
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования, планируемые результаты
- 3. Обзор известных исследований и разработок
- 3.1 Анализ зарубежных источников
- 3.2 Анализ национальных источников
- 3.3 Анализ работ выпускников ДонНТУ
- 4. Основные принципы информационного поиска
- Заключение
- Список источников
Введение
В настоящее время при ведении бизнеса активно применяются современные информационные технологии на основе глобальной компьютерной сети Интернет. Хотя сама сеть Интернет имеет достаточно долгую историю, ее коммерческое использование началось лишь в 1988 году. Мы уже не можем представить жизнь без интернета, который наполнен миллионами сайтов, которые создают виртуальное информационное пространство. Ресурсы Интернета превратившись в инструмент для повседневной работы людей многих профессий.
Быстрый рост информации в сети сделали его океаном разнообразнейших данных, важность которых растет пропорционально их объему. Ежедневно в сети появляются миллионы новых документов, и естественно, что без систем поиска они в подавляющем своем большинстве остались бы не востребованными, вообще не были бы не кем найдены, и то огромное количество информации оказалось бы никому не нужным. Возникла необходимость создания таких средств, которые позволили бы легко ориентироваться в информационных ресурсах глобальных сетей, быстро и надежно находить нужные сведения. Таким образом, в интернете появились специальные поисковые средства.
1. Актуальность темы
Поисковые системы это важнейшая часть современного интернета. На заре развития сети поиск производился по специальным каталогам, содержащим ссылки на существующие ресурсы, но на сегодняшний день их число настолько велико, что требуются специальные полностью автоматизированные системы для поиска в Интернете.
На сегодняшний день интернет пространство постоянно пополняется новыми сайтами. Для того, чтобы привлекать больше посетителей на свои сайты, разработчики ищут новые пути оптимизации, которые помогут удерживать лидирующие позиции.
Модели поведения пользователей – одно из основных направлений исследований в области улучшения поиска. Магистерская работа посвящена актуальной задаче оптимизации поисковых запросов, обзору современных моделей поведения пользователей, а также исследованию того, как модели поведения комбинируются с другими признаками в функции ранжирования. Существуют различные методы поисковых запросов, для которых затрачивается немало времени и навыков. Поэтому предметом исследования является влияние различных методов поисковой оптимизации на поднятие уровня сайта.
2. Цель и задачи исследования, планируемые результаты
Основная задача поиска — давать ответы на вопросы. Значительную часть запросов составляет поиск товаров и услуг. Среди множества сайтов с товарами и услугами поисковой системе нужно найти и предложить пользователям наиболее удобные, информативные и авторитетные. Понятно, что все эти характеристики субъективны, а поисковый алгоритм может использовать только измеримые параметры. Главной целью является новые и более объективные показатели эффективности ториентированного поиска, эффективность управленческих решений и запросов в сфере предоставления товаров и услуг.
Основные задачи исследования:
- Анализ моделей поведения для пользователя [9].
- Анализ моделирования сессии пользователя.
- Анализ новых принципов построения более совершенных поисковых систем [8].
- Разработка метода оптимизации поисковых запросов в сфере предоставления товаров и услуг.
Объект исследования: оптимизация поисковых запросов в сфере предоставления товаров и услуг.
Предмет исследования: метод моделирования поведения пользователей.
В рамках магистерской работы планируется получение актуальных научных результатов по следующим направлениям:
- Разработка подхода к модели поведения пользователя при формировании заказа в сфере предоставления товаров и услуг программным методом.
- Разработка личного сайта, на основе которого будут проведены исследования, для апробирования этого метода.
- Модификация известных методов модели поведения пользователя и оценка эффективности применения их для оптимизации поисковых запросов.
3. Обзор исследований и разработок
С каждым годом всё более привычным способом доступа к различной информации становится сеть Интернет. Поисковые системы это важнейшая часть современного интернета и ставший уже неотъемлемым признак современного информационного общества. Модели поведения пользователей является одним из основных направлений исследований в области улучшения поиска.
3.1 Обзор международных источников
Технологии интернет поиска растут вместе с запросами пользователей. Специалистам постоянно приходится развиваться и успевать отслеживать информацию о внесенных изменениях в требования и алгоритмы ведущих поисковых систем. Можно предположить, что в этой области исследований можно ожидать новых прорывов в самое ближайшее время.
Хотелось бы выделить зарубежных экспертов данной тематике:
- Eugene Agichtein – профессор университета Эмори штат Джорджия США [1].
- Chris Bishop – член Королевской академии технических наук [2].
- Nick Craswell – научный сотрудник Bing в Bellevue Вашингтоне [4].
- Monica Wright – директор по работе с аудиторией в печатных изданиях.
- Trevor Hastie – профессор математических наук Стэнфордского университета [3].
3.2 Обзор национальных источников
В Украине достаточно мало специалистов, которые рассматривали бы данную тематику исследования. Первым за специалистов стал Дубинский А.Г. аспирант Национального технического унивеститета Украины Киевский политехнический институт
[10]
3.3 Обзор локальных источников
В Донецком национальном техническом университете проблемами интеллектуального анализа интернет страниц занималася магистр Шинкаренко В.С. по теме: Анализ аудитории и прогнозирование посещаемости интернет ресурса
. В работе проводится анализ целевой аудитории интернет ресурса и нахождение зависимостей для прогнозирования и оценки посещения сайта и других параметров.
4. Принципы информационного поиска
Информационный поиск
В наше время под поиском информации обычно подразумевают поиск в интернете, однако термин информационный поиск
возник гораздо раньше. Согласно монографии [6] это процесс поиска в большой коллекции (хранящейся, как правило, в памяти компьютеров) некоего неструктурированного материала, удовлетворяющего информационные потребности.
Для взаимодействия с поисковой системой пользователь делает запрос на языке понятном системе. В ответ на запрос система выдаёт пользователю упорядоченный список документов. Для определения соответствия документов запросам в теории информационного поиска вводится следующее понятие: релевантность – это соответствие документа информационному запросу. По методу определения обычно различают формальную и содержательную релевантности. Формальная релевантность определяется с помощью некоторого алгоритма, реализованного в поисковой системе. Содержательная релевантность – это соответствие документа запросу пользователя, определяемое неформальным путём, по семантике документа.
На первый взгляд, цель информационного поиска можно сформулировать следующим образом: найти все релевантные документы. Но при работе с большими коллекциями документов итоговое количество документов, соответствующих запросу, может быть на столько большим, что человек просто не сможет просмотреть их все. Таким образом, одной из важных задач поисковой системы является ранжирование документов по степени их соответствия запросу. Функцию, сопоставляющую каждому документу число документа данному запросу – называют ранжирующей функцией (ranking function). Эта функции учитывает различные признаки документа, запроса, а также всей коллекции документов в поисковой системе.
Предметное индексирование и механизм поиска
Когда говорят об поисковой системе, подразумевают, что она использует предметный указатель. Предметный указатель позволяет отыскивать документы, касающиеся некоего предмета
. Для составления предметного указателя анализируется содержание документа и определяется предмет
или предметы
, о которых в документе идет речь. Затем названия этих предметов переводятся на информационно-поисковый язык (ИПЯ). Таким образом, мы получаем поисковый образ документа (ПОД). Проиндексировав (создав поисковые образы) все информационные ресурсы, мы получаем то, что принято называть индексом (index database).
Так как процесс поиска заключается в сопоставлении запроса пользователя с имеющимися данными, полученный запрос также должен быть переведен на ИПЯ. После сопоставления переведенного на ИПЯ запроса и поисковых образов документов пользователь получает список ссылок на документы, которые соответствуют, по мнению системы, его запросу. Типовая схема ИПС, использующей предметное индексирование, представлена на рис.1.
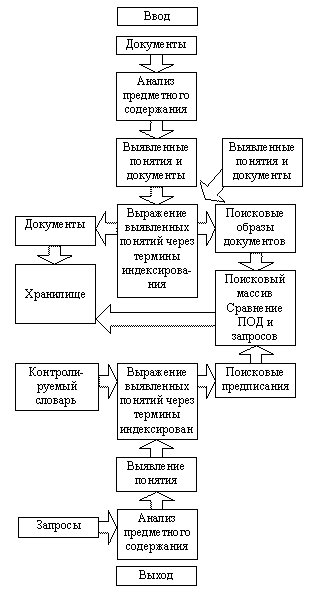
Рисунок 1 – Индекс поисковых систем (ИПС)
Как видно, поиск происходит не по тексту документов, а по их поисковым образам, составленным на ИПЯ. Поэтому ИПЯ - основная часть информационно-поисковой системы, от которой в первую очередь зависит качество системы. В состав информационно-поискового языка входят:
- Словарь индексационyых терминов.
- Кодовый словарь.
- Словарь входов.
- Вспомогательные средства языка индексирования, используемые совместно с индексационными терминами для расширения или сужения определенных понятий.
- Правила использования языка индексирования.
Для повышения эффективности поиска словарь, используемый системой, должен быть контролируемым, то есть он должен быть организован таким образом, чтобы полнота и точность поиска была оптимальной. Очевидно, что организация словаря зависит от многих факторов предметной области, в которой будет использоваться ИПС, характера интересов пользователей, степени их подготовки и т. д.
Для улучшения результатов поиска необходимо определить степень специфичности терминов, используемых при индексации. Принято использовать два принципа: использование наиболее специфического термина, соответствующего объему и содержанию отражаемого понятия, и избыточное индексирование. Под избыточным индексированием понимается дополнение поискового образа терминами, связанными с основным. При этом могут использоваться термины, связанные как с основным отношением обобщения или спецификации, так и ассоциативной связью. Дополнение поискового образа терминами с ассоциативной связью может увеличить полноту поиска, но неизбежно понижает его точность. Недостатком избыточного индексирования является также увеличение объема поисковых образов. Для решения этой проблемы во многих ИПС используется избыточное индексирование не документов, а запросов. Использование предметного индексирования не исключает использования при создании поискового образа атрибутов документа. Это могут быть такие атрибуты, как данные об авторе, дата публикации, язык публикации и т. д.
Стратегии поиска
Точность и полнота поиска зависят не только от характеристик самой ИПС, но и от того, как создается запрос. Идеальный запрос может быть составлен пользователем, в полном объеме знакомым с той предметной областью, которая его интересует, а также с используемой ИПС. Но такому пользователю ИПС, очевидно, не нужна. Остальные же пользователи вынуждены довольствоваться или низкой точностью поиска, или низкой полнотой. Для повышения качества поиска можно использовать различные методы. Наиболее употребляемый из них AND, OR, NOT. Использование логических операторов простой способ повысить релевантность выдаваемых документов, но он имеет и свои недостатки. Главный недостаток плохая масштабируемость. Применение оператора AND может сильно сузить выдачу, а оператора OR может сильно расширить. Степень точности и полноты поиска зависит от того, насколько общие термины использовались при формулировке запроса. Может быть неверным использование как наиболее общих терминов (возрастает уровень информационного шума), так и слишком специфичных терминов (снижается полнота поиска). Использование слишком специфичных терминов может быть чревато еще и тем, что в словаре ИПС этого термина может не оказаться. В общем виде процедура поиска является процедурой итеративной, то есть за этапом выдачи результатов поиска следует коррекция запроса, поиск по этому запросу и т. д. Схематично такая процедура показана на рис.2.
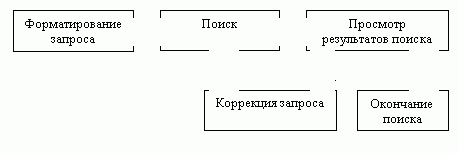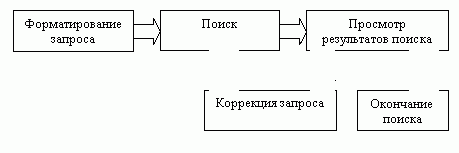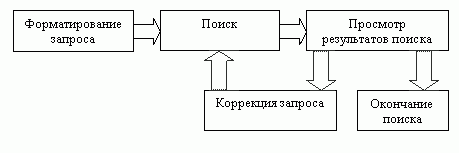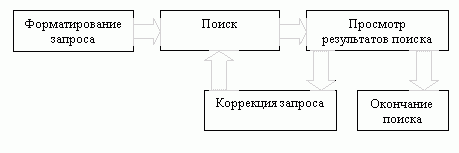
Рисунок 2 – Процедура поиска
Коррекция запроса происходит исходя из количества полученных документов и их релевантности, и может выполняться как пользователем, так и самой поисковой системой.
В зависимости от соотношения полноты и точности найденных документов пользователь может сузить или расширить область поиска, перейдя к более общим или, наоборот, более специфичным терминам. В случае поиска по нескольким терминам такая коррекция области поиска может происходить по одному из нескольких терминов, что позволяет изменять эту область. Может оказаться полезным знание пользователя о наличии определенно релевантных документов. Не найдя их в списке найденных документов, область поиска надо расширить.
Коррекция запроса системой информационного поиска происходит на основании анализа документов, помеченных пользователем как наиболее точно отвечающих его потребности. В таком случае при следующем поиске система ищет те документы, в которых, помимо заданных в первоначальном запросе, содержатся термины, встречающиеся в документах, отмеченных пользователем. Улучшить результаты поиска можно различными способами, если функции для этого предоставляются интерфейсом поисковой системы.
Вероятностная модель поиска
Пользователь неточно формулирует свою информационную потребность в виде запроса. Имея только запрос, система не может точно определить релевантность того или иного документа. Для принятия решений в условиях неопределённости необходим математический аппарат теории вероятностей.
Предположим, что оценки релевантности бинарные: документ может быть либо релевантным данному запросу, либо не релевантным. Таким образом, для каждого документа d и запроса q вводится случайная величина R(d,q) – показатель релевантности; она равна единице, если документ d является релевантным запросу q, и равна нулю в противном случае. Когда это не вызывает недоразумений, будем обозначать показатель релевантности просто R.
В рамках такой модели естественным является ранжирование документов по оценённым вероятностям их релевантности запросу: p(R(d,q) = 1). Такой подход лежит в основе вероятностного принципа ранжирования, предложенного Робертсоном в 1977 году [7].
Его основные положения:
- Релевантность документа запросу не зависит от других документов в коллекции;
- Вероятностный принцип ранжирования: если поисковая система в ответ на каждый запрос пользователя ранжирует документы в порядке убывания их вероятности быть релевантными запросу пользователя, и эта вероятность оценивается наиболее точно на основе доступных данных, то общее качество системы является наилучшим на основе доступных данных.
Особенности оценки технической эффективности поиска
1. Приоритетно тестирование точности. В типовом случае по запросу находится очень много документов, среди которых немало и релевантных. Поэтому большее значение имеет не полнота, а точность поиска. Действительно, рассмотрим 2 поисковые машины. По некоторому запросу 1-я машина находит 200 документов и все они релевантные. 2-я машина по этому же запросу находит 5000 документов, из которых релевантны 500, причем среди первых 200 документов релевантны только 100. И хотя полнота поиска2-й машины существенно выше, совершенно очевидно, что лучше 1-я машина, поскольку редкий пользователь способен просмотреть несколько сотен найденных документов (чаще же всего пользователь ограничивается первой страницей результатов поиска).
2. Нужно тестировать качество ранжирования. Найденные документы выдаются в ранжированном виде, поэтому при оценка качества поиска нужно учитывать позицию документа в списке найденного, то есть качество поиска по запросу следует характеризовать набором значений точности при разном размере начальной части списка документов, например, задавать значения точности при 10, 30, 50, 70 и 100 документах из начальной части списка. Чем больше количество значений, тем точнее оценка, но и трудоемкость оценки больше.
3. Нужна градация значений точности. Из множества значений точности, характеризующих качество поиска по запросу, более важны те, которые получены для небольшого количества документов. Например, точность при 30 документах важнее точности при 300 документах. Другими словами, основной интерес представляет зависимость между полнотой и точностью в области малых значений полноты.
Критерии оценки качества поиска
Для оценки качества поиска необходимо иметь некоторое тестовое множество, содержащее «достоверную» информацию о том, какой документ является релевантным каким запросам. Обычно тестовое множество строится специальными экспертами и состоит из оценок релевантности для пар (запрос, документ). Оценки могут быть числовыми или категориальными. Так как оценки получают от людей, тестовое множество покрывает лишь малую часть всей базы поисковой системы и его получение является трудоёмким и дорогостоящим.
Классическими параметрами для оценки качества работы поисковой системы являются точность и полнота:
- Точность (precision) – количество релевантных запросу документов в выдаче, делённое на общее количество документов в выдаче;
- Полнота (recall) – количество релевантных запросу документов в выдаче, делённое на общее количество релевантных документов в базе поисковой системы.
Выводы
На основе анализа размещения информации в ресурсах Internet, тематического расслоения информационного пространства, особенностей функционирования поисковых роботов и механизмов индексирования поисковых систем, а также наиболее актуальных способов и методов исследования и оптимизации поисковых запросов, был сделан вывод о возможности и необходимости создать упрощенную методику быстрой пользовательской оценки качества и ранжирования поисковых запросов.
Результаты будут представлены в несколько этапов. На первом этапе будет проводится сравнительный анализ нескольких методов информационного поиска. На втором – будет проведена экспериментальная проверка предложенных методов на основе стандартных наборов тестовых данных.
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: декабрь 2015 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Список источников
- Ageev M., Guo Q., Lagun D., Agichtein E. Find it if you can: a game for modeling different types of web search success using interaction data. Proceedings of the 34th Annual ACM SIGIR Conference, 2011.– P. 345–354.
- Bishop C. M. Pattern Recognition and Machine Learning. Springer, 2006.
- Hastie T., Tibshirani R., Friedman J. Elements of StatisticalLearning. Springer, 2008.
- Craswell N., Zoeter O., Taylor M., Ramsey B. An experimental comparison of click position-bias models. Proceedings of the 1st ACM International Conference on Web Search and Data Mining,2008.– P. 87–94.
- Яндекс. Поиск в интернете: что и как ищут пользователи.Информационный бюллетень «Яндекс»
- Manning C. D., Raghavan P., Sch¨utze H. Introduction to Information Retrieval. Cambridge University Press, 2008.
- Robertson S. E. Probability ranking principle in IR. Journal of Documentation, 1977.– P. 294–304.
- Breiman L., Friedman J. H., Olshen R. A., Stone C. T. Classification and Regression Trees. New York: Chapman Hall, 1984.
- Николенко С. И., Фишков А. А. SCM: новая вероятностная модель поведения пользователей интернет-поиска. Труды СПИ-ИРАН, 2012.
- Дубинский А.Г. Факторы, влияющие на качество информационного поиска. Системний аналіз та інформаційні технології: Зб. тез доп. Міжн. наук.-практ. конф. студ., аспірантів та молод. вчених. - Киев: НТУУ «КПІ», 2001.– c. 43– 48.