
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность очистки данных
- 2. Постановка проблемы очистки данных
- 3.Классификация существующих ошибок
- 4 Методы и средства очистки данных в современных корпоративных информационных системах
- 5 Тип ошибок. Пропуски в данных
- 6 Тип ошибок. Противоречивость информации
- 7 Тип ошибок. Дублирование
- 8 Тип ошибок. Несоответствие форматов
- Выводы
- Список источников
Введение
В современном мире качественная информация в крупных корпорациях играет ключевую роль. И многие проекты напрямую зависят от качества данных и реализации их на предприятии. Поэтому очень важно, чтобы каждый филиал предоставляющий такие данные, содержал лишь небольшой коэффициент «загрязненных» данных, иначе при их интеграции в Хранилище данных процент «загрязнения» растет по экспоненциальному закону.
Очистка данных (data cleaning, data cleansing или scrubbing) занимается выявлением и удалением ошибок и несоответствий в данных с целью улучшения качества данных [5].
1. Актуальность темы
На сегодняшний день в огромные корпорации поступают и обрабатываются огромное количество данных, особенно персональных, собранных со всех филиалов компании. В каждом филиале своя структура базы данных, и после интеграции в единый источник данных (например, в Хранилища данных (ХД)), возникает проблема извлечения достоверных данных по причине разрозненных данных в различном представлении, которые необходимо в дальнейшем использовать для анализа. Такие данные будут низкого качества, так как в них допускались ошибки, и обрабатывать их теряет всякий смысл. Поэтому, для получения реальных выводов из существующих данных, применяют различные методы по их коррекции, исключении дубликатов и очистки.
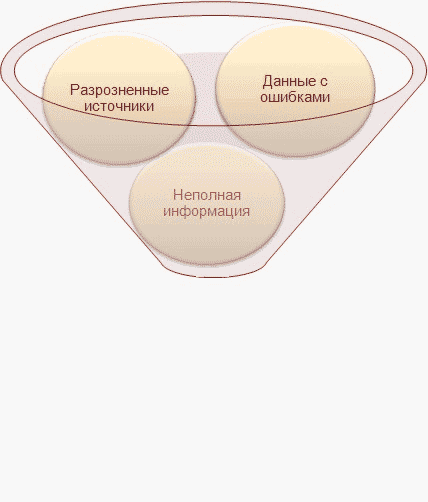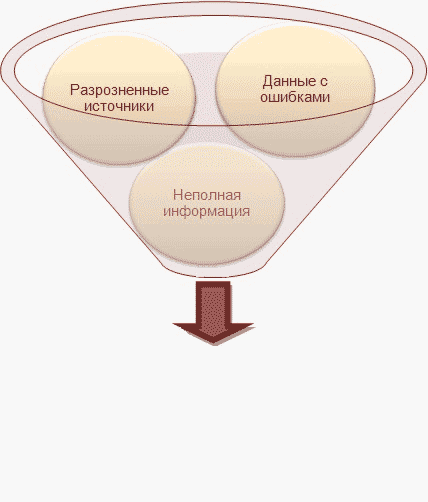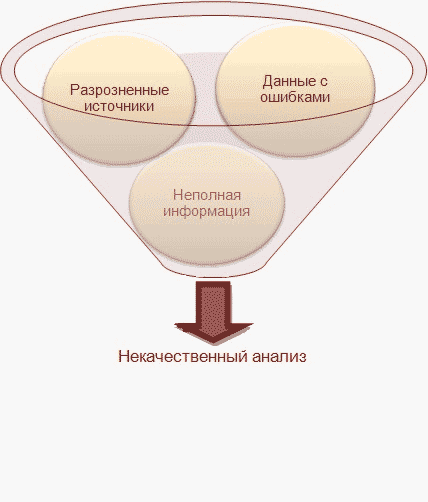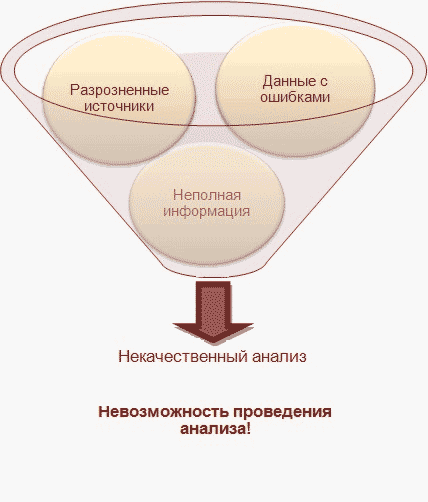
Рисунок 1 – Главная проблема в данных
(анимация: 4 кадров, 6 циклов повторения, 69 килобайт)
Таким образом, задача очистки данных в корпоративных информационных системах на сегодняшний день является актуальной.
2. Постановка проблемы очистки данных
В настоящее время на рынке существует множество фирм, предлагающие свои прогрммы по очистке данных, таких как: Trillium Software, Group-1 Software, Innovative Systems, Vality/Ascential Software, First Logic, Deductor и другие [7], которые помогают выявить и автоматически исправить наиболее важные типы в персонализации данных (например: имена и адреса людей с использованием национального каталога имен и адресов). Но эти средства не идеальны. Они не могут работать со всеми типами «грязных» данных, и по этой причине, не все компании используют уже существующие средства. Не маловажную роль в их применении также играет и стоимость этих программных пакетов. Недостаточное внимание, уделяемое качеству данных, связано с тем, что отсутствует понимание типов, объема загрязненности (которые были импортированы в Хранилища данных), их влияния (они будут в будущем влиять на достоверность полученной информации из Хранилища данных).

Рисунок 2 – Процесс очистки данных
(анимация: 5 кадров, 5 циклов повторения, 37,9 килобайт)
Для начала корпорациям необходимо разобраться в многообразии возможных «грязных» данных, в источниках их появления, методах их обнаружения и очистки[6].
| Ф.И.О. | Пол | Город | Адрес | Модель машины | Телефон |
|---|---|---|---|---|---|
| ... | ... | ... | ... | ... | ... |
| Иванов И.И. | М | Ул. Ходаковского д.6б кв. 5 | Corolla | +380502456987 | |
| Петров П.П. | ж | Макеевка | Улица Ленина д. 7 | Camry | 0635689568 |
| Сидоров С.С. | Донецк | Просп. Ильича д. 6 кв.8 | Yaris | (067) 356-87-98 | |
| Сидоров С.С. | M | Донецк | Просп. Ильича д. 6 кв.8 | Yaris | (067) 356-87-98 |
| ... | ... | ... | ... | ... | ... |
3. Классификация существующих ошибок
Существует множество видов ошибок, которые не зависят от предметной области. Таких ошибок выделяют шесть типов:
- Противоречивостью информации называется такая информация, которая не соответствует законам, правилам или действительности. Сначала решается, что именно необходимо считать противоречивым. Например, по законам Украины пенсионную карту меняют в случае изменения Ф.И.О., но если человек родился мужчиной, а вышел на пенсию женщиной, противоречивость отсутствует [3].
- Аномальными значениями называются такие значения, которые сильно выбиваются в целом из общей картины. Чаще всего такие значения корректируют вручную. Это связано с тем, что такие средства прогнозирования ничего не знают о природе процессов. Поэтому любая аномалия будет восприниматься как совершенно нормальное значение. Из-за этого будет сильно искажаться картина будущего. Какой-то случайный провал или успех будет считаться закономерностью [3].
- Пропусками данных называется такой тип ошибок, если в полях для заполнения отсутствуют данные или заполнены не до конца. Эта проблема считается очень серьезной для большинства ХД. Большинство методов прогнозирования исходят из предположения, что данные поступают равномерным постоянным потоком. На практике такое можно встретить редко. Поэтому одна из самых востребованных областей применения ХД – прогнозирование – оказывается реализованной некачественно или со значительными ограничениями [3].
- Шум – это данные, в которых показания значительно выше или ниже оптимальных значений. Часто при анализе данных сталкиваются с шумами. Он не несет никакой ценной информации, только мешает четко разглядеть картину.
- Несоответствие форматов данных. Несоответствие форматов данных называются однотипные данные, имеющие разные форматы представления.
- Ошибки ввода данных или опечатки преобладают в любых данных, т.к. вводятся человеком. Опечатки – это такой тип ошибок, когда данные содержат пропущенные, лишние символы или искаженные данные.
- Дублирование – это повторяющиеся данные. Повторение различных данных – самая распространенная ошибка при работе с данными, которые заносятся в Хранилища данных.
Исходя из приведенных выше данных можно выявить такие типы ошибок как:
- пропуски данных (не указан город);
- дублирование (Сидоров С.С. и Сидоров С.С.);
- противоречивость информации (Петров П.П. ж);
- несоответствие форматов данных (Ул. улица, Ул).
4. Методы и средства очистки данных в современных корпоративных информационных системах
На сегодняшний день существует огромное количество методов по очистке данных от ошибок и неточностей. Никто из специалистов не скажет, какой из них является самым эффективным, потому что каждый метод совершенно по-разному подходит к этой проблеме.
Данную проблему решают тремя разными способами:
- простыми методами;
- методами, которые основываются на понятиях математической статистики;
- средства ETL (от англ. Extract, Transform, Load — дословно «извлечение, преобразование, загрузка» — один из основных процессов в управлении хранилищами данных [5]).
Простые методы (регулярные выражения, строгие формальные правила и т.д.) очень примитивны и могут решить данную задачу только частично, поэтому ученые решили задействовать математическую статистику и интеллектуальные методы.
Рассчитываются необходимые показатели по всем данным, которые есть в наличии, т.е. охватывает весь диапазон существующих значений и принимаемых признаками. На основе полученных результатов одни методы могут выделить подозрительную информацию, которая сильно отличается от остальных, а другие – вычислить величины, которые предположительно более всего похожи на истинные. Таким образом, анализируя сведения с помощью статистических характеристик, оценивают общую картину данных и уже на ее фоне определяют возможные ошибки с последующим их исправлением на подобранные похожие значения [2].
5. Тип ошибок. Пропуски в даннях
Этот тип ошибок можно решить двумя различными способами:
- Методом машинного словаря. Он представляет собой упорядоченное множество лингвистической информации, которая хранится в памяти компьютера в определенном виде. Метод ищет необходимое проверяемое слово в заранее составленном машинном словаре. В него должны входить всевозможные значения, принимаемые данным полем. При работе с личной информацией используются классификаторы. Классификатор – это словарь, состоящий из названий объектов, классификационных группировок, на которые они разбиты по степени сходства, и идентифицирующих их кодов. Например, классификатор телефонных кодов и мобильных операторов, классификатор адресов и так далее. При помощи именно классификаторов можно избавляться от пропусков в полях. Тогда незаполненная часть информации ищется в классификаторе по имеющимся данным. Если будет найден только один подходящий вариант, то он вносится вместо пропуска. В ином случае все найденные значения выдаются эксперту, принимающему решение, который выбирает, какой из вариантов более близок к исходному [2].
- Интеллектуальный метод. Иногда в данных бывает так, что забывают указать город или индекс в поле адреса, тогда можно воспользоваться «улучшением». Улучшением служит добавление к уже существующей информации ряд фактов, например, можно добавить страну, область, район, долгота и широта указанной местности и т.д. Также можно с помощью этого метода присвоить клиентам пол на основании анализа его имени и других показателей его профайла. Наиболее же ценным дополнением клиентского профайла являются дополнительные данные, то есть данные третьих фирм, которые содержат демографическую и психографическую информацию [2].
6. Тип ошибок. Противоречивость информации.
- Простой метод. С помощью классификатора идентифицирующие коды определяют «грязные» данные. Если хотя бы одному проверяемому значению не будет сопоставлен его код или полученные коды связанных данных противоречат друг другу, то в них, скорее всего, была допущена ошибка. Для того чтобы устранить ее, необходимо проверить поля по отдельности на наличие опечаток или рассматривают дополнительные значения, по которым возможно будут восстановлены потерянные данные. Затем снова необходимо производить поиск кодов в классификаторе с уже новыми полученными данными до тех пор, пока не будет устранен этот тип ошибок [2].
- Проверка допустимости. Бывает так, что человек может ввести неправильный код города, в котором проживает или же город, может быть не сопоставим с районом проживания и т.д. В этом случае необходимо использовать интеллектуальные средства, с помощью которых возможно осуществить распознавание допустимых международных адресов. Некоторые приложения объединяются с программами проверки допустимости и файлами почтовых адресов, проверяющих допустимость международных адресных данных [1].
7. Тип ошибок. Дублирование
- Метод «жестких» правил. Суть метода подразумевает поэтапное сравнение параметров объектов с применением «жестких» правил расчета коэффициентов
совпадения по каждому проверяемому полю. Полученный коэффициент схожести объектов рассчитывается как сумма коэффициентов по каждому полю и, если
его значение превышает заданный порог, то объекты считаются дубликатами. На рисунке 1 механизм работы представлен.
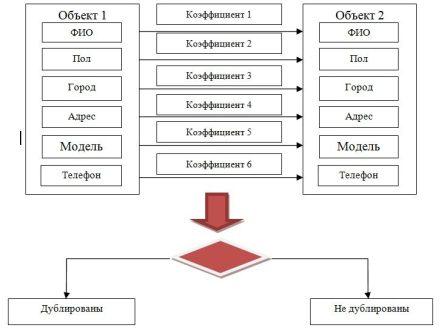
Рисунок 3 – Схема работы метода «жестких» правил- Самообучающийся алгоритм поиска дубликатов. Этот метод основан на применении самообучающихся моделей для поиска потенциальных дубликатов. Модуль состоит из таких шагов: обучение и применение моделей. На первом шаге необходимо подготовить выборку данных, на которой будет происходить обучение модели. После этого шага модель вводится в режим промышленной эксплуатации. Применение данного подхода подразумевает периодическое переобучение построенных моделей, что позволяет адаптировать их под изменения в данных.
- Сравнение и обработка результатов. Данный модуль обеспечивает сравнение и оценку результатов, полученных с применением «жестких» правил и самообучающихся моделей. Кроме того, формируется итоговый набор потенциально схожих объектов. Затем потенциальные дубликаты подвергаются группировке, правила которой всегда индивидуальны, в зависимости задач. Один из доступных вариантов объединения дубликатов – формирование групп схожих клиентов, которые проживают в одном районе или город [4].
- Согласование и консолидация. Согласование необходимо для расстановки приоритетов между полями (в процессе согласования) и контроля очередности сравнения полей.
8. Тип ошибок. Несоответствие форматов
Стандартизации. Данные имен, телефонов и адресов могут вводиться в разных форматах, которые вполне грамматически корректны. Например, “Улица”, “Ул.” и “Ул” обозначают одно и то же очевидное понятие в составе адреса. Или же номера телефонов “(063) 111 11 11”, “+380631111111” и “+38(063)1111111”. У почтовой и телефонной службы существуют стандарты для этих и других подобных случаев (пока только такие службы существует в Соединенных Штатов Америки и в России). Самым важным объектом стандартизации являются записи по клиентам, точность которых может быть существенно повышена за счет использования процесса согласования, описанного далее. Специальные программы стандартизации трансформируют такие поля в определенный шаблон, подходящий для почтовой и телефонной службы.
Заключение
Несмотря на то, что существуют множество платформ, систем, инструментов для преобразования и очистки данных, их все равно не хватает. Эти средства идеально не уберут дублирование, потери данных, несоответствия. Поэтому и сейчас специалисты пытаются найти оптимальные вариации для решения очистки данных
Список источников
1. Чубукова И.А. Статья: Процесс Data Mining. Начальные этапы [электронный ресурс] — Режим доступа: http://www.intuit.ru/...
2. Беликова Александра. Статья: Проблема обработки персональных данных [электронный ресурс] — Режим доступа: http://www.basegroup.ru/library/...
3. Арустамов Алексей. Статья: Предобработка и очистка данных перед загрузкой в хранилище [электронный ресурс] — Режим доступа: http://sysdba.org.ua/proektirovanie-bd/etl/predobrabotka-i-ochistka-dannyih-pered-zagruzkoy-v-hranilische.html
4. Basegroup. Статья: Технология обработки клиентских баз [электронный ресурс] — Режим доступа: http://www.dupmatch.com/...
5. Статья: ETL. [электронный ресурс] — Режим доступа: http://ru.wikipedia.org/wiki/ETL
6. Вон Ким. Статья: Три основных недостатка современных хранилищ данных [электронный ресурс] — Режим доступа: http://citforum.ru/data...
7. Роналд Фоурино. Статья: Электронное качество данных: скрытая перспектива очистки данных [электронный ресурс] — Режим доступа: http://www.iso.ru/р... - Электронный ресурс, хранящий статьи, которые были обублекованные в известных журналах