
Факультет: Вычислительной техники и информатики
Кафедра: Прикладной математики и информатики
Специальность: Программное обеспечение автоматизированных систем
Тема магистерской работы: Исследование эффективности параллельных
одношаговых алгоритмов решения задачи Коши для ОДУ
Руководитель: д.т.н., профессор, Фельдман Л.П.
Реферат
Библиотека
Ссылки
Отчет о поиске
Биография
Инд. задание
Реферат по теме: «Исследование эффективности параллельных
одношаговых алгоритмов решения задачи Коши для ОДУ»
Введение
Идея распараллеливания вычислений базируется на том, что большинство задач может быть разделено на набор меньших задач, которые могут быть решены одновременно. Параллельные вычисления использовались много лет в основном в высокопроизводительных вычислениях, но в последнее время к ним возрос интерес вследствие существования физических ограничений на рост тактовой частоты процессоров.
Появление в последние годы большого количества сравнительно дешевых кластерных параллельных вычисленных систем привело к быстрому развитию параллельных вычислительных технологий, в том числе и в области высокопроизводительных вычислений. В последнее время ситуация в области параллельных вычислительных технологий начала кардинально меняться в связи с тем, что большинство основных производителей микропроцессоров стало переходить на многоядерные архитектуры. Изменение аппаратной базы заставляет менять и подходы к построению параллельных алгоритмов. Для реализации вычислительных возможностей многоядерных архитектур требуется разработка новых параллельных алгоритмов, учитывающих новые технологии. Эффективность использования вычислительных ресурсов, которой будут обладать кластеры нового поколения, напрямую будет зависеть от качества собственно параллельных приложений, так и специализированных библиотек численных алгоритмов, ориентированных на многоядерные архитектуры.
Актуальность данной темы: Постоянные исследования в области разработки и создания высокопроизводительных вычислительных средств позволяют решать фундаментальные и прикладные задачи. Производительности современных ЭВМ недостаточно для обеспечения нужного решения многих задач. Один из наиболее эффективных способов повышения производительности заключается в распараллеливании вычислений в многопроцессорных и параллельных структурах. Моделирование реальных экономических, технических и других процессов, описываемых системами обыкновенных дифференциальных уравнений (СОДУ) большой размерности, представляет собой обширный класс задач, для решения которых применение высокопроизводительной вычислительной техники не только оправдано, но и необходимо.
Один из наиболее эффективных способов повышения производительности заключается в распараллеливании вычислений в многопроцессорных и параллельных структурах. Вследствие чего, применение параллельных вычислительных систем является довольно важным направлением развития вычислительной техники.
В последнее время появилось большое количество численных методов интегрирования дифференциальных уравнений, которые ориентированы на вычислительные системы с параллельной архитектурой. Однако практическое использование большинства методов не всегда оправдано, поскольку многие из них либо обладают численной неустойчивостью, либо имеют очень сложную структуру, приводящую к потере эффективности. К методам, лишенным указанных недостатков, можно отнести блочные. Блочным будем называть метод, при котором для блока из k точек новые k значений функции вычисляются одновременно. Эта особенность методов, во-первых, согласуется с архитектурой параллельных вычислительных систем, а, во-вторых, позволяет вычислять коэффициенты разностных формул не в процессе интегрирования, а на этапе разработки метода, что значительно увеличивает эффективность счета. Однако, при всех их достоинствах эти методы рассмотрены довольно мало. Информация, в основном, защищена и недоступна без регистрации или оплаты.
Цель и задачи данной работы: исследование, сравнение, усовершенствование и определение оптимальных параллельных одношаговых алгоритмов решения задачи Коши для ОДУ для определенного вида вычислительной схемы. Следует учитывать, что метод должен обладать численной устойчивостью, иметь оптимальную для сохранения эффективности структуру и время решения, и, соответственно, время моделирования. Чтобы сделать вывод о целесообразности реализации и выгоде, получаемой при применении параллельного метода, необходимо знать его ускорение и коэффициент параллелизма.
Анализ развития параллельных вычислений
Вычисления называются параллельными, если в один и тот же момент времени выполняются одновременно несколько операций обработки данных[1]. Можно ускорить процесс решения задачи при помощи разделения используемого алгоритма на некоторые независимые части, которые будут выполняться на отдельных процессорах. Однако параллелизм до сих пор не получил широкого распространения. Это обусловлено следующими факторами[2]:
- Высокая стоимость параллельных вычислительных систем. В соответствии с законом Гроша, производительность компьютера возрастает пропорционально квадрату его стоимости и, следовательно, более выгодно получить требуемую вычислительную мощность приобретением одного производительного процессора, чем использование нескольких менее быстродействующих процессоров. Но, следует учесть, что рост быстродействия последовательных ЭВМ не может продолжаться бесконечно, кроме того, даже наиболее мощные компьютеры подвержены быстрому моральному старению. Тенденция же построения высокопроизводительных комплексов из типовых элементов: микропроцессоров, микросхем памяти, коммуникационных устройств, массовый выпуск которых освоен промышленностью, сильно снижает влияние этого фактора[1].
- Потери производительности для организации параллелизма – согласно гипотезе Минского, ускорение, достигаемое при использовании параллельной системы, пропорционально двоичному логарифму от числа процессоров, то есть при 1000 процессорах возможное ускорение оказывается равным 10. При этом существует большое количество задач, параллельное решение которых достигается 100% использование всех имеющихся процессоров параллельной вычислительной системы.
- Постоянное совершенствование последовательных компьютеров – в соответствии с законом Мура мощность последовательных процессоров возрастает практически в два раза каждые 18–24 месяцев и, как результат, необходимая производительность может быть достигнута и на обычных последовательных компьютерах. Стоит отметить, что аналогичное развитие свойственно и параллельным системам[5, c. 3-4].
- Существование последовательных вычислений – в соответствии с законом Амдаля [3] ускорение процесса вычислений при использовании р процессоров ограничивается величиной
- Зависимость эффективности параллелизма от учета характерных свойств параллельных систем – в отличие от единственности классификации схемы фон Неймана последовательных ЭВМ параллельные системы отличаются существенным разнообразием архитектурных принципов построения, и максимальный эффект от использования параллелизма может быть получен только при полном использовании всех особенностей аппаратуры. Следовательно, перенос параллельных алгоритмов и программ между разными типами систем становится затруднительным. С другой стороны, при всем разнообразии архитектур параллельных систем, тем не менее, существуют и определенные способы обеспечения параллелизма.
- Существующее программное обеспечение ориентировано в основном на последовательные ЭВМ[4]. Но, если последовательные программы не позволяют получать решения новых задач за приемлемое время или же возникает необходимость решения новых задач, то необходимой становится разработка нового программного обеспечения, и эти программы могут быть реализованы в параллельном варианте.
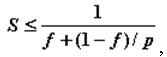
где f есть доля последовательных вычислений в применяемом алгоритме обработке данных. Однако, часто доля последовательных действий характеризует не возможность параллельного решения задач, а последовательные свойства применяемых алгоритмов. И, следовательно, доля последовательных вычислений может быть существенно снижена при выборе более подходящих для распараллеливания алгоритмов.
При выполнении параллельных вычислений в МВС для организации взаимодействия, синхронизации и взаимоисключения параллельно выполняемых процессов используется передача данных между процессорами вычислительной среды. Временные задержки при передаче данных по линиям связи могут оказаться существенными (по сравнению с быстротой процессоров) и, как результат, коммуникационная трудоемкость алгоритма оказывает существенное влияние на выбор параллельных способов решения задач.
Топологии
К числу типовых топологий обычно относят следующие схемы: линейка, кольцо, решетка, тор, гиперкуб, клика, звезда.[5]
- линейка (linear array or farm) - система, в которой каждый процессор имеет линии связи только с двумя соседними (с предыдущим и последующим) процессорами; такая схема является, с одной стороны, просто реализуемой, а с другой стороны, соответствует структуре передачи данных при решении многих вычислительных задач (например, при организации конвейерных вычислений);
- кольцо (ring) - данная топология получается из линейки процессоров соединением первого и последнего процессоров линейки;
- звезда (star) - система, в которой все процессоры имеют линии связи с некоторым управляющим процессором; данная топология является эффективной, например, при организации централизованных схем параллельных вычислений;
- полный граф (completely-connected graph or clique)- система, в которой между любой парой процессоров существует прямая линия связи; как результат, данная топология обеспечивает минимальные затраты при передаче данных, однако является сложно реализуемой при большом количестве процессоров;
- решетка (mesh) - система, в которой граф линий связи образует прямоугольную сетку (обычно двух- или трех- мерную); подобная топология может быть достаточно просто реализована и, кроме того, может быть эффективно используема при параллельном выполнении многих численных алгоритмов (например, при реализации методов анализа математических моделей, описываемых дифференциальными уравнениями в частных производных);
- гиперкуб (hypercube) - данная топология представляет частный случай структуры решетки, когда по каждой размерности сетки имеется только два процессора (т.е. гиперкуб содержит 2N процессоров при размерности N); данный вариант организации сети передачи данных достаточно широко распространен в практике и характеризуется следующим рядом отличительных признаков:
1) два процессора имеют соединение, если двоичное представление их номеров имеет только одну различающуюся позицию;
2) в N-мерном гиперкубе каждый процессор связан ровно с N соседями;
3) N-мерный гиперкуб может быть разделен на два (N–1)-мерных гиперкуба (всего возможно N различных таких разбиений);
4) кратчайший путь между двумя любыми процессорами имеет длину, совпадающую с количеством различающихся битовых значений в номерах процессоров (данная величина известна как расстояние Хэмминга). Реальные высокопроизводительные параллельные вычислительные системы обычно используют несколько различных схем соединения процессоров. Это позволяет сочетать лучшие качества известных топологий и минимизировать недостатки. Другим способом улучшить характеристики схем коммутации является построение систем с изменяемой конфигурацией. Изменять шаблон соединений можно как статически (до выполнения программы), так и динамически (в ходе ее выполнения).
Последовательный метод
В общем случае методы Рунге-Кутта записывают в виде
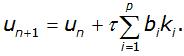
Здесь:
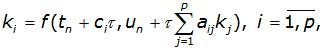
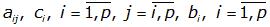 – константы
– константы
Число p, показывающее количество вспомогательных точек kj, используемых для вычисления основной точки ki, называется порядком метода.

Параллельные одношаговые блочные методы
Рассмотрим решение задачи Коши для одного обыкновенного дифференциального уравнения первого порядка
одношаговым блочным методом. Есть некоторое множество M точек равномерной сетки {tm},
m = 1,М и tm=T с шагом 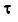 , которое разбивается на N блоков. Каждый блок содержит k точек. N<=M.
, которое разбивается на N блоков. Каждый блок содержит k точек. N<=M.
Пусть i=0.
k – номер каждой точки в каждом блоке n;
tn,i – точка с номером i, принадлежащая блоку n.
tn,0 – начальная точка n-го блока.
tn,k – конечная точка.
Отсюда видно, что имеет место равенство tn,k =tn+1,0. Также в блок не включается начальная точка t0=t1,0. При численном решении задачи Коши на каждом шаге одновременно получаем новые k значений функции и именно поэтому блочные методы достаточно хорошо реализуются в параллельных ВС[6].

")
Пусть un,0 – приближенное значение решения задачи Коши в точке tn,0 – начальной точке обрабатываемого блока. Предположим, что в одном блоке все точки сетки находятся на равных расстояниях, т.е. tn,i = tn,0+it. Тогда уравнения одношаговых блочных разностных методов для блока из k точек может быть записано в виде:
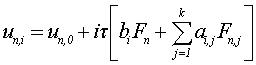
Для определения коэффициентов ai,j и bi нужно построить интерполяционный многочлен Лагранжа Lk(t) с узлами интерполяции tn,i, i= 0,1,…,k и соответствующими им значениями Fn,i=f(tn,i, un,i)[6]. Далее требуется проинтегрировать его в пределах (tn, tn + ih), i=1..k:
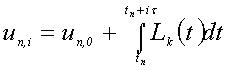

Формулы для трехточечного блочного метода:
Построим интерполяционный многочлен L3(t) с узлами интерполяции tn,i, i = 0,1,2,3 и соответствующим им значениям правой части уравнения Fn,i=f(tn,i, un,i) и далее проинтегрируем его в соответствующих пределах.[6] Используя пакет Mathematica, получим искомые формулы:
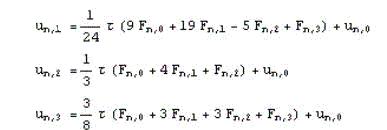
Формулы, которые были получены для трехточечного блочного метода, определяют значение приближенного решения неявно, а это значит, что возникает необходимость решения системы уравнений относительно un,1, un,2 и un,3. В данной ситуации мы можем получить не одну точку за шаг, а сразу k точек за один шаг.
Погрешность аппроксимации
Одношаговый k-точечный блочный метод имеет наивысший порядок аппроксимации, равный k+1.[8] А погрешность рассматриваемого метода имеет вид:
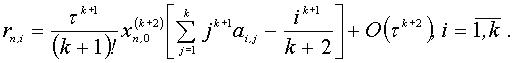
Главный член локальной погрешности будет:
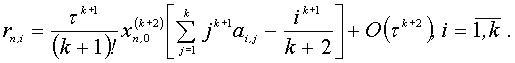
Параллельная реализация неявных блочных одношаговых методов численного решения жесткой задачи Коши
Исследование методов решения динамических задач с сосредоточенными параметрами показало, что параллельные свойства таких методов во многом определяются видом численной схемы, положенной в них основу. Наименее трудоемкими являются явные методы, однако присущие этим схемам недостатки, в частности условная стойкость, существенным образом ограничивают сферу их применения. В связи с этим значительный интерес представляют неявные схемы, которые, не смотря на большую вычислительную сложность, не имеют альтернативы среди одношаговых методов при решении жестких задач [9].
Рассматривается численное решение задачи Коши, ассоциированное с решением систем обычных дифференциальных уравнений (СОДУ) первого порядка с известными начальными условиями:

где правая часть системы является в общем случае нелинейной функцией, которая задает отображение
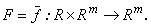
Ради управления шагом интегрирования для одношаговых блочных методов может быть использована идея вложенных форм, которая была предложена для оценки локальной погрешности численного решения обычных дифференциальных уравнений методами Рунге-Кутты. В данном докладе приведено обоснование применения этого способа оценки погрешности для параллельных вложенных блочных алгоритмов решения нелинейной задачи Коши для ОДУ на основе следующего подхода: комбинации независимых формул смежных порядков точности решения.
Подход состоит в использовании двух разных независимых блочных методов смежных порядков точности
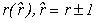 на одной и той же сетке интегрирования
на одной и той же сетке интегрирования
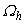 :
:
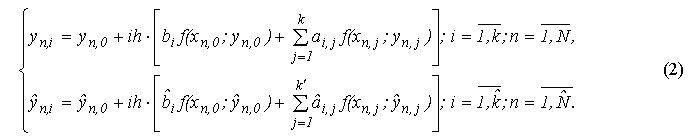
При этом первый метод определяет аппроксимацию решения на основе
k - точечного одношагового метода, а второй 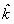 - точечного тоже одношагового метода. Другое приближенное решение в совпадающих узлах блоков
- точечного тоже одношагового метода. Другое приближенное решение в совпадающих узлах блоков
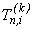
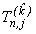 сетки
используется для оценки апостериорной локальной погрешности. Пусть для определенности основным является блоковый метод низкого порядка точности, т.е.
сетки
используется для оценки апостериорной локальной погрешности. Пусть для определенности основным является блоковый метод низкого порядка точности, т.е.
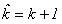 . Локальная погрешность приближенного решения одношаговым k- точечным методом в i- том узле блока для одного уравнения определяется следующей формулой:
. Локальная погрешность приближенного решения одношаговым k- точечным методом в i- том узле блока для одного уравнения определяется следующей формулой:
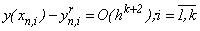 , и для (k+1)- точечного метода в том же узле равняется:
, и для (k+1)- точечного метода в том же узле равняется:
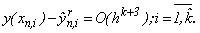 Из полученных соотношений получается, что оценка локальной погрешности формулы меньшего порядка точности, k- точечного метода, приблизительно может быть вычисленная, как:
Из полученных соотношений получается, что оценка локальной погрешности формулы меньшего порядка точности, k- точечного метода, приблизительно может быть вычисленная, как:
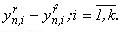 Такой подход к оценки локальной погрешности является более эффективным в сравнении с правилом Рунге, поскольку при достаточной простоте позволяет уменьшить вычислительные затраты. Так, для использования правила дублирования шага необходимо решить три системы нелинейных алгебраических уравнений размерности k,
а для применения вложенного метода две системы: одну той же размерности, другу размерности (k+1) .
Такой подход к оценки локальной погрешности является более эффективным в сравнении с правилом Рунге, поскольку при достаточной простоте позволяет уменьшить вычислительные затраты. Так, для использования правила дублирования шага необходимо решить три системы нелинейных алгебраических уравнений размерности k,
а для применения вложенного метода две системы: одну той же размерности, другу размерности (k+1) .
Потенциально вложенные блочные методы владеют высокой степенью внутреннего параллелизма: практически линейным ускорением и единичной эффективностью. Это вытекает из приведенных ниже соотношений для коэффициентов потенциального ускорения и эффективности алгоритма в случае, если время обращения к правой части ОДУ доминирует над другими вычислениями:
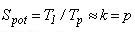 ,
,
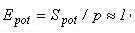 ,
,
где k - число точек в блоке, а p - число использованных процессоров.
Аналогичный результат имеем для тривиальной правой части. Отметим, что влияние фактора "сложность правой части ОДУ" является таким, что во многом определяет качество параллелизма. При одинаковых значениях коммуникационных констант и параметров, которые задают уникальный блочный метод, коэффициенты ускорения и эффективности уменьшаются практически в два раза при переходе от доминирующих к тривиальным правым частям. Анализ теоретического выполнения и вычислительный эксперимент показывают, что для выполнения групповых обменных операций в предложенном алгоритме эффективными являются топологии гиперкуб и тор, худший вариант соединения процессоров – кольцо.
Кроме топологии соединения, на величину времени межпроцессорных обменов и динамические характеристики параллелизма существенное влияние имеют тип параллельной архитектуры и определенные им машинно-зависимые константы обмена, такие, как латентность и время передачи одного слова. Отметим, что с ростом величины латентности коммуникационной среды время на реализацию обменов увеличивается, а ускорение и эффективность алгоритма уменьшаются. Аналогичные зависимости связывают динамические характеристики и время передачи одного слова.
Однако величина латентности является наиболее существенным параметром, степень влияния скорости передачи данных, как правило, возрастает при увеличении объемов переданных данных. Поэтому, степень влияния коммуникационных констант традиционная для данных методов и операций обмена. Увеличение числа точек в блоке приводит к росту коэффициента ускорения
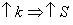 и к уменьшению коэффициента эффективности
и к уменьшению коэффициента эффективности
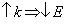 . Такая зависимость объясняется тем, что число точек блока связано с числом используемых процессоров.
. Такая зависимость объясняется тем, что число точек блока связано с числом используемых процессоров.
Подытоживая все теоретические результаты и полученные экспериментальные зависимости, можно сделать вывод, что метод вложенных форм для блочных одношаговых способов решения нелинейной задачи Коши для ОДУ владеет бесспорными преимуществами перед правилом Рунге и локальной экстраполяцией.
Оценка эффективности
Для оценки эффективности реализации и выгоде, получаемой при применении параллельного метода необходимо знать его ускорение и коэффициент параллелизма.[10]
Введем обозначения:
tf – время вычисления значения функции f(t,x);
tсл – время выполнения операции сложения;
tум – время выполнения операции умножения;
tоб – время передачи числа соседнему процессору.
Время вычисления на одном процессоре с точностью O(tk+1) во всех k узлах блока по формулам
Рунге-Кутта k+1 порядка точности равно
T1=k(k+1)tf+k2(tсл+tум)
Время параллельного вычисления на k процессорах приближенных значений решения во всех k узлах блока равно
Tk=(k+1)tf+k2(tсл+tум)+k(k+1)tоб.
Тогда ускорение параллельного одношагового k-точечного алгоритма равно
W(k)=T1/k=(k+1)2/k=k.
Коэффициент эффективности параллельного алгоритма вычисляется по формуле
E(k)=W(k)/Nпроц
Здесь Nпроц – количество используемых процессорных элементов. В нашем случае
Nпроц=k (7)
Поэтому E(k) примерно равно 1.
Выводы
Практическое использование большинства методов численного интегрирования дифференциальных уравнений, которые ориентированы на вычислительные системы с параллельной архитектурой не всегда оправдано, поскольку многие из них либо обладают численной неустойчивостью, либо имеют очень сложную структуру, приводящую к потере эффективности. К методам, лишенным указанных недостатков, можно отнести блочные. k точечный одношаговый блочный метод – метод, при котором для блока k точек новые k значений функции вычисляются одновременно. Эта особенность методов, во-первых, согласуется с архитектурой параллельных вычислительных систем, а, во-вторых, позволяет вычислять коэффициенты разностных формул не в процессе интегрирования, а на этапе разработки метода, что значительно увеличивает эффективность счета. В дальнейшей работе я планирую перейти к решению систем обыкновенных дифференциальных уравнений блочными методами. А также создать пакет, расширяющий функциональные возможности пакета Mathematica при решении и оценке эффективности задачи Коши для ОДУ.
Замечание
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: декабрь 2009г. Полный текст работы и материалы по теме могут быть получены у автора или руководителя после указанной даты.
Литература
- Воеводин В.В. Математические основы параллельных вычислений. – М.: МГУ, 1991. – 345 с.
- Воеводин В.В., Воеводин Вл.В. Параллельные вычисления. – СПб.: БХВ – Петербург, 2002. – 540 c.
- Информационно-аналитический центр по параллельным вычислениям www.parallel.ru
- Хокни Р., Джессхоуп К. Параллельные ЭВМ: Архитектура, программирование и алгоритмы. – М.: Радио и связь, 1986. – 392 с.
- Гергель В.П., Стронгин, Р.Г. Основы параллельных вычислений для многопроцессорных вычислительных систем. Учебное пособие – Нижний Новгород: Изд-во ННГУ им. Н.И. Лобачевского, 2003. – 184 с.
- Фельдман Л.П. Сходимость и оценка погрешности параллельных одношаговых блочных методов моделирования динамических систем с сосредоточенными параметрами //Науковi працi Донецького державного технiчного унiверситету. Серiя: Проблеми моделювання та автоматизації проектування динамичних систем, випуск 15: – Донецк: ДонГТУ, 2000. – с. 12 – 16.
- Фельдман Л.П., Святный В.А. Параллельные алгоритмы моделирования динамических систем, описываемых обыкновенными дифференциальными уравнениями. // Научн. тр. ДонГТУ, вып. 6.– Донецк: ДонГТУ, 1999. – 330 с.
- Ортега Дж., Пул У. Введение в численные методы решения дифференциальных уравнений: пер. с англ.; под ред. Абрамова А.А. – М.: Наука. Гл. ред. физ.-мат. лит., 1986. – 288 с.
- Хайрер Э., Нёрсетт С., Ваннер Г. Решение обыкновенных дифференциальных уравнений. Нежесткие задачи: пер. с англ. – М.: Мир, 1990. – 512 с.
- Фельдман Л.П., Дмитриева О.А. Эффективные методы распараллеливания численного решения задачи Коши для обыкновенных дифференциальных уравнений // Математическое моделирование. – М.: 2001. – Т.13, № 7. – с. 66-72.
- Самарский А.А., Гулин А.В. Численные методы. – М.: Наука. Гл. ред. физ.-мат. лит., 1989. – 432 с.