Web Mining: основные понятия
Web Mining – применение методов и алгоритмов Data Mining для обнаружения и поиска зависимостей и знаний в сети Интернет.
Чтобы лучше понять предметную область, рассмотрим основные понятия и принципы сети Интернет.
Основные понятия и принципы
В таблице 1 приведено описание основных терминов и понятий, которые используются в данной статье.
Таблица 1 – Основные термины и понятия
|
Название |
Описание |
|
Электронный портал |
Крупный сайт с разветвленной структурой, предоставляющий посетителям широкий спектр информации и услуг. |
|
Веб-сервер |
Сервер, принимающий запросы от клиентов (часто веб-браузеров) и выдающий им ответы обычно вместе с HTML-страницей, изображением, файлом, медиа-потоком или другими данными. |
|
Веб-лог |
Специальный файл, в который заносятся все действия пользователя на сервере. |
|
Веб-контент |
Информационное содержимое интернет-страницы: текст, графика, мультимедиа. |
|
Веб-структура |
Способ организации страниц на сайте и связей между ними. |
|
Клик |
Нажатие клавиши компьютерной мыши (от англ. “click” – щелчок). |
|
Протокол |
В данной статье под этим термином будет пониматься сетевой протокол – набор соглашений, который определяет правила обмена данными между различными программами. |
|
IP-адрес |
Сетевой адрес узла в компьютерной сети, построенной по протоколу IP (Internet Protocol). |
|
Идентификация |
Присвоение посетителям сайта идентификатора и (или) сравнение его с перечнем уже присвоенных. |
|
Авторизация |
Процесс подтверждения прав зарегистрированных пользователей на выполнение некоторых действий. |
|
Клиент |
Компьютер или программа, посылающий(ая) запросы на сервер. |
|
Гиперссылка |
Часть интернет-страницы (например, текст или рисунок), ссылающаяся на другой объект (файл, страницу) в сети Интернет. |
Все сайты сети Интернет хранятся на веб-серверах. Чтобы получить страницу сайта, браузер посылает запросы на веб-сервер. В ответ на них возвращаются файлы, необходимые для формирования интернет-страницы в окне браузера. Эта идея наглядно продемонстрирована на рисунке 1.
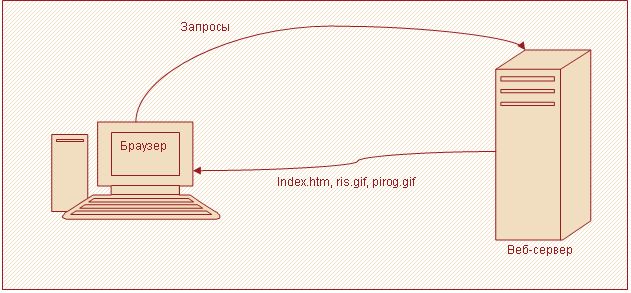
Рисунок 1 – Взаимодействие браузера и веб-сервера
Загрузив страницу, пользователь просматривает имеющуюся на ней информацию. После чего он может перейти на другую согласно структуре сайта, связи в которой устанавливаются посредством гиперссылок.
Для удобства навигации страницы могут быть объединены в категории, а они в свою очередь в разделы. Подобная структура изображена на рисунке 2.
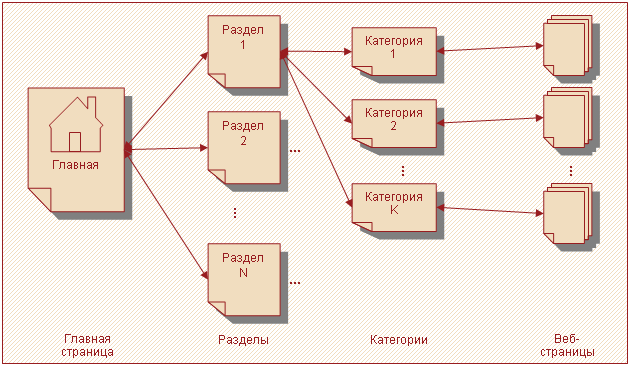
Рисунок 2 – Пример структуры веб-сайта
Внутри категорий между страницами может быть разнообразная структура (иерархическая, последовательная, сетевая). На большинстве сайтов предусмотрен быстрый переход с любой страницы на главную. В зависимости от выбранной структуры пользователь перемещается с одной страницы на другую. На рисунке 3 изображен фрагмент структуры сайта, где страницы пронумерованы согласно порядку их просмотра.
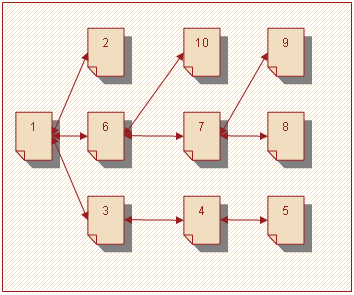
Рисунок 3 – Путь пользователя на сайте
Можно заметить, что между пятой и шестой просматриваемыми страницами прямой ссылки нет, но исходя из структуры совершенно очевидно, что после пятой страницы пользователь вернулся к первой. Отсюда полный его путь по сайту будет следующим: 1, 2, 1, 3, 4, 5, 4, 3, 1, 6, 7, 8, 7, 8, 9, 7, 6, 10.
Исходя из перечисленных особенностей размещения информации в сети Интернет возникают различные сложности анализа веб-данных. Рассмотрим их.
Сложности анализа данных из сети Интернет
Всемирная сеть сейчас содержит огромное количество информации, знаний. Пользователи на различных условиях могут просматривать всевозможные документы, аудио- и видеофайлы. Однако это многообразие данных скрывает в себе проблемы, которые могут возникнуть не только при анализе, но и при поиске необходимой информации в Интернет.
- Проблема поиска нужной информации связана с тем, что пользователь не всегда сразу может найти необходимые ему электронные ресурсы. Лишь небольшой процент ссылок среди предложенных поисковыми системами приводит к требуемым документам. Также труден поиск неиндексированной информации такими средствами.
- Проблема обнаружения новых знаний. Даже если найдено множество информации, для пользователя извлечение полезных знаний является довольно трудоемкой и непростой задачей. Сюда же можно и отнести сложности, связанные с осмыслением сведений, понятием тех идей, которые были вложены авторами.
- Проблема изучения потребителей связана с предоставлением пользователю информации, которая оказалась бы ему интересна. Это особенно актуально для электронных торговых порталов, которые могли бы «подсказывать» пользователю при выборе товара.
Обозначив сложности анализа веб-данных, вернемся к Web Mining. Рассмотрим его основные этапы.
Этапы Web Mining
В Web Mining можно выделить следующие этапы:
- входной этап (input stage) – получение «сырых» данных из источников (логи серверов, тексты электронных документов);
- этап предобработки (preprocessing stage) – данные представляются в форме, необходимой для успешного построения той или иной модели;
- этап моделирования (pattern discovery stage);
- этап анализа модели (pattern analysis stage) – интерпретация полученных результатов.
Это общие шаги, которые необходимо пройти для анализа данных сети Интернет. Конкретные процедуры каждого этапа зависят от поставленной задачи. В связи с этом выделяют различные категории Web Mining.
Категории Web Mining
- Анализ использования веб-ресурсов (Web Usage Mining).
- Извлечение веб-структур (Web Structure Mining).
- Извлечение веб-контента (Web Content Mining).
Рассмотрим их подробнее.
Анализ использования веб-ресурсов
Это направление основано на извлечении данных из логов веб-серверов. Целью анализа является выявление предпочтений посетителей при использовании тех или иных ресурсов сети Интернет.
Здесь крайне важно осуществить тщательную предобработку данных: удалить лишние записи лога, которые не интересны для анализа.
Каждый пользователь сети имеет свои индивидуальные вкусы, взгляды, в зависимости от которых он посещает те или иные ресурсы. Выявив, какие страницы и в какой последовательности открывал пользователь, можно сделать вывод о его предпочтениях. Анализ общих тенденции среди всех посетителей показывает, насколько эффективно работает электронный портал, какие его страницы посещаются больше всего, какие меньше.
На основе этого анализа можно оптимизировать сайт: найти ранее не замеченные проблемы в функционировании, дизайне и много другое.
Извлечение веб-структур
Данное направление рассматривает взаимосвязи между веб-страницами, основываясь на связях между ними. Построенные модели могут быть использованы для категоризации веб-ресурсов, поиска схожих и распознавания авторских сайтов.
В зависимости от поставленной задачи структура сайта моделируется с определенным уровнем детализации. В самом простом случае гиперссылки представляют в виде направленного графа:
G = (D, L),
где D – это набор страниц, узлов или документов; L – набор ссылок.
Извлечение веб-структур может быть использовано как подготовительный этап для извлечения веб-контента.
Извлечение веб-контента
Поиск знаний в сети Интернет является непростой и трудоемкой задачей. Именно это направление Web Mining решает её. Оно основано на сочетании возможностей информационного поиска, машинного обучения и Data Mining.
Анализируется содержание документов: находятся схожие по смыслу слова и их количество. Затем решается задача кластеризации или классификации. Так документы группируются по смысловой близости.
Это направление может быть использовано для оптимизации поиска индексированных документов.
Общая взаимосвязь между категориями Web Mining и задачами Data Mining изображена на рисунке 4.
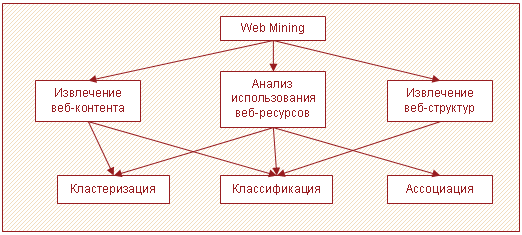
Рисунок 4 – Категории Web Mining и задачи Data Mining
В бизнес-аналитике Web Mining решает следующие задачи:
- описание посетителей сайта (кластеризация, классификация);
- описание посетителей, которые совершают покупки в интернет-магазине (кластеризация, классификация);
- определение типичных сессий и навигационных путей пользователей сайта (поиск популярных наборов, ассоциативных правил);
- определение групп или сегментов посетителей (кластеризация);
- нахождение зависимостей при пользовании услугами сайта (поиск ассоциативных правил).
В следующих статьях цикла будут подробнее рассмотрены вопросы Web Mining в части анализа использования веб-ресурсов.
Литература
- Markov Z, Larose D.T. Data-mining the Web : uncovering patterns in Web content, structure, and usage, – John Wiley & Sons Inc., 2007
- Анализ данных и процессов: учеб. пособие / А. А. Барсегян, М. С. Куприянов, И. И. Холод, М. Д. Тесс, С.И. Елизаров. – 3-е издание перераб. и доп. – СПб.: БХВ-Петербург, 2009
