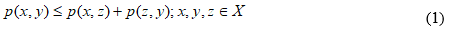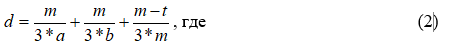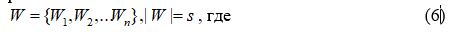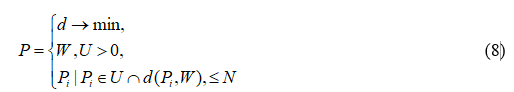Реферат по теме выпускной работы
Введение
В настоящее время популярны покупки товаров через Интернет-магазины. Пользователю не нужно выходить из дома, а достаточно выйти в сеть Интернет, зайти в любой интернет-магазин и заказать себе какой-либо товар.
Популяризация продажи товаров через интернет-магазин привело к росту числа интернет-магазинов. Каждый из них может продавать одну и туже продукцию, но выставляет свою цену и свои условия. Такая политика цен может привлечь новых клиентов или же наоборот, сделать выбора в пользу другого интернет-магазина.
1. Актуальность темы
Пользователь ставит пред собой цель – найти наиболее подходящий для себя товар по различным критериям (цена, характеристики и т.д.), но метод отбора данного товара производится вручную пользователем. В результате чего, можно выделить ряд недостатков, таких как:
- Трата времени на ознакомления с интерфейсом каждого нового интернет-магазина просматриваемого пользователем;
- Пользователь должен запоминать / записывать вручную найденный нужный товар и сравнивать его;
- Не всегда корректный встроенный поиск интернет-магазина;
- И т.п.
Для исключения этих недостатков, были внедрены системы сбора данных с других интернет-магазинов. Данные системы исключают два недостатка: ручного поиска по интернет-магазинам и сравнения их по критериями (к примеру, сортировка по цене одного вида товара). Но данные системы имеют свои недостатки:
- Отсутствие распознавания и обработки ошибок запросов пользователей;
- Неполноценный сбор информации;
- Нет возможности расширения параметров поиска, для более точной / расширенной выборки данных.
Основной задачей системы будет направлена на устранение недостатков в уже существующих систем за счет оптимизации поиска различных запросов пользователей и выдачи качественного ответа. Рассмотрим задачу поиска и отбора товаров.
2. Цель и задачи исследования, планируемые результаты
Пользователь зайдет в систему. В строке поиска укажет свой запрос и подтвердит его. После, система начнет обрабатывать запрос. Она примет запрос (входные данные), произведёт выборку товаров и выведет список отобранных товаров (выходные данные) с минимальной информацией (цена, название, характеристики и т.д.) и ссылкой на заказ этого товара.
Опираясь на входные и выходные данные представлен такой алгоритм работы поиска и отбора товаров в системе:
- Индексация содержимого сайта.
- Ввод запроса пользователем и подтверждаем.
- Система из запроса исключаются служебные части речи
- Получившаяся строка разбивается на массив слов, переведенных в базовую форму
- Поиск каждого слова полученного массива осуществляется в индексе,
- Результаты поиска ранжируются, сортируются и отдаются пользователю.
Также, при недостаточном или неполном списке товаров, пользователь может расширить параметры поиск. Расширение параметров поиска за счет добавления нового ограничения к своему ранее указанному запросу. Система произведет повторное выполнение алгоритма для более лучшего ответа. Также, для повышения эффективности поиска, система ведет статистический журнал поиска пользователей.
Целью данной работы является повышение эффективности процесса поиска информации в зависимости от запроса, а также сокращение времени получения качественных и точных результатов запросов.
Для решения поставленной цели, необходимо решить ряд задач:
- Автоматическое формирование и ранжирование списка товаров;
- Автоматическое дополнение запроса ограничениями на основании статистических данных с целью улучшения качества ответа пользователю;
- Разработки подсистемы для хранения данных; (индексация данных)
Для решения поставленных задач, необходимо выполнить анализ существующих методов, выделить их достоинства, недостатки и выбрать наиболее перспективные из них.
3. Обзор алгоритмов и методов поиска
Задача методов нечеткого поиска заключается в отборе совпадений заданного слова (или начинающиеся с этого слова) из N-размерного текста или словаря. Одной из характерных черт алгоритма нечеткого поиска является метрика.
Метрика – это функция расстояния между двумя словами, позволяющая оценить степень их сходства в данном контексте. Строгое математическое определение метрики (X — множество слов, p — метрика) [1]:
3.1 Расстояние Хемминга
Расстояние Хэмминга – мера различающихся позиций для объектов с одинаковой длинной. Широко используется для различных задач, таких как поиск близких дубликатов, распознавание образов, классификация документов, исправление ошибок, обнаружения вирусов и т.д [2].
Основным недостатком расстояния редактирования Хэмминга является требование одинаковой длины строк, таким образом, расстояние Хэмминга подходит для расчета расстояния редактирования с учетом таких искажений, как замена и транспозиция, но не подходит при вставках и удалениях.
3.2 Джаро-Винклер
Сходство Джаро-Винклера (Jaro-Winkler similarity) было применено в переписи США и использовано в последующей обработке [2].
Для данных строк string1 и string2, их сходство задаётся формулой:
m - число соответствующих символов
a - длина string1
b - длина string2
t - число перестановок
Два символа считаются соответствующими, только если они находятся не дальше чем (max(a,b)/2 - 1). Первый соответствующий символ в string1 сравнивается с первым соответствующим символом в string2; второй соответствующий символ в string1 сравнивается со вторым соответствующим символом в string2, и так далее. Число соответствующих символов делённое на 2 даёт число перестановок[8].
Улучшенный метод Джаро-Винклера использует веса отличные от 1/3. Он также даёт меньший вес некоторым типам ошибок: визуального сканирования, клавишного ввода и в конце строки.
3.3 Распознавание форм Ратклиффа/Обершелпа (алгоритм Оливера)
Алгоритм Ратклиффа/Обершелпа (Ratcliff/Obershelp pattern recognition) вычисляет сходство двух строк как удвоенное число соответствующих символов разделённое на полное число символов в строках.[9]
Соответствующие символы находятся в самой длинной общей подпоследовательности плюс, рекурсивно, соответствующие символы в остальной части по любую сторону от самой длинной общей подпоследовательности. Формула данного алгоритма:[4]
Km - число совпадающих символов,
|S1|, |S2| - длина сравнивающихся слов
3.4 Дистанция редактирования (Расстояние Левенштейна и Дамерау – Левенштейна)
Расстояние Левенштейна ищет минимальное количество действий (вставок, удаления и замены одного символа на другой), необходимых для превращения одной строки в другую. Метод широко используется для исправления ошибок в словах (грамматика поисковых систем), сравнения текстовых файлов или даже генов и хромосом. [3]
Преобразовать одно слово в другое можно различными способами, количество действий также может быть разным. При вычислении расстояния Левенштейна следует выбирать минимальное количество действий.
Если поиск слова осуществляется в тексте, который набран с клавиатуры, то вместо расстояния Левенштейна используют усовершенствованное расстояние Дамерау – Левенштейна.
Алгоритм Вагнера – Фишера позволяет получать расстояние Дамерау – Левенштейна.
3.5 Методы поиска с использованием индексов
Особо интересными являются алгоритмы поиска с индексацией.
Представим, одновременно более 30 человек выполняют поисковые запросы. Сервер принимает каждое соединение, управление потоком передается интерпретатору. При каждом запросе заново инициализируется поисковый движок, заново прерывается содержимое сайта. Сложно сказать, сколько времени и ресурсов потребуется, чтобы обработать все эти запросы. Для исключения проделывания одной и той же работы, была придумана технология индексирования.
Индексирование выполняется только при изменении или добавлении содержимого сайта, а поиск выполняется уже по индексу, а не по содержимому.
Особенностью всех алгоритмов нечеткого поиска с индексацией является то, что индекс строится по словарю, составленному по исходному тексту или списку записей в какой-либо базе данных.[10]
Наиболее распространенные из алгоритмов:
- Метод расширения выборки (query extension);
- Метод n-грамм.
Алгоритм расширения выборки
Он основан на сведении задачи о нечетком поиске к задаче о точном поиске.
Суть данного метода заключается в построении множества всевозможных «ошибочных» слов, например, получающихся в результате одной операции редактирования Левенштейна, после чего построенные поисковые запросы ищутся в словаре на точное совпадение.
Одним из недостатков данного алгоритма то, что время его работы сильно зависит от числа k ошибок и от размера алфавита A, и в случае использования поиска по словарю составляет [5]:
Σ – размер алфавита,
n – размер слова,
k – число ошибок.
Например, если для поиска с k = 1 требуется выполнить 300-500 «точных» запросов к словарю, то для k = 2 требуется не менее 10000 запросов.
Следует отметить, что в некоторых случаях можно ограничить класс операций замен и достичь приемлемого сочетания полноты и качества поиска.
Особенность данного алгоритма заключается в том, что он: не требует никакой предварительной обработки словаря; экономит память за счет использования не всего словаря.
Метод Триграмма (N-грамма)
Триграммное сходство (trigram similarity) между двумя строками определяется числом совпадающих символьных триплетов в обоих строках. Алгоритм можно обобщить на n-граммы, где n=1, 2, ... Строки string1 и string2 пополняются слева и справа одним символом пробела. Затем строки разделяются на триплеты (триграммы). Окончательно, сходство вычисляется по формуле [2]:
m - число совпадающих триграмм,
a и b - число триграмм в string1 и string2
Особенность данного метода заключается в простоте реализации. Но чем меньше длина слова и чем больше в нем ошибок, тем выше шанс того, что оно не попадет в соответствующие N-граммам запроса списки, и не будет присутствовать в результате. За счет чего необходимо модифицировать данный метод или же использовать более эффективных методов.
Эти все методы и алгоритмы используют различные подходы к решению проблемы — одни из них используют сведение к точному поиску, другие используют свойства метрики для построения различных пространственных структур. Но все они очень чувствительны к изменениям содержимого и длине сравниваемых слов. Например:
- Расстояние Левенштейна при перестановке слов в предложении принимает большое значение;
- Расстояние Левенштейна может быть велико для больших похожих слов, но при этом, если есть два коротких слова значительно отличающихся друг от друга, то тогда расстояние Левенштейна будет мало.[2]
Скорость выполнения работы алгоритмов нечеткого поиска обычно напрямую зависит от размера словаря. Но, модификации и доработки этих алгоритмов позволяют добиться достаточного малого времени работы даже при весьма больших объемах словарей.
4. Математическая постановка
Для данной задачи мы имеем исходные данные, представленные в виде запроса пользователя W, который он ввел в поисковой строке. Длина этого запроса может быть Wn-слов. Данный запрос имеет такие ограничения:
s – любая длина поискового запроса,
Также, имеется словарь U размерности m. Словарь содержит подмножество 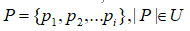 - содержащий некую информацию о товарах, которые он и индексирует у себя. Словарь имеет такие ограничения:
- содержащий некую информацию о товарах, которые он и индексирует у себя. Словарь имеет такие ограничения:
Имея заданный поисковый запрос W пользователя, нам необходимо выбрать из словаря U подмножество P всех слов. А мера отличия d при сравнении поискового запроса между словарем должна не превышать некоторого порогового числа N. Если подмножество P удовлетворяет этому условию, то из словаря будет добавлено это подмножество (товар и его информация) в массив ответа пользователю с информацией о товаре.
Мера отличия стремиться к минимальному числу расхождения при сравнении поискового запроса с подмножеством из словаря. Для нахождения меры отличия используем один из нижеописанных методов.
Вывод
В результате проведенного обзора актуальных методов и алгоритмов нечеткого поиска, были отмечены достоинства и недоставки этих методов.
Также, выделим алгоритмы с индексацией. Они имеют сложную реализацию, а также требуют подготовленный словарь для сравнений, но, значительно быстрее выполняют сравнение строк большой размерности, а также более точно определяют схожесть этих строк. Данные алгоритмы с их модификацией наиболее подойдут для реализации поставленных задач в пределах исследуемой области.
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: июнь 2019 года. Полный текст работы
и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Список источников
- Нечёткий поиск в тексте и словаре [Электронный ресурс]. – Режим доступа: https://sohabr.net/habr/post/1149...
- Алгоритмы приблизительного сравнения текста [Электронный ресурс]. – Режим доступа: http://alexandrerodichevski.chiappani...
- Вычисление редакционного расстояния [Электронный ресурс]. – Режим доступа: https://habr.com/post/117063/
- Comparison of Jaro-Winkler and Ratcliff/Obershelp algorithms in spell check [Электронный ресурс]. – Режим доступа: ib-extended-essay-ilovepdf-compressed.pdf
- Классификация современных алгоритмов нечеткого словарного поиска [Электронный ресурс]. – Режим доступа: http://rcdl.ru/doc/2004/paper27.pdf
- Программаная реализация Алгоритма Левенштейна [Электронный ресурс]. – Режим доступа: https://moluch.ru/archive/19/1966/
- Вычисления Левенштейна [Электронный ресурс]. – Режим доступа: https://docviewer.yandex.ua/view/0/...
- ВЫЯВЛЕНИЕ ДУБЛИКАТОВ В РАЗНОРОДНЫХ БИБЛИОГРАФИЧЕСКИХ ИСТОЧНИКАХ [Электронный ресурс]. – Режим доступа: https://nsu.ru/xmlui/bitstream/handle/nsu/7131/10.pdf
- Применение алгоритмов нечеткого поиска в PHP [Электронный ресурс]. – Режим доступа: https://habr.com/ru/post/115394/
- Индекс (базы данных) [Электронный ресурс]. – Режим доступа: https://ru.wikipedia.org/wiki/Индекс_(базы_данных)