
Vladislav Pranskevichus
- Faculty
- Computer sciences and technologies
- Department
- Automated Control Systems
- Subject
- Development of distributed web crawler
- Scientific advisor
- M. Privalov, Ph. D
Abstract
Development of distributed web crawler
Table of contents
- Introduction and subject relevance
- Goals and objectives of the system
- Scientific novelty
- Overview of previous work
- Research
- Conclusions
- References
1. Introduction and subject relevance
Due to the rapid development of the World Wide Web, every day more and more important becomes the problem of automated data collection and analysis of information provided on various Web resources. Back in the early 90-ies the World Wide Web was a a huge number of poorly structured information search in which it became for a man almost impossible task. It was at this time began to appear first developments in the field of automated agents to facilitate the task of finding the necessary information in the web. The main part of such systems is a search robot - software complex to navigate through a Web-based resources and information for the database Application Agent [11]. In general case, an information gathered by web crawler consists of web pages and web link structure.
2. Goals and objectives of the system
The objective of this research is a distributed web crawler. The main goals of a web crawler are:
- Choice of highly distributed, scalable and flexible architecture;
- Guarantees of reliable operation and interaction of components;
- Choice of web page importance metric;
- Research on the optimal in terms of performance of structures and data processing algorithms;
- Effective implementation of data storage.
The main purpose is to improve the performance and scalability of search robots through the use of flexible circuits to parallelize tasks.
To formalize the architecture I propose to use π-calculus [4], and for the evaluation – metrics, proposed for web crawlers in [3]. These concepts are described more thoroughly in next sections.
3. Scientific novelty
Scientific novelty of the work lies in the formal approach to the study of competitive and parallel processes in a search robot, which will identify ways to improve policies parallelizing the search robots.
The practical value of the work lies in the fact that the developed system can be used for rapid scanning of distributed and easily scalable web crawlers, crucial user tasks. Also, the study of competitive processes of this work can also be used to build other distributed systems other than Web crawler.
4. Overview of previous work
4.1 Local overview
- Shadi Abu Ruck: "Research of properties of search engine". This paper investigates the general problem to be solved by modern search engines. Shows mathematical model, which can be used for SEO.
4.2 National overview
No active research is going on the topic of search engines at national scale.
4.3 Global overview
Research in the field of search robots are maintained from the very inception of the World Wide Web. We can distinguish several main areas of research:
- Web crawler architectures [2, 3, 7];
- P2P web crawlers [3, 12];
- Focused web crawlers [5];
- Selection and refresh policies in web crawlers [9];
- Politeness policies.
In the context of this work, the most interesting are the studies in the field of architecture search engines and algorithms of P2P systems.
One of the most cited and fundamental work in the field of search engines is the article by Sergey Brin and Larry Page «The Anatomy of a Large-Scale Hypertextual Web Search Engine» [2], describing Googlebot architecture as of 1998 год. Undoubtedly, since Googlebot has undergone a lot of changes, but in connection with the commercial nature of Google public data on this.
Paper by Junghoo Cho and Hector Garcia-Molina. «Parallel crawlers» [1] The classification of parallel architectures search engines and the metrics used to evaluate them. This master thesis is largely based on these studies.
5. Research
The task of constructing an effective search bot is pretty trivial, for several reasons:
- World Wide Web is evolving chaotic environment, most of the resources which includes violations of accepted standards for web development [10];
- due to the almost exponential growth of information on the World Wide Web, search engine robot should allow to efficiently process a large number of Web resources in a finite time and have an architecture that is suitable for scaling;
- web crawler must be versatile enough to adapt flexibly to the needs of the application using it.
Thanks to the huge volume and heterogeneity of the World Wide Web, the architecture of a search robot and in particular the policy of parallelism inherent in it, is an interesting subject of research. To date, the key point in determining the performance of a search robot is horizontal scalability of its architecture, ie property of the system to increase productivity by adding new nodes (computers). Sufficiently interesting study and attempt to classify the different architectures of parallel search engines are presented in [1].
However, the existing architecture of search engines are quite complex, and their scalability is often far from linear. Also, when zooming possible deterioration of the values of quality metrics collected by the robot information. It can be concluded that additional studies of policies to parallelize search engines can improve the scalability and performance of the robot, as well as improve the quality of collected data.
Given the complexities outlined above, relating to the circumvention of the World Wide Web, architecture and politics parallelize general-purpose search engines were initially developed in such a way as to ensure the most rapid data retrieval and ease of scaling. We can distinguish these two broad classes of architectures of parallel search engines:
- Centralized Architecture - underlie most used to date search engines. These architectures consist of several potentially competitive distributed components having a central point of synchronization (for example, all tasks or a specific component-coordinator). A striking example of a search robot, which has a centralized architecture is Googlebot [2]. Normally, when using a centralized architecture is used (intra-site) distribution model (according to the classification given in [1]), in which the components are distributed within a local environment. The block diagram of a search robot with a centralized architecture shown in Fig. 1.
- Decentralized or multi-agent architecture - characterized by complete (or close to full) the decentralization component. Building such systems requires a slightly different algorithms and methods than those used in centralized architectures [8], so they can make a separate class. An example of a decentralized architecture is shown in [3].
At a lower level, architecture search engines may be different methods of distribution of tasks between components, ways of sharing the URL and the algorithm of their distribution. The configuration of a specific web crawler may vary depending on the needs of the application using it. For example, to minimize the volume of downloaded data and optimize the performance of the Web crawler can be used in the calculation of deferred form abstractions futures [5].
To evaluate search engines, you can use the following metrics proposed in [1].
- Overlap — assesses the amount of redundant loaded pages and is determined by the formula:
where N — total number of downloaded pages, I — number of unique web pages.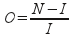
-
Coverage — determines the amount of pages that were supposed to be loaded, but due to specific functions of address allocation between the agents were not identified. Coverage can be defined by the following relation:
where I — number of unique web pages, U — total number of pages.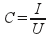
-
Quality - to determine the quality, we assume the existence of a hypothetical oracle crawler, which is known in advance on the importance of pages on any metric. Denote the set of "interesting" pages of power N, busy predicting a robot as PN, and a similar set of pages you have visited the real robot as AN. On this basis, we can define quality as:
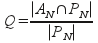
The above-mentioned metrics are directly related to the parallelization policy embodied in the architecture of a search robot, and tend to deteriorate in the distribution of competitive components or increase their numbers [1]. This fact clearly indicates the need for further research of parallelization policies.
Parallel search robot, by its very nature is a model system with competitive computing, and hence to it can be applied mathematical methods and models of competitive algorithms. One of the most impressive models of competitive algorithms is π-calculus [4]. Π-calculus is Turing-complete model of computation and is a powerful tool for the formalization and the study of competitive processes with complex interactions.
Basic π-calculus offers the following primitives to describe the process:
- concurrency, which is depicted as P | Q, where P, Q — processes;
- input prefix, c(x).P defines process P, awaiting for message x, that should be delivered by channel с;
- output prefix с(y).P, which defines process P, sending name y through channel с;
- creation of new name, (υx)P creates local name x in the process context P.
As an example, define the process in terms of π-calculus can be considered a process Fetch, performed directly by loading the page on this URL:
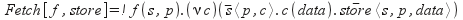
This process is an abstraction of π-calculus (ie parameterized); URL in the form (s, p), where s - server, p - the page is taken via f, then there is a page request from the server, followed by her receipt of channel with the parameter data. Then, data is transmitted over a channel store in the repository.
Thus, using the π-calculus can be simulated by other system components that will allow a more formal approach to the study of architecture web crawlers and policies parallelization. π-calculus allows to simulate complex interactions between system components and carry out structural reforms with the help of mechanisms bisimulations and structural congruence of processes.
In the theory of concurrent algorithms are usually distinguished two basic mechanisms of interaction: interaction with shared memory and interaction through message passing. This division is also reflected in the implementations of programming languages and frameworks. In the semantics of the π-calculus laid interprocess communication using message passing, which must be considered when choosing the means of implementation of the search robot.
The basic requirements for the implementation language are:
- availability of high-level structures and tools for functional decomposition of the system and create the necessary abstractions;
- expression, which is close to a formal mathematical description of the system;
- availability of built-in tools for describing competitive algorithms to easily implement the system processes and their interactions;
- availability of quality, community-supported libraries, such as networking, messaging protocols, parsing the HTML pages, DBMS, etc.;
- openness and accessibility of language implementation and development tools.
Given the demands put forward, as the implementation language was chosen as the programming language Haskell (http://www.haskell.org). Haskell belongs to the family of languages ML and is a pure functional language with lazy evaluation. Haskell has a strict statically typed language with automatic type inference on the model of Hindley-Milner, support for algebraic and recursive data types, function call on the model.
The determining factor in choosing this particular programming language has its advanced implementation of the primitives of competitive algorithms (Concurrent Haskell), close to the semantics of π-calculus [6]. Concurrent Haskell primitives implement all the basic operations of π-calculus, except for non-deterministic choice, which nevertheless can be implemented, if necessary, by other entities.
6. Conclusions
Specifics of the problem crawling the World Wide Web leads to the inevitable use of competitive algorithms in the development of search engines. For effective implementation of competition and good scalability crawler, you must pay considerable attention to developing the system architecture and policies of parallelization.
After analyzing the existing architecture, politics and parallelization methods for constructing search engines, for the developed system was selected decentralized architecture. It was also suggested the use of π-calculus as a mechanism to formalize and further investigation of policies parallelization of search robots. For the actual implementation crawler was chosen programming language Haskell and its extension Concurrent Haskell as the closest to the semantics of π-calculus method for describing competitive algorithms.
Important notice: At the time of writing this abstract masters thesis is not yet complete. This work will be finalised in December 2011. At the nearest future I plan to develop an architecture and implement a prototype of web crawler to compare it with other existing implementations.
References
- Junghoo Cho and Hector Garcia-Molina. Parallel crawlers // In Proc. of the 11th International World–Wide Web Conference – 2002.
- Sergey Brin, Lawrence Page. The Anatomy of a Large-Scale Hypertextual Web Search Engine // Computer Science Department, Stanford University, Stanford — 1998. - C. 107-117.
- Paolo Boldi, Bruno Codenotti, Massimo Santini, Sebastiano Vigna. UbiCrawler: a scalable fully distributed Web crawler // Software: Practice and Experience – 2004. - C. 711-726.
- Robin Milner. Communicating and Mobile Systems: the Pi-Calculus // Cambridge, UK: Cambridge University Press – 1999. - 162 C.
- Пранскевичус В. А., Привалов М. В. Построение масштабируемого сфокусированного поискового робота с использованием принципа отложенных вычислений // Вестник ЛНТУ им. Шевченко – 2010. - С. 189-194.
- Simon Peyton Jones , Andrew Gordon , Sigbjørn Finne. Concurrent Haskell // Proceedings of the 23rd ACM SIGPLAN-SIGACT symposium on Principles of programming languages – 1996. - C. 295-308.
- Vladislav Shkapenyuk, Torsten Suel. Design and Implementation of a High-Performance Distributed Web Crawler // In Proc. of the Int. Conf. on Data Engineering – 2002. - C. 357-368.
- David Karger, Tom Leighton, Danny Lewin, and Alex Sherman. Web caching with consistent hashing // In Proc. of 8th International World–Wide Web Conference, Toronto, Canada – 1999.
- Larry Page, Sergey Brin, R. Motwani, T. Winograd. The PageRank Citation Ranking: Bringing Order to the Web // Stanford InfoLab – 1998.
- Making AJAX Applications Crawlable – Full Specification [Электронный ресурс]. Режим доступа: URL: http://code.google.com/web/ajaxcrawling/docs/specification.html
- Web Crawler – Wikipedia [Электронный ресурс]. Режим доступа: URL: http://en.wikipedia.org/wiki/Web_crawler
- GRUB Web Crawler [Электронный ресурс]. Режим доступа: URL: http://grub.org/