| [Биография] | | | [Автореферат] | | | [Индивидуальное задание] | | | [Библиотека] | | | [Ссылки] | | | [Поиск по теме] |
Тема: |
"Разработка базы данных для проблемно ориентированной среды для сетевого объекта с распределенными параметрами" |
Руководитель: |
профессор Святный Владимир Андреевич |
Консультант: |
Молдованова О.В. |
В настоящее время технология баз данных используется во многих программных приложениях, которые связаны с тем или другим видом обработки информации. Это могут быть сложные (или не очень) вычисления, автоматизация разных производственных процессов, решения повседневных задач или интеграция разных областей деятельности с помощью глобальных сетей. Некоторые из этих программных продуктов, предназначенные для одного пользователя с одним компьютером, другие используются рабочими группами в количества 20-30 человек через локальную сеть, третьи служат сотням пользователей и содержат огромное количество байт. В последнее время технология баз данных используется в объединении с интернет-технологией для поддержки мультимедийных программных приложений в открытых и закрытых сетях. Базы данных позволяют упростить и автоматизировать некоторые повседневные операции, увеличивают безопасность хранения, ускоряет поиск нужных данных.
Моделирования динамических систем реальной сложности с распределенными параметрами (ДСРП) и модельная поддержка их создания является актуальной проблемой для всех областей техники и технологии. Реальные ДС предъявляют такие требования к системам моделирования, которым удовлетворяют параллельные вычислительные системы. Архитектура параллельных вычислительных систем развивается значительно быстрее техники параллельного программирования и моделирования. Поэтому важной задачей моделирования есть разработка проблемно ориентированной параллельной моделирующей среды (ПОПМС) для динамических сетевых объектов с распределенными параметрами. В качестве динамического объекта с распределенными параметрами рассматривается шахтная вентиляционная сеть (ШВС). Проблемная ориентация среды заключается в дружественном для пользователя описании объекта моделирования и решаемых задач, в специфическом представлении результатов моделирования, а также в создании общего интерфейса пользователя. Одной из важных составных частей проблемной ориентации является также база данных (БД) моделей и их параметров. Представления данных, которые используются при моделировании сетевых объектов, в виде базы данных облегчает работу пользователя с ними и оберегает данные от несанкционированного изменения или удаления. Разрабатываемая ПОПМС ориентирована на работу в глобальной сети Интернет, поэтому разработка базы данных приобретает некоторые специфичные для Интернета особенности.
При создании базы данных ПОПМС для предприятий угледобывающей промышленности, впрочем, как и при создании информационных систем для любой другой отрасли промышленности, успех во многом зависит от правильного выбора системы управления базами данных (СУБД) – платформы любой информационной системы, разработки эффективной структуры базы данных и создания интерфейса пользователя. Решению этих задач и посвящена данная работа.
Работа относится к проблематике кафедры ЭВМ Донецкого национального технического университета (ДонНТУ), решаемой в рамках государственной программы разработки конкурентно способных средств моделирования сложных систем и договоров о научном сотрудничестве со Штутгартским университетом по разработке параллельной моделирующей среды.
Целью данной работы является разработка, отладка и экспериментальные исследования базы данных для параллельной моделирующей среды, ориентированной на решение задач моделирования шахтных вентиляционных сетей (ШВС) для сети Интернет, рассматриваемых как динамические объекты с распределенными параметрами.
Для достижения этой цели в работе решаются следующие задачи:
1. Характеристика шахтных вентиляционных сетей как объектов моделирования.
2. Рассмотрение современных типов систем управления базами данных, выбор СУБД на основе требований сетевых объектов с распределенными параметрами к ПОПМС.
3. Разработка структуры базы данных для ПОПМС.
4. Разработка интерфейса пользователя базы данных для ПОПМС.
5. Имплементация и экспериментальные исследования базы данных для ПОПМС для сетевого объекта с распределенными параметрами.
В процессе создания базы данных для ПОПМС использовались унифицированный язык моделирования (UML), СУБД MySQL и структурированный язык запросов (SQL), методика разработки графического интерфейса пользователя базы данных, экспериментальная проверка программы на тестовых ШВС
Практическая ценность работы заключается в разработке:
1. Работоспособной базы данных ПОПМС, позволяющей решать практические задачи моделирования ШВС (проектные, эксплуатационные, задачи автоматизации управления);
2. Интерфейса пользователя базы данных, который может применяться в угольной промышленности и в учебном процессе.
Вентиляционные сети играют важную роль для решения задач безопасности в шахтах, где они обеспечивают распределение воздуха между объектами проветривания. ШВС включает объекты проветривания, выработки, которые подают и отводят воздух, вентиляционные сооружения и источники тяги – вентиляторы главного проветривания, которые устанавливаются на поверхности, и подземные вспомогательные вентиляторы местного проветривания. Объектами проветривания являются очистные и подготовительные забои, а также горные выроботки, в которых правилами безопасности регламентируется значения затрат воздух и концентрации вредных примесей. Выработки, которые подают и отводят воздух, – это стволы, штреки, поклоны, шурфы, по которым попадают свежие струи воздуха к объектам проветривания и отводятся на поверхность исходные струи с вредными примесями. Объекты проветривания, выработки, которые подают и отводят воздух, создают шахтную вентиляционную сеть.
Рассматривая сети как объекты управления можно выделить следующие их особенности: сложность топологии как по числу ветвей, так и по характеру их соединения; взаимная связь между расходом воздуха в разных ветвях, которая вызовет возмущение по расходам воздуха во всех ветвях при управлении некоторой і-ой схемой проветривания участка; изменяемость топологии и аэродинамических параметров ветвей сети при проведении горных работ; наличие диагональных выработок и путей истока воздух, которые могут вызвать неустойчивые режимы проветривания; размещения регулирующих органов, учитывая задаче стойкости вентиляционных потоков и минимизации истоков, которые обеспечивают изменение затрат воздуха в соответствии с задачами управления проветриванием; наличие иерархии регулирующих органов; необходимость в изменении размещения регуляторов по мере развития горных работ; наличие в сети шлюзов из регулюємим аэродинамическим сопротивлением, обеспечивающих стойкость вентиляционных струй и отсутствие резких изменения газовой обстановки при прохождении транспорта; наличие забоев подготовительных выработок, которые проветриваются с помощью вспомогательных вентиляторов; значительная протяжность выработок, которые составляют ШВС, разряженность источников метановыделения и путей истока воздух по длине выработки; влияние естественной тяги на воздухораспределение в зависимости от точек влияния на воздушные потоки; необходимость обеспечения ШВС правилами безопасности воздухораспределения в нормальных и аварийных режимах работы шахты [1].
Целью изучения динамических свойств ШВС как объектов управления является получения системы дифференциальных уравнений, которые описывают динамику изменений вектора затрат воздуха во всех ветвях с учетом всех приведенных особенностей сетей как многосвязных объектов с иерархическим расположением регулирующих органов. Эту задачу будет решать проблемно ориентированная параллельная моделирующая среда для СОРП. В данной работе будет разрабатываться база данных, которая описывает структуру и параметры для введенной пользователем ШВС. При этом работа с базой данных от пользователя будет скрыта, т.е для пользователя не предусматривается интерфейс для работы с базой данных непосредственно. Заносить информацию в базу данных будет сама моделирующая среда. На основании данных о топологии и параметрах ШВС система моделирования будет осуществять моделирование введенной пользователем ШВС, после чего результаты моделирования заносятся в базу данных и происходит их визуализация.
Сложность сетей и их систем управления как объектов моделирования, многочисленные постановки задач при исследовании и проектировании таких систем с помощью вычислительных машин определяют следующие требования к математическим моделям. Модели должны отражать процессы в сетях с реальной сложностью. Большие размерности сетей, где число ветвей больше 200 и число узлов больше 50, вызывают значительные трудности и возможные ошибки при их формальном описании дифференциальными уравнениями. Поэтому при составлении модели с использованием ЭВМ необходимо иметь минимум информации по структуре и параметрам объекта. Сетевые модели должны решать задачи реального времени для связи с реальными компонентами систем управления. При этом необходимо исследовать все этапы их разработки (моделирование алгоритмов и структур, вплоть до обучения пользовательского персонала).
Характер процессов в отдельных выработках в значительной степени определяется топологией вентиляционных схем, то есть их местонахождением в ШВС по отношению к вентиляторам, источникам аэродинамических нарушений и управляющих воздействий, источникам метановыделення. Топология СДОРП задается ориентированным графом G(U, V) с множеством узлов |U| = n и ветвей |V| = m. Граф кодируется следующей таблицей:
| AKJ | EKK | QI | PAR(PI1,PI2,...,PIs) | AEI | VECOMI |
где AKJ и EKK – соответственно номер начального и конечного узла ветви, при этом J, Kє(1, 2, …, n); QI – идентификатор ветви графа, при этом Q – расход воздуха, I – номер ветви и Iє (1, 2, …, m); PAR – физические параметры ветвей графа (удельное аэродинамическое сопротивление, длина ветви, площадь поперечного сечения и др.), задаваемые каждый в своей колонке таблицы; AEI – активный элемент (вентилятор, генератор, компрессор и др. – в зависимости от физической природы сетевого объекта) в I-й ветви; VECOMI – вербальный комментарий, объясняющий технологическое назначение ветви I. Аэродинамические процессы вызываются w <= m вентиляторами и характеризуются вектором расходов Q = (Q1, Q2, …, Qm)T и давлений P = (P1, P2, …, Pm)T в ветвях.
В j-ой ветви, рассматриваемой как объект с распределенными параметрами, процессы изменения расхода Qj и давления Pj описываются системой уравнений:
|
|
где rj – удельное аэродинамическое сопротивление воздуховода, p – плотность воздуха, Fj – площадь сечения воздуховода, а – скорость звука в воздухе, RRj – регулируемое сопротивление,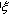 – пространственная координата, отсчитываемая вдоль оси воздуховода в пределах его длины lj, т.е. 0 <= <= lj.
– пространственная координата, отсчитываемая вдоль оси воздуховода в пределах его длины lj, т.е. 0 <= <= lj.
Граничными условиями для (1) являются давления в начальном и конечном узлах ветви
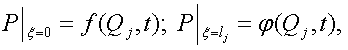
|
которые в общем случае зависят от расходов.
Для моделирования сетевого динамического объекта (СДО) необходимо произвести его формальное описание, которое включает:
- таблицу кодирования (таблица 1) и топологические характеристики, которые могут быть получены из нее и использованы в уравнениях;
- m пар уравнений типа (1), записанных для каждой ветви СДО
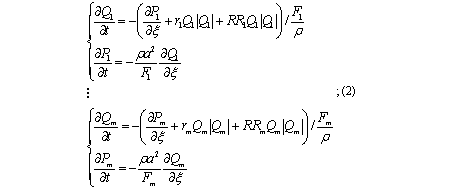
|
- n узловых граничных условий – давлений в узлах, являющихся некоторыми функциями fk расходов Qu, инцидентных узлам и обеспечивающих смыкание решений
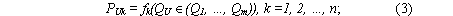
|
- w характеристик вентиляторов (или других активных элементов), работающих на сеть
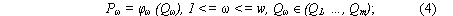
|
- w0 открытых выходов в атмосферу, где давления принимаются постоянными и равными атмосферному давлению
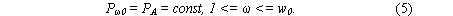
|
Аппроксимируя уравнения (1) по методу прямых, получим для k-го элемента Qj ветви длиной 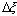 уравнения:
уравнения:
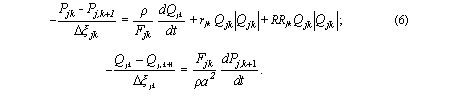
|
Граничные условия для уравнений воздушных потоков в ветвях делятся на внешние и внутренние. К внешним относятся давления в начальных узлах, чьи ветви соединены с атмосферой, и давления в узлах, к которым подключены вентиляторы. Внутренние граничные условия – это давления в узлах сети, которые должны быть вычислены при решении системы уравнений.
Внутренние граничные условия определяются в соответствии со следующим уравнением:
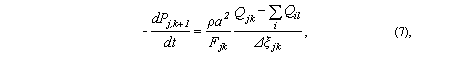
|
где 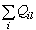 – алгебраическая сумма расходов в элементах ветвей, инцидентных граничному узлу, i – номер ветви, l =
– алгебраическая сумма расходов в элементах ветвей, инцидентных граничному узлу, i – номер ветви, l = 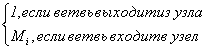 , Mi – число элементов i-ой ветви.
, Mi – число элементов i-ой ветви.
На основе уравнений (6) и (7) должна генерироваться система уравнений для всей сети, аппроксимирующая систему (2).
Последовательности действий для нахождения расхода воздуха в каждой из ветвей для динамического объекта с распределенными параметрами представлена на рис.1.
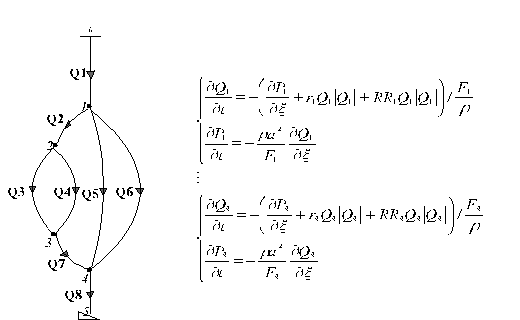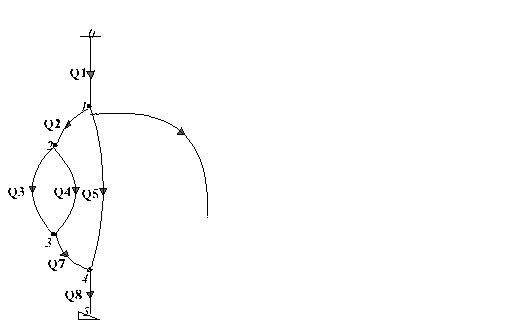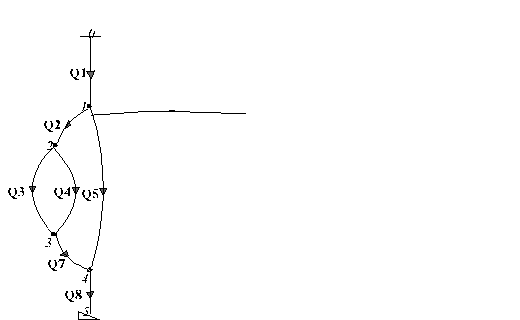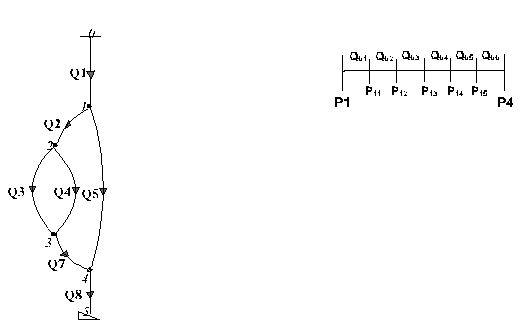
|
| Рис.1 Анимированная последовательность действий при расчете ШВС как динамического объекта с распределенными параметрами |
Выбор системы управления баз данных представляет собой сложную многопараметрическую задачу и является одним из важных этапов при разработке приложений баз данных. Выбранный программный продукт должен удовлетворять как текущим, так и будущим потребностям предприятия, при этом следует учитывать финансовые затраты на приобретение необходимого оборудования, самой системы, разработку необходимого программного обеспечения на ее основе, а также обучение персонала. Кроме того, необходимо убедиться, что новая СУБД способна принести предприятию реальные выгоды [2].
Одним из главных критериев выбора СУБД является выбор используемой модели данных. Основными видами используемыми в настоящее время моделями данных являются реляционные и объектные. Мэри Лумис, один из идеологов СУБД Versant, очень кратко и точно сформулировала актуальность объектного подхода к базам данных: "Модель данных более близка сущностям реального мира. Объекты можно сохранить и использовать непосредственно, не раскладывая их по таблицам. Типы данных определяются разработчиком и не ограничены набором предопределенных типов". Когда сложный объект заносится в реляционную базу, обязательна процедура декомпозиции его данных для их размещения в таблице. [3] В объектной технологии все сложности структур данных скрываются внутри объектов, а доступ к информации осуществляется через простой унифицированный интерфейс. Реляционная технология также предлагает простой унифицированный интерфейс, однако формат хранения данных упрощен настолько насколько это возможно, поэтому все проблемы, связанные с обработкой сложной информации, ложатся на плечи пользователей и программистов.
Так как объекты позволяют моделировать комплексные данные очень просто, объектное программирование лучше всего подходит для разработки сложных приложений. Поскольку в данной работе объекты реального мира имеет не очень сложное поведение и разрабатываемая база данных не будет содержат мультимедийного представления данных, то была выбрана реляционная модель данных.
Одним из основных преимуществ реляционного подхода к организации баз данных (БД) является то, что пользователи реляционных БД получают возможность эффективной работы в терминах простых и наглядных понятий таблиц, их строк и столбцов без потребности знания реальной организации данных во внешней памяти. Способ хранения данных, использующийся в реляционной модели минимизирует их дублирование и исключает определенные типы ошибок обработки, возникающие при других способах хранения данных. Данные хранятся в виде таблиц со столбцами. Согласно реляционной модели, не все виды таблиц одинаково приемлемы. С помощью процесса, называемого нормализацией, нежелательная таблица может быть преобразована в две или более приемлемых.
Одно из преимуществ реляционной модели состоит в том, что в столбцах содержатся данные, связывающие одну строку с другой. Это делает связи между строками видимыми для пользователя [4].
Реляционная модель данных, содержащая набор четких предписаний к базовой организации любой реляционной системы управления базами данных (СУБД), позволяет пользователям работать в ненавигационной манере, т.е. для выборки информации из БД человек должен всего лишь указать список интересующих его таблиц и те условия, которым должны удовлетворять выбираемые данные. СУБД скрывает от пользователя выполняемые ей последовательные просмотры таблиц, выполняя их наиболее эффективным образом. Очень важная особенность реляционных систем состоит в том, что результатом выполнения любого запроса к таблицам БД является также таблица, которую можно сохранить в БД и/или, по отношению к которой можно выполнять новые запросы.
По мнению разработчиков приложений, самой большой инновацией в реляционных базах данных является использование задекларированного языка запросов SQL - Structured Query Language (теперь все чаще название языка понимается как Standard Query Language). Большинство языков программирования являются процедурными. Программист указывает компьютера, что делать шаг за шагом, специфицирую процедуры. В SQL же программист говорит: «Я хочу данные, которые отвечают следующему критерию» и планировщик запросов реляционная система управления баз данных (РСУБД) изображает как взять их. Есть 2 преимущества в использовании языка запросов. Во-первых запросы больше не зависят от представления данных. Во-вторых это повышенная программная надежность [5].
Теперь перейдем к вопросу выбора конкретной РСУБД. Это достаточно сложный вопрос, так как существует много критериев выбора и много продуктов представлено на рынке. В настоящее время к наиболее популярным РСУБД можно отнести такие продукты как Oracle 7x, Informix, IBM DB-2, CA OpenIngres, Sybase SQL Server, Microsoft SQL Server, MySQL .
В качестве хранилища информации для ПОМПС, ориентированной для работы в Интернете была выбрана СУБД MySQL. Причин для такого выбора множество. Во-первых, MySQL всегда позиционировалась разработчиками как самая быстрая база (они открыто заявляли, что некоторые функции не будут реализованы, потому что отрицательно влияют на скорость обработки). Во-вторых, работа с базой довольно простая - многие конструкции стандарта SQL не поддерживаются, поэтому изучить язык запросов можно довольно быстро. И что особенно важно - MySQL очень тесно интегрирована с популярными языками программирования для разработки веб-сайтов, в первую очередь, с PHP, где поддержка ее встроена в сам язык, так что для работы с БД не требуется каких-либо дополнительных библиотек или средств. И последний аргумент в выборе базы данных для построения сайта - распространение MySQL под open-source лицензией GPL, бесплатно для некоммерческого использования.
Следует заметить, что программное обеспечение MySQL (TM) представляет собой очень быстрый многопоточный, многопользовательский, надежный SQL-сервер баз данных. Сервер MySQL предназначен как для критических по задачам производственных систем с большой нагрузкой, так и для встраивания в программное обеспечение массового распространения.
Жизненный цикл базы данных состоит из нескольких этапов. На предпроектной стадии осознания необходимости создания информационной системы находят зримую материальную форму: техническая задача на построение системы. Само построение делится на две части: создания системы «на бумаге» - назовем эту стадию проектированием и создания системы «в железе» - назовем эту стадию разработкой. Взаимная адаптация друг к другу созданной системы и среды ее «обитания» составляет стадию внедрения, за которой вытекает использования системы по назначению – стадия эксплуатации. Со временем благодаря изменениям, которые произошли в организации, система перестает справляться с возложенными на нее задачами – это служит поводом для ее модификации. Периодическая модификация будет выполняться до тех пор, пока проектные решения и технологии, заложенные в систему, не исчерпают свои возможности и не потребуется кардинальная реконструкция системы. В этом случае старая система завершит своя жизнь, передавая эстафету и наработанные данные и знания новой системе.
Стадии проектирования, разработки и, частично, стадии предпроектного анализа и внедрения составляют процесс проектирования, которой является сам по себе объектом анализа и управления. Существующая сегодня технология управления проектами (не только в сфере создания информационных систем) разрешает хорошо структурировать этот процесс, используя известные формализации и соответствующее программное обеспечение.
Далее рассматривается стадии предпроектного анализа и проектирования.
База данных – это модель пользовательской модели деловой активности. Поэтому, для того чтобы построить эффективную базу данных и ее приложения, нужно ясно представлять себе пользовательскую модель. Для этого строится модель данных, которая идентифицирует объекты, которые должны храниться в базе данных, и определяют их структуру и связи между ними. Это понимание должно быть достигнуть на ранней стадии процесса разработки путем опрашивания пользователей и составления технической задачи. Большинство таких технических задач включают использование прототипов – шаблонных баз данных и приложений, которые представляют разные аспекты создаваемой системы.
Есть две общих стратегии разработки баз данных: сверху вниз и снизу к вверху. Разработка сверху вниз идет от общего к частного. Она начинается с изучение стратегических целой организации, способов, с помощью которых эти цели могут быть достигнуты, требований к информации, которые должны быть удовлетворены для достижения этих целой, и систем, необходимых для предоставления такой информации. Результатом такого исследования есть абстрактная модель данных.
Отталкиваясь от этой общей модели, команда разработчиков движется “вниз”, к более и более подробным описаниям и моделям. Модели промежуточного уровня также постоянно детализируется, пока не преобразуються в конкретные базы данных и их приложения. В конце вся многоуровневая модель данных трансформируется к низькоуровневые модели, после чего реализуются все указанные системы, базы данных и приложения.
При разработке снизу вверх уровень абстракции изменяется в обратном направления: исходным пунктом является необходимость в конкретной системе.
Приверженцы разработки сверху вниз утверждают, что этот подход имеет преимущества перед разработкой снизу доверху, поскольку модели данных (и соответствующие им системы) строятся с глобальной перспективой. Они считают, что такие системы намного лучше взаимодействуют между собою, являются более согласованными и требуют намного меньше переработок.
Приверженцы разработки снизу вверх говорят, что такой подход работает быстрее и сопряжен с меньшим риском. Они утверждают, что моделирования сверху вниз выливается в большее количество исследований, что тяжело выполнять, и что процесс планирования часто заходит в тупик. Хотя моделирования снизу вверх не обязательно имеет своим результатом оптимальный набор систем, тем не менее, с его помощью можно быстро создавать работающую систему. Такие системы начинают давать прибыль намного быстрее, чем системы смоделированные сверху вниз, и это более чем компенсирует любые переработки и модификации, которые понадобиться сделать, чтобы настроить систему на глобальную перспективу.
Наиболее эффективной моделью при разработке сверху вниз является модель «сущность-связь», а при разработке снизу вверх – объектная модель. В данной работе используется метод разрботки сверху вниз и соответственно модель «сущность-связь».
Основы модели «сущность-связь» были заложены Питером Ченом в 1976 году. С тех пор эта модель изменялась, как самим П.Ченом, так и многими другими. Модель «сущность-связь» входит в состав множества СаSе-інструментів, что тоже внесло свой вклад в ее эволюцию. На сегодняшний день не существует единого общепринятого стандарта для модели «сущность-связь», но есть набор общих конструкций, которые составляют основу большинства вариантов этой модели.
Ключевыми элементами модели «сущность-связь» являются сущности, атрибуты, идентификаторы и связи. Сущность – это некоторый объеєкт, который идентифицируется в рабочей среде пользователя, кое-что такое, за чем пользователь хотел бы следить. Сущности одного и того же типа группируется в классы сущностей. Класс сущностей – это совокупность сущностей, и описывается он структурой или форматом сущностей, составляющих этот класс. Экземпляр сущности представляет конкретную сущность. Обычно класс сущностей содержит много экземпляров сущности.
У сущности есть атрибуты, или, как их иногда называют, свойства, которые описывают характеристики сущности. В модели «сущность-связь» предполагается, что все экземпляры данного класса сущностей имеют одинаковые атрибуты. Исходные определения модели «сущность-связь» включают в себя композитные атрибуты и многозначные атрибуты. Экземпляры сущностей имеют идентификаторы – атрибуты, с помощью которых эти экземпляры именуются, или идентифицируются. Идентификатор экземпляра сущности состоит из одного или более атрибутов сущности. Идентификатор может быть уникальным или неуникальным. Если идентификатор является уникальным, его значения будет указывать на один и только одни экземпляр сущности. Если идентификатор является неуникальным, его значения будет указывать на некоторое множество экземпляров.
Взаимоотношения сущностей выражаются связями. Модель «сущность-связь» включает в себя классы связей и экземпляры связей. Классы связей – это взаимоотношения между классами сущностей, а экземпляры связи - взаимоотношения между сущностями. У связей могут быть атрибуты. Класс связей может затрагивать несколько классов сущностей. Число классов сущностей, которые принимают участие в связи, называется степенью связи. Связи степени 2 очень распространенные, их часто называют еще бинарными связями.
Существует много разных подходов к семантическому моделированию баз данных. В последние 10 лет одним из наиболее популярных языков семантического моделирования является UML. Проектирования реляционных БД – только одна и не слишком большая область применения этого языка, его возможности намного шире, однако подмножество UML (диаграммы классов) успешно применяется именно для таких целей.
UML разработанный и развивается консорциумом OMG (Object Management Group) и имеет много общего с объектными моделями, на которые основанная технология распределенных объектных систем CORBA, и объектной моделью ODMG (Object Data Management Group).
Диаграммой классов в терминологии UML называется диаграмма, на которой изображен набор классов (и некоторых других сущностей, которые не имеют явное отношение к проектированию БД), а также связи между этими классами (иногда слово relationship переводится на русский язык не как “связь”, а как “отношения”). Кроме того, диаграмма классов может включать комментарии и ограничения. Ограничения могут неформально задаваться естественным языком или же могут формулироваться языком OCL (Object Constraints Language), который является частью общей спецификации UML Классом называется именованное описание совокупности объектов с общими атрибутами, операциями, связями и семантикой. Графически класс изображается в виде прямоугольника. У каждого класса должно иметься имя, которое уникально отличает его от всех других классов. При формировании имен классов в UML допускается использование произвольной комбинации букв, цифр и даже разделительных знаков. Однако на практике рекомендуется использовать как имена классов короткие и осмысленные прилагательные и существительные, каждое из которых начинается с заглавной буквы.
Атрибутом класса называется именованное свойство класса, которое описывает большое множество значений, которые могут принимать экземпляры этого свойства. Свойство, которое выражается атрибутом, есть свойством моделируемой сущности, общим для всех объектов данного класса. Так что атрибут является абстракцией состояния объекта. Любой атрибут любого объекта класса должный иметь некоторое значение. Имена атрибутов представляются в разделе класса, расположенном под именем класса. Хотя UML не накладывает ограничений на способы формирования имен атрибутов, на практике рекомендуется использовать короткие прилагательные и существительные, смысл которых отвечает содержанию соответствующего свойства класса. Первое слово в имени атрибута рекомендуется писать с прописной буквы, а все другие слова – с заглавной буквы.
Операция – это абстракция того, что можно делать с объектом. Класс может содержать произвольное число операций (в частности, не содержать ни одной операции). Набор операций класса является общим для всех объектов данного класса. При этом можно ограничиться только указанием имен операций, оставив более детальную спецификацию выполнения операций на поздние этапы моделирования. Описание операции может также содержать его сигнатуру, то есть имена и типы всех параметров, а если операция выступает в функции, то и тип ее значения.
В диаграмме классов могут принимать участие связи трех разных категорий: зависимость (dependency), обобщения (generalization) и ассоциирование (association). Для проектирования реляционных БД наиболее важные вторая и третья категории связей.
Зависимостью называют связь по использованию, когда изменение в спецификации одного класса может повлиять на обращение другого, который использует первый класса. Чаще всего зависимости применяются в диаграммах классов, чтобы отразить в сигнатуре операции одного класса тот факт, который параметром этой операции могут быть объекты другого класса. Понятно, что если интерфейс этого второго класса изменяется, то это влияет на обращение объектов первого класса Зависимость показывается пунктирной линией со стрелкой, направленной к классу, от которого имеется зависимость.
Связью-обобщением называется связь между общей сущностью, называемой суперклассом, или отцом, и более специализированной разновидностью этой сущности, называемой подклассом, или потомком. Обобщения иногда называют связями “is a”, имея в виду, что класс-потомок есть частицей случаем класса-предка. Класс-потомок наследует все атрибуты и операции класса-предка, но в нем могут быть определенные дополнительные атрибуты и операции.
Объекты класса-потомка могут использоваться везде, где могут использоваться объекты класса-предка. Это свойство называют полиморфизмом по включению, имея в виде, что объекты потомка можно считать включаются в класс-предок. Графически обобщения изображаются в виде сплошной линии с большой не закрашенной стрелкой, направленной к суперклассу.
Ассоциацией называется структурная связь, которая показывает, что объекты одного класса некоторым образом связанные с объектами другого или того же самого класса. Допускается, чтобы оба конца ассоциации относились до одного класса. В ассоциации могут связываться два класса, и тогда она называется бинарной. Допускается создание ассоциаций, которые связывают сразу n классов (они называются n-арными ассоциациями). Графически ассоциация изображается в виде линии, которая соединяет класс сам с собою или с другими классами. С понятием ассоциации связанные четырех важных дополнительных понятия: имя, роль, кратность и агрегация. Во-первых, ассоциации может быть присвоенное имя, которое характеризует природу связи. Содержание имени уточняется черным треугольником, размещаемым над линией связи по правую сторону или по левую сторону от лица ассоциации. Этот треугольник указывает направление, в котором должно читаться имя связи. Другим способом именования ассоциации является указание роли каждого класса, который участвует в этой ассоциации. Роль класса задается именем, которое помещается под линией ассоциации ближе к данному классу. В общем случае, для ассоциации может задаваться и ее собственное имя, и имена ролей классов. Это связан с тем, что класс может играть ту самую роль в разных ассоциациях, так что в общем случае пара имен ролей классов не идентифицирует ассоциацию. С другой стороны, в простых случаях, когда между двумя классами определяется только одна ассоциация, можно вообще не связывать с ею дополнительные имена.
Кратностью (multiplicity) роли ассоциации называется характеристика, которая указывает, сколько объектов класса с данной ролью может или должно принимать участие в каждом экземпляре ассоциации (в UML экземпляр ассоциации называется соединением – link). Наиболее распространенным способом задачи кратности роли ассоциации есть указание конкретного числа или диапазона. Например, указание “1” говорит о том, что все объекты класса с данной ролью должны принимать участие в некотором экземпляре данной ассоциации, причем в каждом экземпляре ассоциации может принимать участие ровно один объект класса с данной ролью. Указание диапазона “0..1” говорит о том, что не все объекты класса с данной ролью обязанные принимать участие в каком-нибудь экземпляре данной ассоциации, но в каждом экземпляре ассоциации может принимать участие только один объект. Аналогично, указание диапазона “1..*” говорит, что все объекты класса с данной ролью должны принимать участие в некотором экземпляре данной ассоциации, и в каждом экземпляре ассоциации должный принимать участие хотя бы один объект (верхняя граница не задана). Толкования диапазона “0..*” есть очевидным расширением случая “0..1”.
Обычная ассоциация между двумя классами характеризует связь между равноправными сущностями: оба класса находятся на одном концептуальном уровне. Иногда в диаграмме классов нужно отразить тот факт, что ассоциация между двумя классами имеет специальный вид “часть-целое”. В этом случае класс “целое” имеет более высокий концептуальный уровень, чем класс “часть”. Ассоциация такого рода называется агрегатной. Графически агрегатные ассоциации изображаются в виде простой ассоциации с не закрашенным ромбом на стороне класса-“целого”. Бывают случаи, когда связь “части” и “целого” настолько сильная, что уничтожения “целого” приводит к уничтожению всех его “частей”. Агрегатные ассоциации, которые владеют таким свойством, называются композитными, или просто композициями. При наличии композиции объект-часть может быть частью только одного объекта-целого (композита). При обычной агрегатной ассоциации “часть” может одновременно належать нескольким “целым”. Графически композиция изображается в виде простой ассоциации, дополненной закрашенным ромбом со стороны “целого”.
В контексте проектирования реляционных БД агрегатные и в особенности композитные ассоциации влияют только на способ поддержки ссылочной целостности. В частности, композитная связь есть явным указанием того, что ссылочная целостность между “целым” и “частями” должный поддерживаться путем каскадного удаления частей при удалении целого.
В качестве результатов экспериментальных исследований, на основе всего вышеизложенного, была составлена на диаграмма классов для моделирования пользовательских данных для базы данных ПОМПС (рис.2).
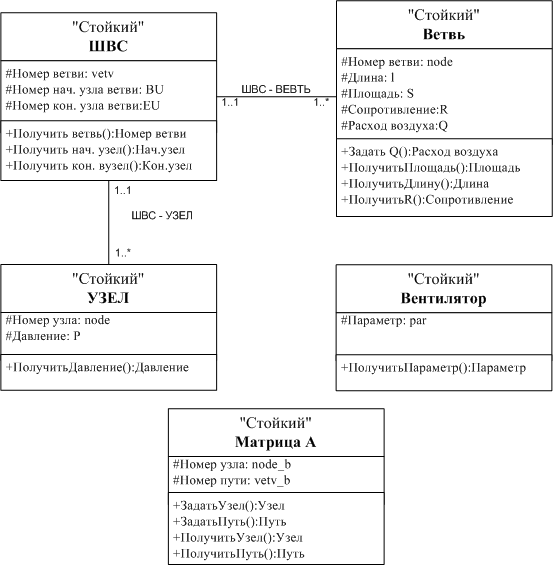
|
| Рис.2 Диаграмма классов ШВС на языке UML |
В работе выполнен выбор СУБД для разрабатываемой базы данных на основании проведенного анализа существующих СУБД. Также разработана диаграмма классов для моделирования пользовательских данных на языке UML.
В данной работе был проведен анализ проблемной области по проблематики моделирования динамических объектов с распределенными параметрами. При анализе были рассмотрены уже выполненные работы в исследуемой области и среди них были найдены аналоги разрабатываемой ПОМПС. Но эти аналоги были рассчитаны либо на моделирования динамических объектов со сосредоточенными параметрами, либо реализации ПОМПС не использовались базы данных и эти среды не были рассчитаны на работу в среде Интернет. Моя же разработка направлена на создание ПОМПС для моделирования динамического объекта с распределенными параметрами (с использованием технологии баз данных) в среде Интернет.
1. Моделирование динамических процессов рудничной аэрологии /Абрамов Ф.А., Фельдман Л.П., Святный В.А. – Киев: Наук. мысль,1981.-284 с.
2. А.Аносов. Критерии выбора СУБД Источник: http://www.citforum.ru/database/articles/criteria/
3. Андреев А. М.Проблема создания современных бизнес-приложений СУБД
4. Теория и практика построения баз даних. 8-е изд./ Д.Крёнке. – СПб.:Питер, 2003.-800с.
5. P.Greenspum. Chapter 11: Choosing a Relational Database Источник: http://www.http://philip.greenspun.com/wtr/dead-trees/index.htm.
| [Биография] | | | [Автореферат] | | | [Индивидуальное задание] | | | [Библиотека] | | | [Ссылки] | | | [Поиск по теме] |