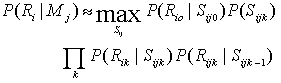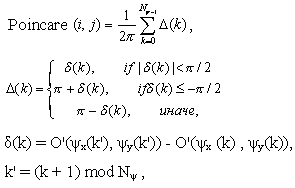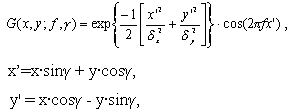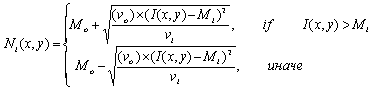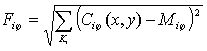| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| главная | биография | автореферат | библиотека | ссылки | результаты поиска | индивидуальное задание | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Тема: «Автоматизированная система контроля доступа на основании распознавания отпечатков пальцев».
Введение. Актуальность. Новизна
Биометрические системы идентификации, доступные в настоящее время или находящиеся в стадии разработки включают в себя системы доступа по отпечатку пальца, аромату, ДНК, форме уха, геометрии лица, температуре кожи лица, клавиатурному почерку, отпечатку ладони, сетчатке глаза, рисунку радужной оболочки глаза, подписи и голосу. В последние годы, процесс идентификации личности по отпечатку пальца обратил на себя внимание как биометрическая технология, которая вполне вероятно будет наиболее широко использоваться в будущем. Преимущества - простота использования, удобство и надежность. Использование отпечатка пальца для идентификации личности является наиболее удобным из всех биометрических методов. Вероятность ошибки при идентификации пользователя намного меньше в сравнении с другими биометрическими методами. Кроме того, само устройство идентификации по отпечатку пальца малогабаритно. В настоящее время уже производятся подобные системы размером меньше колоды карт. Актуальность использования идентификации личности на основании отпечатков пальцев обуссловлена и широкой областью применения. Это: системы идентификации личности, системы контроля доступа, электронной коммерции, банковские системы и т.п. Уже имеются примеры конкретных реализаций систем ограничения доступа к мобильным персональным телекоммуникационным и вычислительным устройствам, системы пропускного контроля на пограничных постах и аэропортах. Запущен проект по интеграции биометрических идентификаторов в документы подтверждающие личность. Сегодня существует более чем 10,000 компьютеризированных мест, хранилищ, исследовательских лабораторий, банков крови, банкоматов, военных сооружений, доступ к которым контролируется устройствами, которые сканируют уникальные физиологические или поведенческие характеристики индивидуума.
Уникальность каждого отпечатка пальца можно определить по узору, который образуют эти гребни и бороздки, а также по другим его деталям. Основные определения, используемые в работе (Рис. 1.1):
Следует отметить, что качество получаемого со сканера изображения папиллярного узора пальца является одним из основных критериев, от которого зависит избираемый алгоритм формирования свертки отпечатка пальца и в конечном итоге идентификации человека.
Во второй половине ХХ века в связи с появлением новых технических возможностей распознавание по отпечаткам пальцев начало выходить за рамки использования только в криминалистике и нашло свое применение в самых различных областях информационных технологий; в первую очередь такими областями стали:
Остановимся подробнее на внутренних аспектах работы современных биометрических систем распознавания по отпечаткам пальцев, на том, с чего начинается их работа и что является ядром любой такой системы.
Одна из основных сложностей при сравнении моделей отпечатков одного пальца заключается в том, что при неправильном размещении пальца на сканирующем устройстве отпечаток пальца претерпевает искажения. Основные усилия в этом направлении прилагаются к созданию модели искажения отпечатка пальца. Такая модель позволит не только разрабатывать системы генерации отпечатков пальца, но и создавать алгоритмы распознавания отпечатка пальца, устойчивые к искажениям. Другая проблема: идентификация по отпечатку пальцев имеет очень низкий уровень FAR ("пропустить чужого", т.е. принимается решение "свой", хотя, на самом деле, субъект отсутствует в списке зарегистрированных пользователей). Но у этого метода, как и у всех других, есть свои проблемы, которые могут возникнуть при идентификации. Во-первых, проблема "муляжа" - возможность имитации папиллярного рисунка живого пальца. Во-вторых, проблема "трудных пальцев" - примерно 1% всех людей испытывают трудности при сканировании папиллярного рисунка из-за повреждений, ожогов, кожных болезней и т.д. Наравне с проблемой "чужой среди своих" возможен вариант "свой среди чужих", когда нужный отпечаток пальца отбрасывается и попадает в разряд "чужих", то есть он не опознается как "свой". Еще одной проблемой, которая возникает при использовании технологии распознавания отпечатков пальцев, является негативное отношение пользователей к этому способу идентификации, связанное с "криминальным" оттенком получения отпечатков пальцев.
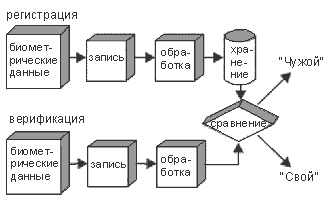
Работа автоматизированной биометрической системы обычно происходит в одном из двух режимов - идентификации или верификации, о которых будет рассказано ниже. В обоих случаях начальная установка, или так называемая регистрация, практически одинаковая и во многом зависит от правильного ввода информации. Процесс регистрации представляет собой установку основных начальных параметров системы и состоит из пяти этапов: 1. Загрузка биометрических данных. При добавлении в базу данных конкретной биометрической характеристики часто вводится несколько ее вариантов, относящихся к одному и тому же лицу, чтобы учесть возможные изменения. Таким образом в базе данных хранятся несколько отпечатков пальцев, относящихся к одному и тому же лицу. 2. Фиксирование данных. Измерение и фиксация базовой биометрической информации, относящейся к конкретному образу. 3. Обработка данных. Перевод зафиксированных данных в цифровую форму с созданием эквивалента отпечатку пальца. 4. Сверка обработанных данных с первично загруженной информацией. Проводится с целью подтверждения правильности распознавания системой введенных данных. 5. Сохранение подтвержденных биометрических данных. Результатом регистрации должен стать представленный в электронном виде информационный пакет, удобный для использования и размещенный в базе данных или же на идентификационных смарт-картах. Регистрация является тем этапом, на котором крайнюю важность приобретают эффективное взаимодействие между всеми пользователями и точное выполнение всех процедур, так как от этого зависят дальнейшее функционирование, работоспособность и точность системы. Один из важных вопросов, которые необходимо решить, заключается в том, для чего планируется использовать систему - для идентификации или верификации. Если говорить об идентификации, то система пытается найти, кому принадлежит данный образец, сравнивая образец с базой данных для того, чтобы найти совпадение (также этот процесс называют сравнением одного со многими). Верификация - это сравнение, при котором биометрическая система пытается верифицировать личность человека. В таком случае новый биометрический образец сравнивается с ранее сохраненным образцом. Сравнивая эти два образца, система подтверждает, что данный человек действительно тот, за кого он себя выдает. В процессе идентификации система сравнивает один образец со многими, тогда как процесс аутентификации или верификации сравнивает один с одним. В случае идентификации необходима центральная база данных биометрической информации, с которой будет сравниваться конкретный образец. Во втором случае биометрические данные человека проверяются на сходство с электронными данными, содержащимися, например, на смарт-карте.
На самом простом техническом уровне, например, если разрешение полученного со сканера изображения составляет 300-500 dpi, на изображении поверхности пальца можно выделить достаточно большое количество мелких деталей (minutiae), по которым можно их классифицировать, но, как правило, в автоматизированных системах используют всего два типа деталей узора (особых точек):
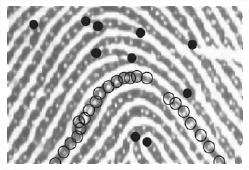
Если есть возможность получить изображение поверхности пальца с разрешением около 1000 dpi, на нем можно обнаружить детали внутреннего строения самих папиллярных линий, в частности, поры потовых желез (рисунок 2.3, пустыми кружками отмечены поры, черными кружками отмечены конечные точки и точки ветвления) и соответственно использовать уже их расположение в целях идентификации. Однако этот метод мало распространен из-за сложности получения в не лабораторных условиях изображений такого качества.
В автоматизированном распознавании отпечатков пальцев, в отличие от традиционной дактилоскопии, возникает гораздо меньше проблем, связанных с различными внешними факторами, влияющими на сам процесс распознавания. При получении отпечатков пальцев красковым способом (с помощью откатки) важно исключить или, по крайней мере, максимально уменьшить смещение или поворот пальца, изменение давления, изменение качества поверхности кожи и т.д. С электронных бескрасковых сканеров получить изображение отпечатка пальца с достаточным для обработки качеством существенно проще. Качество получаемого со сканера изображения папиллярного узора пальца является одним из основных критериев, от которого зависит избираемый алгоритм формирования свертки отпечатка пальца и в конечном итоге идентификации человека.
1. Корреляционное сравнение. Суть метода заключается в следующем. Полученный со сканера отпечаток пальца накладывается на каждый эталон из базы данных поочередно, после чего прямо по пикселям изображений осуществляется просчет различий между ними. Правда, при этом приходится учитывать один момент. Дело в том, что человек каждый раз прикладывает палец под разными углами и не точно в одно и то же место рабочей области сканера. А это значит, что процесс сравнения отпечатка его пальца с эталонами должен включать в себя множество итераций, на каждой из которых изображение, полученное со сканера, поворачивается под небольшим углом или чуть-чуть смещается. Главным преимуществом этого рассматриваемого метода идентификации являются низкие требования к качеству изображения отпечатка пальца. Недостатком же остается большая длительность процедуры сравнения полученного папиллярного узора с эталонами. А это очень сильно ограничивает область применения корреляционного сравнения. Вследствие сложности и длительности работы данного алгоритма, особенно при решении задач идентификации (сравнение "один-ко-многим") - системы, построенные с его использованием, сейчас практически не используются. 2. Сравнение по особым точкам - по одному или нескольким изображениям отпечатков пальцев со сканера формируется шаблон, представляющий собой двухмерную поверхность, на которой выделены конечные точки и точки ветвления. При сравнении - на отсканированном изображении отпечатка также выделяются эти точки, карта этих точек сравнивается с шаблоном и по количеству совпавших точек принимается решение по идентичности отпечатков. Главным преимуществом алгоритма сравнения отпечатков пальцев по особым точкам является быстрота его работы. Больше всего времени в процессе идентификации занимает перебор эталонов в поиске отпечатка, идентичного временному. Поэтому в силу простоты реализации и скорости работы - алгоритмы данного класса являются наиболее распространенными. Правда, есть у метода сравнения по особым точкам и недостаток. Им являются относительно высокие требования к качеству изображения папиллярного узора. Для их удовлетворения сканер должен обеспечивать разрешение не меньше 300, а лучше - около 500 dpi. 3. Сравнение по узору - в данном алгоритме сравнения используется непосредственно особенности строения папиллярного узора на поверхности пальцев. Полученное со сканера изображение отпечатка пальца, разбивается на множество мелких ячеек, как показано на рисунке 2.4 (размер ячеек зависит от требуемой точности).
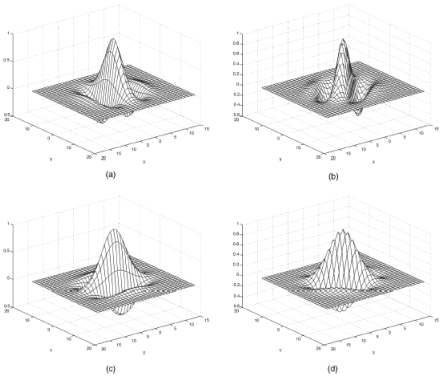
Расположение линий в каждой ячейке описывается параметрами некоторой синусоидальной волны (рисунок 2.5), то есть, задается начальный сдвиг фазы (
Специальный модуль рассматривает папиллярные линии в квадратиках поочередно и каждую из них описывает уравнением синусоидальной волны, то есть устанавливает начальный сдвиг фазы, длину волны и направление ее распространения. Именно эти данные и используются для идентификации: в базе данных эталонов хранятся параметры всех отрезков бугорков в каждой области. И именно они сравниваются с данными, полученными при сканировании. Главными плюсами рассмотренного алгоритма являются достаточно высокая скорость его работы и низкие требования к качеству получаемого изображения. К сожалению, метод сравнения по узору пока не получил широкого распространения. Дело в том, что он очень сложен для реализации и требует солидной математической базы. Поэтому только немногие компании взяли на вооружение подобный подход.
1) на основе модели. Метод классификации отпечатка пальца на основе модели использует местоположения особых точек (ядро и разветвление), чтобы классифицировать отпечаток пальца в пять вышеупомянутых классов. Подход на основе модели использует знания людей-экспертов, применяя правила для каждой категории вручную построенной модели и поэтому, не требует обучения. Использование этих подходов показало точность 85% и 87.5% относительно базы данных NIST-4. 2) на основе структуры. Подход на основе структуры использует предполагаемую область ориентации в изображении отпечатка пальца, чтобы классифицировать отпечаток пальца в один из этих пяти классов. Получена точность 90.2% с 10-процентным отклонением относительно базы данных NIST-4. Нейронная сеть обучалась на изображениях от 2 000 пальцев (одно изображение на палец) и затем была проверена на независимом наборе 2 000 изображений, взятых от тех же самых пальцев. Ошибка оказалась удивительной. Более поздняя версия этого алгоритма была проверена на базе данных NIST-14, которая является естественно распределенной базой данных, обеспечивая лучшее выполнение алгоритма. Однако, это улучшение выполнения предполагалось, так как база данных NIST-14 содержит маленький процент отпечатков пальцев типа дуга, которые наиболее трудны для классификаторов отпечатка пальца, а нейронная сеть, используемая в алгоритме, неявно использует эту информацию. Подобный подход на основе структуры, который использует скрытые модели Маркова для классификации, зависит от надежности оценки местоположений выступов, которая трудна в шумных изображениях. В другом подходе на основе структуры используются кривые B-сплайна, чтобы классифицировать отпечатки пальца. 3) на основе частоты. Подходы на основе частоты используют спектр частоты отпечатков пальца для классификации. Здесь используются ряды Фурье. 4) синтаксический подход. Синтаксический подход использует формальную грамматику, чтобы представить и классифицировать отпечатки пальца. 5) гибридные подходы. Гибридные подходы комбинируют два или больше подхода для классификации. Эти подходы подают надежды, но не были проверены на больших базах данных. Например, отчет Чонг и др. заканчивается на 89 отпечатках пальца, Фитз и Грин - на 40 отпечатках пальцев, и Кавагое и Тоджо - на 94 отпечатках пальцев.
1. Классификатор K-ближайший. Классификатор К-ближайший приводит к точности 85.4% для задачи классификации пятого класса, когда рассматриваются 10 ближайших соседей (K=10). Точность классификации не всегда увеличивается с увеличением K; так существует оптимальное значение K для конечных учебных задач классификации размера модели. Для задачи классификации четвертого класса (где классы A и T были объединены в один класс), достигнута точность 91.5%. Смешанная матрица для классификатора K- ближайший показана в таблице 2.1.
Таблица 2.1 Смешанная матрица для классификатора K-ближайших соседа (К=10) Диагональные записи в этой матрице показывают число тестовых моделей от различных классов, которые правильно классифицированы. Так как множество отпечатков пальца в базе данных NIST-4 помечено как принадлежность двум различным классам, суммы ряда смешанной матрицы в рядах не идентичны. 2. Классификатор Нейронная сеть В данном случае обучалась многослойная передовая нейронная сеть, используя быстрое распространение, обучающее алгоритм. Нейронная сеть имеет один скрытый слой с 20 нейронами, 192 нейронами входа, и пятью нейронами выхода, соответствующими этим пяти классам. Получалась точность 86.4% для задачи классификации пятого класса. Для задачи классификации четвертого класса, достигнута точность 92.1%. Смешанная матрица для классификатора нейронная сеть приведена в таблице 2.2.
Таблица 2.2 Смешанная матрица для классификатора нейронной сети. 3. Двухэтапный Классификатор Здесь идея состоит в том, чтобы выполнить "простую" задачу классификации, используя классификатор K-NN и затем - группу классификаторов нейронной сети с двумя классами, чтобы обращаться с более тонкими выделениями. Первая стадия использует классификатор K-ближайший (K = 10), чтобы привести к двум самым вероятным классам. Было замечено, что 85.4% времени, класс с максимальной частотой среди К-ближайших - правильный класс, а 12.6% времени, класс со второй наивысшей частотой - правильный класс. Другими словами, классификатор K-ближайший приводит к лучшим двум классам с точностью до 98%. Этот результат может использоваться, чтобы точно классифицировать отпечатки пальца в два из этих пяти классов. Каждый отпечаток пальца будет иметь вхождение в два из пяти разделения базы данных, и соответственно обязан будет входить только в соответствующие два разделения базы данных. Вторая стадия использует 10 различных нейронных сетей для 10 различных попарных классификаций. Эти нейронные сети имеют 192 нейрона входа, 20-40 скрытых нейронов в одном скрытом слое, и 2 нейрона выхода. Каждая нейронная сеть обучается, используя образцы только от двух соответствующих классов в учебном наборе. Например, нейронная сеть, которая различает R и W, обучается, используя только помеченные образцы R и W в учебном наборе. Этот двухэтапный классификатор обеспечивает точность 90% для задачи классификации пятого класса, а для задачи классификации четвертого класса достигнута точность 94.8%. Смешанная матрица для двухэтапного классификатора приведена в таблице 2.3.
Таблица 2.3 Смешанная матрица для двухэтапного классификатора. Хотя этот классификатор является устойчивым к шуму и в состоянии правильно классифицировать большинство отпечатков пальца низкого качества в базе данных NIST-4, оно не применимо на некоторых очень плохих, некачественных изображениях отпечатка пальца, где никакая информация выступа не присутствует в центральной части отпечатка пальца. В отпечатках пальца низкого качества, очень трудно правильно обнаружить точку центра. Классификатор также не в состоянии правильно классифицировать изображения петли близнеца, которые помечены как пальцевой узор в базе данных NIST-4. Для этих изображений, алгоритм местоположения центра улучшает верхнее ядро и при рассмотрении определяет, что центр изображения похож на петлю в нужной области, что приводит к ошибочной классификации W как L или R. Приблизительно 3% ошибочно классифицируются из-за малого различия между петлей и типами дуги. Ошибочная классификация A-T составляет приблизительно 5% ошибок. 4. Классификатор отклонение выбора Точность классификации может быть далее увеличена, применяя выбор отклонения. Использовалось (K, K') - классификатор К-ближайших для отклонения и предложенного двухэтапного классификатора для классификации. Если число обученных образцов от класса среди K-ближайших тестовой модели меньше чем K' (K'‹K), мы отклоняем тестовую модель и не пытаемся классифицировать ее. Большинство отклоненных изображений, которые используют эту схему, плохого качества. Другие отклоненные изображения - изображения, которые "кажется" принадлежат различным классам. Отклоняя 19.5% изображений для задач пятого класса, точность классификации может быть увеличена до 93.5%, а для задач классификации четвертого класса, точность может быть увеличена до 96.6% (табл 2.4).
Таблица 2.4 Соотношение отклонения ошибки 5. Классификатор скрытой модели Маркова Скрытые модели Маркова (СММ) - форма стохастического конечного автомата состояния, подходящего к распознаванию образов и успешному полному применению распознавания речи и других задач. Эти модели способны классифицировать данные, основанные на большом количестве признаков, число которых является переменным и имеет определенные типы основной структуры. В отпечатке пальца, основная информация класса может быть выведена из синтаксического анализа особых точек, но может также быть замечена в общем виде выступов. СММ в состоянии статистически моделировать различные структуры образцов выступов по целому отпечатку, не основываясь на извлечении особых точек. Чтобы находить местоположения выступов, используется множество методов обработки изображения. Выступы утончаются таким образом, чтобы каждый выступ представлялся линией шириной в один пиксел, которая названа скелетом. Учитывая скелетное изображение выступов, параллельные принятые за основу сравнения линии, расположены поперек изображения под углом ф. Для каждого пересечения принятой за основу линии с выступом, сгенерирован признак. Каждый признак состоит из множества измерений, выбранных, чтобы характеризовать поведение выступа и его развитие в точке пересечения. Размеры каждого признака называют структурой и структурами, Rik для i-ой принятой за основу линии все вместе называют рядом, Ri, расположение которого сохранено. Для каждой ориентации ф принятой за основу линии, определено представление Rф={Ri,Vi} отпечатка. В этом исследовании, использовались только горизонтальные и вертикальные линии, предоставляя особенности Rh и Rv, соответственно. Как правило, СММ - одномерные структуры, подходящие для того, чтобы анализировать временные данные. Здесь, данные являются двумерными, но процесс извлечения особенности может также быть описан как одно измерение массива одномерных процессов ряда. Для классификации, модель Mc построена для каждого класса, c, и максимальный класс вероятности выбран после вычисления вероятности данных R, образующих модель: argmaxcP(R| Mc). Вероятности выделения структуры смоделированы с объединением диагональной ковариации, многомерных Гауссовских распределений. Таким образом, для любой структуры Rik, возможно вычислить вероятность P(Rik|Sijk)) этого происходящий в любом состоянии Sijk. С этими вероятностями, для любой модели ряда, вероятность любого ряда может быть приближена к максимальной вероятности любой последовательности состояния, выравнивающей признаки и состояния, вычисленные как результат вероятностей структуры и вероятностей перехода для последовательности состояния:
Для каждой ориентации принятых за основу линий может быть сделан отдельный классификатор. Так как ошибки различных классификаторов будут отличны, комбинация их множества может привести к лучшей точности. Обозначение Mhc, Mvc, класс "c" модели, обучаемые с вертикальными и горизонтальными особенностями, соответственно, и независимостью принятия, вероятность данных написан как:
6. Классификатор дерево решения Это решение построения деревьев использует методы, разработанные такими людьми, как Эмит и др. Эти авторы занялись множеством проблем, включая изображения классификации распознавания пальца с помощью цифр от '0' до '9'. Техника, используемая Эмитом и др. для того, чтобы строить деревья решений использует стадию большого количества простых признаков. Каждая признак в отдельности обеспечивает немного информации о решении классификации. Однако комбинации таких признаков могут предоставить много важной информации, необходимой для принятия точного решения классификации. Эмит и др. описывают процедуру создания деревья решения, поднимая вопросы, основанные на таких комбинациях простых признаков. Процедура для классификации отпечатка пальца затрагивает начальную фазу извлечения характерных черт, сопровождаемую построением задачи, которая создает информативные вопросы, помогающие в классификации. Эти сложные вопросы объединены в иерархической манере и формируют деревья решения, которые используются для классификации. Поскольку деревья построены случайно, деревья, построенные для одной и той же задачи, имеют различные результаты и, как правило, многократные деревья объединены с классификаторами дерева решения, чтобы дать окончательную классификацию.
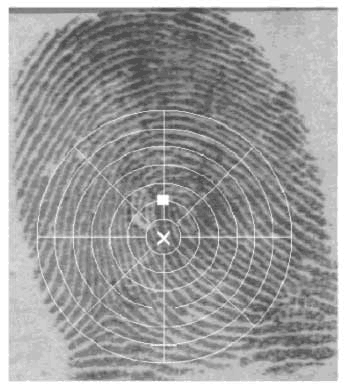
Категория отпечатка пальца определена его глобальными выступами и структурами бороздочек. Надежный набор признаков для классификации отпечатка пальца должен быть в состоянии полностью захватить эту глобальную информацию. Была развита новая схема представления (код пальца), который в состоянии представить и мелкие детали, и глобальные выступы и структуры бороздочек отпечатка пальца. Для классификации, использовалось представление низкого уровня, которое является очень эффективным в представлении глобальных выступов и структур бороздочек и которое инвариантно к индивидуальным мелким деталям. Главные шаги этого алгоритма извлечения признаков следующие: 1) Найти регистрационную точку (точку центра) и определить пространственное составление мозаики места изображения вокруг регистрационной точки (представленное совокупностью секторов). 2) Разложить входное изображение в ряд составляющих изображений, которые сохраняют глобальные выступы и структуры бороздочек. 3) Вычислить оценку стандартного отклонения серого уровня в каждом секторе, чтобы сформировать вектор признаков или код пальца. Пусть I(x, y) обозначают серый уровень в пикселе (x, y) в М x N изображении отпечатка пальца и пусть (xc, yc) обозначают точку центра. Пространственное составление мозаики области изображения, которое состоит из значимой области, определено совокупностью секторов Si, где i-сектор Si вычислен в терминах параметров (r, Главные шаги алгоритма классификации следующие (рис. 2.7): 1) Определить местонахождение регистрационных точек во входном изображении и определить пространственное составление мозаики области вокруг регистрационной точки (сектора). Любая точка, которая может быть последовательно обнаружена в изображении отпечатка пальца, может использоваться как регистрационный точка (или точка центра (xc, yc), так как она может быть помещена в центр изображения). Алгоритм обнаружения этой точки: а) Оценить область ориентации О, используя алгоритм оценки ориентации наименьшего квадрата. Область ориентации О определена как N x N изображение, где O(i,j) представляет местную ориентацию выступов в пикселе (i,j). Изображение разделено на ряд wxw неналожившихся окон, и единственная местная ориентация определена для каждого окна. б) Сгладить область ориентации в местном соседстве. Пусть приглаженной ориентации области будет представлена как O'. в) Иницализировать A, изображение метки как правило указывает основную точку. г) Для каждого пиксела (i, j) в O', вычисляют индекс Пуанкарэ (Poincare) и назначают соответствующие пикселы в А значение одного из индекса Пуанкарэ - (1/2). Индекс Пуанкарэ в пикселе (i, j) приложенный к пальцевидной кривой, которая состоит из последовательности пикселов, которые на расстоянии одного пиксела от соответствующей кривой, вычислен следующим образом:
д) Найти связанные компоненты в A. Если область связанного компонента больше семи, ядро обнаружено в средней точке связанного компонента. Если область связанного компонента больше 20-ти, два ядра обнаружены в средней точке связанного компонента. е) Если обнаружено больше, чем два ядра, возвратитесь к Шагу б). ж) Если два ядра обнаружены, центр назначен координаты основной точки с нижним значением y (верхнее ядро). Если только одно ядро обнаружено, центр имеет координаты основного центра. з) Если никакая основная точка не обнаружена, вычислите матрицу ковариации векторной области в местном соседстве (q x q) каждой точки в области ориентации. Определите изображение признаков I с наибольшим собственным значением матрицы ковариации для каждого элемента в изображении ориентации. Ядро обнаружено в средней точке наибольшего связанного компонента в пороговом изображении F и центр назначен координатами ядра. Центр, найденный выше, перемещен на 40 пикселов вниз для дальнейшей обработки, основанной на факте, что большинство информации в отпечатке пальца находится в более низкой части отпечатка пальца. Эта значение было опытным путем определено. 2) Разбить входное изображение на ряд составляющих изображений, каждое из которых сохраняет определенные структуры выступов; вычислить стандартное отклонение составляющих изображений в каждом секторе, чтобы составить вектор признаков (названный кодом пальца). Это достигается при помощи фильтров Габора. Фильтры Габора - полосовые фильтры, которые имеют свойства и отборной ориентации, и отборной частоты, и имеют оптимальное объединенное решение и в пространстве и области частоты. Применяя фильтры Габора к изображению отпечатка пальца, истинные выступы и структуры ряда могут быть хорошо выделены (рис. 2.9) Ровный симметрический фильтр Габора имеет следующую общую форму в пространственной области
В нашем алгоритме, частота фильтра f - это средняя частота выступов (1/K), где K - расстояние между выступами. Среднее расстояние между выступами - приблизительно 10 пикселов в изображении отпечатка пальца 500 точек на дюйм. Опытным путем определены значения Изображение отпечатка пальца разделено на четыре составляющих изображения, соответствующие четырем различным значениям Перед разложением изображения отпечатка пальца, мы нормализуем необходимую область в каждом секторе отдельно к постоянному среднему и разнице. Нормализация сделана, чтобы удалить эффекты шума датчика и различий давления пальца. Пусть I(x, y) обозначают серое значение в пикселе (x, y), Mi и Vi, предполагаемом среднем и разнице сектора Si, соответственно, и Ni(x, y), нормализованное значение серого уровня в пикселе (x, y). Для всех пикселов в секторе Si, нормализованное изображение определено как:
Нормализация - пиксельная операция, которая не изменяет четкость структур бороздочек и выступов. Для наших экспериментов, мы устанавливаем оба значения и M0, и V0 равными 100. Нормализованные, фильтрованные, и восстановленные изображения для отпечатка пальца, показаны на рис. 2.10.
3) Ввести вектор признаков в классификатор; В этом алгоритме, используется двухэтапный классификатор. Этот двухэтапный классификатор использует классификатор соседа K-ближайщий на первой стадии и ряд классификаторов нейронной сети на второй стадии, чтобы классифицировать вектор признаков в один из пяти классов отпечатка пальца. В каждом составляющем изображении, местное соседство с выступами и бороздочками, которые являются параллельными соответствующему направлению фильтра, показывает более высокое изменение, тогда как местное соседство с выступами и бороздочками, которые не параллельны соответствующему фильтру, имеет тенденцию быть уменьшенным фильтром, что приводит к более низкому изменению. В нашем алгоритме, стандартное отклонение в пределах секторов определяет вектор признаков. Пусть
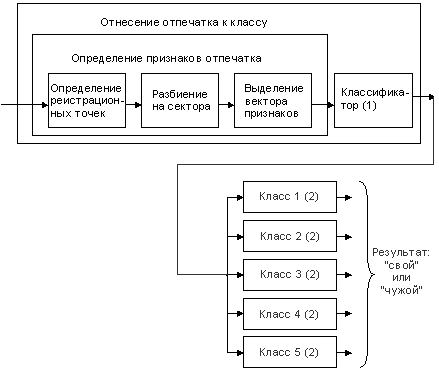
На схеме 2.1 представлен алгоритм идентификации отпечатков пальцев, использующий комбинированный метод. Как видно из схемы, основными этапами являются: определение регистрационных точек, разбиение на сектора и выделение вектора признаков. По этому вектору с помощью классификатора отпечаток пальца будет классифицирован в один из пяти классов.
Схема 2.1 Алгоритм идентификации отпечатка пальца (1) - используемые классификаторы:
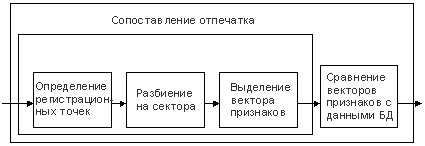
Поскольку отнесение к классу основывается на своих признаках, то в каждом подклассе используется свой алгоритм сопоставления отпечатка пальца с набором отпечатков из данного класса.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| главная | биография | автореферат | библиотека | ссылки | результаты поиска | индивидуальное задание | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||