
Институт информатики и искусственного интеллекта
Кафедра систем искусственного интеллекта
Специальность «Системы искусственного интеллекта»
Модели и алгоритмическое обеспечение для построения семантических сетей текстов на естественном языке
Научный руководитель: к.т.н., доц. Вороной Сергей Михайлович
Реферат
Содержание
Цели и задачи
Актуальность темы работы
Предполагаемая научная новизна
Планируемые практические результаты
Глобальный уровень исследований и разработок по теме
5.1 Семантические сети
5.2 Анализ текстовой информации Text-mining
Национальный уровень исследований и разработок по теме
Локальный обзор исследований и разработок
Cобственные результаты
Выводы
Литература
1 Цели и задачи
Целью исследовательской работы является создание нового более эффективного метода построения семантической сети текстов на естественном языке.
Для достижения данной цели необходимо решить следующие задачи:
- провести детальный анализ ранее существующих методов построения семантических сетей;
- выделить основные недостатки и проблемы реализации существующих алгоритмов построения семантических сетей;
- выяснить степень изученности данных проблем;
- определить область применения существующих технологий;
- определить, какой круг проблем позволяют решить семантические сети;
- на основе анализа, выше перечисленных пунктов, сделать выводы и предложить новый метод построения семантических сетей, способный максимально полно решать существующие проблемы данной предметной области.
2 Актуальность темы работы
С каждым днем объемы информации растут большими темпами. Но, как известно, информация требует систематизации и обработки. Поэтому появляется необходимость в создании средств для хранения данных и механизмов для их быстрой и эффективной обработки.
Семантические сети являются именно тем механизмом, который позволяет эффективно и в полной мере обрабатывать информацию и накопленные знания.
Способ представления знаний в сетевых моделях наиболее близок к тому, как они представлены в текстах на естественном языке. В его основе лежит идея о том, что вся необходимая информация может быть описана как совокупность троек (arb), где a и b – объекты, а r – бинарное отношение между ними [1].
Семантическая сеть – информационная модель предметной области, имеющая вид ориентированного графа, вершины которого соответствуют объектам предметной области, а дуги (рёбра) задают отношения между ними. Объектами могут быть понятия, события, свойства, процессы.
Исходя из выше сказанного, можно сделать вывод, что тема данной исследовательской работы весьма актуальна. Т.к. позволяет решить одну из самых важных проблем информационного общества – проблему обработки накопленной информации и представление ее в более удобном для последующего хранения виде.
3 Предполагаемая научная новизна
Научная новизна исследовательской работы заключается в разработке нового метода построения семантических сетей текстов на естественном языке, основываясь на результатах детального анализа ранее существующих методов, определении недостатков и проблем уже имеющихся методов и алгоритмов.
4 Планируемые практические результаты
В результате проведения работы планируется создание алгоритмического обеспечения по разработанному методу. Данный алгоритм должен отвечать следующим требованиям:
- быстрота реализации;
- отсутствие недостатков, которые имели место в предыдущих алгоритмах;
- эффективность результатов работы;
- возможность оптимизации для решения нестандартных задач.
5 Глобальный уровень исследований и разработок по теме
5.1 Семантические сети
Семантическая сеть (СС) – математическая модель, отображающая множество понятий относящихся к определенным классам объектов. В общем случае СС может быть представлена в виде гиперграфа, в котором вершины соответствуют понятиям, а дуги – отношениям. Графовая форма представления в СС дает большую простоту реализации отношений многих объектов ко многим, нежели в иерархической модели.
Основное преимущество этой модели – в соответствии современным представлениям об организации долговременной памяти человека. Недостаток модели – сложность поиска вывода на семантической сети.
Начиная с конца 50-ых годов были созданы и применены на практике десятки вариантов семантических сетей. Несмотря на то, что терминология и их структура различаются, существуют сходства, присущие практически всем семантическим сетям:
- узлы семантических сетей представляют собой концепты предметов, событий, состояний;
- дуги семантических сетей создают отношения между узлами-концептами (пометки над дугами указывают на тип отношения);
- некоторые отношения между концептами представляют собой лингвистические падежи, такие как агент, объект, реципиент и инструмент (другие означают временные, пространственные, логические отношения и отношения между отдельными предложениями);
- концепты организованы по уровням в соответствии со степенью обобщенности так как, например, сущность, живое существо, животное, плотоядное.
Однако существуют и различия:
- понятие значения с точки зрения философии;
- методы представления кванторов общности и существования и логических операторов;
- способы манипулирования сетями и правила вывода, терминология.
Все это варьируется от автора к автору. Несмотря не некоторые различия, сети удобны для чтения и обработки компьютером, а также достаточно мощны, чтобы представить семантику естественного языка [2].
Важнейшими типизированным отношениями объектов являются: «Род» – «Вид», «Целое» – «Часть», «Причина» – «Следствие», «Средство» – «Цель», «Аргумент» – «Функция», «Ситуация» – «Действие». Типизация отношений позволяет однозначно интерпретировать смысл ситуаций, отображаемых в базе знаний и настраивать механизм вывода особенности этих отношений. Так, отражение отношений «Род» - «Вид» дает возможность осуществлять наследование атрибутов классов объектов и, таким образом, автоматизировать процесс выведения заключений от общего к частному. Способ представления семантической сети в виде графа представлен на рисунке 5.1 [3].

В общем случае под семантической сетью понимается выражение, приведенное в формуле 5.1
S=(O,R1,R2,…,Rk), (5.1)
где O – множество объектов конкретной предметной области;
Ri i=1,n – множество отношений между объектами;
i – тип отношений.
Из множества существующих методов построения семантической сети был выбран метод создания семантической сети из коллекции текстовых документов определенной предметной области. Суть метода заключается в пошаговом анализе текста, который приведен на рисунке 5.2.
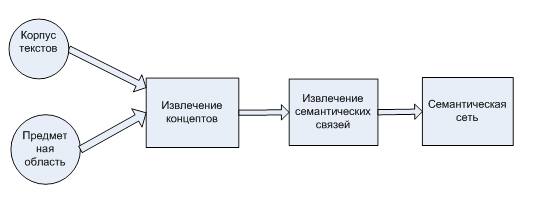
На этапе извлечения концептов происходит выделение ключевых слов, выделение ключевых словосочетаний и группирование словосочетаний. В свою очередь группирование ключевых слов разбивается на несколько этапов, приведенных ниже.
1. Нормализация, токенизация, лемматизация.
2. Фильтрация на основе лингвистической информации: удаление стоп-слов, имен собственных, чисел, дат, всего остального кроме существительных и прилагательных.
3. Ранжирование слов-кандидатов с использованием статистической информации.
Выделение ключевых словосочетаний также делится на отдельные шаги.
1. Извлечение свободных словосочетаний.
2. Группирование словосочетаний-кандидатов, путем поиска наибольших общих подстрок.
3. Ранжирование словосочетаний [4].
5.2 Анализ текстовой информации Text-mining
Анализ структурированной информации, хранящейся в базах данных, требует предварительной обработки: проектирование БД, ввод информации по определенным правилам, размещение ее в специальных структурах (например, реляционных таблицах) и т.п. Таким образом, непосредственно для анализа этой информации и получения из не новых знаний необходимо затратить дополнительные усилия. При этом они не всегда связаны с анализом и не обязательно приводят к желаемому результату. Из-за этого КПД анализа структурированной информации снижается. Кроме того, не все виды данных можно структурировать без потери полезной информации. Например, текстовые документы практически невозможно преобразовать в табличное представление без потери семантики текста и отношений между сущностями. По этой причине такие документы хранятся в БД без преобразований, как текстовые поля (BLOB-поля). В то же время в тесте скрыто огромное количество информации, но ее неструктурированность не позволяет использовать алгоритмы Data Mining. Решением этой проблемы занимаются методы анализа неструктурированного текста. В западной литературе такой анализ называют Text Mining.
Методы анализа в неструктурированных текстах лежат на стыке нескольких областей: Data Mining, обработка естественных языков, поиск информации, извлечение информации и управление знаниями.
Обнаружение знаний в тексте – это нетривиальный процесс обнаружения действительно новых, потенциально полезных и понятных шаблонов в неструктурированных текстовых данных. Как видно, от определения Data Mining это определение отличается только новым понятием «неструктурированные текстовые данные». Под такими знаниями понимается набор документов, представляющих собой логически объединенный текст без каких-либо ограничений на его структуру. Примерами таких документов являются: web-страницы, электронная почта, нормативные документы и т.п. В общем случае такие документы могут быть сложными и большими и включать в себя не только текст, но и графическую информацию. Документы, использующие язык расширяемой разметки XML (eXtensible Markup Language), стандартный язык обобщенной разметки SGML (Standart Generalised Markup Language) и другие подобные соглашения по структуре формирования текста, принято называть полуструктурированными документами. Они также могут быть обработаны методами Text Mining.
Процесс анализа тестовых документов можно представить как последовательность нескольких шагов, приведенных на рисунке 5.3.
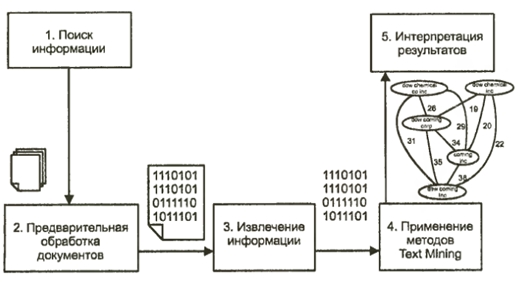
Поиск информации. На первом шаге необходимо идентифицировать, какие документы должны быть подвергнуты анализу, и обеспечить их доступность. Как правило, пользователи могут определить набор анализируемых документов самостоятельно – вручную, но при большом количестве документов необходимо использовать варианты автоматизированного отбора по заданным критериям.
Предварительная обработка документов. На этом шаге выполняется простейшие, но необходимые преобразования с документами для представления их в виде, с которым работают методы Text Mining. Целью таких преобразований является удаление лишних слов и придание тексту более строгой формы.
Извлечение информации. Извлечение информации из выбранных документов предполагает выделение в них ключевых понятий, над которыми в дальнейшем будет выполняться анализ. Данный этап является очень важным.
Применение методов Text Mining. На данном шаге извлекаются шаблоны и отношения, имеющиеся в текстах. Данный шаг является основным в процессе анализа текстов, и практические задачи, решаемые на этом шаге.
Интерпретация результатов. Последний шаг в процессе обнаружения знаний предполагает интерпретацию полученных результатов. Как правило, интерпретация заключается или в представлении результатов на естественном языке, или в их визуализации в графическом виде.
Визуализация также может быть использована как средство анализа текста. Для этого извлекаются ключевые понятия, которые и представляются в графическом виде. Такой подход помогает пользователю быстро идентифицировать главные темы и понятия, а также определить их важность.
Предварительная обработка текста
Одной из главных проблем анализа текстов является большое количество слов в документе. Если каждое из этих слов подвергать анализу, то время поиска новых знаний резко возрастает, и вряд ли будет удовлетворять требованиям пользователей. В то же время очевидно, что не все слова в тексте несут полезную информацию. Кроме того, в силу гибкости естественных языков формально различные слова (синонимы и т.п.) на самом деле означают одинаковые понятия. Таким образом, удаление неинформативных слов, а также приведение близких по смыслу слов к единой форме значительно сокращает время анализа текстов. Устранение описанных проблем выполняется на этапе предварительной обработки текста.
Обычно используют следующие приемы удаления неинформативных слов и повышения строгости текстов.
1. Удаление стоп-слов. Стоп-словами называются слова, которые являются вспомогательными и несут мало информации о содержании документа. Обычно заранее составляются списки таких слов, и в процессе предварительной обработки они удаляются из текста. Типичным примером таких слов являются вспомогательные слова и артикли, например «так как», «кроме того» и т.п.
2. Стэмминг – морфологический поиск. Он заключается в преобразовании каждого слова к его нормальной форме. Нормальная форма исключает склонение слова, множественные формы, особенности речи и т.п. Например, слова «сжатие» и «сжатый» должны быть преобразованы в нормальную форму слова «сжимать». Алгоритмы морфологического разбора учитывают особенности и вследствие этого являются языково-зависимыми алгоритмами.
3. N-граммы – это альтернатива морфологическому разбору и удалению стоп-слов. N-грамма – это часть строки, состоящая из N символов. Например слово «дата» может быть представлено 3-граммой «_да», «дат», «ата», «та_» или 4-граммой «_дат», «дата», «ата_», где символ подчеркивания заменяет предшествующий или замыкающий слово пробел. По сравнению со стэммингом или удалением стоп-слов, N-граммы менее чувствительны к грамматическим и типографическим ошибкам. Кроме того, N-граммы не требуют лингвистического представления слов, что делает данный прием более независимым от языка. Однако N-граммы, позволяя сделать текст более строгим, не решают проблему уменьшения количества неинформативных слов.
4. Приведение регистра. Этот прием заключается в преобразовании всех символов к верхнему или нижнему регистру. Например, все слова «текст», «Текст», «ТЕКСТ» приводятся к нижнему регистру «текст».
Извлечение ключевых понятий из текста
Извлечение ключевых понятий из текста может рассматриваться и как отдельный этап анализа текста, и как определенная прикладная задача. В первом случае извлеченные из текста факты используются для решения различных задач анализа: классификации, кластеризации и др. Большинство методов Data Mining, адаптированные для анализа текстов, работают именно с такими отдельными понятиями, рассматривая их в качестве атрибутов данных.
В задаче извлечения ключевых понятий из текста интерес представляют некоторые сущности, события и отношения. При этом извлеченные понятия анализируются и используются для ввода новых. В данном разделе и будет описано решение такой задачи. При этом часть процесса решения может быть использована для ключевых понятий при решении других задач анализа текста.
Извлечение ключевых понятий из текстовых документов можно рассматривать как фильтрацию больших объемов текста. Этот процесс включает в себя отбор документов из коллекции и пометку определенных термов в тексте. Существуют различные подходы к извлечению информации из текста. Примером может служить определение частных наборов слов и объединение их в ключевые понятия.
Другим подходом является идентификация фактов в текстах извлечение их характеристик. Фактами являются некоторые события или отношения. Идентификация производится с помощью наборов образцов. Образцы представляют собой возможные лингвистические варианты фактов.
Такой подход позволяет представить найденные ключевые понятия, представленные событиями и отношениями, в виде структур, которые в том числе можно хранить в базах данных.
Процесс извлечения ключевых понятий с помощью шаблонов разбивается на две стадии: локальный анализ и анализ понятий. На первой стадии их тестовых документов извлекаются отдельные факты с помощью лексического анализа. Вторая стадия заключается в интеграции извлеченных фактов и/или в выводе новых фактов. В конце наиболее характерные факты преобразовываются в нужную выходную форму. Данный процесс представлен ниже на рисунке 5.4
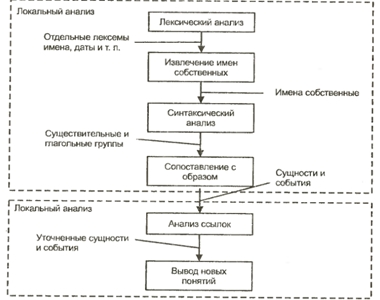
Сложность извлечения фактов с помощью образцов связана с тем, что на практике их нельзя представить в виде простой последовательности слов. В большинстве систем обработки естественных языков вначале идентифицируются различные уровни компонентов и отношений, а затем на их основе строятся образцы. Этот процесс обычно начинается с лексического анализа (определения частей речи и характеристик слов и фраз посредством морфологического анализа и поиска по словарю) и распознавания имен (идентификации имен и других лексических структур, таких как даты, денежные выражения и т.п.). За этим следует синтаксический разбор, целью которого является выявление групп существительных, глаголов и, если возможно, дополнительных структур. Затем применяются предметно-ориентированные образцы для идентификации интересующих фактов.
На стадии интеграции найденные в документах факты исследуются и комбинируются. Это выполняется с учетом отношений, которые определяются местоимениями или описанием одинаковых событий. Также на этой стадии делаются выводы из ранее установленных фактов.
Как уже отмечалось ранее, извлечение фактов выполняется при помощи сопоставления текста с набором регулярных выражений (образцов). Если выражение сопоставляется с текстовыми сегментами, то такие сегменты помечаются метками. При необходимости этим сегментам приписываются дополнительные свойства. Образцы организуются в наборы. Метки, ассоциированные с одним набором, могут ссылаться на другие наборы. Каждый образец имеет связанный с ним набор действий. Как правило, главное действие – это пометить тестовый сегмент новой меткой, но могут быть и другие действия. В каждый момент времени текстовому сегменту сопоставляется с первого слова предложения. Если образец может быть сопоставлен более чем одному сегменту, то выбирается наиболее длинный сопоставленный сегмент. Если таких сегментов несколько, то выбирается первый. При сопоставлении выполняются действия, ассоциированные с этим образцом. Если не удалось сопоставить ни один образец, то сопоставление повторяется, начиная со следующего слова в предложении. Если сегмент сопоставлен с образцом, то сопоставление повторяется, начиная со следующего слова после сегмента. Процесс продолжается до конца предложения.
Основной целью сопоставления с образцами является выделение в тексте сущностей, связей и событий. Все они могут быть преобразованы в некоторые структуры, которые могут анализироваться стандартными методами Data Mining [5].
6 Национальный уровень исследований и разработок по теме
Семантические сети – модель представления знаний, которая наиболее близка к естественному языку [6]. Семантическая сеть представляет собой ориентированный граф с вершинами, которым соответствуют объекты, понятия или ситуации, и дугами, которые могут быть определены различными методами, характеризующими отношения между объектами. К достоинствам семантических сетей можно отнести большие выразительные возможности; наглядность системы знаний, представленной графически; близость к естественному языку; соответствие современным представлениям об организации долговременной памяти человека; легкое настраивание. Отрицательными моментами использования сетевой модели являются такие факты: эта модель не дает ясного представления о структуре предметной области, которая ей соответствует, поэтому формирование и модификация такой модели затруднительны; сетевые модели представляют собой пассивные структуры, для обработки которых необходим специальный аппарат формального вывода и планирования; сложность поиска и вывода на семантических сетях; наличие множественных отношений между элементами сети. [7]
Семантические сети обеспечивают представление ПО в виде ориентированного графа, вершинами которого выступают объекты, а ребрами – связи между ними. Связь между объектами сетевой модели выражает минимальный объем знаний, простейший факт, относящийся к двум понятиям. Основа семантической сети – это экземпляры или объекты, понятия или классы, атрибуты, отношения или связи [8].
Объекты – это основные элементы семантической сети, которые могут представлять собой как физические объекты, так и абстрактные. Онтология может обойтись и без конкретных объектов. Однако, одной из главных целей онтологии является классификация таких объектов, поэтому они также включаются. Классы – это абстрактные группы, коллекции или наборы объектов. Они могут включать в себя экземпляры, другие классы, либо же сочетания и того, и другого.
Атрибуты характеризуют объекты в онтологии. Каждый атрибут имеет, по крайней мере, имя и значение, и используется для хранения информации, которая специфична для объекта и привязана к нему. Связи – это специфический компонент сети, который определяет зависимость или отношение объектов между собой.
Построение семантической модели начинается с выделения составных элементов, выступающих в виде объектов описания. Исходя из содержания технического задания (предметной области) типового научно-технического проекта. Следует отметить, что каждый элемент описания может быть единичным или представлять группу элементов.
На основе анализа элементов сети и их взаимосвязей формируется структура элементов семантической модели содержания проекта. Структура, использованная при разработке семантической модели описания основных объектов, включает описание атрибутов узлов сети и указание видов связей.
Далее проводится ряд процедур, приведенных ниже.
1. Определение набора атрибутов узлов и связей семантической сети.
2. Выделения классов и объектов.
3. При описании элементов выделяются определенные типы объектов.
4. Выделение семантических типов.
5. Определение типов связей, используемых для построения семантической сети [9].
Метод семантического анализа текста подробно описывается в работе [10]. В данной работе содержится описание системы ассоциативно-семантического контекстного анализа естественноязыковых текстов, на базе которой реализована прикладная система мониторинга текстовых потоков и корпусов с блоком качественного оценивания лингвистических фокусных объектов, предназначенная для вычисления различных качественных характеристик и параметров заданных объектов и процессов.
Процесс ассоциативно-семантического анализа в системе можно условно разделить на три этапа:
– переход от слов и словосочетаний предложений до соответствующих семантических значений – концептов онтологии;
– сборка семантических фреймов предложений текста;
– объединение семантических структур предложений текста в единую семантическую сеть текста.
На первом этапе система определяет в семантической сети онтологической базы знаний концепт, соответствующий корректному значению слова или словосочетания в тексте. Эта задача решается поиском того значения слова из множества возможных альтернатив концептов, которое семантически является наиболее близким к значениям слов-соседей из локального окружения данного слова.
Второй этап – построение семантического фрейма текущего предложения входного текста. Он заключается в заполнении слотов фреймовой структуры предложения.
Третья фаза смыслового анализа – объединение изолированных семантических фреймов предложений в связную семантическую сеть текста. Объединение двух структур в одну сеть выполняется по принципу объединения семантически тождественных вершин.
На выходе системы генерируется семантическая сеть входного текста, которая содержит в вершинах концепты текста, связанные дугами семантических отношений. Дальнейшая смысловая обработка полученной семантической сети текста позволяет решать широкий класс задач компьютерной лингвистики.
7 Локальный уровень исследований и разработок по теме
В работе студента Донецкого национального технического университета Шатохина Н.А. «Семантический анализ естественных языков и его приложения» рассматривается анализ текстов на естественном языке. В своей работе автор приводит алгоритм метода, который описывается ниже.
Шаг 1. Морфологический анализ. На этом этапе в тексте распознаются слова и разделители. При этом сложные предложения разбиваются на несколько простых. Тип связи между ними запоминается.
Шаг 2. Синтаксический анализ. На этапе синтаксического анализа предложение разбирается по составу — в нем выделяются подлежащее, сказуемое и второстепенные члены. Также определяется к какой части речи относится каждый из членов. Для этого используется словарь — структура вида:
Таблица 1 [11]

Здесь: позиция — где располагается слово, относительно связанного с ним (спереди, сзади, где-угодно), дополнительно — дополнительные свойства слова, например, род, множественное или единственное число и т.п.
Шаг 3. Семантический анализ. На этом этапе определяется значение каждого из простых предложений. Зная, как они были связаны в сложном, можно определить семантику исходного текста. Для этого можно использовать исчисление высказываний.
Этап семантического анализа делится на три подэтапа.
Шаг 3.1. Реляционный анализ. С помощью словаря определяются отношения между членами предложения. Для этого берется самое левое слово и по словарю определяется что это за часть речи и с какими членами оно может состоять в отношениях. Если возможное отношение всего одно, либо его можно определить с помощью поля «Позиция», то данное отношение сохраняется и осуществляется переход к следующему слову. Иначе используются дополнительные свойства.
Шаг 3.2. Построение семантической сети. Зная отношения между всеми членами предложения, строим граф, в котором в качестве вершин будут записаны слова, а каждое ребро будет соответствовать определенному отношению.
Шаг 3.3. Определение семантики предложения. Имея семантическую сеть, можно перевести входное предложение в запрос понятный машине [11].
8 Краткое изложение собственных результатов
В результате проведения анализа ранее существующих методов построения семантических сетей были выделены основные недостатки и проблемы реализации существующих алгоритмов. Также была определена степень изученности проблемы и актуальность использования семантических сетей. На основе анализа, выше сказанного, были сделаны выводы. В данный момент ведется работа над созданием нового метода построения семантических сетей, способного максимально полно решать проблемы данной предметной области.
9 Заключение
Задачи обработки текстов возникли практически сразу после появления вычислительной техники. Несмотря на полувековую историю исследований в области искусственного интеллекта, накопленный опыт вычислительной лингвистики, огромный скачок в развитии интернет технологий и смежных дисциплин, удовлетворительного решения большинства практических задач обработки текста пока не найдено. Однако ИТ-индустрия потребовала удовлетворительного решения некоторых задач обработки текстов. Так, развитие хранилищ данных делает актуальными задачи извлечения информации и формирования корректно построенных текстовых документов. Бурное развитие интернета повлекло за собой создание и накопление огромных объемов текстовой информации, что требует создания средств полнотекстового поиска и автоматической классификации текстов (в частности, программные средства для борьбы со спамом), и если первая задача более или менее удовлетворительно решена, то до решения второй пока еще далеко. Мое исследование будет направлено на решение именно этих проблем.
В последнее время, благодаря развитию систем документооборота, наличию множества постоянно обновляемых юридических справочников, ряду других факторов, наблюдается накопление массивов специализированных (но не формализованных) текстовых документов. По аналогии со структурированной информацией, когда усовершенствование средств анализа вылилось в появление хранилищ данных, развитие систем документооборота со временем может потребовать создания полнотекстовых хранилищ, дающих возможность всестороннего анализа и исследования неформализованных текстов на естественном языке.
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: январь 2012 г. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Литература
- Аверкин А.Н., Гаазе-Рапопорт М.Г., Поспелов Д.А. Толковый словарь по искусственному интеллекту. – М: Радио и связь, 1992.
- Искусственный интеллект в домашних условиях. Семантические сети. [Электронный ресурс] – Режим доступа: http://www.aimatrix.nm.ru/aimatrix/SemanticNetworks.htm.
- Электронная библиотека «Википедия». Семантическая сеть. [Электронный ресурс] – Режим доступа: http://ru.wikipedia.org/wiki/Семантическая_сеть.
- Панченко А. Построение семантической сети из разнородных данных. [Электронный ресурс] – Режим доступа: http://it-claim.ru/Persons/Panchenko/presentation2010_sept_final.pdf.
- Барсегян А.А. Технологии анализа данных: Data Mining, Visual Mining, Text Mining, OLAP / А.А. Барсегян, М.С. Куприянов, В.В. Степаненко, И.И. Холод. – СПб.: БХВ – Петербург, 2007. – С. 194 – 204.
- Уотермен Д. Руководство по экспертным системам: пер. с англ. / Д. Уотермен. – М.: Мир, 1989. – 388 с.
- Круглов В.В. Искусственные нейронные сети. Теория и практика / В.В. Круглов, В.В. Борисов. – 2-е изд., стереотип. – М.: Горячая линия – Телеком, 2002. – 382 с.
- Мельник К.В., Ершова С.И. Проблемы и основные подходы к решению задачи медицинской диагностики. [Электронный ресурс] – Режим доступа: http://www.nbuv.gov.ua/portal/natural/soi/2011_2/melnik.pdf.
- Носова Н.Ю. Семантическая модель содержания инновационного технического проекта. [Электронный ресурс] – Режим доступа: http://www.nbuv.gov.ua/portal/natural/soi/2011_4/nosov.pdf.
- Марченко А.А., Никоненко А.А. Контекстный семантический анализ текста. Система текстового мониторинга и качественного оценивания фокусного объекта. [Электронный ресурс] – Режим доступа: http://www.nbuv.gov.ua/portal/natural/ii/2008_3/JournalAI_2008_3/Razdel9/02_Marchenko_Nikonenko.pdf.
- Шатохин Н.А. Семантический анализ естественных языков и его приложения. [Электронный ресурс] – Режим доступа: http://masters.donntu.ru/2011/fknt/shatokhin/library/article4.htm.