
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования, планируемые результаты
- 3. Анализ методов в условиях поставленной задачи
- 3.1 Кластерный анализ
- 3.2 Типология задач кластеризации
- 3.3 Обзор выбранного метода
- 3.4 Подход к тестированию. Психометрия
- 4. Предложения по структуре магистерской работы
- Выводы
- Список источников
Введение
Система поддержки принятия решений(СППР) предназначена для поддержки многокритериальных решений в сложной информационной среде. При этом под многокритериальностью понимается тот факт, что результаты принимаемых решений оцениваются не по одному, а по совокупности многих показателей (критериев), рассматриваемых одновременно.
Информационная сложность определяется необходимостью учета большого объема данных, обработка которых без помощи современной вычислительной техники практически невыполнима. В этих условиях число возможных решений, как правило, весьма велико, и выбор наилучшего из них «на глаз» без всестороннего анализа может приводить к грубым ошибкам.
СППР решает две основные задачи:
-выбор наилучшего решения из множества возможных (оптимизация);
-упорядочение возможных решений по предпочтительности (ранжирование).
В обеих задачах принципиальным моментом является выбор совокупности критериев, на основе которых в дальнейшем будут оцениваться и сопоставляться возможные (альтернативные) решения. Система СППР помогает пользователю сделать такой выбор. СППР, или DSS — мощный инструмент помощи лицу, принимающему решения. Это единая система данных, моделей и средств доступа к ним (интерфейс). Роль СППР не ограничивается хранением данных и выдачей требуемых отчетов. СППР призваны улучшить работу использующих знания людей путем применения информационных технологий. В свою очередь, СППР можно условно разделить на два типа. Это так называемые информационные системы руководства (EIS), предназначенные для немедленного реагирования на текущую ситуацию, и СППР с глубокой проработкой данных.
При этом результатом применения СППР, как правило, является получение рекомендаций и прогнозов, которые носят скорее эвристический характер и не всегда являются прямым указанием к дальнейшим действиям.
Для анализа и выработки предложений в СППР используются разные методы. Среди них: информационный поиск, интеллектуальный анализ данных, поиск знаний в базах данных, рассуждение на основе прецедентов, имитационное моделирование, генетические алгоритмы, нейронные сети и др. Некоторые из них были разработаны в рамках искусственного интеллекта. Если в основе работы системы лежит один или несколько таких методов, то говорят об интеллектуальной СППР (ИСППР). [1]
1. Актуальность темы
Современный страховой бизнес невозможно представить без эффективных информационных технологий, однако выбор оптимального IT-решения с учетом перспективных и текущих бизнес-задач страховой компании до сих пор остается весьма непростым делом. Как правило, этот выбор основан на тщательном анализе.
Помимо классических задач выбора страховой компании для страхования жизни, имущества, автострахования, в настоящее время в связи с проведением в Украине реформ в сферах здравоохранения и пенсионном обеспечении возникают новые вопросы выбора страховой компании. В частности, необходимо будет выбирать каждому оптимальную для себя компанию для медицинского страхования и негосударственного пенсионного фонда (II этап пенсионной реформы). Развитие негосударственных форм пенсионного и медицинского страхования в Украине приближают нас к европейским стандартам жизни, а также требует (более) современного, научно обоснованного, достоверного и эффективного выбора более подходящей для каждого гражданина компании для различных видов и сфер страхования.
Итак, вопрос выбора страховой компании в Украине в текущее время довольно актуален, и большой поток зарубежных и новых отечественных компаний предлагают широкий диапазон услуг при различном уровне надёжности. Чтобы сделать правильный выбор в этом разнообразии вариантов необходимо иметь надежный и в то же время простой в использовании инструмент принятия решений.
2. Цель и задачи исследования, планируемые результаты
Целью работы является разработка СППР, предоставляющая удобные сервисы для выбора страховой компании, наилучшим образом удовлетворяющая требованиям клиента.
Для достижения поставленной цели необходимо решить задачи:
- Определить критерии для классификации страховых компаний;
- Проанализировать методы кластеризации применительно к группировке компаний;
- Разработать тестовые вопросы и выполнить их критеризацию по выбранным параметрам;
- Разработать СППР.
3. Анализ методов в условиях поставленной задачи
Поставленную задачу можно решить проведением кластерного анализа, использованием адаптивных нейронных сетей, что добавит динамизма и универсальности в предложенную модель системы.
3.1 Кластерный анализ
Кластерный анализ выполняет следующие основные задачи:
- Разработка типологии или классификации.
- Исследование полезных концептуальных схем группирования объектов.
- Порождение гипотез на основе исследования данных.
- Проверка гипотез или исследования для определения, действительно ли типы (группы), выделенные тем или иным способом, присутствуют в имеющихся данных.
Применение кластерного анализа предполагает следующие этапы:
- Отбор выборки для кластеризации.
- Определение множества переменных, по которым будут оцениваться объекты в выборке.
- Вычисление значений той или иной меры сходства между объектами.
- Применение метода кластерного анализа для создания групп сходных объектов.
- Проверка достоверности результатов кластерного решения.
Кластерный анализ предъявляет следующие требования к данным:
- показатели не должны кореллировать между собой;
- показатели должны быть безразмерными;
- распределение показателей должно быть близко к нормальному;
- показатели должны отвечать требованию «устойчивости», под которой понимается отсутствие влияния на их значения случайных факторов;
- выборка должна быть однородна, не содержать «выбросов».
Если кластерному анализу предшествует факторный анализ, то выборка не нуждается в «ремонте» — изложенные требования выполняются автоматически самой процедурой факторного моделирования (есть ещё одно достоинство — z-стандартизация без негативных последствий для выборки; если её проводить непосредственно для кластерного анализа, она может повлечь за собой уменьшение чёткости разделения групп). В противном случае выборку нужно корректировать. [3]
При анализе результатов социологических исследований рекомендуется осуществлять анализ методами иерархического агломеративного семейства, а именно методом Уорда, при котором внутри кластеров оптимизируется минимальная дисперсия, в итоге создаются кластеры приблизительно равных размеров. Метод Уорда наиболее удачен для анализа социологических данных. В качестве меры различия лучше квадратичное евклидово расстояние, которое способствует увеличению контрастности кластеров. Главным итогом иерархического кластерного анализа является дендрограмма или «сосульчатая диаграмма». При её интерпретации исследователи сталкиваются с проблемой того же рода, что и толкование результатов факторного анализа — отсутствием однозначных критериев выделения кластеров. В качестве главных рекомендуется использовать два способа — визуальный анализ дендрограммы и сравнение результатов кластеризации. Визуальный анализ дендрограммы предполагает «обрезание» дерева на оптимальном уровне сходства элементов выборки. «Виноградную ветвь» (терминология Олдендерфера М. С. и Блэшфилда Р. К.) целесообразно «обрезать» на отметке 5 шкалы Rescaled Distance Cluster Combine, таким образом будет достигнут 80 % уровень сходства. Если выделение кластеров по этой метке затруднено (на ней происходит слияние нескольких мелких кластеров в один крупный), то можно выбрать другую метку.
Теперь возникает вопрос устойчивости принятого кластерного решения. Проверка устойчивости кластеризации сводится к проверке её достоверности. Здесь существует эмпирическое правило — устойчивая типология сохраняется при изменении методов кластеризации. Результаты иерархического кластерного анализа можно проверять итеративным кластерным анализом по методу k-средних. Если сравниваемые классификации групп респондентов имеют долю совпадений более 70 % (более 2/3 совпадений), то кластерное решение принимается.
Проверить адекватность решения, не прибегая к помощи другого вида анализа, нельзя. По крайней мере, в теоретическом плане эта проблема не решена. В классической работе Олдендерфера и Блэшфилда «Кластерный анализ» подробно рассматриваются и в итоге отвергаются дополнительные пять методов проверки устойчивости:
- кофенетическая корреляция — не рекомендуется и ограниченна в использовании;
- тесты значимости (дисперсионный анализ);
- методика повторных (случайных) выборок;
- тесты значимости для внешних признаков пригодны только для повторных измерений;
- методы Монте-Карло.
3.2 Типология задач кластеризации
Типы входных данных:
- Признаковое описание объектов. Каждый объект описывается набором своих характеристик, называемых признаками. Признаки могут быть числовыми или нечисловыми.
- Матрица расстояний между объектами. Каждый объект описывается расстояниями до всех остальных объектов обучающей выборки.
Цели кластеризации:
- Понимание данных путём выявления кластерной структуры. Разбиение выборки на группы схожих объектов позволяет упростить дальнейшую обработку данных и принятия решений, применяя к каждому кластеру свой метод анализа (стратегия «разделяй и властвуй»).
- Сжатие данных. Если исходная выборка избыточно большая, то можно сократить её, оставив по одному наиболее типичному представителю от каждого кластера.
- Обнаружение новизны: выделяются нетипичные объекты, которые не удаётся присоединить ни к одному из кластеров.
В первом случае число кластеров стараются сделать поменьше. Во втором случае важнее обеспечить высокую степень сходства объектов внутри каждого кластера, а кластеров может быть сколько угодно. В третьем случае наибольший интерес представляют отдельные объекты, не вписывающиеся ни в один из кластеров.
Во всех этих случаях может применяться иерархическая кластеризация, когда крупные кластеры дробятся на более мелкие, те в свою очередь дробятся ещё мельче, и т. д. Такие задачи называются задачами таксономии.
Результатом таксономии является древообразная иерархическая структура. При этом каждый объект характеризуется перечислением всех кластеров, которым он принадлежит, обычно от крупного к мелкому.
Среди методов кластеризации выделяют:
- K-средних (K-means).
- Метод нечеткой кластеризации C-средних (C-means).
- Графовые алгоритмы кластеризации.
- Статистические алгоритмы кластеризации.
- Алгоритмы семейства FOREL.
- Иерархическая кластеризация или таксономия.
- Нейронная сеть Кохонена.
- Ансамбль кластеризаторов.
- Алгоритмы семейства КRAB.
- EM-алгоритм.
- Алгоритм, основанный на методе просеивания.
Метод K-средних (K-means)
Алгоритм представляет собой версию EM-алгоритма, применяемого также для разделения смеси гауссиан. Он разбивает множество элементов векторного пространства на заранее известное число кластеров k.
Основная идея в том, что на каждой итерации перевычисляется центр масс для каждого кластера, полученного на предыдущем шаге, затем векторы разбиваются на кластеры вновь в соответствии с тем, какой из новых центров оказался ближе по выбранной метрике.
Алгоритм завершается, когда на какой-то итерации не происходит изменения кластеров. Это происходит за конечное число итераций, так как количество возможных разбиений конечного множество конечно, а на каждом шаге суммарное квадратичное уклонение V уменьшается, поэтому зацикливание невозможно.
Демонстрация алгоритма
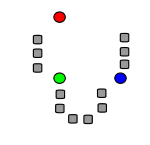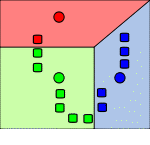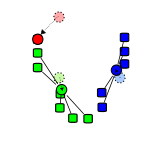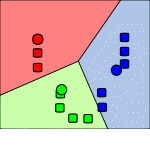
Рисунок 2 – Действие алгоритма в двумерном случае. Начальные точки выбраны случайно.
(анимация: 4 кадра, 10 циклов повторения, 16 килобайт)
Кадр 1 – Исходные точки и случайно выбранные начальные точки.
Кадр 2 – Точки, отнесённые к начальным центрам. Разбиение на плоскости —
диаграмма Вороного относительно начальных центров.
Кадр 3 – Вычисление новых центров кластеров (Поиск центра масс).
Кадр 4 – Предыдущие шаги повторяются, пока алгоритм не сойдётся. [8]
Проблемы k-means:
- Не гарантируется достижение глобального минимума суммарного квадратичного уклонения V, а только одного из локальных минимумов.
- Результат зависит от выбора исходных центров кластеров, их оптимальный выбор неизвестен.
- Число кластеров надо знать заранее.
Широко известна и используется нейросетевая реализация K-means - сети векторного квантования сигналов (одна из версий нейронных сетей Кохонена).
Нейронные сети Кохонена — класс нейронных сетей, основным элементом которых является слой Кохонена. Слой Кохонена состоит из адаптивных линейных сумматоров («линейных формальных нейронов»). Как правило, выходные сигналы слоя Кохонена обрабатываются по правилу «победитель забирает всё»: наибольший сигнал превращается в единичный, остальные обращаются в нуль.
По способам настройки входных весов сумматоров и по решаемым задачам различают много разновидностей сетей Кохонена. Наиболее известные из них:
- Сети векторного квантования сигналов, тесно связанные с простейшим базовым алгоритмом кластерного анализа (метод динамических ядер или K-средних)
- Самоорганизующиеся карты Кохонена (Self-Organising Maps, SOM)
- Сети векторного квантования, обучаемые с учителем (Learning Vector Quantization).
Метод нечеткой кластеризации C-средних (C-means) позволяет разбить имеющееся множество векторов (точек) мощностью p на заданное число нечетких множеств. Особенностью метода является использование нечеткой матрицы принадлежности U с элементами uij, определяющими принадлежность i-го элемента исходного множества векторов - j-му кластеру. Кластеры описываются своими центрами сj - векторами того же пространства, которому принадлежит исходное множество векторов.
В ходе решения задачи нечеткой кластеризации C-means решается задача минимизации следующей целевой функции E=∑∑uijm•||xi-cj||² при ограничениях ∑juij=1, i=1..p.
FOREL (Формальный Элемент) — алгоритм кластеризации, основанный на идее объединения в один кластер объектов в областях их наибольшего сгущения.
Цель кластеризации - разбить выборку на такое (заранее неизвестное число) таксонов, чтобы сумма расстояний от объектов кластеров до центров кластеров была минимальной по всем кластерам. То есть наша задача — выделить группы максимально близких друг к другу объектов, которые в силу гипотезы схожести и будут образовывать наши кластеры.
Необходимые условия работы:
- Выполнение гипотезы компактности, предполагающей, что близкие друг к другу объекты с большой вероятностью принадлежат к одному кластеру (таксону).
- Наличие линейного или метрического пространства кластеризуемых объектов.
Входные данные: кластеризуемая выборка может быть задана признаковыми описаниями объектов — линейное пространство либо матрицей попарных расстояний между объектами.
Замечание: в реальных задачах зачастую хранение всех данных невозможно или бессмысленно, поэтому необходимые данные собираются в процессе кластеризации.
Параметр R — радиус поиска локальных сгущений. Его можно задавать как из априорных соображений (знание о диаметре кластеров), так и настраивать скользящим контролем. В модификациях возможно введение параметра k — количества кластеров.
Выходные данные: кластеризация на заранее неизвестное число таксонов.
На каждом шаге мы случайным образом выбираем объект из выборки, раздуваем вокруг него сферу радиуса R, внутри этой сферы выбираем центр тяжести и делаем его центром новой сферы. Т.о. мы на каждом шаге двигаем сферу в сторону локального сгущения объектов выборки, то есть стараемся захватить как можно больше объектов выборки сферой фиксированного радиуса. После того как центр сферы стабилизируется, все объекты внутри сферы с этим центром мы помечаем как кластеризованные и выкидываем их из выборки. Этот процесс мы повторяем до тех пор, пока вся выборка не будет кластеризована.
Алгоритм:
- Случайно выбираем текущий объект из выборки.
- Помечаем объекты выборки, находящиеся на расстоянии менее, чем R от текущего.
- Вычисляем их центр тяжести, помечаем этот центр как новый текущий объект.
- Повторяем шаги 2-3, пока новый текущий объект не совпадет с прежним.
- Помечаем объекты внутри сферы радиуса R вокруг текущего объекта как кластеризованные, выкидываем их из выборки.
- Повторяем шаги 1-5, пока не будет кластеризована вся выборка.
Эвристики выбора центра тяжести: в линейном пространстве — центр масс; в метрическом пространстве — объект, сумма расстояний до которого минимальна, среди всех внутри сферы; объект, который внутри сферы радиуса R содержит максимальное количество других объектов из всей выборки (медленно); объект, который внутри сферы маленького радиуса содержит максимальное количество объектов (из сферы радиуса R).
Наблюдения:
- Доказана сходимость алгоритма за конечное число шагов.
- В линейном пространстве центром тяжести может выступать произвольная точка пространства, в метрическом — только объект выборки.
- Чем меньше R, тем больше таксонов (кластеров).
- В линейном пространстве поиск центра происходит за время О(n), в метрическом O(n²).
- Наилучших результатов алгоритм достигает на выборках с хорошим выполнением условий компактности.
- При повторении итераций возможно уменьшение параметра R, для скорейшей сходимости.
- Кластеризация сильно зависит от начального приближения (выбора объекта на первом шаге).
- Рекомендуется повторная прогонка алгоритма для исключения ситуации «плохой» кластеризации, по причине неудачного выбора начальных объектов.
Преимущества:
- Точность минимизации функционала качества (при удачном подборе параметра R).
- Наглядность визуализации кластеризации.
- Сходимость алгоритма.
- Возможность операций над центрами кластеров — они известны в процессе работы алгоритма.
- Возможность подсчета промежуточных функционалов качества, например, длины цепочки локальных сгущений.
- Возможность проверки гипотез схожести и компактности в процессе работы алгоритма.
Недостатки:
- Относительно низкая производительность (решается введение функции пересчета поиска центра при добавлении 1 объекта внутрь сферы).
- Плохая применимость алгоритма при плохой разделимости выборки на кластеры.
- Неустойчивость алгоритма (зависимость от выбора начального объекта).
- Произвольное по количеству разбиение на кластеры.
- Необходимость априорных знаний о ширине (диаметре) кластеров.
После работы алгоритма над готовой кластеризацией можно производить некоторые действия:
- Выбор наиболее репрезентативных (представительных) объектов из каждого кластера. Можно выбирать центры кластеров, можно несколько объектов из каждого кластера, учитывая априорные знания о необходимой репрезентативности выборки. Т. О. по готовой кластеризации мы имеем возможность строить наиболее репрезентативную выборку
- Пересчет кластеризации (многоуровненвость) с использованием метода КНП.
Области применения:
-Решение задач кластеризации.
-Решение задач ранжирования выборки.
[16]
Математически таксономией является древообразная структура классификаций определенного набора объектов. Вверху этой структуры — объединяющая единая классификация — корневой таксон — которая относится ко всем объектам данной таксономии. Таксоны, находящиеся ниже корневого, являются более специфическими классификациями, которые относятся к поднаборам общего набора классифицируемых объектов. Современная биологическая классификация, к примеру, представляет собой иерархическую систему, основание которой составляют отдельные организмы (индивидуумы), а вершину — один всеобъемлющий таксон; на различных уровнях иерархии между основанием и вершиной находятся таксоны, каждый из которых подчинён одному и только одному таксону более высокого ранга.
Точка зрения, утверждающая, что человеческий мозг организует свое знание о мире в такие системы, часто основывается на эпистемологии Иммануила Канта.
EM-алгоритм (англ. Expectation-maximization (EM) algorithm) — алгоритм, используемый в математической статистике для нахождения оценок максимального правдоподобия параметров вероятностных моделей, в случае, когда модель зависит от некоторых скрытых переменных. Каждая итерация алгоритма состоит из двух шагов. На E-шаге (expectation) вычисляется ожидаемое значение функции правдоподобия, при этом скрытые переменные рассматриваются как наблюдаемые. На M-шаге (maximization) вычисляется оценка максимального правдоподобия, таким образом увеличивается ожидаемое правдоподобие, вычисляемое на E-шаге. Затем это значение используется для E-шага на следующей итерации. Алгоритм выполняется до сходимости.
Часто EM-алгоритм используют для разделения смеси гауссиан. [11]
3.3 Обзор выбранного метода
Обоснование выбранного метода
Решение задачи со строго фиксированным набором критериев, описывающих деятельность страховых компаний с уровнем значимости в описании общей ситуации, привело бы к статической модели.
Сети векторного квантования сигналов добавляют динамизм в решение задачи кластеризации, возможна реализация адаптивности составленной модели, что сделало бы систему универсальной при дополнении рядом критериев и степенью значимости в описании объекта в целом. Также часть модуля вывода может быть реализовано семантическими правилами.
Подробный обзор выбранного метода
Слой Кохонена состоит из некоторого количества n параллельно действующих линейных элементов. Все они имеют одинаковое число входов m и получают на свои входы один и тот же вектор входных сигналов x = (x1,...xm). На выходе jго линейного элемента получаем сигнал
Yi=Wj0+∑ Wij*Xi,
где Wji — весовой коэффициент iго входа jго нейрона, Wj0 — пороговый коэффициент.
После прохождения слоя линейных элементов сигналы посылаются на обработку по правилу «победитель забирает всё»: среди выходных сигналов Yj ищется максимальный; его номер jmax = argmax j{yj}. Окончательно, на выходе сигнал с номером jmax равен единице, остальные — нулю. Если максимум одновременно достигается для нескольких jmax , то либо принимают все соответствующие сигналы равными единице, либо только первый в списке (по соглашению). «Нейроны Кохонена можно воспринимать как набор электрических лампочек, так что для любого входного вектора загорается одна из них.»
Самоорганизующаяся карта Кохонена. Идея и алгоритм обучения
Задача векторного квантования состоит, по своему существу, в наилучшей аппроксимации всей совокупности векторов данных k кодовыми векторами Wj. Самоорганизующиеся карты Кохонена также аппроксимируют данные, однако при наличии дополнительной структуры в совокупности кодовых векторов (англ. codebook). Предполагается, что априори задана некоторая симметричная таблица «мер соседства» (или «мер близости») узлов: для каждой пары j,l (j,l = 1,...k) определено число ηjl () при этом диагональные элементы таблицы близости равны единице (ηjj = 1).
Векторы входных сигналов x обрабатываются по одному, для каждого из них находится ближайший кодовый вектор («победитель», который «забирает всё») Wj(x). После этого все кодовые векторы Wl, для которых ηj(x)l ≠ 0, пересчитываются по формуле
Wlnew=Wlold(1- ηj(x)l * θ) + x * ηj(x)l *θ, где θ(0,1) - шаг обучения. Соседи кодового вектора — победителя (по априорно заданной таблице близости) сдвигаются в ту же сторону, что и этот вектор, пропорционально мере близости.
Чаще всего, таблица кодовых векторов представляется в виде фрагмента квадратной решётки на плоскости, а мера близости определяется, исходя из евклидового расстояния на плоскости.
Самоорганизующиеся карты Кохонена служат, в первую очередь, для визуализации и первоначального («разведывательного») анализа данных. Каждая точка данных отображается соответствующим кодовым вектором из решётки. Так получают представление данных на плоскости («карту данных»). На этой карте возможно отображение многих слоёв: количество данных, попадающих в узлы (то есть «плотность данных»), различные функции данных и так далее. При отображении этих слоёв полезен аппарат географических информационных систем (ГИС). В ГИС подложкой для изображения информационных слоев служит географическая карта. Карта данных является подложкой для произвольного по своей природе набора данных. Она служит заменой географической карте там, где ее просто не существует. Принципиальное отличие в следующем: на географической карте соседние объекты обладают близкими географическими координатами, на карте данных близкие объекты обладают близкими свойствами. С помощью карты данных можно визуализировать данные, одновременно нанося на подложку сопровождающую информацию (подписи, аннотации, атрибуты, информационные раскраски). Карта служит также информационной моделью данных. [4]
3.4 Подход к тестированию. Психометрия
Тестирование позволяет осуществить взаимодействие потребностей человека с возможностями системы. Грамотно организованное тестирование даёт максимально точный результат.
Требования к тестированию:
- Надежность и валидность имеют отношение к обобщаемости показателей тестов — определению того, какие выводы по тестовым показателям являются обоснованными. Надежность касается выводов о согласованности измерения. Согласованность определяется по-разному: как временная устойчивость, как сходство между предположительно эквивалентными тестами, как однородность в рамках одного теста или как сравнимость оценок, выносимых экспертами. При использовании метода «тест-ретест» надежность теста устанавливается путем повторного его проведения с той же группой спустя определенный промежуток времени. Затем два полученных набора показателей сравниваются с целью определения степени сходства между ними. При использовании метода взаимозаменяемых форм, на выборке обследуемых проводятся два параллельных измерения. Привлечение экспертов («оценщиков») к оценке качества параллельных форм теста дает меру надежности, наз. надежностью оценщиков. Этот метод часто применяют, когда есть необходимость в экспертной оценке.
- Валидность характеризует качество выводов, получаемых на основе результатов проведения измерительной процедуры.
- Валидность рассматривается как способность теста отвечать поставленным целям и обосновывать адекватность решений, принятых на основе результата. Недостаточно валидный тест не может считаться инструментом измерения и использоваться на практике, поскольку зачастую полученный результат может серьёзно влиять на будущее тестируемого.
Выделяется три вида валидности тестов.
Конструктная (концептуальная) валидность. Её требуется определить, если тест измеряет свойство, имеющее абстрактный характер, то есть не поддающееся прямому измерению. В таких случаях необходимо создание концептуальной модели, которая бы объясняла данное свойство. Эту модель и подтверждает или опровергает тест.
Критериальная (эмпирическая) валидность. Показывает, насколько соотносятся результаты теста с неким внешним критерием. Эмпирическая валидность существует в двух видах: текущая критериальная валидность — корреляция результатов теста с выбранным критерием, существующим в настоящее время; прогностическая критериальная валидность — корреляция результатов с критерием, который появится в будущем. Определяет, насколько тест предсказывает проявление измеряемого качества в будущем, учитывая влияние внешних факторов и собственной деятельности тестируемого.
Содержательная валидность. Определяет, насколько соответствует тест его предметной области, то есть измеряет ли он качество, для измерения которого предназначен, у репрезентативной выборки. Чтобы поддержать содержательную валидность теста, необходимы его регулярные проверки на соответствие, так как реальная картина проявления определённого качества может меняться у выборки с течением времени. Оценка содержательной валидности должна произвдится экспертом в предметной области теста.
Процесс валидизации теста должен представлять собой не сбор доказательств его валидности, а комплекс мер по повышению этой валидности.
Большинство процедур анализа заданий предполагают:
а) регистрацию числа испытуемых, давших правильный или неправильный ответ на определенное задание;
б) корреляцию отдельных заданий с др. переменными;
в) проверку заданий на систематическую ошибку (или «необъективность»).
Долю испытуемых, справившихся с заданием теста, наз., возможно не вполне точно, трудностью задания. Способ улучшить задания — подсчитать процент выбора каждого варианта ответа на задание с множественным выбором; полезно также вычислить средний тестовый показатель испытуемых, выбравших каждый вариант.
Эти процедуры позволяют контролировать, чтобы варианты ответов выглядели правдоподобными для неподготовленных испытуемых, но не казались правильными наиболее знающим. Отбор заданий, которые сильно коррелируют с показателем полного теста, максимизирует надежность как внутреннюю согласованность теста, тогда как отбор заданий, которые сильно коррелируют с внешним критерием, максимизирует его прогностическую валидность. Описательная аналоговая модель этих корреляций называется характеристической кривой задания; в типичных случаях — это график зависимости доли испытуемых, правильно отвечающих на вопрос, от их суммарного тестового показателя. Для эффективных заданий эти графики представляют собой положительные восходящие кривые, не снижающиеся по мере прироста способности.
Область психометрии связана с количественным подходом к анализу тестовых данных. Психометрическая теория обеспечивает исследователей и психологов математическими моделями, используемыми при анализе ответов на отдельные задания или пункты тестов, тесты в целом и наборы тестов. Прикладная психометрия занимается применением этих моделей и аналитических процедур к конкретным тестовым данным. Четырьмя областями психометрического анализа являются нормирование и приравнивание, оценка надежности, оценка валидности и анализ заданий. Каждая из этих областей содержит набор определенных теоретических положений и конкретные процедуры, используемые при оценке качества работы теста в каждом отдельном случае.
Нормирование тестов — составная часть их стандартизации, обычно включает проведение обследования репрезентативной выборки лиц, определение различных уровней выполнения тестов и перевод сырых тестовых оценок в общую систему показателей. Тесты иногда приравнивают, когда существуют различные формы того же самого теста. Приравнивание приводит оценки по всем формам к общей шкале.
Существуют следующие основные стратегии приравнивания: первый метод предполагает проведение каждой формы теста на эквивалентной (например, случайной отобранной) группе респондентов, а затем оценки по этим различным формам устанавливаются т. о., чтобы равные оценки имели равные процентильные ранги (та же самая пропорция респондентов получает ту же или более низкую оценку); при более точном методе все респонденты заполняют все формы теста, и для определения эквивалентности показателей используются уравнения; третий часто используемый метод связан с проведением общего теста или части теста со всеми респондентами; общая оценочная процедура служит в качестве «связывающего» теста, который позволяет все последующие измерения привязывать к единой шкале; при проведении обследования с использованием различных форм одного и того же теста в каждую включаются несколько «анкерных заданий», выполняющих функцию такого «связывающего» теста. [14]
4. Предложения по структуре магистерской работы
Структура состоит из реализации 3х этапов:
- формирования базы знаний
- кластеризации критериев оценки деятельности страховых компаний
- механизма принятия решения (выбора)
Критерий выбора компании может быть описан как:
minL= Σ(КiL-ΣKijn)²,
где КiL- набор, которым эксперты описывают успешность деятельности страховой фирмы, Kijn – j-й элемент множества, который выбрал респондент в результате прохождения теста. Таким образом становится возможным максимально учесть интересы и потребности конкретного человека при выборе страховой компании.
В дальнейшем планируется провести анализ и рассмотреть возможность применения адаптивного обучения нейронной сети в составе разрабатываемой системы. Выявить проблемы с обучением НС при добавлении новых критериев, найти пути решения. Провести беседу со специалистами в области консалтинговых услуг в сфере страхования и финансовых инвестиций для выявления степени важности каждого критерия в описании деятельности страховых компаний.
Выводы
В ходе выполнения научно-исследовательской работы был изучен объект компьютеризации, определены пути его автоматизации и обоснована необходимость разработки новой системы; проанализированы методы кластерного анализа, нейросетевой модели Кохонена.
Дальнейшие действия определяются необходимостью разработки математических и алгоритмических моделей функционирования, а также разработку программной архитектуры, пригодной для практической реализации системы.
В экономически высокоразвитых странах процесс выбора страховой компании для одного человека, предприятия и целой отрасли осуществляется консалтинговыми фирмами. Это незаинтересованные организации, которые глубоко и комплексно изучают потребности заказчика, беспристрастно и всесторонне анализируют предложения, возможности и результаты деятельности множества страховых компаний, и делают выбор оптимального варианта страховой компании.
Для такой сложной и очень ответственной деятельности и нужна доступная, гибкая и эффективная система, описанная в работе. По мере развития рынка услуг страхования и консалтинга в Украине, она будет всё более и более востребованной в нашей стране.
Описанная система может также успешно применяться при выборе банка, инвестиционной компании и хедж-фонда.
Остался ещё ряд вопросов, которые будут решены в результате дальнейшего анализа предметной области, выбора статичной составляющей в математической модели и составляющей, какую необходимо анализировать и обрабатывать динамическими методами, что позволит получить более гибкую систему.
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: декабрь 2012 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Список источников
- Системы поддержки принятия решений. IT Спец [Электронный ресурс]: Режим доступа :URL: abc.org.ru/
- Business Intelligence [Электронный ресурс]: Режим доступа :URL: ru.wikipedia.org/wiki/Business_Intelligence
- Кластерный анализ [Электронный ресурс]: Режим доступа :URL: ru.wikipedia.org/wiki/Кластерный_анализ
- Нейронная сеть Кохонена [Электронный ресурс]: Режим доступа :URL: ru.wikipedia.org/wiki/Нейронная_сеть_Кохонена
- Комплексные программные решения EPAM Systems [Электронный ресурс]: Режим доступа :URL: epam-group.ru/solutions-EPAM_solutions.htm
- Нейронные сети [Электронный ресурс]: Режим доступа :URL: gotai.net/documents-neural_networks.aspx
- Внедрение информационных технологий как один из путей повышения эффективности деятельности страховой компании [Электронный ресурс]: Режим доступа :URL: economic-innovations.com/article/introduction_information_technology_as_one_way_enhancing_effectiveness_insurance_company
- K-means [Электронный ресурс]: Режим доступа :URL: K-means - Википедия
- How many kinds of Kohonen networks exist? [Электронный ресурс]: Режим доступа :URL: faqs.org/faqs/ai-faq/neural-nets/part1/section-11.html
- Самоадаптирующиеся нейронные сети [Электронный ресурс]: Режим доступа :URL: 314159.ru/neuroinformatics.htm
- Методы многомерной классификации и сегментации. Кластерный анализ [Электронный ресурс]: Режим доступа :URL: nickart.spb.ru/analysis/cluster.php
- Адаптивные сети и системы. Нейронные сети [Электронный ресурс]: Режим доступа :URL: neuronet.narod.ru/
- Обучение без учителя [Электронный ресурс]: Режим доступа :URL: ru.wikipedia.org/wiki/Обучение_без_учителя
- Психометрия [Электронный ресурс]: Режим доступа :URL: ru.wikipedia.org/wiki/Психометрия
- Рейтинг страховых компаний Украины [Электронный ресурс]: Режим доступа :URL: forinsurer.com/ratings/nonlife/
- Кластерный анализ [Электронный ресурс]: Режим доступа :URL: statsoft.ru/home/textbook/modules/stcluan.html
- Факторный анализ — Википедия [Электронный ресурс]: Режим доступа : URL: ru.wikipedia.org/wiki/Факторный_анализ