
Факультет: Обчислювальної техніки та інформатики
Кафедра: Прикладної математики та інформатики
Спеціальність: Програмне забезпечення автоматизованих систем
Тема магістерскої роботи: Оцінка ефективності паралельних однокрокових
алгоритмів рішення задачі Коші для ЗДР
Керівник: д.т.н., професор, Фельдман Л.П.
Біографія
Реферат на тему: «Оцінка ефективності паралельних однокрокових алгоритмів рішення задачі Коші для ЗДР»
Введення
Ідея розпаралелювання обчислень базується на тому, що більшість задач може бути розділена на набір менших завдань, які можуть бути вирішені одночасно. Паралельні обчислення використовувалися багато років в основному в найпродуктивніших обчисленнях, але останнім часом до них зріс інтерес внаслідок існування фізичних обмежень на зростання тактової частоти процесорів.
Поява в останні роки великої кількості порівняно дешевих кластерних паралельних обчислювальних систем призвело до швидкого розвитку паралельних обчислювальних технологій, у тому числі і в області високопродуктивних обчислень. Останнім часом ситуація в галузі паралельних обчислювальних технологій почала кардинально змінюватися в зв'язку з тим, що більшість основних виробників мікропроцесорів стали переходити на багатоядерні архітектури. Зміна апаратної бази змушує змінювати і підхід до побудови паралельних алгоритмів. Для реалізації обчислювальних можливостей багатоядерних архітектур потрібна розробка нових паралельних алгоритмів. Ефективність використання обчислювальних ресурсів, яку будуть мати кластери нового покоління, напряму залежатиме від якості власне паралельних програм, так і спеціалізованих бібліотек чисельних алгоритмів, орієнтованих на багатоядерні архітектури.
Актуальність даної теми: Постоянные исследования в области разработки и создания высокопроизводительных вычислительных средств позволяют решать фундаментальные и прикладные задачи. Производительности современных ЭВМ недостаточно для обеспечения нужного решения многих задач. Один из наиболее эффективных способов повышения производительности заключается в распараллеливании вычислений в многопроцессорных и параллельных структурах. Моделирование реальных экономических, технических и других процессов, описываемых системами обыкновенных дифференциальных уравнений (СОДУ) большой размерности, представляет собой обширный класс задач, для решения которых применение высокопроизводительной вычислительной техники не только оправдано, но и необходимо. Постійні дослідження в галузі розробки і створення високопродуктивних обчислювальних засобів дозволяють вирішувати фундаментальні та прикладні завдання. Продуктивності сучасних ЕОМ недостатньо для забезпечення потрібного розв’язання багатьох задач. Один з найбільш ефективних способів підвищення продуктивності полягає в розпаралелюванні обчислень у багатопроцесорних і паралельних структурах. Моделювання реальних економічних, технічних та інших процесів, які описуються системами звичайних диференціальних рівнянь (СЗДР) великої розмірності, є великий клас задач, для вирішення яких застосування високопродуктивної обчислювальної техніки не тільки виправдано, але і необхідно.
Один з найбільш ефективних способів підвищення продуктивності полягає в розпаралелюванні обчислень у багатопроцесорних і паралельних структурах. Внаслідок чого, застосування паралельних обчислювальних систем є досить важливим напрямком розвитку обчислювальної техніки.
Останнім часом з'явилася велика кількість чисельних методів інтегрування диференціальних рівнянь, які орієнтовані на обчислювальні системи з паралельною архітектурою. Однак практичне використання більшості методів не завжди виправдано, оскільки багато з них або мають чисельну нестійкість, або мають дуже складну структуру, що призводять до втрати ефективності. До методів, позбавлених зазначених недоліків, можна віднести блочні. Блочний будемо називати метод, при якому для блоку з k точок нові k значень функції обчислюються одночасно. Ця особливість методів, по-перше, узгоджується з архітектурою паралельних обчислювальних систем, а, по-друге, дозволяє обчислювати коефіцієнти різнистних формул не в процесі інтегрування, а на етапі розробки методу, що значно збільшує ефективність рахування. Однак, при всіх їх достоїнствах ці методи розглянуті недостатньо. Інформація, в основному, захищена і недоступна без реєстрації або оплати.
дослідження, порівняння, удосконалення та визначення оптимальних паралельних однокрокових алгоритмів рішення задачі Коші для ОДУ для певного виду обчислювальної схеми. Слід враховувати, що метод повинен мати чисельну стійкість, мати оптимальну для збереження ефективності структуру і час рішення, і, відповідно, час моделювання. Щоб зробити висновок про доцільність реалізації і вигоді, що одержується при застосуванні паралельного методу, необхідно знати його прискорення і коефіцієнт паралелізму.
Аналіз розвитку паралельних обчислень
Обчислення називають паралельними, якщо в один і той же момент часу одночасно виконується кілька операцій обробки даних [1]. Можна прискорити процес вирішення задачі за допомогою поділу алгоритму на деякі незалежні частини, які будуть виконуватися на окремих процесорах. Однак паралелізм ще не отримав широкого розповсюдження. Це зумовлено наступними факторами [2]:
- Висока вартість паралельних обчислювальних систем. За законом Гроша, продуктивність комп'ютера зростає пропорційно квадрату його вартості і, отже, більш вигідно отримати необхідну обчислювальну потужність придбанням одного продуктивного процесора, ніж використанням декількох менш швидкодіючих процесорів. Але, слід враховувати, що зростання швидкодії послідовних ЕОМ не може тривати нескінченно, крім того, навіть найбільш потужні комп'ютери піддаються швидкому моральному старінню. Тенденція ж побудови високопродуктивних комплексів з типових елементів: мікропроцесорів, мікросхем пам'яті, комунікаційних пристроїв, масовий випуск яких освоєно промисловістю, сильно знижує вплив цього фактора [1].
- Втрати продуктивності для організації паралелізму - згідно гіпотези Мінського, прискорення, досягається при використанні паралельної системи, пропорційно подвійному логарифму від числа процесорів, тобто при кількості процесорів 1000 можливе прискорення виявляється рівним 10. При цьому існує велика кількість завдань, паралельне вирішення яких досягається 100% використанням усіх наявних процесорів паралельної обчислювальної системи.
- Постійне вдосконалення послідовних комп'ютерів - відповідно до закону Мура потужність послідовних процесорів зростає практично у два рази кожні 18-24 місяців і, як результат, необхідна продуктивність може бути досягнута і на звичайних послідовних комп'ютерах.[5, c. 3-4].
- Існування послідовних обчислень - згідно з законом Амдаля [3] прискорення процесу обчислень при використанні р процесорів обмежується величиною
- Залежність ефективності паралелізму від обліку характерних властивостей паралельних систем - на відміну від одиничності класифікації схеми фон Неймана послідовних ЕОМ паралельні системи істотно відрізняються різноманітністю архітектурних принципів побудови, і максимальний ефект від використання паралелізму може бути отриманий тільки при повному використанні всіх особливостей апаратури. Отже, перенесення паралельних алгоритмів і програм між різними типами систем стає важким. При всьому розмаїтті архітектур паралельних систем, існують і певні засоби забезпечення паралелізму.
- Існуюче програмне забезпечення орієнтовано в основному на послідовні ЕОМ [4]. Але, якщо послідовні програми не дозволяють отримувати вирішення нових завдань за певний час або ж виникає необхідність вирішення нових завдань, то стає необхідною розробка нового програмного забезпечення, і ці програми можуть бути реалізовані в паралельному варіанті.
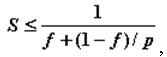
де f є частиною послідовних обчислень в алгоритмі, що використовується для обробки даних. Однак, часто частина послідовних дій характеризує не можливість паралельного вирішення завдань, а послідовні властивості алгоритмів, що застосовуються. І, отже, частина послідовних обчислень може бути істотно знижена при виборі більш підходящих для розпаралелювання алгоритмів.
При виконанні паралельних обчислень в МВС для організації взаємодії, синхронізації паралельно виконуваних процесів використовується передача даних між процесорами обчислювального середовища. Тимчасові затримки при передачі даних по лініях зв'язку можуть виявитися істотними (у порівнянні зі швидкістю процесорів) і, як результат, комунікаційна трудомісткість алгоритму суттєво впливає на вибір паралельних способів вирішення завдань.
Топології
До числа типових топологій зазвичай відносять наступні схеми: лінійка, кільце, решітка, тор, гіперкуб, кліка, зірка.[5]
- лінійка (linear array or farm) - система, в якій кожен процесор має лінії зв'язку тільки з двома сусідніми (з попереднім і наступним) процесорами; така схема, з одного боку, просто реалізується, а з іншого боку, відповідає структурі передачі даних при вирішенні багатьох обчислювальних задач (наприклад, при організації конвейєрних обчислень);
- кільце (ring) - дана топологія витікає з лінійки процесорів з'єднанням першого та останнього процесорів лінійки;
- зірка (star) - система, в якій всі процесори мають лінії зв'язку з деяким керуючим процесором; дана топологія є ефективною, наприклад, при організації централізованих схем паралельних обчислень;
- повний граф (completely-connected graph or clique) - система, в якій між будь-який парою процесорів існує пряма лінія зв'язку, як результат, дана топологія забезпечує мінімальні витрати при передачі даних, проте є складно реалізується при великій кількості процесорів;
- решітка (mesh) - система, в якій граф ліній зв'язку утворює прямокутну сітку (зазвичай двох-або трьох-мірну); подібна топологія може досить просто реалізовуватись і, крім того, може бути ефективно використовуватися при паралельному виконанні багатьох чисельних алгоритмів (наприклад, при реалізації методів аналізу математичних моделей, які описуються диференціальними рівняннями з частинними похідними);
- гиперкуб (hypercube) - данная топология представляет частный случай структуры решетки, когда по каждой размерности сетки имеется только два процессора (т.е. гиперкуб содержит 2N процессоров при размерности N); данный вариант организации сети передачи данных достаточно широко распространен в практике и характеризуется следующим рядом отличительных признаков:
1) два процессора имеют соединение, если двоичное представление их номеров имеет только одну различающуюся позицию;
2) в N-мерном гиперкубе каждый процессор связан ровно с N соседями;
3) N-мерный гиперкуб может быть разделен на два (N–1)-мерных гиперкуба (всего возможно N различных таких разбиений);
4) кратчайший путь между двумя любыми процессорами имеет длину, совпадающую с количеством различающихся битовых значений в номерах процессоров (данная величина известна как расстояние Хэмминга). Реальные высокопроизводительные параллельные вычислительные системы обычно используют несколько различных схем соединения процессоров. Это позволяет сочетать лучшие качества известных топологий и минимизировать недостатки. Другим способом улучшить характеристики схем коммутации является построение систем с изменяемой конфигурацией. Изменять шаблон соединений можно как статически (до выполнения программы), так и динамически (в ходе ее выполнения). гіперкуб (hypercube) - дана топологія представляє окремий випадок структури решітки, коли на кожній розмірності сітки є тільки два процесори (тобто гіперкуб містить 2N процесорів при розмірності N); даний варіант організації мережі передачі даних досить широко розповсюджений у практиці і характеризується наступними рядом характерних ознак:
1) два процесори мають з'єднання, якщо двійкове представлення їх номерів має тільки одну позицію, яка розрізняється;
2) у N-мірного гіперкубе кожен процесор зв'язаний тільки з N сусідами;
3) N-мірний гіперкуб може бути розділений на два (N-1)-мірних гіперкуба (можливо тільки N різних розділень);
4) найкоротший шлях між двома будь-якими процесорами має довжину, що збігається з кількістю різних бітових значень в номерах процесорів (ця величина відома як відстань Хеммінга). Реальні високопродуктивні паралельні обчислювальні системи зазвичай використовують декілька різних схем з'єднання процесорів. Це дозволяє поєднувати кращі якості відомих топологій і мінімізувати недоліки. Іншим способом поліпшити характеристики схем комутації є побудова систем зі змінною конфігурацією. Змінювати шаблон з'єднань можна як статично (до виконання програми), так і динамічно (в ході її виконання).
Послідовний метод
У загальному випадку метод Рунге-Кутти записують у вигляді
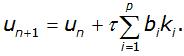
Де:
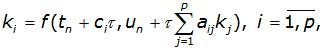
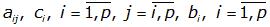 – константи
– константи
Число p, що показує кількість допоміжних точок kj, що використовуються для обчислення основної точки ki, називається порядком методу.

Паралельні однокрокові блочні методи
Розглянемо рішення задачі Коші для одного звичайного диференціального рівняння першого порядку
однокроковим блочним методом. Є деяка безліч M точок рівномірної сітки {tm},
m = 1,М и tm=T с шагом 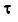 , яка ділиться на N блоків. Кожен блок має k точок. N<=M.
, яка ділиться на N блоків. Кожен блок має k точок. N<=M.
Пусть i=0.
k – номер кожної точки в кожному блоці n;
tn,i – точка з номером i, яка належить блоку n.
tn,0 – початкова точка n-го блока.
tn,k – кінцева точка.
Звідси видно, що має місце рівність tn,k =tn+1,0. Також в блок не включається початкова точка t0=t1,0. При чисельному рішенні задачі Коші на кожному кроці одночасно отримуємо нові k значень функції і саме тому блочні методи досить добре реалізуються у паралельних ОС[6].

")
Пусть un,0 – значення рішення завдання Коші в точці tn,0 – начальна точке блока, що опрацьовується. Припустимо, що в одному блоці всі точки сітки знаходяться на рівних відстанях, тобто tn,i = tn,0+it. Тоді рівняння однокрокових блочних різнистних методів для блоку з k точок може бути записано у вигляді:
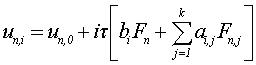
Для визначення коефіцієнтів ai,j и bi треба побудувати інтерполяційний многочлен Лагранжа Lk(t) з вузлами інтерполяції tn,i, i= 0,1,…,k та відповідними їм значеннями Fn,i=f(tn,i, un,i)[6]. Далі потрібно проінтегріровать його в межах (tn, tn + ih), i=1..k:
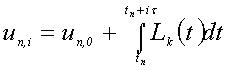

Формули для трехточечного блочного методу:
Побудуємо інтерполяційний многочлен L3(t) з вузлами інтерполяції tn,i, i = 0,1,2,3 та відповідними їм значеннями правих частин рівняння Fn,i=f(tn,i, un,i), а далі проінтегруємо його в відповідних межах.[6] Використовуючи пакет Mathematica, отримаємо формули:
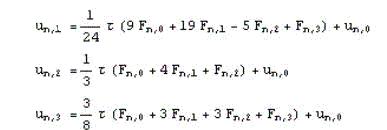
Формулы, які отримали для трехточечного блочного методу, визначають значення приблизного рішення неявно, а це значає, що виникає необхідність вирішення системи рівнянь щодо un,1, un,2 и un,3. даній ситуації ми можемо отримати не одну точку за крок, а відразу k точок за один крок.
Похибка апроксімації
Однокрокой k-точечний блочний метод має найвищий порядок апроксімації, який дорівнює k+1.[8] А похибка має вигляд:
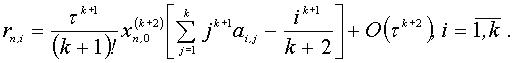
Головний член локальної похибки буде:
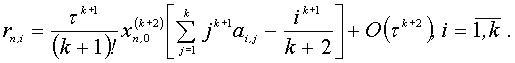
Паралельна реалізація неявних блочних однокрокових методів чисельного рішення жерсткої задачі Коші
Дослідження методів вирішення динамічних задач із зосередженими параметрами показало, що паралельні властивості таких методів багато в чому визначаються видом чисельної схеми, покладеної в їх основу. Найменш трудомісткими є явні методи, проте властиві цим схемам недоліки, зокрема умовна стійкість, істотно обмежують сферу їх застосування. В зв'язку з цим значний інтерес представляють неявні схеми, які, не дивлячись на велику обчислювальну складність, не мають альтернативи серед однокрокових методів при вирішенні жорстких задач [1].
Розглядається чисельне розв’язання задачі Коші, асоційоване з вирішенням систем звичайних диференційних рівнянь (СЗДР) першого порядку з відомими початковими умовами:

де права частина системи є в загальному випадку нелінійна функція, яка задає відображення
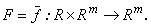
Задля керування кроком інтегрування для однокрокових блокових методів може бути використана ідея вкладених форм, що була запропонована для оцінки локальної похибки чисельного розв’язання звичайних диференціальних рівнянь методами Рунге-Кути. У даному докладі приведено обґрунтування застосування цього способу оцінки похибки для паралельних вкладених блокових алгоритмів рішення нелінійної задачі Коші для ОДУ на основі наступного підходу: комбінації незалежних формул суміжних порядків точності розв’язку.
Підхід полягає у використанні двох різних незалежних блокових методів суміжних порядків точності
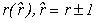 на одній і тій же сітці інтегрування
на одній і тій же сітці інтегрування
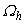 :
:
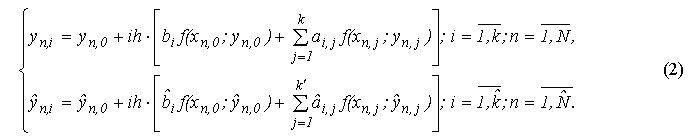
При цьому перший метод визначає апроксимацію вирішення на основі
k - точкового однокрокового методу, а другий 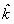 - точкового також однокрокового методу. Другий наближений розв’язок в співпадаючих вузлах блоків
- точкового також однокрокового методу. Другий наближений розв’язок в співпадаючих вузлах блоків
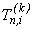 і
і
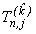 сітки
використовується для оцінки апостеріорної локальної похибки. Нехай для визначеності основним є блоковий метод нижчого порядку точності, тобто
сітки
використовується для оцінки апостеріорної локальної похибки. Нехай для визначеності основним є блоковий метод нижчого порядку точності, тобто
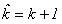 . Локальна похибка наближеного розв’язку за однокроковим k-точковим методом в i-том вузлі блоку для одного рівняння визначається наступною формулою:
. Локальна похибка наближеного розв’язку за однокроковим k-точковим методом в i-том вузлі блоку для одного рівняння визначається наступною формулою:
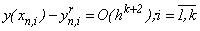 , і для (k+1)- точкового методу в тому ж вузлі дорівнює:
, і для (k+1)- точкового методу в тому ж вузлі дорівнює:
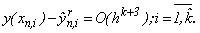 З отриманих співвідношень виходить, що оцінка локальної похибки формули меншого порядку точності, k-точкового методу, приблизно може бути обчислена, як:
З отриманих співвідношень виходить, що оцінка локальної похибки формули меншого порядку точності, k-точкового методу, приблизно може бути обчислена, як:
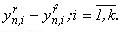 Такий підхід до оцінки локальної похибки є ефективнішим в порівнянні з правилом Рунге, оскільки при достатній простоті дозволяє зменшити обчислювальні витрати. Так, для вживання правила дублювання кроку необхідно вирішити три системи нелінійних алгебраїчних рівнянь розмірності k,
а для застосування вкладеного методу дві системи: одну тієї же розмірності, другу розмірності (k+1) .
Такий підхід до оцінки локальної похибки є ефективнішим в порівнянні з правилом Рунге, оскільки при достатній простоті дозволяє зменшити обчислювальні витрати. Так, для вживання правила дублювання кроку необхідно вирішити три системи нелінійних алгебраїчних рівнянь розмірності k,
а для застосування вкладеного методу дві системи: одну тієї же розмірності, другу розмірності (k+1) .
Потенційно вкладені блокові методи володіють високим ступенем внутрішнього паралелізму: практично лінійним прискоренням і одиничною ефективністю. Це витікає з приведених нижче співвідношень для коефіцієнтів потенційного прискорення і ефективності алгоритму у випадку, якщо час звернення до правої частини ОДУ домінує над іншими обчисленнями:
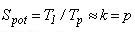 ,
,
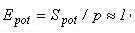 ,
,
де k - число точок у блоці, а p - число використаних процесорів.
Аналогічний результат маємо для тривіальної правої частини. Відмітимо, що вплив чинника “складність правої частини ОДУ” є таким, що багато в чому визначає якість паралелізму. При однакових значеннях комунікаційних констант і параметрів, які задають унікальний блоковий метод, коефіцієнти прискорення і ефективності зменшуються практично в два рази при переході від домінуючих до тривіальних правих частин. Аналіз теоретичного виконання і обчислювальний експеримент показують, що для виконання групових обмінних операцій в запропонованому алгоритмі ефективними є топології гиперкуб і тор, гірший варіант з'єднання процесорів – кільце.
Окрім топології з'єднання, на величину часу міжпроцесорних обмінів і динамічні характеристики паралелізму істотний вплив мають тип паралельної архітектури і визначені їм машино-залежні константи обміну, такі, як латентність і час передачі одного слова. Відмітимо, що із зростанням величини латентності комунікаційної середи час на реалізацію обмінів збільшується, а прискорення і ефективність алгоритму зменшуються. Аналогічні залежності зв'язують динамічні характеристики і час передачі одного слова. Проте величина латентності є найбільш істотним параметром, ступінь впливу швидкості передачі даних, як правило, зростає при збільшенні об'ємів переданих даних. Отже, ступінь впливу комунікаційних констант традиційний для даних методів і операцій обміну. Збільшення числа точок в блоці приводить до зростання коефіцієнту прискорення
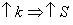 та к зменшенню коефіцієнту ефективності
та к зменшенню коефіцієнту ефективності
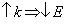 . Така залежність пояснюється тим, що число точок блоку пов'язане з числом використовуваних процесорів.
. Така залежність пояснюється тим, що число точок блоку пов'язане з числом використовуваних процесорів.
Підсумовуючи всі теоретичні результати та отримані експериментальні залежності, можна зробити висновок, що метод вкладених форм для блокових однокрокових способів рішення нелінійної задачі Коші для ОДУ володіє безперечними перевагами перед правилом Рунге та локальною екстраполяцією.
Оцінка ефективності
Для оцінки эфективності реалізації, яку отримаємо при застосуванні паралельного методу необхідно знати його прискорення і коефіцієнт паралелізму.[10]
Введемо позначення:
tf – час обчислення функції f(t,x);
tсл – час виконання операції складання;
tум – час виконання операції множення;
tоб – час передачі числа процесору-сусіду.
Час обчислення на одному процесорі з точністю O(tk+1) у всіх k вузлах блоку по формулам
Рунге-Кутта k +1 порядку точності одно
T1=k(k+1)tf+k2(tсл+tум)
Час паралельного обчислення на k процесорах наближених значень рішення у всіх k вузлах блоку дорівнює
Tk=(k+1)tf+k2(tсл+tум)+k(k+1)tоб.
Тоді прискорення паралельного одношагового k-точечного алгоритму дорівнює
W(k)=T1/k=(k+1)2/k=k.
Коефіцієнт ефективності паралельного алгоритму обчислюється за формулою
E(k)=W(k)/Nпроц
Де Nпроц – кількість використовуваних процесорних елементів. У нашому випадку
Nпроц=k (7)
Тому E(k) приблизно дорівнює 1.
Висновки
Практичне використання більшості методів чисельного інтегрування диференціальних рівнянь, які орієнтовані на обчислювальні системи з паралельною архітектурою не завжди виправдано, оскільки багато з них або мають чисельну нестійкість, або мають дуже складну структуру, що призводить до втрати ефективності. До методів, позбавленим зазначених недоліків, можна віднести блочні. k точечний однокроковий блочний метод - метод, де для блоку k точок нові k значень функції обчислюються одночасно. Ця особливість методів, по-перше, узгоджується з архітектурою паралельних обчислювальних систем, а, по-друге, дозволяє обчислювати коефіцієнти різнистних формул не в процесі інтегрування, а на етапі розробки методу, що значно збільшує ефективність розрахунків. У подальшій роботі я планую перейти до розв'язання систем звичайних диференціальних рівнянь блочними методами.
Зауваження
При написанні цього реферату магістерська робота ще не завершена. Остаточне завершення: грудень 2009р. Повний текст роботи та матеріали за темою можуть бути отримані у автора або керівника після закінчення вказаного сроку.
Литература
- Воеводин В.В. Математические основы параллельных вычислений. – М.: МГУ, 1991. – 345 с.
- Воеводин В.В., Воеводин Вл.В. Параллельные вычисления. – СПб.: БХВ – Петербург, 2002. – 540 c.
- Информационно-аналитический центр по параллельным вычислениям www.parallel.ru
- Хокни Р., Джессхоуп К. Параллельные ЭВМ: Архитектура, программирование и алгоритмы. – М.: Радио и связь, 1986. – 392 с.
- Гергель В.П., Стронгин, Р.Г. Основы параллельных вычислений для многопроцессорных вычислительных систем. Учебное пособие – Нижний Новгород: Изд-во ННГУ им. Н.И. Лобачевского, 2003. – 184 с.
- Фельдман Л.П. Сходимость и оценка погрешности параллельных одношаговых блочных методов моделирования динамических систем с сосредоточенными параметрами //Науковi працi Донецького державного технiчного унiверситету. Серiя: Проблеми моделювання та автоматизації проектування динамичних систем, випуск 15: – Донецк: ДонГТУ, 2000. – с. 12 – 16.
- Фельдман Л.П., Святный В.А. Параллельные алгоритмы моделирования динамических систем, описываемых обыкновенными дифференциальными уравнениями. // Научн. тр. ДонГТУ, вып. 6.– Донецк: ДонГТУ, 1999. – 330 с.
- Ортега Дж., Пул У. Введение в численные методы решения дифференциальных уравнений: пер. с англ.; под ред. Абрамова А.А. – М.: Наука. Гл. ред. физ.-мат. лит., 1986. – 288 с.
- Хайрер Э., Нёрсетт С., Ваннер Г. Решение обыкновенных дифференциальных уравнений. Нежесткие задачи: пер. с англ. – М.: Мир, 1990. – 512 с.
- Фельдман Л.П., Дмитриева О.А. Эффективные методы распараллеливания численного решения задачи Коши для обыкновенных дифференциальных уравнений // Математическое моделирование. – М.: 2001. – Т.13, № 7. – с. 66-72.
- Самарский А.А., Гулин А.В. Численные методы. – М.: Наука. Гл. ред. физ.-мат. лит., 1989. – 432 с.