
Пранскевічус Владислав Олександрович
- Факультет
- Комп'ютерних наук і технологій
- Кафедра
- Автоматизованних систем управління
- Тема роботи
- Розробка розподіленого пошукового робота
- Науковий керівник
- к.т.н., доцент Привалов М. В.
Реферат на тему випускної роботи
Розробка розподіленого пошукового робота
Зміст
- Введення. Обгрунтування актуальності теми
- Цілі і завдання роботи
- Передбачувана наукова новизна і практична цінність
- Огляд існуючих досліджень і розробок по темі
- Дослідження
- Висновки
- Література
1. Введення. Обгрунтування актуальності теми
У зв'язку з бурхливим розвитком Всесвітньої павутини, з кожним днем все більш актуальною стає проблема автоматизованого збору та аналізу інформації, що розміщується на різних веб-ресурсах. Ще на початку 90-х років минулого століття Всесвітня павутина являла собою величезна кількість слабо структурованої інформації, проводити пошук в якій стало для людини практично непосильним завданням. Саме в цей час стали з'являтися перші розробки в сфері автоматизованих агентів, що полегшують завдання пошуку необхідної інформації в павутині. Основною частиною таких систем є пошуковий робот - програмний комплекс, що здійснює навігацію по веб-ресурсів та збір інформації для бази даних програми-агента[11].У загальному випадку, що збирається роботом інформація складається з веб-сторінок і посилальної структури вебу.
2. Цілі і завдання роботи
Об'єктом дослідження даної роботи є розподілений пошуковий робот. Основними завданнями розробки пошукового робота є:
- Вибір добре розподіляється, масштабованої і гнучкої архітектури;
- Забезпечення надійної роботи та взаємодії компонентів;
- Вибір метрики релевантністю веб-сторінки;
- Пошук оптимальних з точки зору продуктивності структур та алгоритмів обробки даних;
- Ефективна організація сховища даних.
Основною метою роботи є поліпшення масштабованості та продуктивності пошукових роботів шляхом використання гнучкої схеми паралелізації завдань.
Для формалізації архітектури пропонується використовувати π-числення [4], а для оцінки - метрики, запропоновані для веб-краулерів в [3]. Ці концепції описані більш детально в наступних розділах.
3. Передбачувана наукова новизна і практична цінність
Наукова новизна роботи полягає у формальному підході до дослідження конкурентних і паралельних процесів в пошуковому роботі, що дозволить виявити шляхи поліпшення політик паралелізації в пошукових роботах.
Практична цінність роботи полягає в тому, що розробляється система може використовуватися для швидкої розгортки розподілених і легко масштабованих веб-краулерів, вирішальних користувальницькі завдання. Також, дослідження конкурентних процесів з даної роботи можуть використовуватися і для побудови інших розподілених систем, відмінних від веб-краулери.
4. Огляд існуючих досліджень і розробок по темі
4.1 Локальний огляд
- Шади Абу Рок: "Дослідження властивостей пошукових систем ". У даній роботі досліджено загальні проблеми, які вирішуються сучасними пошуковими системами. Наведено математична модель, яка може бути використана в т.ч. для пошукової оптимізації.
4.2 Національний огляд
У національному масштабі не було виявлено активних досліджень за темою пошукових роботів.
4.3 Глобальний огляд
Дослідження в області пошукових роботів ведуться з самого моменту зародження Всесвітньої павутини. Можна виділити кілька основних напрямів досліджень:
- Архітектури пошукових роботів [2, 3, 7];
- P2P пошукові роботи [3, 12];
- Фокусовані пошукові роботи [5];
- Політики вибору і оновлення сторінок в пошукових роботах [9];
- Політики ввічливості.
У контексті даної роботи, найбільш цікавими є дослідження в області архітектур пошукових роботів і алгоритмів роботи P2P систем.
Однією з найбільш цитованих та фундаментальних робіт в області пошукових роботів є стаття Сергія Бріна і Ларрі Пейджа «The Anatomy of a Large-Scale Hypertextual Web Search Engine» [2], який описує архітектуру Googlebot за станом на 1998 рік. Безсумнівно, з тих пір Googlebot зазнав масу змін, однак у зв'язку з комерційною природою Google відкритих даних про це немає.
В роботі Junghoo Cho and Hector Garcia-Molina. «Parallel crawlers» [1]представлена класифікація архітектур паралельних пошукових роботів і метрики, використовувані для їх оцінки. Дана магістерська робота багато в чому базується на цих дослідженнях.
5. Дослідження
Завдання побудови ефективного пошукового робота є досить нетривіальною, з кількох причин:
- Всесвітня павутина є гетерогенної хаотично розвивається середовищем, велика частина ресурсів якої містить порушення прийнятих стандартів веб-розробки [10];
- у зв'язку з практично експоненціальним зростанням обсягів інформації у Всесвітній павутині, пошуковий робот повинен дозволяти ефективно обробляти велику кількість веб-ресурсів за кінцевий час і мати архітектуру, придатну для масштабування;
- пошуковий робот повинен бути досить універсальним для того, щоб гнучко підлаштовуватися під потреби використовує його застосування.
Завдяки величезним обсягам і гетерогенності Всесвітньої павутини, архітектура пошукового робота і зокрема політики паралелізму, закладені в ній, є цікавим об'єктом досліджень. На сьогоднішній день ключовим моментом, що визначає продуктивність пошукового робота є горизонтальна масштабованість його архітектури, тобто властивість системи збільшувати продуктивність при додаванні нових вузлів (комп'ютерів). Досить цікаве дослідження і спроба класифікації різних архітектур паралельних пошукових роботів представлені в[1].
Однак, існуючі архітектури пошукових роботів досить складні, і їх масштабованість часто далека від лінійної. Також, при масштабуванні можливе погіршення значень метрик якості збираної роботом інформації. Можна зробити висновок, що додаткові дослідження політик паралелізації пошукових роботів можуть поліпшити масштабованість і продуктивність робота, а також підвищити якість зібраних ним даних.
Враховуючи зазначені вище складності, пов'язані з обходом Всесвітньої павутини, архітектури та політики паралелізації пошукових роботів загального призначення спочатку розроблялися таким чином, щоб забезпечити максимально швидке отримання даних і простоту масштабування. Можна виділити такі два великі класи архітектур паралельних пошукових роботів:
- Централізовані архітектури - лежать в основі більшості використовуваних на сьогоднішній день пошукових роботів. Ці архітектури складаються з кількох потенційно розподілених конкурентних компонентів, що мають центральний пункт синхронізації (наприклад, черга завдань або спеціальний компонент-координатор). Яскравим прикладом пошукового робота, що має централізовану архітектуру є Googlebot [2]. Зазвичай при використанні централізованої архітектури застосовується внутрідоменная (intra-site) модель розподілу (відповідно до класифікації даної в [1]), при якій компоненти розподіляються всередині одного локального оточення. Структурна схема пошукового робота з централізованою архітектурою представлена на рис. 1.
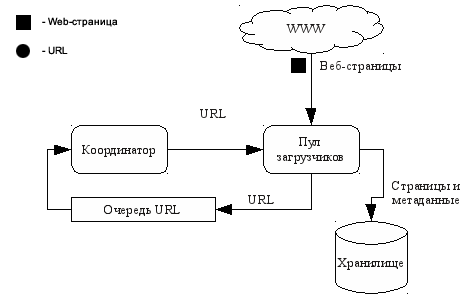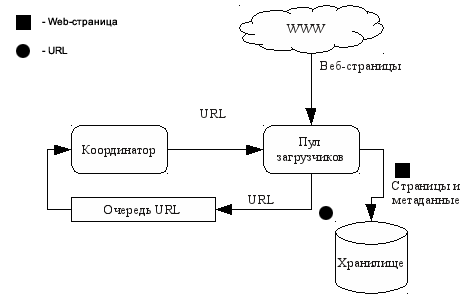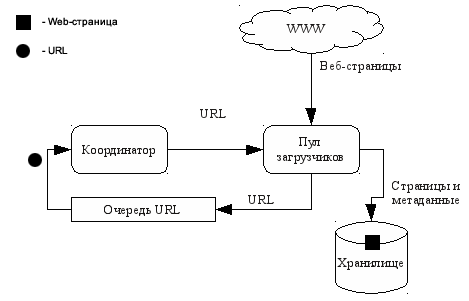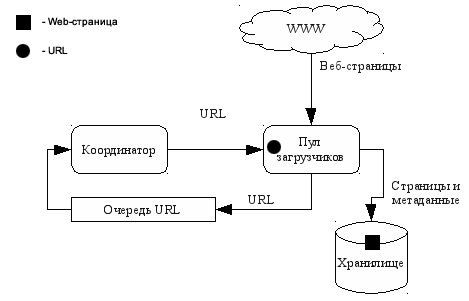
Рисунок 1: Централізована архітектура пошукового робота - Децентралізовані або мультиагентні архітектури - відрізняються повної (або наближеною до повної) децентралізацією компонентів. Побудова подібних систем вимагає дещо інших алгоритмів і методів, ніж тих, які використовуються в централізованих архітектурах [8], тому їх можна винести в окремий клас. Приклад використання децентралізованої архітектури наведено в[3].
На більш низькому рівні, архітектури пошукових роботів можуть відрізнятися методами розподілу завдань між компонентами, способами обміну URL і алгоритмом їх розподілу. Конфігурація конкретного пошукового робота може змінюватись в залежності від потреб використовує його застосування. Наприклад, для мінімізації обсяг даних і оптимізації продуктивності веб-краулери можуть використовуватися відкладені обчислення у формі абстракцій futures [5].
Для оцінки пошукових роботів, можна використовувати наступні метрики, запропоновані в [1].
- Дублювання (overlap) - оцінює обсяг надлишково завантажених сторінок і визначається за формулою:
де N - загальна кількість завантажених сторінок, I - кількість унікальних сторінок.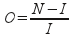
-
Покриття (coverage) - визначає обсяг сторінок, які повинні були бути завантажені, але
завдяки специфіці функцій розподілу адрес між агентами не були. Покриття можна
визначити наступним співвідношенням:
де I - кількість унікальних сторінок, U - загальна кількість сторінок.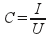
-
Якість (quality) - для визначення якості, припустимо існування гіпотетичного пророкує робота (oracle crawler), якому заздалегідь відомо значення важливості сторінки з якої-небудь метриці. Позначимо множину "цікавих"сторінок потужності N, завантажених пророкує роботом як PN, а аналогічне безліч сторінок, завантажених реальним роботом як AN. Виходячи з цього, можна визначити якість як:
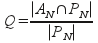
Перераховані вище метрики перебувають у прямій залежності від політик паралелізації, закладених в архітектурі пошукового робота, і мають тенденцію погіршуватися при розподілі конкурентних компонентів або збільшенні їх числа [1]. Цей факт явно показує необхідність подальших досліджень політик паралелізації.
Паралельний пошуковий робот, по своїй суті являє собою зразок системи з конкурентними обчисленнями, і отже до нього можуть бути застосовані математичні методи і моделі конкурентних обчислень. Однією з найбільш виразних моделей конкурентних обчислень є π-числення [4]. Π-числення є Т'юрінгом повної моделлю обчислень і є потужним інструментів для формалізації і дослідження конкурентних процесів з комплексними взаємодіями.
Базове π-числення пропонує наступні примітиви для опису процесів:
- конкурентність, позначається як P | Q, где P, Q — процеси;
- вхідний префікс, c(x).P визначає процес P, який очікує повідомлення x, яке повинно бути доставлено по каналу с;
- вихідний префікс с(y).P, який визначає процес P, здійснює відправку імені y по каналу с;
- створення нового імені, (υx)P створює локальне ім'я x в контексті процесу P.
Як приклад визначення процесу в термінах π-числення можна розглянути процес Fetch, що виконує безпосередню завантаження сторінки з даного URL:
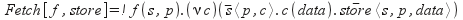
Даний процес є абстракцію π-числення (тобто параметризують); URL у вигляді (s, p), де s - сервер, p - сторінка, приймається по каналу f, потім відбувається запит сторінки з сервера з подальшим її отриманням за каналу з параметром data. Потім data передається по каналу store в сховище.
Таким чином, за допомогою π-числення можна промоделювати інші компоненти системи, що дозволить більш формально підійти до дослідження архітектур веб-краулерів і політик паралелізації. π-числення дозволяє моделювати складні взаємодії між компонентами системи і проводити структурні перетворення за допомогою механізмів бісімуляціі і структурної конгруентності процесів.
У теорії конкурентних обчислень прийнято виділяти два основних механізми взаємодії: взаємодія за допомогою спільної пам'яті і взаємодію шляхом передачі повідомлень. Це розділення також знаходить відображення в реалізаціях мов програмування та фреймворків. У семантиці π-числення закладено межпроцессное взаємодія за допомогою передачі повідомлень, що необхідно враховувати при виборі засобів реалізації пошукового робота.
Основними вимогами, висунутими до мови реалізації є:
- наявність високорівневих конструкцій і засобів для функціональної декомпозиції системи і створення необхідних абстракцій;
- виразність, близька до формального математичного опису системи;
- наявність вбудованих засобів для опису конкурентних обчислень, що дозволяють легко реалізувати процеси системи та їх взаємодії;
- наявність якісних, підтримуваних спільнотою розробників бібліотек, наприклад для мережевих взаємодій, протоколів обміну повідомленнями, розбору HTML сторінок, роботи з СУБД і т. п.;
- відкритість і загальнодоступність реалізації мови та інструментів розробки.
З урахуванням висунутих вимог, в якості мови реалізації була вибрана мова програмування Haskell (http://www.haskell.org). Haskell відноситься до сімейства мов ML і являє собою чистий функціональний мову з відкладеними обчисленнями. Haskell володіє суворої статичної типізацією з автоматичним виведенням типів за моделлю Хиндлі-Мілнер, підтримкою алгебраїчних і рекурсивних типів даних, викликом функції за зразком.
Визначальним фактором у виборі саме цієї мови програмування стала його просунута реалізація примітивів конкурентних обчислень (Concurrent Haskell), близька за семантикою до π-числення [6]. Примітиви Concurrent Haskell реалізують всі основні операції π-числення, крім недетермінірованного вибору, який тим не менш може бути реалізований у випадку необхідності за допомогою інших примітивів.
6. Висновки
Специфіка завдання обходу Всесвітньої павутини призводить до неминучого використання конкурентних обчислень при розробці пошукових роботів. Для ефективної реалізації конкурентності та хорошою масштабованості пошукового робота, необхідно приділяти чималу увагу розробці архітектури системи і політик паралелізації.
Проаналізувавши існуючі архітектури, політики паралелізації і методи побудови пошукових роботів, для розробляється системи була обрана децентралізована архітектура. Також було запропоновано використання π-числення як механізму формалізації і подальшого дослідження політик паралелізації пошукових роботів. Для самої реалізації пошукового робота була вибрана мова програмування Haskell і його розширення Concurrent Haskell як найбільш близький до семантикою π-числення спосіб опису конкурентних обчислень.
Важливе зауваження: На момент написання даного реферату магістерська робота ще не закінчена. Остаточне завершення роботи відбудеться в грудні 2011 року. У найближчому майбутньому планується розробка архітектури та реалізація прототипу пошукового робота, порівняння його з іншими реалізаціями.
Література
- Cho J., Garcia-Molina H. Parallel crawlers // In Proc. of the 11th International World–Wide Web Conference – 2002. - 13 C.
- Brin S., Page L. The Anatomy of a Large-Scale Hypertextual Web Search Engine // Computer Science Department, Stanford University, Stanford — 1998. - C. 107-117.
- Boldi P., Codenotti B., Santini M., Vigna S. UbiCrawler: a scalable fully distributed Web crawler // Software: Practice and Experience – 2004. - C. 711-726.
- Milner R. Communicating and Mobile Systems: the Pi-Calculus // Cambridge, UK: Cambridge University Press – 1999. - 162 C.
- Пранскевичус В. А., Привалов М. В. Построение масштабируемого сфокусированного поискового робота с использованием принципа отложенных вычислений // Вестник ЛНТУ им. Шевченко – 2010. - С. 189-194.
- Jones S. P. , Gordon A. , Finne S. Concurrent Haskell // Proceedings of the 23rd ACM SIGPLAN-SIGACT symposium on Principles of programming languages – 1996. - C. 295-308.
- Shkapenyuk V., Suel T. Design and Implementation of a High-Performance Distributed Web Crawler // In Proc. of the Int. Conf. on Data Engineering – 2002. - C. 357-368.
- Karger D., Leighton T., Lewin D., Sherman A. Web caching with consistent hashing // In Proc. of 8th International World–Wide Web Conference, Toronto, Canada – 1999. - C. 1203-1213.
- Page L., Brin S., Motwani R., Winograd T. The PageRank Citation Ranking: Bringing Order to the Web // Stanford InfoLab – 1998. - 17 C.
- Making AJAX Applications Crawlable – Full Specification [Электронный ресурс]. Режим доступа: URL: http://code.google.com/web/ajaxcrawling/docs/specification.html
- Web Crawler – Wikipedia [Электронный ресурс]. Режим доступа: URL: http://en.wikipedia.org/wiki/Web_crawler
- GRUB Web Crawler [Электронный ресурс]. Режим доступа: URL: http://grub.org/