
Реферат по теме выпускной работы
Содержание
- Введение
- Постановка задачи
- Методы представления текстовой информации
- Архитектуры нейронных сетей для классификации текстов
- Обучение и оценка моделей
- Проблемы и ограничения
- Заключение
- Список источников
Введение
Классификация текстов — важная и сложная задача в области обработки естественного языка (NLP), с широким спектром применений. Она используется для фильтрации спама, анализа тональности, подбора контекстной рекламы, автоматизации переводов и многого другого. Решение задачи классификации требует алгоритмов, способных эффективно обрабатывать большие объемы данных, учитывать их неоднородность, сложные связи и особенности естественного языка, а также работать с приемлемыми затратами времени и вычислительных ресурсов. В последние годы значительное внимание уделяется применению нейронных сетей для классификации текстов, хотя сами искусственные нейронные сети (ИНС) начали развиваться ещё в 1970-х годах. При корректной настройке и обучении ИНС демонстрируют высокую точность и производительность в решении сложных, нечетко определённых задач, к которым относится и задача классификации текстов. Такие сети могут анализировать сложные паттерны и извлекать смысл даже из очень обширных текстовых массивов. С развитием Интернета объёмы доступной информации достигли таких масштабов, что ручная обработка стала невозможной. Компании и организации, работающие с большими данными, стремятся максимально автоматизировать анализ текстовой информации. Они используют нейронные сети не только для классификации, но и для задач прогнозирования, принятия решений, выявления трендов и закономерностей в данных. Такие подходы помогают повышать качество решений и лучше адаптироваться к новым требованиям и изменениям в информационной среде [1].
Постановка задачи
В общем смысле задачу классификации можно формализовать следующим образом: классификация текста представляет собой процесс присвоения некоторому текстовому фрагменту конкретного (одного или нескольких) заранее определенного классов. Классификация может быть решена в формате «один текст – один класс» или в формате «один текст – несколько классов». Основной этап и главная сложность алгоритма – разбиение текста на фрагменты (лексемы, токены) и поиск связей между ними[2]. Непосредственно для решения задачи классификации текстовой информации чаще всего используют рекуррентные (RNN), сверточные (CNN) сети и трансфомеры. Эти модели способны улавливать контекст всего текста, распознавать отдельные слова и их связи между собой, что, в свою очередь, гарантирует высокую точность «понимания» текста и построения правильного прогноза или ответа. Среди прочих сильнее всего отличились модели BERT и GPT, которые совершили переворот в сфере распознавания текстов и генерации ответов благодаря обучению на больших объемах данных и усовершенствованным алгоритмам обработки контекста[3-4]. Решение каждой задачи классификации можно разделить на следующие этапы, которые необходимо рассмотреть подробнее:
- Сбор и анализ пригодности данных для предварительного обучения модели.
- Обработка текста и преобразование в числовое представление для понимания моделью.
- Построение модели, обучение на исходном корпусе текстов, получение первых прогнозов и классификаций.
- Сбор статистики запросов, проверка на тестовой выборке данных, измерение качества построенной модели и точности ее прогнозов.
Методы представления текстовой информации
В качестве первого этапа для построения качественной модели необходимо подобрать достаточно объемные корпуса исходных текстов, чтобы на основании обучающей выборки обучать модель. В современном мире большую сложность составляет формализация текста, чем его поиск. Рассмотрим подробнее различные методы представления текстов. К классическим можно отнести Bag of Words (BoW). Данный метод предполагает разделение текста на неупорядоченный набор слов, каждому из которых ставится индекс из заранее сформированного словаря, а затем строится вектор, каждое значение которого обозначает частоту встречаемости каждого слова в тексте. Метод Term Frequency – Inverse Document Frequency (TF-IDF) является логическим продолжением и закономерным развитием метода BoW и учитывает важность отдельных слов в документах. При данном подходе уменьшается вес (значение в тексте) слишком часто встречающихся слов (союзов, предлогов, частиц, артиклей, прочих малополезных фрагментов текста), за счет чего увеличивается относительный вес более важных лексем и терминов. Также подход учитывает частоту и важность отдельных слов в выбранном документе, и их встречаемость среди всех других документов. К современным методам можно отнести GloVe (Global Vectors for Word Representation), который создает связанные векторы для слов на основании статистики словосочетаний во всех текстах одновременно, что позволяет улавливать глобальные закономерности в контексте и языке в целом. Word2Vec сам является продуктом нейросетевых технологий, он также располагает слова в некотором многомерном пространстве, где похожие по смыслу слова находятся ближе друг к другу. Этот подход сложнее, но дает большую производительность и точность, чем классические подходы. Также можно выделить FastText, который является улучшенной версией Word2Vec, и обрабатывает не слова и лексемы, а N-граммы, то есть фрагменты слов по N символов, что позволяет учитывать редкие слова и словоформы при анализе исходного текста[5-6].
Архитектуры нейронных сетей для классификации текстов:
После разделения исходного текста на лексемы и токены, его можно передавать непосредственно в нейронную сеть для обучения и прогнозирования. Для этого используют одну из множества архитектур[6-7]. Рассмотрим некоторые из них подробнее. Многослойные перцептроны (MLP) представляют собой несколько полносвязных слоев нейронов, каждая связь между которыми имеет некоторые веса. MLP не учитывает порядок слов в тексте и контекст, поэтому может решать только относительно простые задачи распознавания и не может быть использован для больших и сложных задач. На рисунке 1 представлена общая схема многослойного перцептрона с двумя скрытыми слоями.
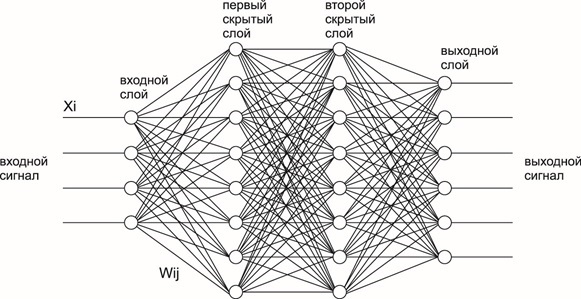
Рисунок 1. Архитектура многослойного перцептрона.
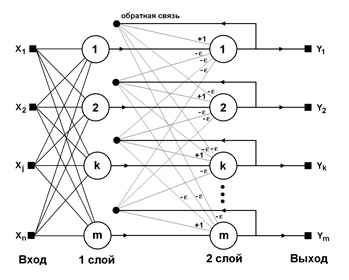
Рисунок 2. Архитектура рекуррентной нейронной сети.
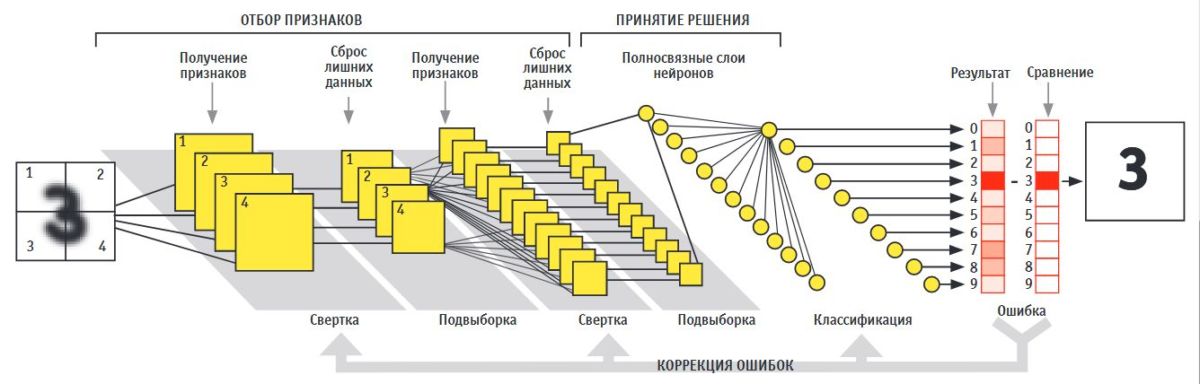
Рисунок 3 – Схема работы сверточной нейронной сети.
Обучение и оценка моделей
После выбора и обучения модели необходимо проверить качество её работы. Для оценки нейронных сетей могут быть использованы различные метрики, рассмотрим наиболее применимые из них. Доля правильных ответов (Accuracy) — процент правильно классифицированных текстов из всего корпуса текстов. Эта метрика проста и популярна, но может оказаться малоинформативной при наличии несбалансированных классов (текстов одного класса значительно больше, чем другого). Точность (Precision) — доля правильно классифицированных текстов в рамках одного класса среди всех текстов, отнесенных моделью к этому классу. Точность показывает, насколько хорошо модель идентифицирует конкретный класс, и помогает понять, насколько часто модель ошибочно относит тексты к этому классу. Для комплексной оценки стоит рассчитывать Precision для каждого класса, чтобы выявить, в каких классах чаще всего возникают ошибки. Полнота (Recall) — доля правильно классифицированных объектов из всех объектов, принадлежащих данному классу в тестовой выборке. Полнота отражает способность модели корректно находить все объекты конкретного класса и полезна для оценки полноты охвата каждого класса. F1-мера (F1 Score) — гармоническое среднее между Precision и Recall. Эта метрика особенно важна при неравномерном распределении классов, так как учитывает как точность, так и полноту, указывая на общий баланс между этими показателями.
Проблемы и ограничения
Даже при тщательном и правильном подборе параметров и удовлетворительных значениях всех метрик работа с нейронными сетями может вызывать некоторые сложности. К основной проблеме при разработке, обучении и внедрении нейронных сетей можно отнести высокие аппаратные требования: современные трансформеры требуют огромных вычислительных мощностей, для ускорения работы нередко используют целые кластеры графических процессоров. Помимо сложностей при обработке, исходные данные для обучения и проверки необходимо где-то хранить, и чем больше и сложнее нейросеть, тем больше данных для обучения и параметров самой сети необходимо хранить и в постоянной памяти в периоды неактивности сети, и в оперативной, когда алгоритм производит вычисления. Большие системы BERT и GPT могут требовать десятков гигабайт оперативной памяти. И все так же остро стоит проблема сходимости: текстовая информация в любом виде очень неоднородная, что может вызывать ошибки в прогнозировании, зацикливание на локальных минимумах или большие задержки в работе.
Нейронные сети глубокого обучения уже могут правильно решать множество задач, в том числе и задачу классификации, но чем сложнее алгоритм обучения и прогнозирования, тем сложнее понять весь процесс построения прогноза. В общем случае у больших нейронных сетей замечаются явные проблемы из-за ограниченной интерпретируемости. Чем больше слоев, нейронов и параметров модели, тем сложнее объяснить, почему нейросеть приняла то или иное решение. Чаще всего отдельные значения параметров ничего не говорят, важны только их сочетания, которые не всегда могут быть очевидны разработчику или пользователю. Отсюда могут возникать проблемы недоверия к результату прогнозирования. Редкие ошибки на важных проверках могут ставить под вопрос всю работу модели, что может потребовать от простого переобучения до полной переработки архитектуры нейронной сети. Для повышения «понятности» работы нейронных сетей начата разработка специальных алгоритмов, таких как Local Interpretable Model-agnostic Explanations (LIME) и SHapley Additive exPlanations (SHAP), но и они не могут объяснить всех деталей. Разработка подобных алгоритмов – задача, возможно, даже более сложная, чем разработка самой нейросети.
Последней проблемой при обучении большой и качественной нейросети, уже не связанной с процессом разработки, можно считать подбор данных для обучения. Большие корпуса текста легко найти, но их необходимо правильно разметить, «указать» алгоритму более важные вещи и отсеять наименее полезную информацию. Для разметки узкоспециализированных данных (юридических, медицинских и других, где необходима высокая квалификация) необходимо привлекать профильных специалистов, что увеличивает время и стоимость итогового продукта. Также может оказаться, что для каких-то отраслей большие объемы текстовой информации ограничены или вовсе отсутствуют, что еще больше усложняет процесс обучения модели. Для работы со слаборазмеченными данными могут быть применены специальные алгоритмы, такие как semi-supervised learning, self-supervised learning и transfer learning, но их реализация и настройка также требует значительного времени.
Заключение
Классификация текстов является одной из ключевых задач обработки естественного языка. Нейронные сети позволили сделать большой скачок в решении подобных задач, но все алгоритмы неидеальны и должны быть усовершенствованы в будущем. К особо перспективным направлениям можно отнести развитие архитектур трансформеров как передовых систем распознавания и генерации текста, их оптимизация и ускорение. Немаловажным фактором развития нейронных сетей можно выделить упрощение процесса обучения: ускорение, необходимость в меньшем и/или меньше размеченном наборе входных данных для обучения. Это позволит быстрее разворачивать более компактные системы без больших затрат на обучение и донастройку. Также у меньших моделей, но не менее эффективных и производительных, следует повышать интерпретируемость: проще будет понимать ход вычислений, если параметров будет меньше. Задача классификации текста – не единственная задача, часто решаемая нейронными сетями. Различные нейросети можно комбинировать между собой, создавая новые более сложные архитектуры. Новые модели уже умеют обрабатывать текстовую информацию вместе с изображениями, голосовыми командами, анализировать математические формулы и решать математические задачи. Это позволит автоматизировать анализ еще больших объемов данных, не опираясь только на текстовую информацию, что значительно улучшит взаимодействие между человеком и машиной. Даже сейчас особенно популярны различные голосовые помощники и чат-боты. С непрерывной интеграцией с различными сервисами их потенциал трудно себе даже представить.
Список источников
- Фаустова К.И. Нейронные сети: применение сегодня и развитие завтра // Территория науки. - 2017 - №4.
- Каллан Р. Основные концепции нейронных сетей: Пер. с агл. А.Г.Сивака— М.: Вильямс, 2001. — 287 с.
- Хайкин Саймон. Нейронные сети: Полный курс: Пер. с англ.— М.: Вильямс, 2008. — 1103 с.
- Гудфеллоу Я., Бенджио И., Курвилль А. Глубокое обучение / Я. Гудфеллоу, И. Бенджио, А. Курвиль. Пер. с анг. А. А. Слинкина. – 2-е изд., испр. – М.: ДМК Пресс, 2018. – 652 с.: цв. ил.
- Эмбеддинги для начинающих. https://habr.com/ru/companies/otus/articles/787116/. Сайт: электр. Информ. – Режим доступа https://habr.com/ - Загл. С экрана.
- Обзор четырех популярных NLP-моделей. https://proglib.io/p/obzor-chetyreh-populyarnyh-nlp-modeley-2020-04-21. Сайт: электр. Информ. – Режим доступа https://proglib.io - Загл. С экрана.
- 7 архитектур нейронных сетей для решения задач NLP https://ai-news.ru/2018/10/7_arhitektur_nejronnyh_setej_dlya_resheniya_zadach_nlp.html. Сайт: Электр. информ. – Режим доступа: https://ai-news.ru/ - Загл. с экрана.
- Введение в архитектуру нейронных сетей https://habr.com/ru/company/oleg-bunin/blog/340184/. Сайт: Электр. информ. – Режим доступа: https://habr.com/ - Загл. с экрана.
- Как устроена нейросеть BERT от Google https://sysblok.ru/knowhow/kak-ustroena-nejroset-bert-ot-google/. Сайт: Электр. информ. – Режим доступа: https://sysblok.ru / - Загл. с экрана.
- Что такое GPT: раскрываем тайны трансформеров https://proglib.io/p/chto-takoe-gpt-raskryvaem-tayny-transformerov-2024-04-11. Сайт: Электр. информ. – Режим доступа: https://proglib.io / - Загл. с экрана.
- Построение и обучение нейронной сети для решения задачи прогнозирования погоды при помощи программы Neuroph Studio https://kit-e.ru/neuroph-studio/. Сайт: Электр. информ. – Режим доступа: https://kit-e.ru - Загл. с экрана.
- Нейронные сети https://llbeagle.wordpress.com/tag/%D0%BD%D0%B5%D0%B9%D1%80%D0%BE%D0%B1%D0%B8%D0%BE%D0%BD%D0%B8%D0%BA%D0%B0/. Сайт: Электр. информ. – Режим доступа: https://llbeagle.wordpress.com - Загл. с экрана.
- Квантовая революция: какими будут компьютеры будущего https://ichip.ru/tekhnologii/kvantovaya-revolyuciya-kakimi-budut-kompyutery-budushhego-204782. Сайт: Электр. информ. – Режим доступа: https://ichip.ru - Загл. с экрана.