
Julia Mishchuk
Faculty:
Computer Science and Technology
Speciality:
Software engineering
Master's work topic:
Perfomance analysis of computer systems using Markov model
Supervisor:
Prof. Feldman L.P.
Summary on the topic of graduation:
"Analysis of the effectiveness of computer systems using Markov model"
Aims:
- Review and analysis of modern computing systems.
- Review methods of computer systems analysis.
- Develop the model of homogeneous cluster with the common disk space.
- Implement program model using parallel systems.
- Assess the effectiveness of implementation.
Relevance
The need to increase the calculated capacity in many areas of human activity, active development of algorithms for improving the work of computing systems - data processing systems are configured to address the challenges specific application. Fundamental to the theory of computing systems are models and apparatus of the theory of Markov processes.
The concept of high-performance system architecture is broad enough, since the architecture can be understood and the method of parallel data processing used in the system, and the organization of memory, and the topology of communication between processors, and the manner of execution of the system of arithmetic operations. We consider a cluster architecture multiprocessor systems [1]. Given the complexity and large amounts of data, Markov models have not been used in large systems, therefore the task is urgent [2]. This work should examine the effectiveness of parallelizing the method and find out how accelerated simulation of multiprocessor systems [3].
Scientific significance
Creation and use of modern supercomputer systems has become one of the main trends in the leading countries of the world nowadays. One of the main problems encountered in the design and operation of parallel and distributed computing systems (CS) is to advise the management of resources, the computing environment. One effective way to solve this problem would be to use the results of continuous or discrete analytical models [4].
Review of research and development on the subject
There are a number of industries (such as: Earth sciences (atmospheric physics, meteorology, climatology, physical oceanography); mathematical linguistics (speech recognition, text analysis), biology, ecology, economics, social sciences, computer science (distributed computing, pattern recognition images, maintain database); medicine, pharmaceutics, etc.), so there is need to address large amounts of computations in a reasonable time countable [5].
The growth of computing power, the emergence of modern supercomputers, clusters of workstations, the constant improvement of computer power systems leads to the fact that the tasks that have in the recent past could not be solved in real time, successfully solved through the use of parallel algorithms implemented on multiprocessor systems with high performance.
Therefore, active development of algorithms for improving the work of computer systems. Work in this direction do not lose their relevance and require further development, finding new solutions.
On these issues involved:
- Doctor of Technical Sciences, professor, L. Feldman,
- Candidate of technical sciences, docent T. Mikhailova,
- Candidate of technical sciences, docent Y. Ladyzhenskiy
Tatiana Dyachenko (Supervisor: Ph.D. Mathematical Sciences, docent Datsun Natalia N.)
Theme Master's thesis: "Research of the parallel algorithm for Markov models of computer systems"Olga Kucherenosova (Supervisor: Prof. Bashkov Eugene A.)
Theme Master's thesis: "Efficiency research of parallel computing system"Eugene Altynpara (Supervisor: Ph.D., docent Ladyzhenskii Yuri V.)
Theme Master's thesis: "Meeting the challenges of large-scale on the cluster"Roman Morozov (Supervisor:Ph.D., docent Ladyzhenskii Yuri V.)
Theme Master's thesis: "Portioned algorithms of solving of the problems of high dimensionality on computing claster"Dmitriy Zavalkin (Supervisor: Doctor of Technical Sciences Professor Feldman Lev P.)
Theme Master's thesis: "The Analysis and Estimation of Efficiency of Parallel Difference Methods of Solution the ODE on a Cluster"Al'masri Mohammed Rida (Supervisor: Ph.D., docent Ladyzhenskii Yuri V.)
Theme Master's thesis: "Parallel methods for solving systems of linear algebraic equations on a computer cluster"
General concepts
Structure of computer system — a combination of elements and their relationships. As the elements of a computer system are the individual computers and processors.
There are number of grounds on which classified computing systems: their purpose and function, by type and number of computers or processors, by architecture of the system.
In 1966, Michael Flynn (Flynn) was offered an extremely convenient approach to the classification of computer architecture [6]. The basis was on the concept of flux, which is the sequence of elements, commands, or data processed by the processor. The corresponding system of classification is based on the consideration of the number of streams of instructions and data flows, and describes the four architectural classes:
-
SISD = Single Instruction Single Data
Single stream of commands and a single data stream. This class includes serial computers, which have one central processor, capable of processing only one thread of instructions executed sequentially.
-
MISD = Multiple Instruction Single Data
Multiple stream of commands and a single data stream. Theoretically, this type of machine set of instructions to be executed over a single stream of data. So far, no real machine that falls in this class, was not created.
-
SIMD = Single Instruction Multiple Data
Single command stream and multiple data stream. These systems usually have a large number of processors, ranging from 1024 to 16384, which can perform the same instruction on different data in a rigid configuration. The single instruction is executed in parallel on many data elements.
-
MIMD = Multiple Instruction Multiple Data
Multiple command stream and multiple data stream. These machines perform several parallel streams of instructions on the various streams of data. Unlike SISD-multiprocessor machines mentioned above, the commands and data linked, because they represent different parts of the same task at hand. For example, MIMD-systems can simultaneously perform many subtasks to reduce execution time the main task.
Systematic Flynn is widely used for specifying types of computer systems, such a classification leads to the fact that virtually all types of parallel systems (despite their significant heterogeneity) belong to one group MIMD. As a result, many researchers have made repeated attempts to detail the systematic Flynn. For example, for the class of MIMD offered almost universally accepted structural scheme in which the further division types of multiprocessor systems based on the methods used by the organization of RAM in these systems [7].
Cluster consists of two or more computers (called nodes), merged with network technologies based on bus architecture or the switch and brought to users as a single information and computing resources. As the cluster nodes can be selected servers, workstations, and even ordinary PCs. The advantage of clustering to improve the efficiency becomes evident in case of failure of any node: while another cluster node can assume the load of a faulty node, and users will see no interruption in access.
Clustering can be implemented at different levels of computer systems, including hardware, operating systems, utility programs, management systems and applications. The higher levels of integrated clustering technology, the higher reliability, scalability and manageability of the cluster.
The model of a homogeneous cluster with sharing space
One of the classification systems is the classification of cluster systems to share the same disk separate units: clusters with shared and separate disk space [8].
In this work we consider a model cluster with sharing space.
Implementation
Parallelization algorithm determines:
- number of nodes computing cluster;
- number of processes on the cluster;
- way of storing data;
- switching methods.
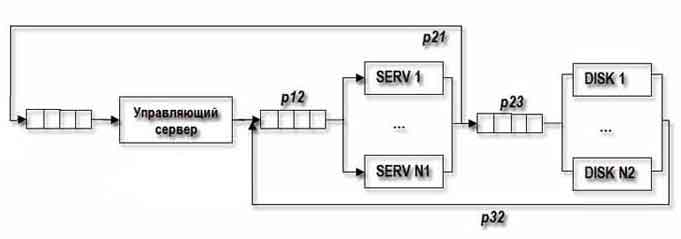
Picture 1 — Block diagram of the cluster with sharing space.
In the computer system, shown in Picture 1, M tasks or users, N1 identical cluster servers and N2 discs where data is stored. Each user (from M) send with probability of P12, the request to one of the N1 servers, which processing the request, turning to one of the N2 discs with a probability of P 23. The probability of completion of maintenance tasks by one of the discs and N2 flow at the i-th server will be - P 32 [i = 1 .. N1].
Algorithm
The algorithm applied in the parallel realization of Markov models [2,10], consists from two parts: computing the matrix of transition probabilities and the vector of stationary probabilities.
Calculation of stationary probabilities is implemented using iterative algorithm, which used as a basic algorithm for matrix multiplication on the vector.
Matrix element calculation of transition probabilities does not depend on neighboring elements, based on the parallel implementation this part of the parallel algorithm can use the principle of parallelism according [4]. The bottom line is the problem identified separate independent parts - the branches of the program, which if you have multiple processing units can run in parallel and independently from each other.
As a basic subproblem in the algorithm of the calculation is taken row of transition probabilities, which is characterized by the same computational complexity.
Assessment of efficiency
Calculations of the main characteristics are:
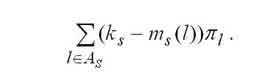 |
The average number of free devices in the s-th node is calculated by formula. |
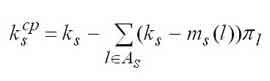 |
The average number of employed devices in the s-th node is determined by a formula. |
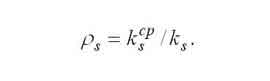 |
Loading devices is determined by the following formula. |
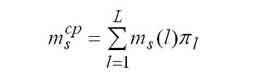 |
The average number of tasks that are in the s-th node. |
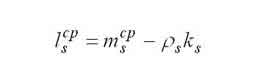 |
Average number tasks queued to the s-th node. |
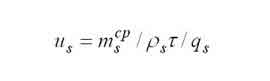 |
The mean time spent in the s-th node. |
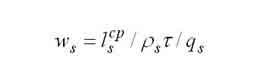 |
Average waiting time in the s-th node. |
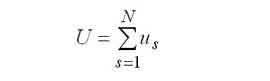 |
The mean time spent in the computer system. |
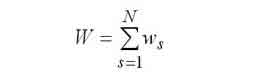 |
Average waiting time in the computer system. |
Expected practical results
A parallel algorithm for Markov models of multiprocessor computers can simulate any multi-processor structure. These algorithms can be used in the analysis, synthesis and modernization of computing structures. They quickly calculated in real time and therefore can be used to reconfigure computer systems in real time.
Conclusion
In this work we solve the pressing scientific challenges related to development of methods and studies the parallel algorithm for Markov models of multiprocessor systems for corporate computer networks to analyze the quality of their functioning, prediction of properties and modeling
The parallel algorithm improves the efficiency of the investigated computational structure.
Expected to study the efficiency of parallel algorithm for constructing Markov model on parallel structures of different topologies to determine optimal parallel computing structure.
Note! When writing this synopsis master work was not yet completed. Final completion: December 2010. Full text of work and materials for the topic can be derived from the author or its supervisor after that date.
Literature
1. Основы вычислительных систем. Курс лекций. Модели и методы. [Электронный ресурс] / Интернет-ресурс. — Режим доступа: http://256bit.ru/education/infor2/lecture7-2.htm
2. Михайлова Т.В. Параллельный алгоритм построения дискретной модели Маркова // Искусственный интеллект. Интеллектуаьные и многопроцесорные системы. Материалы Международной научно-технической конференции, 25-30 сентября 2006г., Таганрог-Донецк-Минск, 2006. – С. 275–279
3. Мищук Ю.К. Моделирование параллельной реализации марковских моделей в многопроцессорных вычислительных системах // Наукові праці Донецького національного технічного університету. — Донецьк, ДонНТУ, 2010. – с. 238-240
4. Фельдман Л.П., Михайлова Т.В., Ролдугин А.В. Реализация параллельного алгоритма построения марковских моделей. // Наукові праці ДонНТУ. Серія: Інформатика, кібернетика та обчислювальна техніка, випуск 10. - С.17-20
5. Ефимов С.С. Обзор методов распараллеливания алгоритмов решения некоторых задач вычислительной дискретной математики. [Электронный ресурс] / Интернет-ресурс. — Режим доступа: http://cmm.univer.omsk.su/sbornik/jrn17/efimov.pdf
6. Image Processing. Классификация параллельных вычислительных систем. [Электронный ресурс] / Интернет-ресурс. — Режим доступа: http://iproc.ru/parallel-programming/lection-2/
7. Информационно-аналитический портал. Высокопроизводительные вычисления на WINDOWS-кластерах. Классификация вычислительных систем. [Электронный ресурс] / Интернет-ресурс. — Режим доступа: http://www.winhpc.ru/?id=36
8. Спортак М., Франк Ч., Паппас Ч. и др. Высокопроизводительные сети. Энциклопедия пользователя. — К.: ДиаСофт, 1998. — 432 с.
9. Фельдман Л.П., Михайлова Т.В. ВЕРОЯТНОСТНЫЕ МОДЕЛИ АНАЛИЗА ОЦЕНКИ ЭФФЕКТИВНОСТИ КЛАСТЕРНЫХ СИСТЕМ // Материалы второго Международного научно-практического семинара: Высокопрозводительные параллельные вычисления накластерных системах,Нижегородский государственный университет им. Н.И. Лобачевского, 2002. C. 307-314
10. Фельдман Л.П., Михайлова Т.В. Использование аналитических методов для оценки эффективности многопроцессорных вычислительных систем. //Электронное моделирование, Т.29, №2, 2007. - С.17-27