
Реферат по теме выпускной работы
Структурно-алгоритмическая организация устройств генерации произвольных дуг и секторов в 3D пространстве для объёмных дисплеев
Введение
Устройства отображения информации являются на данных момент основными средствами общения и взаимодействия человека и средств вычислительной техники. Посредством именно устройств отображения информации после некоторой обработки данные предоставляются пользователю. Алгоритмы вывода и представления алфавитно-цифровой информации являются достаточно изученной областью знаний. Отображение алфавитно-цифровых объектов ориентировано главным образом на поддержку языковой коммутативности. В то же самое время основным способом доведения больших объемов информации до человека и его зрительных органов и центров, воспринимающих основной объем информации, обрабатываемый человеческим мозгом, стало отображение данных в виде естественных и искусственных графических образов [1].
Разработка новых способов построения трехмерных устройств отображения [2] информации, так называемых «3D дисплеев», дает толчок новым исследованиям в области объемной визуализации, направленным на создание алгоритмической базы генерации, обработки вывода «вокселизированных» объектов и сцен. Следует отметить, что в литературе [3] достаточно подробно рассмотрены вопросы создания воксельных моделей («вокселизации») реальных объектов, например, с помощью трехмерных сканеров, в то время как методы и алгоритмы генерации типичных графических примитивов не рассматриваются.
Повышение информативности и улучшение изобразительных возможностей визуального канала обмена данными между компьютером и человеком приводит к созданию трехмерных устройств отображения. Современная классификация [2] 3D устройств визуализации объектов и изображений выделяет как особый класс системы, построенные на базе объемных технологий. Такие устройства позволяют создавать виртуальное изображение объектов в трехмерном пространстве, причем, эффект трехмерности они обеспечивают для множества точек наблюдения, расположенных в широком диапазоне как по горизонтали, так и по вертикали.
Создание и использование такого рода устройств требует разработки специальных аппаратных и программных средств. Особенностью устройств отображения на базе объемных технологий является наличие объемного воксельного запоминающего устройства — аналога растровой памяти двумерных устройств отображения. При генерации трехмерного изображения в воксельной памяти программными средствами создается «вокселизированная» модель реальных объектов, состоящая из совокупности трехмерных графических примитивов: отрезков трехмерных прямых, трехмерных плоскостей, дуг, окружностей, сферических треугольников, эллипсоидов и т.п. [1]
Актуальность работы
В виду постоянного увеличения мощности аппаратной базы, предназначенной для обработки и представления человеку визуализируемой информации, а также в ходе постоянного увеличения интереса к визуализации трехмерных образов в пространстве устройств отображения информации, возрастает и потребность в разработке эффективных алгоритмов генерации графических примитивов, на основе которых в последующем будут строиться более сложные графические объекты, их композиции, а также будет происходить формирование сложных сцен, отображаемых в пространстве устройства отображения информации.
В сфере компьютерной графики разработано достаточное количество методов, алгоритмов и подходов, позволяющих ускорить процесс отображения информации на экране дисплея. Алгоритмы, описывающие процесс визуализации являются хорошо отлаженными и проверенными продуктами. Но большинство известных на данный момент алгоритмов и подходов ориентированы на разрешение проблем, касающихся визуализации в пространстве довольно привычных для среднестатистического пользователя устройств отображения информации: мониторов, графопостроителей, табло бегущей строки и прочих. Более узкой сферой является отображение графических образов и элементов сцен при помощи объемных дисплеев. Наряду со сложностью разработки алгоритмов, позволяющих качественно, с большой точностью и эффективностью воспроизводить образы в пространстве 3D дисплея, перед разработчиком зачастую возникает проблема проверки результатов разработанного алгоритма в виду недоступности материальной базы из-за ее дороговизны и отсутствия в достаточной мере проверенных и надёжных аппаратных решений. Поэтому зачастую приходится прибегать к использованию нетривиальных выходов из сложившейся ситуации, связанной со сложностью проверки результатов работы алгоритма. Аппаратной заменой объемного устройства отображения информации могут выступать уже готовые программные продукты, отображающие отдельную часть трехмерного непрерывного Евклидова пространства (MatLab, MathCAD, SciDAVis, 3D-grapher). Также не исключается возможность разработки собственных систем, заменяющих трехмерное устройство визуализации.
Наряду с проблемами, связанными со сложностью проверки результатов алгоритмов генерации графических примитивов в пространстве трехмерных дисплеев, возникают проблемы отладки программ, т.к. математический аппарат, связанный с трехмерной графикой, является достаточно сложным инструментом в сравнении с алгоритмами двумерной графики. Особое внимание уделяется оптимизации работы алгоритмов трехмерной графики с точки зрения затраченного времени на отрисовку сцены, а также с точки зрения аппаратных затрат, что зачастую является определяющим фактором во время выбора стратегии решения поставленной задачи.
Обзор исследований
В глобальном плане исследование приложения воксельной графики не является новинкой. В Internet доступно значительное количество статей, в тексте которых авторы раскрывают ту или иную область приложения воксельной графики, а также рассматривают проблемы, стоящие на пути внедрения воксельной графики.
1. Винсент Бретон в своей статье рассматривает применение воксельной графики в контексте построения изображений, помогающих врачам поставить пациенту правильный своевременный диагноз.
2. Забугорский Н. в своих рассуждениях на тему воксельной графики касается аспекта создания компьютерных игр на ее базе.
3. Шаламов А.В. и Мазеин П.Г. рассматривают воксельную графику в качестве приложения к популярным CAD системам, с помощью которых создаются и моделируются трехмерные модели тел.
Но специализированные разработки, направленные именно на генерацию графических примитивов [4, 5, 6] в пространстве трехмерных дисплеев, являются в достаточной мере малоисследованной областью знаний.
1. Башков Е.А., Авксентьева О.А., Аль-Орайкат Анас Махмуд в своей статье рассматривают способы построения графических примитивов в пространстве трехмерных дисплеев.
2. Е.А. Башков, О.А. Авксентьева, Аль-Орайкат Анас Махмуд, Д.И. Хлопов в своей статье рассматривают методы генерации отрезков прямых, а также методы ускорения генерации графических примитивов.
3. Е.А.Башков, Аль-Орайкат Анас Махмуд, Дубровина О.Д., Авксентьева О.А. в своей статье рассматривают алгоритмический базис построения генераторов отрезков прямых для 3D дисплеев.
Поиск по порталу магистров дал несколько ссылок на рефераты студентов, магистерские работы которых тем или иным образом затрагивают проблемы и методы, связанные с воксельной графикой.
1. Магистр Хромова Е.Н. рассматривает проблему построения сеточной модели объектов сложной формы по произвольному набору точек для визуализации и моделирования в трехмерном пространстве.
2. Магистр Захаров С.С. рассматривает проблему компьютерного моделирование природных явлений: визуализации неба и облаков.
Цели и задачи разработки и исследований
После того, как было принято решение разработки оптимального, эффективного и в достаточной мере точного алгоритма генерации трехмерного сплайна в пространстве 3D дисплея, стал вопрос о том, какими методами руководствоваться во время его разработки, тестирования и отладки. После того, как была определена методическая база [7] построения функциональной сущности алгоритма, было принято решение направить дальнейшие исследования в этой области по следующим направлениям:
1. Разработка оптимального алгоритма генерации дуги в качестве графического примитива в пространстве трехмерного устройства отображения информации. Нахождение множества координат каждого вокселя, участвующего в воксельном разложении заданного графического примитива.
2. Разработка критериев оценки точности воксельного разложения, временных затрат, а также критериев оптимизации полученных показателей.
3. Тестирование полученного алгоритма на граничные случаи при помощи различного количества запусков и поэтапного сравнения показателей.
4. Тестирование алгоритма на различных архитектурах и платформах, а также дальнейшее сравнение полученных временных показателей и характеристик, указывающих на точность воксельного разложения.
5. Сделать вывод о целесообразности использования той или иной архитектуры или платформы, основываясь на показателях, полученных в качестве результатов на предыдущих этапах решение единой задачи.
6. Произвести попытку построения более сложного графического примитива на базе уже разработанного и отлаженного алгоритма генерации дуги в пространстве трехмерного дисплея. Например, найти множество координат каждого вокселя, участвующего в воксельном разложении шара или эллипсоида. На ранних этапах рассматривались варианты построения геометрического объекта, по форме напоминающего «полутрубу» с произвольным углом генерации дуги, распространяющейся вдоль линейной оси. На поздних этапах исследования были направлены на попытку создания воксельного разложения части поверхности шара, заданной тремя точками, находящимися на ней.
Планируемые практические результаты
В ходе работы над решением поставленной задачи нахождения воксельного разложения графического примитива планируется получить оптимальный метод решения подобных задач. В конечном итоге результатом магистерской работы станет вывод, полученный на основе анализа программной, программно-аппаратной и аппаратной реализации разрабатываемого алгоритма, указывающий на архитектуру или платформу, наиболее подходящую для решения задач, связанных с генерацией графических примитивов в пространстве трехмерных устройств отображения информации.
Предполагаемая научная новизна
В ходе работы были исследованы и протестированы методы генерации графического примитива (дуги) в пространстве трехмерного дисплея, нахождения множества координат всех вокселей, участвующих в воксельном разложении данного графического примитива. Также были предложены методы оптимизации разработанного алгоритма как с точки зрения программных улучшений, вносимых непосредственно в код программы, так и с точки зрения программно-аппаратных решений, основывавшихся на применении архитектуры CUDA, использующей графический процессор и ядра GPU в качестве вычислительного ресурса. Также GPU использовались в качестве платформы, обладающей колоссальным потенциалом распараллеливания алгоритмической реализации генерации графического примитива. Наряду с программными и программно-аппаратными подходами к оптимизации алгоритмической реализации предложенного решения единой задачи был выбран и аппаратный метод решения, основывавшийся на погружении данного алгоритма в FPGA, что обусловило всестороннее исследование разработанного алгоритма с точки зрения возможных путей оптимизации.
Экспериментальная база
1. К программным усовершенствованиям разработанного алгоритма относятся непосредственные изменения, вносимые в код программы, генерирующей координаты всего множества вокселей, участвующих в воксельном разложении трехмерного сплайна в пространстве 3D дисплея. Эксперименты и замеры, заключающиеся в многократных запусках программы на выполнение, и дальнейший анализ полученных временных показателей и характеристик, указывающих на точность воксельного разложения, проводились на базе компьютера, обладающего следующими характеристиками: Intel(R) Celeron CPU 2.3GHz, 1 Гб ОЗУ.
2. К программно-аппаратным улучшениям, вносимым в структуру алгоритма, относится его тестирование на базе архитектуры CUDA, что подразумевает использование графического процессора в качестве основы для ресурсоёмких вычислений. В код программы вносились изменения, в первую очередь затрагивавшие те блоки кода, выполнение которых было возможно параллельно, используя аппаратные ресурсы, предоставляющие значительный потенциал распараллеливания запускаемой программы. Эксперименты, направленные на распараллеливание выполнения программы, проводились на базе компьютера, обладающего следующими характеристиками: Intel(R) Core(TM)2 Duo CPU E4600 2.40GHz, 2.40ГГц, 1,99ГБ ОЗУ.
3. Аппаратная реализация алгоритма производилась на основе FPGA фирмы Xilinx [8, 9] путем погружения разработанного алгоритма на плату. В ходе работы были произведены циклы контрольных запусков и подсчитаны временные показатели и характеристики, касающиеся точности генерации трехмерного сплайна в пространстве объемного дисплея. Таким образом была совершена попытка создания специализированного устройства, направленного на решение конкретной задачи – воксельного разложения графического примитива.
Рисунок 1 поясняет этапы разработки и тестирования алгоритма генерации дуги в пространстве трехмерного дисплея.

Рисунок 1 — Этапы исследования разработанного алгоритма генерации графического примитива в пространстве трехмерного дисплея.
5 кадров. Задержка после последнего кадра = 2 сек. Задержка после остальных кадров = 1 сек.
Размер анимации: 382px х 240px. Размер файла: 31.6 Kbytes. Создано при помощи Adobe ImageReady.
Обзор базового алгоритма. Программное решение поставленной задачи
В ходе разработки концепции алгоритма генерации трехмерного сплайна (дуги, заданной произвольными начальными данными) в пространстве 3D дисплея были рассмотрены такие двумерные алгоритмы генерации графических примитивов:
1. Алгоритм цифрового дифференциального анализатора (DDA — Digital Differential Analyzer).
2. Двумерный алгоритм Брезенхема в приложении к генерации окружности и прямой (Bresenham's algorithm).
3. Трехмерный алгоритм Брезенхема в приложении к генерации прямой.
После изучения уже существующей алгоритмической базы было принято решение создать алгоритм, учитывающий преимущества и ликвидирующий слабые места вышеизложенных подходов. Задача растрового разложения дуги формулируется как задача определения множества вокселей, находящихся в пространстве 3D дисплея, к которому принадлежат начальный и конечный воксели генерации, каждый из которых (кроме начального и конечного) имеет два и только два соседних вокселя, центр каждого из которых лежит на минимальном расстоянии от дуги и их количество во множестве минимально. Т.к. классический двумерный алгоритм Брезенхема подразумевает только целочисленную арифметику, исключая вычисления, связанные с величинами, представленными в формате с плавающей запятой, количество вычислений в разрабатываемом алгоритме, связанных с дробной арифметикой, было минимизировано настолько, насколько это представилось возможным. Полное исключение комплексных вычислений, связанных со значительными затратами процессорного ресурса, оказалось невозможным, т.к. трехмерный случай решения задачи генерации сплайна связан с подсчетом значительного количества значений, коэффициентов и величин, представленных в формате с плавающей запятой. Основная идея разрабатываемого алгоритма заключается в том, что в функцию, являющуюся точкой входа в алгоритм, поступают значения, задающие точку центра дуги, начальную точку дуги, точку лежащую на плоскости генерации, которая в свою очередь обеспечивает однозначность решения единой задачи и определяет плоскость генерации, а также значение угла генерации дуги. Этапы работы алгоритма можно описать следующим образом:
1. Получение и обработка начальных данных. Определение коэффициентов уравнения плоскости, на которой будет вестись процесс генерации [10]. Переход от значений, задающих точки непрерывного трехмерного пространства, к значениям, обозначающим координаты точек в дискретном пространстве, часть которого отображается трехмерным дисплеем.
2. Нахождение конечной точки генерации с помощью матрицы поворота.
3. Циклическое последовательное вычисление координат вокселей, входящих в воксельное разложение дуги. Для каждого вокселя, определенного на предыдущем этапе, существует 7 вокселей-претендентов, каждый из которых может стать следующим в воксельном разложении. Для каждого из семи вокселей-претендентов производится вычисление двух количественных показателей, дальнейшая обработка которых показывает, какой из вокселей-претендентов станет следующим в воксельном разложении.
4. На каждой итерации алгоритма производится подсчет не только количественных значений, указывающих на то, какой из вокселей-претендентов станет следующим в воксельном разложении, но и качественных показателей, указывающих на точность и скорость работы разрабатываемого алгоритма. В дальнейшем каждый из качественных показателей будет оценен и проанализирован.
Предлагаемый модифицированный алгоритм воксельного разложения дуги в трехмерном пространстве, с учетом вышеизложенного, может бать записан на псевдоязыке из [11] следующим образом.
Алгоритм воксельного представления дуги
Входные данные: N начальная точка дуги, C центральная точка дуги, P точка на плоскости, α угол дуги.
Выходные данные: массив вокселей V
Begin
Input C, P, N, α; Определение VC, VP, VN Вычисление координат векторов CP и CN Вычисление координат вектора нормали n к плоскости Вычисление радиуса дуги Вычисление координат точки K Repeat Вычисление координат вектора касательной k Заполнение матрицы приращений M Do k = 1,2 … 7 V(k)<q+1>:= VN + M(k) +0.5 Вычисление погрешности E1(k)<q+1> Вычисление погрешности E2(k)<q+1> End Do
MIN = MIN(E1(k)<q+1> + E2(k)<q+1>))
Do k = 1,2 … 7
If (E1(k)<q+1> = MIN)
If (Приоритет максимален)
Vpoints:= VN + M(k)
points:= points + 1
End if
End if
End Do
Until VN<>VK
Output V
End
После того, как была получена и отлажена модифицированная версия алгоритма, программа, реализующая данный алгоритм, прошла процедуру многократных пробных запусков. Количество таких запусков варьировалось от 10 до 10 000, причем инициализация начальных значений проводилась с помощью генератора псевдослучайных чисел, не исключая граничных значений, обработка которых была предусмотрена и учтена в ходе разработки программы. Результат очередной 1 000 запусков представлен ниже:
Количество сгенерированных дуг = 1000 Количество точек = 1949224 Суммарная E1 = 435864.58976 Суммарная E2 = 433187.11029 Суммарная E3 = 696534.57655 ============================================================== Средняя ошибка по радиусу (E1av) = 0.22361 Средняя ошибка по расстоянию до плоскости дуги (E2av) = 0.22224 Средняя ошибка по расстоянию до функции (E3av) = 0.35734 ============================================================== MAX ошибка по радиусу (E1max) = 0.84506 MAX ошибка по расстоянию до плоскости дуги (E2max) = 0.84604 MAX ошибка по расстоянию до функции (E3max) = 0.86601 ============================================================== MIN ошибка по радиусу (E1min) = 0.00010 MIN ошибка по расстоянию до плоскости дуги (E2min) = 0.00000 MIN ошибка по расстоянию до функции (E3min) = 0.00016 Время, затраченное на генерацию 1000 дуг = 20593 миллисекунд
Результат работы программы приведен ниже. Координаты вокселей, полученные в ходе выполнения программы, записываются в текстовый файл, обладающий специальной структурой. После построения такого файла, содержащего координаты всех вокселей, входящих в воксельное разложение трехмерного сплайна в пространстве трехмерного дисплея, его можно обрабатывать с помощью любого трехмерного визуализатора. В качестве среды визуализации, моделирующей часть Евклидова пространства, отображаемого трехмерным дисплеем, был выбран программный пакет MatLab версии 7.01.
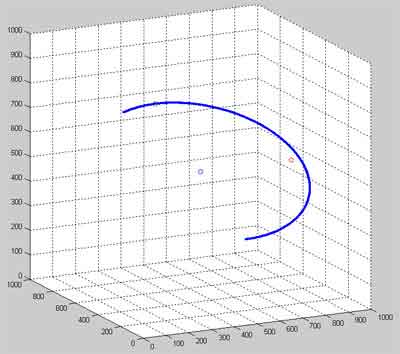
Рисунок 2 — Результат визуализации воксельного разложения дуги, заданной произвольными параметрами в пространстве трехмерного дисплея
(среда визуализации – программный пакет MatLab 7.01)
Дальнейшая модификация алгоритма. Применение технологии CUDA
«CUDA (англ. Compute Unified Device Architecture) — программно-аппаратная архитектура, позволяющая производить вычисления с использованием графических процессоров NVIDIA, поддерживающих технологию GPGPU (произвольных вычислений на видеокартах). Архитектура CUDA впервые появились на рынке с выходом чипа NVIDIA восьмого поколения — G80 и присутствует во всех последующих сериях графических чипов, которые используются в семействах ускорителей GeForce, Quadro и Tesla.
CUDA SDK позволяет программистам реализовывать на специальном упрощённом диалекте языка программирования Си алгоритмы, выполнимые на графических процессорах NVIDIA, и включать специальные функции в текст программы на Cи. CUDA даёт разработчику возможность по своему усмотрению организовывать доступ к набору инструкций графического ускорителя и управлять его памятью, организовывать на нём сложные параллельные вычисления.» [12]
Во время программно-аппаратной оптимизации разработанного алгоритма архитектура CUDA использовалась в качестве вычислительной среды, позволяющей выполнять параллельно некоторые фрагменты программы [13]. За счет того, что программу на языке Си можно за непродолжительный промежуток времени оптимизировать и реструктурировать в соответствии с требованиями, предъявляемыми CUDA к программам, выполняемым на GPU, алгоритм со временем был успешно «переведен» на специфический диалект языка Си, написание программ на котором является обязательным требованием со стороны архитектуры [14, 15]. Но помимо сложностей, возникших во время перевода программы, реализующей алгоритм воксельного разложения графического примитива, на пути дальнейшей оптимизации стали проблемы поиска блоков алгоритма, которые можно было подвергнуть параллельной реализации [16, 17]. Такие блоки были найдены и реализованы таким образом, чтобы минимизировать количество циклов, выполняемых в программе.
Особую сложность, возникающую перед программистом, создающим программу на языке Си, оптимизированную в соответствии с требованиями, предъявляемыми со стороны архитектуры CUDA, составляет отладка программы. Эта сложность во многом тесно связана с тем, что просмотреть содержимое переменных невозможно с помощью стандартных механизмов Debugger-а Microsoft Visual Studio, т.к. все параметры, передаваемые в CUDA-функцию, являются недоступными из-за их расположения во внутренней памяти GPU. Стандартным подходом в таком случае (во время написания простейших программ-тестов) является вывод содержимого переменных в консоль или в файл. Таким методом пользуются в тех случаях, когда стандартные методы отладки недоступны. Но и этот подход невозможно реализовать в условиях вычислений на графических процессорах, т.к. CUDA-функция не имеет доступа к стандартным потокам вывода, что означает невозможность использования ни консоли, ни файлов. Еще одним методом, доступным во время разработки приложения для CUDA, является поэтапное копирование результатов, обработанных GPU, из внутренней памяти графического процессора в основную память компьютера. Этот метод требует дополнительной адаптации программы и написания дополнительного программного кода. Особенностью использования такого метода являются значительные временные затраты, направленные на резервирование памяти под переменные как на CPU, так и на GPU. Но резервирование памяти влияет на время выполнения программы не настолько фатально, насколько постоянное копирование результатов работы CUDA-функции в пространстве памяти GPU. Т.к. одним из требований к эффективной работе программ, созданных для выполнения и тестирования на графических процессорах, является минимизация копирования данных между CPU и GPU (память GPU ограничена, поэтому стоит обратить особое внимание на копирование и обработку больших объемов информации), от применения вышеописанного метода пришлось отказаться.
Рисунок 3 — Nexus Debug Environment
Во время исследований требовалось разработать довольно нетривиальную программу. Поэтому пришлось искать методы решения проблемы отладки. Эта задача была решена с помощью технологии Nexus. С появлением технологии, позволяющей с помощью интегрируемых в Microsoft Visual Studio средств эффективно отлаживать программы, процесс разработки приложений для графических процессоров значительно ускорился. Согласно [18, 19] основными возможностями, предоставляемыми разработчику программ, выполняемых на GPU, со стороны технологии Nexus являются:
Еще одной важной задачей, которую было необходимо решить, стал поиск метода замера времени, затрачиваемого на выполнение программы во время пробных циклов запуска. Стандартные методы, поддерживаемые Microsoft Visual Studio (например, применение функции getTickCount() в начале программы, а затем в ее конце с последующим нахождением разности этих величин) не могут быть применены, т.к. на практике было выяснено, что применение такого замера даёт неправильный результат. Выход из сложившейся ситуации был найден. Применение именно стандартных средств, поддерживаемых архитектурой CUDA, стало наиболее удобным и точным методом замера времени работы программы. Таким средством стал Compute Visual Profiler. Значения, представленные в таблице 1, получены именно с помощью Compute Visual Profiler.
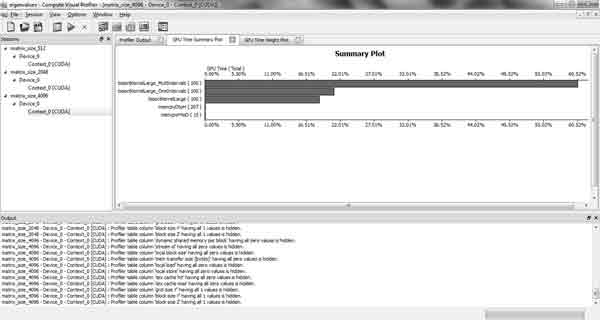
Рисунок 4 — CUDA Compute Visual Profiler
Результаты, показанные архитектурой CUDA превзошли все ожидания. По мере увеличения количества пробных циклов запуска степень распараллеливания алгоритма программы увеличивалась. В зависимости от количества пробных запусков ускорение, показываемое GPU по сравнению с CPU, составило от 4.5 до 8.7 раз. Такие результаты были вполне предсказуемы, т.к. степень распараллеливания была равна количеству вокселей-претендентов на вхождение в воксельное разложение. Таким образом, подсчет всех характеристик, присущих каждому вокселю-претенденту, происходил параллельно.
Таблица 1 — Сравнительные характеристики временных затрат при выполнении программы на CPU и GPU
| Количество запусков | CPU (мс) | GPU (мс) | Отношение времени выполнения на GPU ко времени выполнения на CPU |
| 128 | 328 | 73,559 | 4,459005696 |
| 512 | 1297 | 187,437 | 6,919658339 |
| 1024 | 2641 | 359,803 | 7,340127792 |
| 4096 | 10172 | 1254,01 | 8,111578058 |
| 10240 | 25547 | 2990,54 | 8,542604346 |
| 16384 | 41672 | 4785,61 | 8,707771841 |
От CUDA к FPGA
«Есть простое инженерное правило - специализированные устройства для применения в конкретной области всегда лучше универсальных. Оно остается справедливым вне зависимости от любых технических ухищрений, ведь, на самом деле, определяет и цель проектного процесса, и его следствие, результат. Иными словами, устройство проектируют специализированным именно для того, чтобы оно в чем-то было лучше универсальных».
Именно эта фраза стала девизом проводимых исследований на время разработки алгоритмической реализации воксельного разложения дуги, заданной произвольными параметрами, в пространстве трехмерного дисплея. Попытка протестировать разработанный алгоритм на FPGA была сделана не только для того, чтобы охватить все области его оптимизации. Именно желание выявить наилучший способ решения задач, подобных поставленной задаче, стало причиной перехода от программной и программно-аппаратной реализации алгоритма к сугубо аппаратной его оптимизации.

Рисунок 5 — FPGA Spartan-3E фирмы Xilinx
Главными целями прошивки FPGA в соответствии с алгоритмом генерации графического примитива были:
1. Загрузка начальных произвольных данных в FPGA посредствами интерфейса.
2. Многократное тестирование алгоритма с целью выявления неточностей и ошибок.
3. Пробное тестирование алгоритма на FPGA с последующей дальнейшей выдачей результатов.
4. Анализ временных характеристик и показателей, указывающих на точность воксельного разложения.
Результаты
На момент написания магистерской работы исследования, проводимые в ее рамках, носили не только сугубо теоретический характер, но и были подтверждены на программном, программно-аппаратном, а также аппаратном уровнях. Разработанный в ходе выполнения магистерской работы алгоритм прошел все стадии:
1. Формулировка единой задачи.
2. Исследование имеющегося накопленного опыта в данной сфере компьютерной графики.
3. Анализ алгоритмической основы, ставшей базисом для разрабатываемого алгоритма.
4. Выработка критериев оценки качественных показателей алгоритма.
5. Оптимизация разработанного алгоритма с точки зрения минимизации комплексных вычислений, связанных с вычислениями величин, представленных в формате с плавающей запятой. Тестирование алгоритма, замеры временных характеристик и признаков, указывающих на точность генерации графического примитива.
6. Модернизация и оптимизация алгоритма в соответствии с требованиями, предъявляемыми к программам со стороны платформы CUDA. Проверка работоспособности алгоритма на GPU компании nVidia с поддержкой технологии CUDA. Анализ полученных временных характеристик, а также показателей, указывающих на точность выполнения алгоритма.
7. Создание модификации алгоритма для дальнейшей прошивки FPGA и анализа результатов, полученных в ходе работы с аппаратной реализацией алгоритма.
Заключение
Опыт работы с разработанным алгоритмом на различных уровнях реализации показал, что любая идея может быть реализована различными способами. Каждая идея может пройти путь от концепции до конкретного внедрения и практической реализации. Алгоритм, на первых порах реализованный сугубо в качестве программы, может пройти стадии многократных модификаций, улучшений и усовершенствований.
Литература
1. Башков Е.А., Авксентьева О.А., Аль-Орайкат Анас М. К построению генератора графических примитивов для трехмерных дисплеев [Текст]. В сб. Наукові праці Донецького національного технічного університету, серія "Проблеми моделювання та автоматизації проектування динамічних систем". Вип. 7 (150). - Донецьк, ДонНТУ. - 2008 .- ст. 203-214.
2. Favalora G.E. Volumetric 3D Displays and Application Infrastructure [Текст] // "Computer", 2005, August, pp 37- 44.
3. Роджерс Д. Алгоритмические основы машинной графики [Текст]. — Пер. с англ. — Москва.: "Мир", 1989. — 512 с.
4. Башков Е.А., Авксентьева О.А., Аль-Орайкат Анас М., Хлопов Д.И. Генератор отрезков прямых повышенной производительности для трехмерных дисплеев [Электронный ресурс]
http://www.nbuv.gov.ua/portal/natural/Npdntu_ikot/2010_11/3_1.pdf
5. Милютин М.О., Башков Е.А., Авксентьева О.А. Аль-Орайкат А. Алгоритм генерации дуги для 3-D дисплеев [Текст]. Донецк, ДонНТУ. - 2009.
6. Авксентьева О.А., Аль-Орайкат Анас, Хлопов Д.И. Улучшенный алгоритм генерации прямой для 3D – дисплеев [Текст]. Материалы 14 – 10 международного молодежного форума «Радиоэлектроника и молодежь в XXI веке», 18 -20 марта 2010, Харьков 2010, сб. материалов 4.1. – Харьков: ХНУРЭ. 2010. – 527с.
7. Дружинин А.И., Вихман В.В. Алгоритмы компьютерной графики [Текст]. Учеб. пособие. – Новосибирск: Изд-во НГТУ, 2003. – 47 с.
8. Spartan-3E FPGA Family: Data Sheet [Электронный ресурс]
http://www.xilinx.com/support/documentation/data_sheets/ds312.pdf
9. Spartan-3E Starter Kit Board User Guide [Электронный ресурс]
http://www.digilentinc.com/Data/Products/S3EBOARD/S3EStarter_ug230.pdf
10. Д.В. Беклемишев. Курс аналитической геометрии и линейной алгебры [Текст]. М.: Наука, 1980.
11. Препарата Ф., Шеймос М. Вычислительная геометрия: Введение [Текст]. - Пер. с англ. – М.: "Мир", 1989. - 478 с.
12. Статья в Wikipedia о CUDA [Электронный ресурс]
13. Андрей Зубинский. NVIDIA Cuda: унификация графики и вычислений [Электронный ресурс]
14. Antonio Tumeo. Politecnico di Milano. Massively Parallel Computing with CUDA [Электронный ресурс]
http://www.ogf.org/OGF25/materials/1605/CUDA_Programming.pdf
15. Nvidia CUDA Development Tools. Getting started [Электронный ресурс]
http://www2.engr.arizona.edu/~ece569a/Readings/NVIDIA_Resources/QuickStart%20Guide.pdf
16. Nvidia CUDA Programming Guide [Электронный ресурс]
http://developer.download.nvidia.com/compute/cuda/3_0/toolkit/docs/NVIDIA_CUDA_ProgrammingGuide.pdf
17. Nvidia CUDA Reference Manual [Электронный ресурс]
http://developer.download.nvidia.com/compute/cuda/2_3/toolkit/docs/CUDA_Reference_Manual_2.3.pdf
18. dimson3d. Знакомство с NVIDIA CUDA, параллельные вычисления с помощью GPU в CG [Электронный ресурс]
http://www.render.ru/books/show_book.php?book_id=840&start=1
19. Nvidia Corporation. CUDA: new architucture for GPU computing [Электронный ресурс]
http://www.nvidia.ru/content/cudazone/download/ru/CUDA_for_games.pdf