изменяется по ее ширине.[8]
Таким образом, можно применять метод «Кусочного выступа», который может иметь дело с обоими типами перекоса изменения угла текста.[9] С другой стороны, «кусочная» проекция чувствительна к изменению размера в текстовых строках и существенных пробелах между последовательными словами. Эти явления слишком негативно влияют на эффективность методов размытия.[10] В таких случаях результаты двух смежных зон могут быть неоднозначными, влияющие разделители строк по ширине документа. Чтобы справиться с этими проблемами, необходимо ввести плавную версию профилей проекционных сегментов каждой зоны как экземпляр текстовых и щелевых регионов (участков текста).[11] Затем нужно переквалифицировать эту область путем применения композиции СММ, что улучшает статистику из всей страницы документа. Н#ачиная движение по тексту слева направо введенные переменные-сепараторы последовательных зон будут учитывать их близости и местные передние планы плотности. Будет применен алгоритм «Витерби» в качестве декодирования сверточного текста и последующего его разбиения на сегменты. Сверточные тексты часто используются как внутренние коды в каскадных схемах кодирования. От эффективности их декодирования в большой степени зависит надежность системы в целом. Поэтому для их декодирования необходимо использовать трудоемкое, но оптимальное в смысле вероятности ошибки правило – декодирование по максимуму правдоподобия. Решающим преимуществом сверточных текстов перед блоковыми кодами является возможность применения весьма эффективной процедуры декодирования по максимуму правдоподобия – алгоритма Витерби. Изображения документов в наборах данных охватывают широкий спектр случаев, которые происходят в почерке, представлены на рисунке 3.
 Рис. 3. Набор данных, характеризующий почерк человека
Рис. 3. Набор данных, характеризующий почерк человека
(анимация, 7 кадров, 146кб)
Алгоритм Витерби работает следующим образом: 1. Инициализация. Номер яруса t = 0. Метрика нулевого узла приравнивается нулю, за этим узлом закрепляется «пустой» путь. 2. Для ярусов с номерами t = 1,…, L для каждого из узлов на ярусе t выполняются следующие вычисления: a. Находим метрику каждого из путей, ведущих в узел, как сумму метрик предшествующих узлов и ребер, связывающих узлы-предшественники с данным узлом. b. Находим путь с минимальной метрикой и эту метрику приписываем данному узлу. c. Путь, ведущий в узел, вычисляется дописыванием к пути, ведущему в выбранный предшествующий узел, информационного символа, соответствующего переходу из узла-предшественника в данный узел. 3. Путь, соответствующий единственному узлу на ярусе L, выдается получателю как результат декодирования.
Вывод
В ходе проведенной работы были рассмотрены наиболее используемые методы сегментации рукописного текста, а именно: метод Витерби и метод сегментации на основе построения структурных моделей. Выявлены основные свойства, достоинства и недостатки данных методов, а также разобран принцип их работы.
Список источников
- Петцольд, Ч. Код. Тайный язык информатики / Ч. Петцольд и др. – М.: Триумф, 2015. – 315 c.
- Корман, Т. Х. Алгоритмы. Построение и анализ / Т. Х. Корман и др. – М.: Лучшие книги, 2015. – 170 c.
- Рашид, Т. Создаем нейронную сеть / Т. Рашид. – М.: Вильямс, 2016. – 18 c.
- Гудфеллоу, Я. Deep Learning / Я. Гудфеллоу, И. Бенджио, А. Курвилль. – М.: The MIT Press, 2017. – 652 c.
- Сегаран, Т. Programming Collective Intelligence / Т. Сегаран. – Москва: Символ-Плюс, 2011. – 375 c.
- Z. Razak, K. Zulkiflee, и др, Off-line handwriting text line segmentation: a review / Z. Razak, – International Journal of Computer Science and Network Security, 2008. 12–20с.
- Yanikoglu, Segmentation of off-line cursive handwriting using linear programming / B. Yanikoglu, P.A. Sandon, – Pattern Recognition, 1998. 1825–1833с.
- G. Louloudis, Text line detection in unconstrained handwritten documents using a block-based Hough transform approach / G. Louloudis, B. Gatos, C. Halatsis, –Proceedings of International Conference on Document Analysis and Recognition, 2007. 599–603с.
- H. Chou, Y. Chu, F. Chang, Estimation of skew angles for scanned documents based on piecewise covering by parallelograms / H. Chou, – Pattern Recognition, 2007. 443–455с.
- M. Arivazhagan, H. Srinivasan, S. Srihari, A statistical approach to line segmentation in handwritten documents / M. Arivazhagan, – Proceedings of SPIE 2007, 65с.
- D.J. Kennard, W.A. Barrett, Separating lines of text in free-form handwritten historical documents, / D.J. Kennard, – in: Proceedings of International Workshop on Document Image Analysis for Libraries, 2006, 12–23с.