
Реферат за темою випускної роботи
Зміст
- Введення
- 1. Актуальність теми
- 2. Мета і завдання дослідження
- 3. Огляд досліджень та розробок
- 3.1. Метод сегментації рукописного тексту на основі побудова структурних моделей
- 3.2. Метод Вітербі
- Висновок
- Список джерел
Введення
Інтелектуальні системи на основі штучних нейронних мереж (ІНС) дозволяють успішно вирішувати проблеми розпізнавання образів, виконання прогнозів, оптимізації, асоціативної пам'яті та управління. Відомі й інші, більш традиційні підходи до вирішення цих проблем, однак вони не мають необхідної гнучкості за межами обмежених умов. ІНС дають багатообіцяючі альтернативні рішення, і багато програм виграють від їх використання.
Можливості штучних нейромереж з розпізнавання образів широко використовуються для робіт з будь-яким текстом. Наприклад, дані можливості ІНС успішно використовуються при оцифровуванні паперових книг, журналів, рукописів, а також просто при необхідності переведення будь-якого тексту в електронний формат.
1. Актуальність теми
На сьогоднішній день розроблено багато систем, які демонструють можливості штучних нейронних мереж: мережі здатні репрезентувати текст фонетично, розпізнавати рукописні літери, стискати зображення. Більшість потужних мереж, орієнтованих на розпізнавання символів і звуків, беруть за основу принцип зворотного розширення, який є систематичним підходом для навчання багатошарових мереж. Нейронні мережі, які працюють за вищевказаним принципом, прийшли на зміну системам, які складалися з одного шару штучних нейронів і використовувалися для широкого класу завдань, у тому числі для організації штучного зору. Однак такі системи мають і суттєві недоліки. Перш за все це те, що немає гарантії, що мережа може бути навчена за кінцевий час.
Сегментація рядка на символи є одним із найважливіших етапів у процесі оптичного розпізнавання символів (OCR), зокрема при оптичному розпізнаванні зображень документів. Сегментацією рядка називається декомпозиція зображення, що містить послідовність символів, фрагменти, що містять окремі символи.
Сегментация строки на символы является одним из важнейших этапов в процессе оптического распознавания символов (OCR), в частности, при оптическом распознавании изображений документов. Сегментацией строки называется декомпозиция изображения, содержащего последовательность символов, на фрагменты, содержащие отдельные символы.
Важливість сегментації обумовлена тим, що у основі більшості сучасних систем оптичного розпізнавання тексту лежать класифікатори (зокрема – нейромережевые) окремих символів, а чи не слів чи фрагментів тексту. У таких системах помилки неправильного проставлення розрізів між символами зазвичай є причиною левової частки помилок кінцевого розпізнавання. [1]
2. Мета і завдання дослідження
Метою дослідження є розробка системи посимвольної сегментації злитого рукописного тексту за допомогою нейромережі.
Основні завдання дослідження:
- Аналіз предметної області та сфери застосування системи.
- Огляд існуючих методів сегментації тексту та подібних систем.
- Оцінка ефективності існуючих методів сегментації тексту і вибір найбільш ефективного з них.
- Досконалий розбір принципів роботи і можливостей обраного методу для реалізації системи.
- Реалізація системи за допомогою обраного методу.
3. Огляд досліджень та розробок
Вирішувати задачу розпізнавання окремих рукописних символів істотно простіше, ніж вирішувати аналогічну задачу розпізнавання для символів, які є частиною рукописного тексту.[2] в такому випадку необхідно не тільки вирішувати задачу оптичного розпізнавання рукописних символів, а й задачу сегментації рукописного тексту – виділення з нього окремих символів і з'єднують їх елементів.
Процес сегментації ускладнюється характерними для багатьох почерків спотвореннями накреслень символів при з'єднанні їх графічного представлення з подальшим і попереднім символами.[3]
3.1. Метод сегментації рукописного тексту на основі побудова структурних моделей
Вхідними даними для розробленого алгоритму повинні бути зображення з зображеннями слів, а вихідними – дані, що дозволяють однозначно визначити спосіб розбиття пікселів зображення на сегменти, кожен із яких відповідає окремому символу.
Аналіз вимог до алгоритму сегментації написання рукописного слова Для виконання сегментації рукописного тексту необхідно проаналізувати вихідне зображення символу, визначивши приналежність кожної з областей графічного представлення ділянки рукописного тексту до певного символу. Розглянути всі можливі розподілу областей графічного уявлення ділянки рукописного символу неможливо у вигляді великої кількості різних розподілів навіть у растрового уявлення начертания. [4]
Розглянутий раніше алгоритм побудови структурної моделі зображення окремого символу можна застосувати для побудови структурної моделі зображення цілого слова.[5] Як і у випадку з окремими символами, у цьому випадку необхідно попередньо виконати скелетизацію вихідного зображення символу.
У ході роботи алгоритму буде виконано виділення структурних складових, у тому числі ключових точок і вигинів, від розташування яких можна відштовхуватися при виборі кордонів, що розділяють області зображення послідовних символів тексту, що сегментується.
Якщо розглянути приклади структурних моделей окремих слів рукописного тексту, можна виділити кілька візуальних особливостей цих моделей.
Насамперед варто відзначити, що більшість розділових ліній між сусідніми літерами слова можна провести через середину ребра, що з'єднує. Причому будь-яким із кінців такого ребра може бути як ключова точка, так і вигин. На рис. 1 можна побачити випадки, коли обидва кінці є ключовою точкою, а також випадок, коли один із кінців є вигином.

Рис. 1. Один з варіантів сегментації ділянки слова
Існують і зображення, для яких можливий варіант сегментації, при якому розділова лінія може бути проведена через ключові точки або вигини. Таке можливо у випадках, коли при накресленні відсутня необхідність у використанні сполучних елементів (рис. 2).
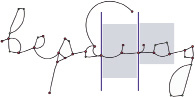
Рис. 2. Сегментація слова з розділовими лініями, що проходять через ключові точки
Аналіз структурних моделей окремих слів рукописного тексту показав, що точками інтересу є ключові точки, вигини, а також середини ребер, що з'єднують їх.
Не завжди можна розділити сусідні символи лише вертикальними лініями. Іноді графічне уявлення одного символу може частково перебувати над або під графічним уявленням сусіднього символу. Такі випадки можливі не тільки через особливості графічного представлення окремих символів, а й через особливості почерку, пов'язані з більшим ступенем нахилу букв.
За результатами перерахованих спостережень можна сформулювати перелік вимог до алгоритму сегментації рукописного тексту: можливість враховувати присутність на зображенні сполучних елементів між сусідніми символами; можливість віднесення окремих ділянок з'єднувальних елементів до накреслення символів, що з'єднуються; використання невертикальних прямих як ліній, що розділяють сусідні символи; врахування можливої різниці нахилу накреслень різних символів в одному слові.
Як було раніше зазначено, точками інтересу для вибору розташування меж між сусідніми символами слова є ключові точки, вигини і центри ребер, що з'єднують. Однак задати пряму, що розділяє, проходить через деяку точку інтересу, можна, лише вибравши другу точку.
Для вирішення задачі сегментації було зроблено припущення про те, що вибір другої точки можна здійснити так само з безлічі точок інтересу.Процес побудови безлічі прямих, підмножина яких у результаті стане поділяючими лініями, можна як перебору всіх можливих точок інтересу і перебору на пару кожної їх точки щодо прямий. Для певності можна вважати, що спочатку перебирається нижня з двох точок, а будь-яка розглянута пряма буде згодом задаватися вектором з нижньої точки у верхню. При такому підході кожна пряма поділяє площину структурної моделі на дві напівплощини: ліву та праву. Здебільшого елементи структурної моделі, що належать до правої напівплощини, відносяться до частини слова праворуч від розділової лінії, а ті, що залишилися, відповідно, – до лівої від розділової лінії частини. Далі будуть зроблені уточнення, чому не всі точки напівплощин можуть бути віднесені до відповідних частин.
Неважко помітити, що в результаті роботи описаного раніше перебору буде отримано прямих O(K2), які можуть бути розділяючими лініями при сегментації, де K - кількість точок інтересу в структурній моделі. Швидкодія будь-якого алгоритму сегментації, що спирається на цю безліч прямих, так чи інакше, залежатиме від розміру цієї множини. Отже, має сенс відсіяти якнайбільше свідомо некоректних прямих, які можуть бути розділовими лініями.Аналіз наявних структурних моделей рукописних слів дозволив виявити три типи прямих, які можна не розглядати як можливі сполучні лінії: горизонтальні або близькі до горизонтальних прямі; прямі, які утворені вектором, що перетинає хоча б одне ребро, що з'єднує, рівно в одній точці; прямі, що перетинають більше двох ребер, що з'єднують.
Далі для обраної прямої слід сформулювати чіткий принцип, яким слід визначати приналежність кожного з елементів структурної моделі до лівої чи правої від цієї прямої частини цієї моделі. Для цього слід спиратися не тільки на геометричні характеристики прямої, але і на місце розташування кінців вектора, яким задається ця пряма. Як раніше було сказано, задає пряму вектор спрямований знизу вгору. У такому разі ми можемо чітко визначити два значення y1 та y2 координати на вертикальній осі Y, між якими знаходиться вектор. Якщо значення y-координати ключової точки або вигину знаходиться між значеннями y1 і y2, то її приналежність до лівої або правої розділової лінії частини визначається тим, ліворуч або праворуч дана точка знаходиться від утворює вектора. Для точок, що залишилися, можна сформулювати наступний алгоритм визначення приналежності до лівої або правої частини.
3.2. Метод Вітербі
Алгоритм сегментації лінії ґрунтується на пошуку оптимальної послідовності текстових та щілинних областей у межах вертикальних зон шляху застосування алгоритму Вітербі. Потім текстовий рядок обробляється сепаратором, малюнок наноситься і, нарешті, підключені компоненти перетворюють зображення на текстові рядки. Сегментація слів ґрунтуються на розриві метрики, яка використовує цільову функцію м'якої рентабельності лінійного SVM, що відокремлює послідовні компоненти зв'язності.
Алгоритми протестовані на бенчмаркінг наборів даних, сегментації почерку та обігнали алгоритми, що беруть участь, за швидкістю виконання. менш стійкими, ніж методи екстракції лінії, і можуть бути класифіковані як проекції у методі змащування Хью.[6] Підходи, що ґрунтуються на глобальних прогнозах розпізнавання при сегментації тексту, є дуже ефективними для друкованих документів. Тим не менш, вони можуть бути застосовані для корекції перекосу в документах із постійним кутом перекосу.[7] Хау методи, засновані на обробку документів зі зміною кута перекосу між рядками тексту дуже ефективні, коли перекіс текстового рядка змінюється з його ширине.[8]
Таким чином, можна застосовувати метод «Шматкового виступу», який може мати справу з обома типами перекосу зміни кута тексту.[9] З іншого боку, «кускова» проекція чутлива до зміни розміру текстових рядків та суттєвих пробілів між послідовними словами. Ці явища надто негативно впливають ефективність методів розмиття.[10] У разі результати двох суміжних зон може бути неоднозначними, впливають роздільники рядків по ширині документа. Щоб упоратися з цими проблемами, необхідно запровадити плавну версію профілів проекційних сегментів кожної зони як екземпляр текстових та щілинних регіонів (ділянок тексту).[[11] Потім слід перекваліфікувати цю область шляхом застосування композиції СММ, що покращує статистику зі всієї сторінки документа. Починаючи рух по тексту зліва направо введені змінні-сепаратори послідовних зон враховуватимуть їх близькість та місцеві передні плани щільності. У цій статті буде застосовано алгоритм «Вітербі» як декодування згорткового тексту та подальшого його розбиття на сегменти. Згорткові тексти часто використовуються як внутрішні коди у каскадних схемах кодування. Від ефективності їх декодування великою мірою залежить надійність системи загалом. Тому для їх декодування необхідно використовувати трудомістке, але оптимальне в сенсі ймовірності помилки правило - декодування максимально правдоподібності. Вирішальною перевагою згорткових текстів перед блоковими кодами є можливість застосування вельми ефективної процедури декодування максимально правдоподібності – алгоритму Вітербі. Зображення документів у наборах даних охоплюють широкий спектр випадків, що відбуваються у почерку, представлені на малюнку 3.
 Рис. 3 Набір даних, що характеризує почерк людини
Рис. 3 Набір даних, що характеризує почерк людини
(анiмацiя, 7 кадрiв, 146кб)
Алгоритм Вітербі працює наступним чином: 1. Ініціалізація. Номер ярусу t = 0. Метрика нульового вузла прирівнюється нулю, за цим вузлом закріплюється «порожній» шлях. 2. Для ярусів з номерами t = 1,..., L для кожного з вузлів на ярусі t виконуються наступні обчислення: a. знаходимо метрику кожного із шляхів, що ведуть у вузол, як суму метрик попередніх вузлів і ребер, що зв'язують вузли-попередники з даним вузлом. B. знаходимо шлях з мінімальною метрикою і цю метрику приписуємо даному вузлу. C. шлях, що веде в вузол, обчислюється дописуванням до шляху, що веде в обраний попередній вузол, інформаційного символу, відповідного переходу з вузла-попередника в даний вузол. 3. Шлях, що відповідає єдиному вузлу на ярусі L, видається одержувачу як результат декодування.
Висновок
В ході проведеної роботи були розглянуті найбільш використовувані методи сегментації рукописного тексту, а саме: метод Вітербі і метод сегментації на основі побудови структурних моделей. Виявлено основні властивості, переваги і недоліки даних методів, а також розібраний принцип їх роботи.
Список джерел
- Петцольд, Ч. Код. Тайный язык информатики / Ч. Петцольд и др. – М.: Триумф, 2015. – 315 c.
- Корман, Т. Х. Алгоритмы. Построение и анализ / Т. Х. Корман и др. – М.: Лучшие книги, 2015. – 170 c.
- Рашид, Т. Создаем нейронную сеть / Т. Рашид. – М.: Вильямс, 2016. – 18 c.
- Гудфеллоу, Я. Deep Learning / Я. Гудфеллоу, И. Бенджио, А. Курвилль. – М.: The MIT Press, 2017. – 652 c.
- Сегаран, Т. Programming Collective Intelligence / Т. Сегаран. – Москва: Символ-Плюс, 2011. – 375 c.
- Z. Razak, K. Zulkiflee, и др, Off-line handwriting text line segmentation: a review / Z. Razak, – International Journal of Computer Science and Network Security, 2008. 12–20с.
- Yanikoglu, Segmentation of off-line cursive handwriting using linear programming / B. Yanikoglu, P.A. Sandon, – Pattern Recognition, 1998. 1825–1833с.
- G. Louloudis, Text line detection in unconstrained handwritten documents using a block-based Hough transform approach / G. Louloudis, B. Gatos, C. Halatsis, –Proceedings of International Conference on Document Analysis and Recognition, 2007. 599–603с.
- H. Chou, Y. Chu, F. Chang, Estimation of skew angles for scanned documents based on piecewise covering by parallelograms / H. Chou, – Pattern Recognition, 2007. 443–455с.
- M. Arivazhagan, H. Srinivasan, S. Srihari, A statistical approach to line segmentation in handwritten documents / M. Arivazhagan, – Proceedings of SPIE 2007, 65с.
- D.J. Kennard, W.A. Barrett, Separating lines of text in free-form handwritten historical documents, / D.J. Kennard, – in: Proceedings of International Workshop on Document Image Analysis for Libraries, 2006, 12–23с.