
Реферат за темою випускної роботи
Зміст
- Вступ
- 1. Мета та завдання дослідження
- 2. Актуальність теми
- 3. Аналіз предметної галузі
- 3.1 Нейронна мережа
- 3.2 Нейрон
- 3.3 Синапс
- 3.4 Функція активації
- 3.5 Багатошаровий персептрон
- 3.6 Метод зворотного розповсюдження помилки
- 3.7 Згорткові нейронні мережі
- 4. Огляд досліджень та розробок
- 4.1. Lalal.ai
- 4.2. Аудіоредактори
- 5. Огляд інструментів розробки
- 5.1 TensorFlow та фреймворк Keras
- 5.1.1 Модуль Keras у TensorFlow 2
- 5.1.2 TensorBoard
- 5.2. PyTorch
- 5.3 ApacheMxnet
- Список джерел
Вступ
Проблема поділу джерел звуку або audio source separation є досить популярною, тим паче її окремий випадок – поділ музики та голосу. Однак, вирішення подібних завдань за допомогою Класичні алгоритми складні, особливо для розділення голосу. Самі алгоритми досить складні, а результат буває далеким від ідеального. Також слід враховувати, що голосів може бути кілька, а вони у свою чергу, можуть бути оброблені реверберацією, затримками та іншими ефектами.
Отже, для вирішення подібних завдань слід використовувати вже досить популярне глибоке машинне навчання. Алгоритм сам повинен навчитися шукати відповідні ознаки, і отримувати їх, отримуючи нову аудіодоріжку.
1. Мета та завдання дослідження
Метою даної роботи є пошук відповідної архітектури та навчання глибокої згорткової нейронної мережі, щоб вона була здатна виділяти з музики голос на досить коректному рівні з найменшою кількістю сторонніх шумів. До завдань дослідження відноситься порівняння створеної нейронної мережі та аналогічних програм із вихідним «незмішаним» голосом різних композицій для виявлення похибки під час роботи створеної програми[1][2].
2. Актуальність теми
Хоча обробка звуку є досить цікавим практично корисним завданням, в галузі глибокого навчання дана тема досліджується не так сильно, як робота із зображеннями чи текстами. Можливо, причиною є велика складність розробки, адже якщо із зображеннями і текстом можна працювати відразу, то звук потрібно перевести у відповідний масив даних. В основному, робота відбувається з частотами, що вимагає роботи з віконним перетворенням Фур'є, або ж з вейвлет-перетворення. Поділ голосу та музики може бути корисним не тільки для отримання. окремої музичної доріжки для пісень, які не мають, але й для обробки аудіозаписів голоси, забирання шумів і т.д. Незважаючи на те, що вже існує багато різних варіантів вирішення даної задачі за допомогою машинного навчання всі рішення не працюють ідеально. Їхня робота залежить від топології мережі, навчальної вибірки, способу мінімізації помилки, і навіть кількості ітерацій. Алгоритми змінюються, розробляються нові, отже, дана тема, як і багато інших, пов'язаних з машинним навчанням залишатимуться актуальними.
3. Аналіз предметної галузі
3.1. Нейронна мережа
Нейронна мережа - це послідовність нейронів, з'єднаних між собою синапсами. Структура нейронної мережі прийшла у світ програмування прямісінько з біології. Завдяки такій структурі, машина набуває здатності аналізувати і навіть запам'ятовувати різноманітну інформацію. Нейронні мережі також здатні не лише аналізувати вхідну інформацію, але й відтворювати її зі своєї пам'яті.
Особливість нейронних мереж полягає в їх навчальності. Нейросети можуть розпізнавати глибші, іноді несподівані закономірності у даних. У загальному значенні слова, навчання полягає у знаходженні вірних коефіцієнтів зв'язку між нейронами (про які буде сказано далі), а також в узагальненні даних та виявленні складних залежностей між вхідними та вихідними сигналами. Якщо спочатку її легко обдурити, то через пару сотень тисяч дій вона легко розпізнає, якщо ви намагаєтеся дати їй щось не те.
Найчастіше для цього потрібно «прогнати» її роботу на десятках мільйонів наборів вхідних даних, вказуючи їй вірні та прибираючи неправильні варіанти.
Нейронні мережі використовуються для вирішення складних завдань, які вимагають аналітичних обчислень подібних до тих, що робить людський мозок. Найпоширенішими застосуваннями нейронних мереж є завдання:
• Класифікація,
• Передбачення,
Розглянемо докладніше основні компоненти нейронної мережі.
3.2. Нейрон.
Нейрон — це обчислювальна одиниця, яка отримує інформацію, здійснює над нею прості обчислення та передає її далі. Вони поділяються на три основні типи: вхідний, прихований та вихідний. коли нейромережа складається з великої кількості нейронів, вводять термін шару. Відповідно, є вхідний шар, який отримує інформацію, n прихованих шарів, які її обробляють та вихідний шар, який виводить результат. У кожного з нейронів є 2 основні параметри: вхідні дані (input data) та вихідні дані (output data). У поле input потрапляє сумарна інформація всіх нейронів з попереднього шару, після чого вона нормалізується за допомогою функції активації.
3.3. Синапс.
Синапс це зв'язок між двома нейронами. У синапсів є один параметр - вага. Завдяки йому вхідна інформація змінюється, коли передається від одного нейрона до іншого.
На зображенні нижче представлена частина нейронної мережі, де літерами I позначені вхідні нейрони, літерою H — прихований нейрон, а літерою w — ваги. З формули видно, що вхідна інформація – це сума всіх вхідних даних, помножених на відповідні їм ваги.
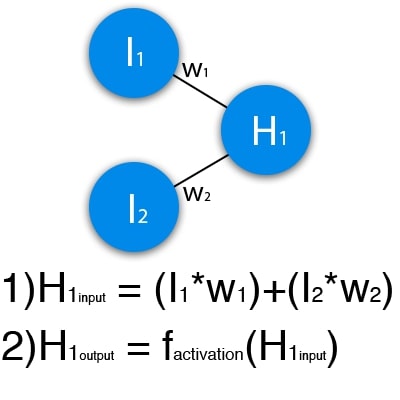
Малюнок 1 – схематичне зображення роботи одного нейрона
Подамо на вхід 1 та 0. Нехай w1=0.4 та w2 = 0.7 Вхідні дані нейрона Н1 будуть наступними: 1*0.4+0*0.7=0.4. Тепер коли ми маємо вхідні дані, ми можемо отримати вихідні дані, підставивши вхідне значення у функцію активації.
3.4. Функція активації.
Функція активації – це спосіб нормалізації вхідних даних (ми вже говорили про це раніше). Тобто, якщо на вході у вас буде велика кількість, пропустивши його через функцію активації, ви отримаєте вихід у потрібному діапазоні. Функцій активації досить багато тому ми розглянемо основні: Лінійна, Сігмоїд (Логістична) та Гіперболічний тангенс. Головні їх відмінності – це діапазон значень (рис. 2-4).
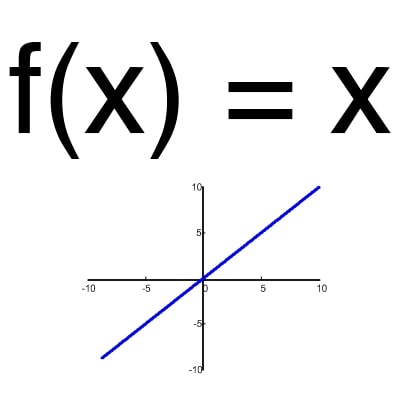
Малюнок 2 – лінійна функція
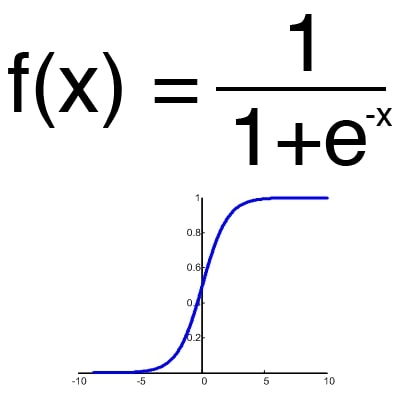
Малюнок 3 – сигмоїд
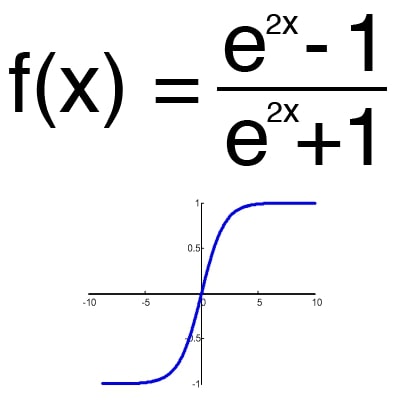
Малюнок 4 – гіперболічний тангенс
3.5. Функція активації.
Багатошаровий персептрон є найпростішою та найпоширенішою нейронною мережею. Є повнозв'язковою нейронною мережею (виходи попереднього шару з'єднані з усіма входами наступного шару) прямого поширення (сигнал йде тільки в одну сторону). Кожен синапс має власну вагу, що визначає силу передачі сигналів від одних конкретних нейронів іншим. Вихідних сигналів може бути як кілька, так і один, залежно від умов завдання [5][6].< /p>
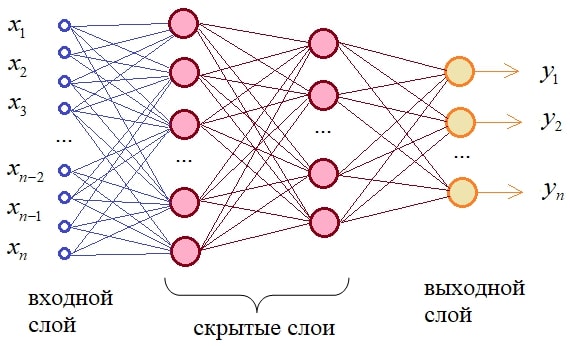
Малюнок 5 – схематичне зображення багатошарового персептрона
3.6. Метод зворотного розповсюдження помилки
Для навчання нейронної мережі «з нуля» беремо значення ваг випадковими числами від -0.5 до 0.5. Далі, необхідно перевірити результат роботи, та скоригувати ваги відповідно до сили помилки. Для цього використовується метод зворотного розповсюдження помилки. Цілі зворотного поширення прості: відрегулювати кожну вагу пропорційно тому, наскільки вона сприяє спільній помилці. Якщо ми ітеративно зменшуватимемо помилку кожної ваги, зрештою, у нас буде низка ваг, які дають хороші прогнози.
Пряме поширення можна розглядати як довгий ряд вкладених рівнянь. Якщо ви так думаєте про пряме поширення, то протилежне поширення - це просто додаток правила ланцюжка (диференціювання складної функції) для пошуку похідних втрат за будь-якою змінною у вкладеному рівнянні. Враховуючи функцію прямого поширення:
де A, B та C — функції активації на різних шарах. Користуючись правилом ланцюжка, обчислюємо похідну f(x) x:
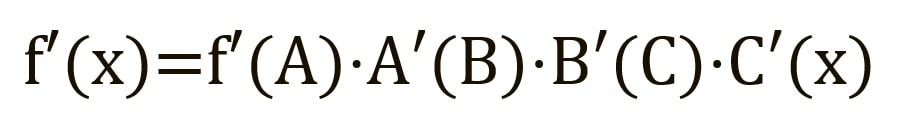
Щоб знайти похідну B, ми можемо зробити вигляд, що B (C(x)) є константою, замінити її змінною-заповнювачем B, і продовжити пошук похідної B стандартно:
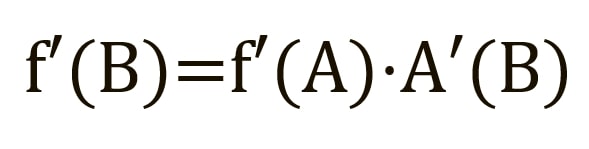
Цей простий метод поширюється на будь-яку змінну всередині функції, і дозволяє нам точно визначити вплив кожної змінною на загальний результат[7][8].
3.7 Згорткові нейронні мережі.
Найкращі результати в області аналізу зображень показала Convolutional Neural Network або згорткова нейронна мережа (далі – СНР). Успіх обумовлений можливістю обліку двовимірної топології зображення, на відміну багатошарового персептрона.
СНР складається з різних видів шарів: згорткові (convolutional) шари, субдискретизуючі (subsampling, підвибірка) шари та шари «звичайної» нейронної мережі – персептрону, відповідно до малюнку 6.
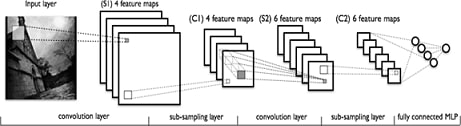
Малюнок 6 – види шарів у згортковій нейронній мережі
Перші два типи шарів (convolutional, subsampling), чергуючись між собою, формують вхідний вектор ознак для багатошарового персептрону.
Свою назву мережа згортка отримала за назвою операції – згортка, суть якої буде описана далі.
Визначення топології мережі орієнтується на вирішуване завдання, дані з наукових статей та власний експериментальний досвід.
Можна виділити такі етапи, що впливають на вибір топології:
• визначити задачу, що вирішується нейромережею (класифікація, прогнозування, модифікація);
• визначити обмеження у розв'язуваній задачі (швидкість, точність відповіді);
• визначити вхідні (тип: зображення, звук, розмір: 100x100, 30x30, формат: RGB, в градаціях сірого) та вихідні дані (кількість класів).
Вхідний шар є двомірним масивом. Згортковий шар являє собою набір карт (інша назва - карти ознак, в побуті це звичайні матриці), у кожної карти є синаптичне ядро (у різних джерелах його називають по-різному: ядро, що сканує, або фільтр).
Кількість карток визначається вимогами до завдання, якщо взяти велику кількість карток, то підвищиться якість розпізнавання, але збільшиться обчислювальна складність.
Ядро являє собою фільтр або вікно, яке ковзає по всій області попередньої карти і знаходить певні ознаки об'єктів. Ядро являє собою систему ваг або синапсів, що розділяються, це одна з головних особливостей згорткової нейромережі.
Спочатку значення кожної картки згорткового шару дорівнюють 0. Значення ваг ядер задаються випадковим чином в області від -0.5 до 0.5. Ядро ковзає по попередній карті і здійснює операцію згортка, яка часто використовується для обробки зображень, формула:
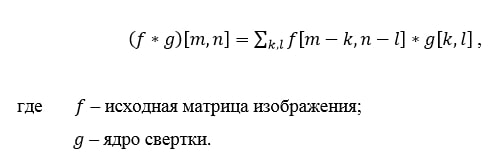
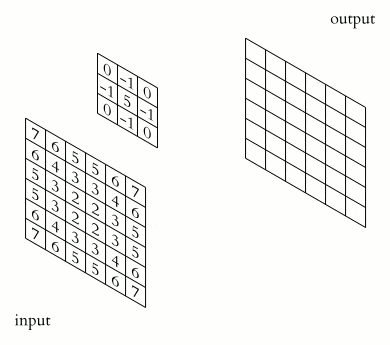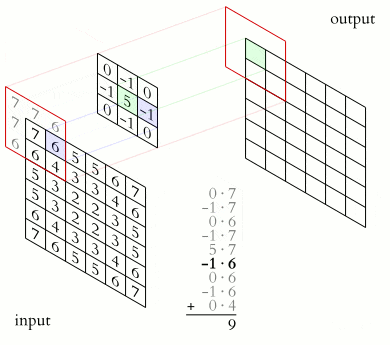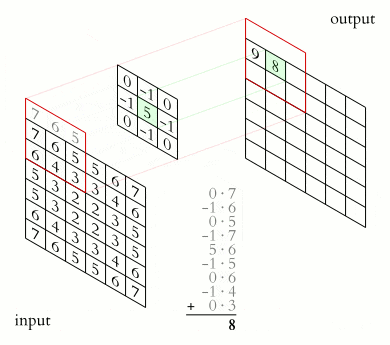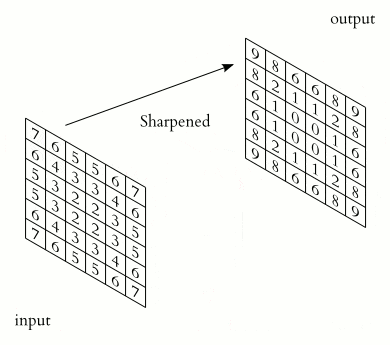
Принцип роботи операції згортка
Підвибірковий шар також, як і згортковий має карти, але їх кількість збігається з попереднім (згортковим) шаром, їх 6. Мета шару – зменшення розмірності карток попереднього шару. Якщо на попередній операції згортки вже було виявлено деякі ознаки, то для подальшої обробки настільки докладне зображення вже не потрібне, і воно ущільнюється до менш детального. Зазвичай кожна карта має ядро розміром 2x2, що дозволяє зменшити попередні карти згорткового шару в 2 рази. Вся карта ознак поділяється на комірки 2х2 елементи, з яких вибираються максимальні за значенням.
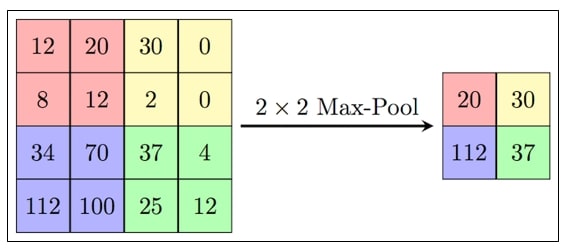
Малюнок 7 — Формування нової карти підвиборного шару на основі попередньої картки згорткового шару. Операція підвиборки (Max Pooling)
Останній з типів шарів - це шар звичайного багатошарового персептрона. Мета шару – класифікація, моделює складну нелінійну функцію, оптимізуючи яку, покращується якість розпізнавання [9].
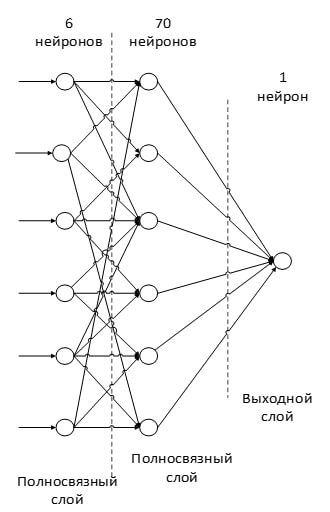
Малюнок 8 – приклад повнозв'язного шару в згортковій нейромережі
4. Огляд досліджень та розробок
4.1 Lalal.ai
LALAL.AI — це онлайн-сервіс із розділення доріжок будь-якого аудіоформату на вокал та музику. LALAL.AI аналізує трек і намагається витягти з нього інформацію про окремих інструментах та партіях.
База даних LALAL.AI налічує 20 Тбайт студійних звукозаписів високої якості, що використовуються для тренування штучного інтелекту. Це дозволяє сервісу справлятися з роботою, роблячи мінімум помилок.
4.2 Аудіоредактори
Поділ музики та голосу також підтримуються багатьма аудіоредакторами різного ступеня якості. До найпопулярніших відносяться:
• Audacity.
• Magix sound forge pro.
• FL Studio.
5. Огляд інструментів розробки.
5.1 TensorFlow та фреймворк Keras
Написаний мовою C++ командою Google у 2015 році TensorFlow є одним із найпопулярніших фреймворків Deep Learning. Сьогодні йтиметься про інтерфейс, який надає TensorFlow для Python: різниця між Tensorflow 1 і TensorFlow 2, вбудований фреймворком Keras, побудова моделей та візуалізація з TensorBoard.
Насамперед необхідно провести кордон між версіями TensorFlow 1.x та TensorFlow 2.x. Вони мають разючі відмінності. Фреймворк оперує статичними обчислювальними графами, а це означає, що вони виконуються лише у момент компіляції.
5.1.1 Модуль Keras у TensorFlow 2
Фреймворк глибокого навчання Keras перекочував у TensoFlow 2, і тепер його функціонал зберігається у модулі tf.keras. Цей модуль містить інструменти для побудови моделі, такі як:
• Шари (layers), включаючи повнозв'язковий (Dense), згортковий (Conv1D), рекурентний (RNN, LSTM). Усього налічується 105 шарів;
• Функції активації (activations), включаючи Softmax, ReLU, Sigmoid. Деякі функції активації, наприклад, PReLU, доступні у вигляді шарів. Усього їх 15;
• Функції втрат, включаючи Binary Crossentropy, MAE, MSE. Усього їх 25;
• Метрики (metrics), наприклад, MAE, MSE, Cosine Similarity. Всього 43 у вигляді класів та 25 у вигляді функцій;
• Оптимізатори (optimizers), включаючи SGD, Adam, Adagrad. Усього їх 9;
• Зворотні дзвінки (callbacks), включаючи RemoteMonitor для передачі подій на сервер, History для відстеження історії подій моделі, EarlyStopping для Зупинка моделі у разі відсутності поліпшень, TensorBoard для активації режиму візуалізації. Усього їх 14.
5.1.2 TensorBoard
TensorFlow має власний інструмент для візуалізації - TensorBoard. За допомогою TensorBoard можна:
• стежити за процесом зміни точності (accuracy) та втрат (loss) у реальному часі;
• візуалізувати граф моделі з шарами та операціями;
• показати параметри моделі (ваги, змішування) або інші тензори, які змінюються з часом;
• вивести зображення, відео або аудіо;
• та багато іншого
5.2. PyTorch
PyTorch, розроблений командою Facebook у 2017 році фреймворк Deep Learning, створений насамперед для Python.
На відміну від TensorFlow, фреймворк PyTorch не нав'язує розробнику свій інтерфейс. Можна самим створювати свої шари, функції активації та інші необхідні об'єкти у вигляді звичайних класів та функцій Python. Операції над тензорами можуть виконуватись на GPU.
PyTorch використовує автоматичне диференціювання для обчислень градієнтів, які використовуються в алгоритмі зворотного розповсюдження помилки (backpropogation). Перевагою такого підходу є швидкість обчислення.
PyTorch не тільки дозволяє працювати з тензорами, а й надає низку можливостей для глибокого навчання (Deep Learning). У PyTorch є чотири основні компоненти, необхідні для побудови моделей:
• nn використовується створення обчислювальних графів, які формують шари нейронних мереж (neural net). Аналогічну функцію у TensorFlow виконує модуль Keras.
• optim містить різні алгоритми оптимізації (SGD, Adam тощо). Аналог у TensorFlow – модуль optimizers.
• Dataset — інтерфейс для представлення вхідних та вихідних даних у різних форматах, наприклад, у вигляді тензорів (TensorDataset), iterable (IterableDataset) і т.д. У TensorFlow також є клас Dataset.
• DataLoader перетворює Dataset в формат, що маніпулюється, за допомогою якого можна контролювати розмір пакета (batch size), перемішувати дані, розподіляти процеси тощо. У TensorFlow за це відповідає модуль data.
Для створення шарів, наприклад, згорткових (convolutional), повнозв'язкових (fully-conected), рекурентних (recurrent), можна скористатися модулем torch.nn, а алгоритмів оптимізації — torch.optim. Однак інтерфейс побудови та навчання моделі не такий високорівневий у порівнянні з TensorFlow, тому доведеться писати додатковий код на Python.
5.3. ApacheMxnet
Apache MXNet – відкритий фреймворк для глибокого навчання, який використовується для створення, навчання та розгортання глибоких нейронних мереж. MXNet абстрагує складнощі, пов'язані з реалізацією нейронних мереж, має високу продуктивність і масштабованість, а також пропонує API для популярних мов програмування, таких як Python, C++, Clojure, Java, Julia, R, Scala та інші.
MXNet включает интерфейс Gluon, позволяющий разработчикам любой квалификации начать работу с технологиями глубокого обучения в облаке, на периферийных устройствах и в мобильных приложениях. С помощью всего нескольких строк кода Gluon можно создавать линейные регрессии, сверточные сети и рекуррентные сети с долгой краткосрочной памятью (LSTM) для обнаружения объектов, распознавания речи, выдачи рекомендаций и индивидуальной настройки.
Преимущества:
• Простота использования с интерфейсом gluon. Библиотека Gluon MXNet предоставляет высокоуровневый интерфейс, который позволяет легко создавать прототипы, обучать и развертывать модели глубокого обучения без ущерба для скорости обучения. Gluon предлагает высокоуровневые абстракции для предопределенных слоев, функции потерь и оптимизаторы. Он также обеспечивает гибкую структуру, которая интуитивно понятна в работе и легко отлаживается.
• Улучшенная произовдительность. Рабочие нагрузки глубокого обучения могут быть распределены между несколькими графическими процессорами практически с линейной масштабируемостью, а это означает, что даже с очень большими проектами можно справиться за меньшее время. Масштабирование выполняется автоматически в зависимости от количества графических процессоров в кластере. Разработчики также экономят время и повышают производительность за счет получения логических выводов на базе бессерверных и пакетных вычислений.
• Для IoT и периферийных устройств. В дополнение к обучению с использованием нескольких графических процессоров и развертыванию сложных моделей в облаке MXNet создает упрощенные представления нейронных сетевых моделей, которые могут работать на маломощных периферийных устройствах, таких как Raspberry Pi, смартфон или ноутбук, и удаленно обрабатывать данные в режиме реального времени.
• Гибкость и возможности выбора. MXNet поддерживает широкий спектр языков программирования, включая C++, JavaScript, Python, R, Matlab, Julia, Scala, Clojure и Perl, что позволяет начать работу, используя уже знакомые языки. Однако для обеспечения максимальной производительности на стороне сервера весь код компилируется на C++, независимо от того, какой язык используется при создании моделей.
Выбор пал на PyTorch по причине большей работы с оптимизацией и большей гибкостью в работе, тем не менее, TensorFlow также является удобным инструментом для разработки[10].
Список джерел
- Виділення вокалу з музики за допомогою згорткових нейромереж[Електронний ресурс]. – Режим доступу: https://habr.com/ua/post/441090.
- Open Source Tools & Data for Music Source Separation[Електронний ресурс]. – Режим доступу: https://source-separation.github.io/tutorial/landing.html.
- Що таке нейронна мережа[Електронний ресурс]. – Режим доступу: https://aws.amazon.com/ru/what-is/neural-network.
- Що таке нейронні мережі, і що вони можуть[Електронний ресурс]. – Режим доступу: https://neural-university.ru/neural-networks-basics.
- Багатошаровий персептрон[Електронний ресурс]. – Режим доступу: https://wiki.loginom.ru/articles/multilayered-perceptron.html.
- Структура та принцип роботи повнозв'язкових нейронних мереж[Електронний ресурс]. – Режим доступу: https://proproprogs.ru/neural_network/struktura-i-princip-raboty-polnosvyaznyh-neyronnyh-setey>https://proproprogs.ru/neural_network/struktura-i-princip- raboty-polnosvyaznyh-neyronnyh-setety.
- Знайомимося з методом зворотного розповсюдження помилки[Електронний ресурс]. – Режим доступу: https://habr.com/ua/company/otus/blog/483466.
- Метод зворотного поширення помилки: математика, приклади, код[Електронний ресурс]. – Режим доступу: https://neurohive.io/ru/osnovy-data-science/obratnoe-rasprostranenie.
- Згорткові нейронні мережі[Електронний ресурс]. – Режим доступу: https://neerc.ifmo.ru/wiki/index.php?title=%D0%A1%D0%B2%D0% B5%D1%80%D1%82%D0%BE%D1%87%D0%BD%D1%8B%D0%B5_%D0%BD%D0%B5%D0%B9%D1%80%D0%BE% D0%BD%
D0%BD%D1%8B%D0%B5_%D1%81%D0%B5%D1%82%D0%B8. - TensorFlow vs PyTorch у 2021: порівняння фреймворків глибокого навчання[Електронний ресурс]. – Режим доступу: https://habr.com/ua/company/ua_mts/blog/565456.