Актуальность темы
В связи с неуклонным ростом сложности и функциональности приборов, а также необходимости диагностики их технического состояния методы компактного тестирования c локализацией ошибок являются одними из наиболее актуальных методов решения задач тестовой диагностики. Достоинством этих методов является значительное сокращение объёма информации, необходимой для проведения тестового эксперимента. При традиционном методе компактного тестирования, контроль проводится по принципу "годен — не годен", что является недостаточным в выявлении типа неисправности в отказавшем элементе дискретного устройства. Необходимо и важно определить момент времени, когда на выходе схемы появляется ошибка, то есть локализовать ошибку в выходной тестовой последовательности битов. Данный метод позволяет выявить и определить тип неисправности на основании полученных последовательностей битов, что позволит ускорить диагностику элементов дискретных устройств [1].
Работа посвящена разработке методики проектирования устройств компактного тестирования с локализацией ошибок и исследование их характеристик.
Цели и задачи
Целью данной работы является разработка методики проектирования устройств компактного тестирования с локализацией ошибок и исследование их характеристик.
Задачами работы является обзор существующих методов локализации ошибок и исследование их характеристик для разработки методики проектирования устройств компактного тестирования.
Предполагаемая научная новизна
Предполагаемая научная новизна и планируемые практические результаты заключаются в получении методики проектирования устройств компактного тестирования с локализацией ошибок и исследование их характеристик, а также разработка нового и более оптимального устройства компактного тестирования с локализацией ошибок, которое ранее не рассматривался в различной литературе, либо недостаточно полно рассматривался.
Основное содержание работы
В работе рассматриваются методы компактного тестирования с локализацией ошибок в выходной тестовой последовательности битов, основанные на циклических кодах Хэмминга, Файра, БЧХ, Рида-Соломона, а также проводится исследование их характеристик.
Циклические коды Хэмминга
Центральную роль при построении циклических кодов играют так называемые порождающие (образующие) полиномы. Для циклических кодов Хэмминга в качестве, порождающих используются так называемые неприводимые полиномы.
Неприводимым называется полином, который не может быть представлен в виде произведения полиномов низших степеней (аналогия с простыми числами). Неприводимые полиномы выбираются из таблиц.
Количество проверочных символов циклического кода равняется степени порождающего полинома и, наоборот, степень порождающего полинома равняется числу проверочных символов.
Основная идея циклического кодирования заключается в том, что разрешенное кодовое слово должно делиться на порождающий полином без остатка.
Остаток от деления принятого декодером кодового слова на порождающий полином выступает в роли синдрома. Если остаток равен нулю, декодер полагает, что ошибок не было. В случае ненулевого синдрома в зависимости от его вида декодер выполняет исправление ошибок.
Различают систематические и несистематические циклические коды.
Пример систематического циклического кода Хэмминга
Исходные данные:
количество исправляемых ошибок: s=1, dmin=3;
количество информационных символов: k=4;
количество проверочных символов: p = [log 2{(k + 1) + [log 2 (k + 1)]}] = 3;
cтепень порождающего полинома: deg K(x) = p = 3;
порождающий полином третьей степени: K(x) = х3 + х + 1.
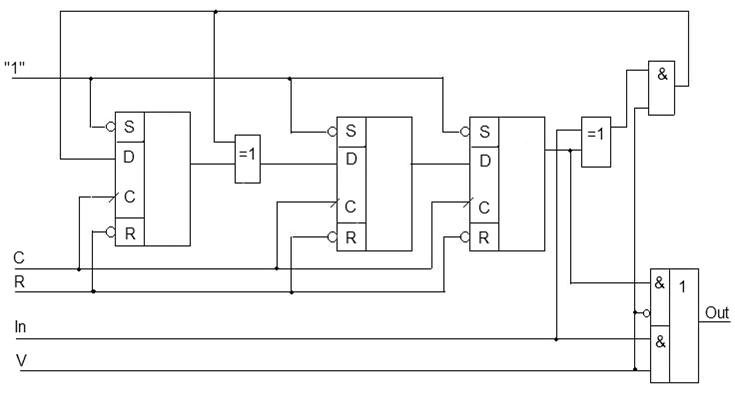 Рисунок 1 — Принципиальная схема кодера систематического кода Хэмминга
Рисунок 1 — Принципиальная схема кодера систематического кода Хэмминга
V — управляющий сигнал;
C — синхросигнал;
R — активный сигнал сброса;
In — информационный сигнал;
Out — выход кодера.
Пример несистематического циклического кода Хэмминга
Исходные данные:
количество исправляемых ошибок: s=1, dmin=3;
количество информационных символов: k=4;
количество проверочных символов: p = [log 2{(k + 1) + [log 2 (k + 1)]}] = 3;
cтепень порождающего полинома: deg K(x) = p = 3;
порождающий полином третьей степени: K(x) = х3 + х + 1.
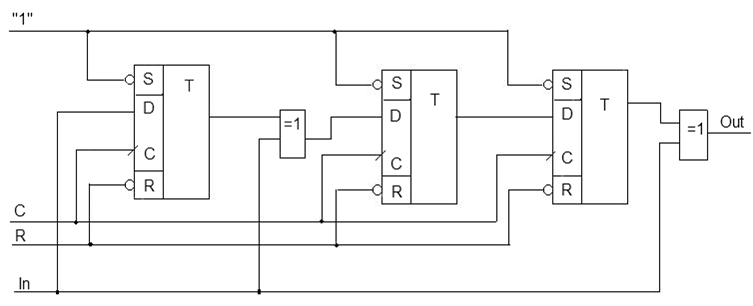 Рисунок 2 — Принципиальная схема кодера несистематического кода Хэмминга
Рисунок 2 — Принципиальная схема кодера несистематического кода Хэмминга
C — синхросигнал;
R — активный сигнал сброса;
In — информационный сигнал;
Out — выход кодера.
Декодер Меггитта
Декодер Меггитта выполняет не только операцию деления на порождающий полином К(х), но и, как кодер циклических кодов, операцию умножения на полином х р.
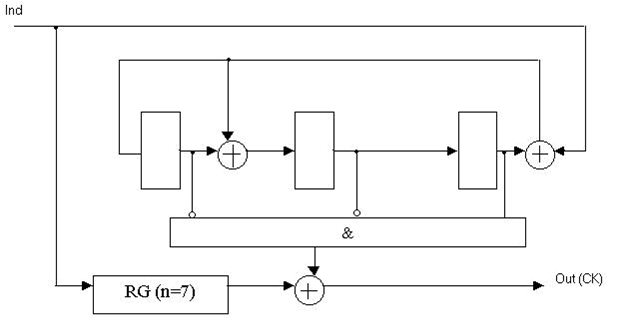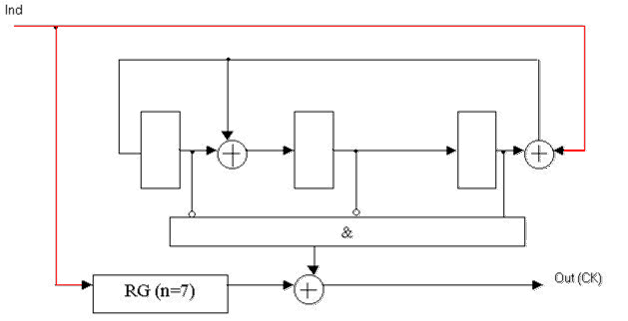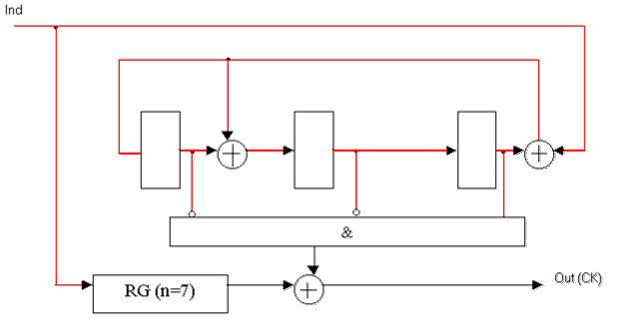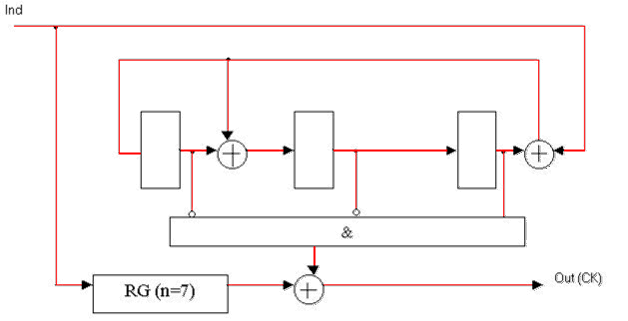 Рисунок 3 — Функциональная схема декодера Меггитта для систематического (7, 4)-кода Хэмминга с порождающим полиномом K(x) = x3 + x + 1.
Рисунок 3 — Функциональная схема декодера Меггитта для систематического (7, 4)-кода Хэмминга с порождающим полиномом K(x) = x3 + x + 1.
(Анимация: объем - 61.4 КБ; размер - 628х321; количество кадров - 4; задержка между кадрами - 80 мс; задержка между первым и последнимкадрами - 320 мс; количество циклов повторения - бесконечное.)
RG(n=7) — регистр разрядностью 7;
Ind — информационный сигнал декодера;
Out(СК) — выход декодера.
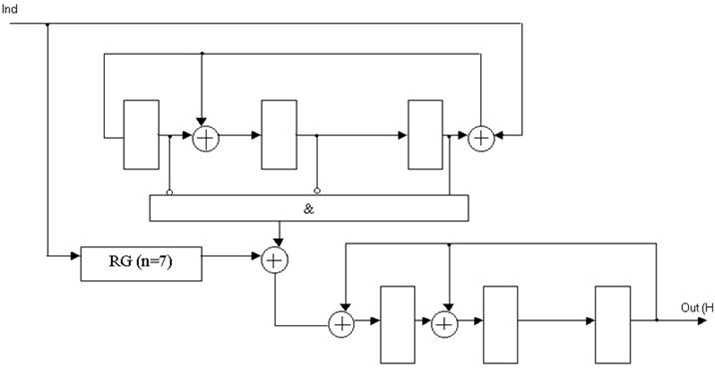 Рисунок 4 — Функциональная схема декодера Меггитта для несистематического (7, 4)-кода Хэмминга с порождающим полиномом K(x) = x3 + x + 1.
Рисунок 4 — Функциональная схема декодера Меггитта для несистематического (7, 4)-кода Хэмминга с порождающим полиномом K(x) = x3 + x + 1.
RG(n=7) — регистр разрядностью 7;
Ind — информационный сигнал декодера;
Out(Н) — выход декодера [2].
Циклические коды Файра
Кодирующие устройства для кодов Файра строятся аналогично кодирующим устройствам для циклических кодов Хэмминга. Отличия заключаются в реализации декодера.
Порождающий полином кода Файра имеет вид:
F(x) = (x 2b-1 + 1)* P(x),
где Р(х) — примитивный полином, deg P(x) = b, b — длина исправляемого пакета ошибок. Длина кода n = (2b-1)*(2b-1), количество проверочных символов p = 3b – 1, количество информационных символов k = n – p, параметр меры неэффективности кода z = b – 1.
Пример систематического циклического кода Файра
Исходный код (105,94), b=2, g(x)= (х7+1)*(х4+х3+1)=х11+х10+х7+х4+х3+1.
Декодер имеет вид:
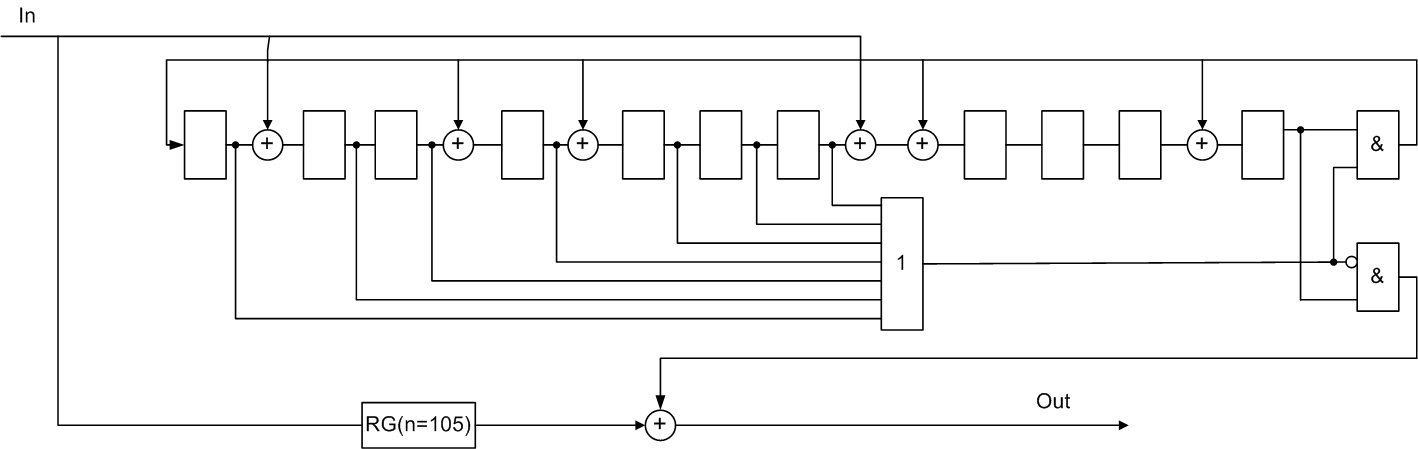 Рисунок 5 — Функциональная схема декодера Файра для систематического (105,94) кода
Рисунок 5 — Функциональная схема декодера Файра для систематического (105,94) кода
Пример систематического циклического кода Файра с перемежением
Исходный код (105,94), b=2, g(x) = (х7+1)*(х4+х3+1)=х11+х10+х7+х4+х3+1.
j=2, посимвольно перемеженный код (210,188), b=4, g(x) = х22+х20+х14+х8+х6+1.
Декодер имеет вид:
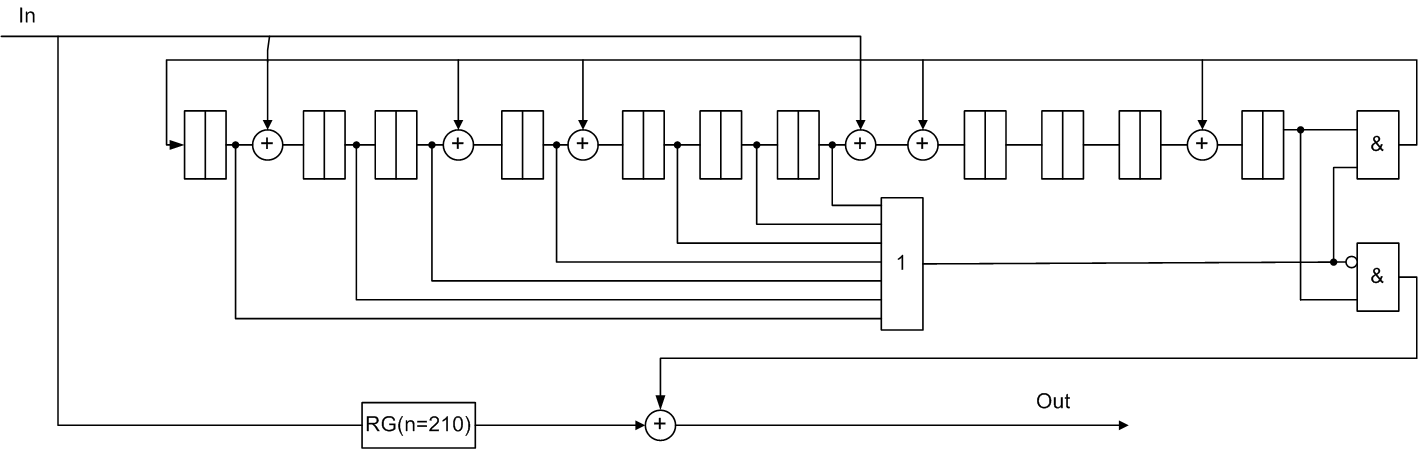 Рисунок 6 — Функциональная схема декодера Файра для систематического (210,188) кода с перемежением j=2
Рисунок 6 — Функциональная схема декодера Файра для систематического (210,188) кода с перемежением j=2
Методом посимвольного перемежения степени j можно получить более длинные коды, исправляющие пакеты ошибок длины (j*b). При этом, если исходный код имеет параметры (n,k) и порождающий полином g(x), то новыми параметрами будут (jn, jk) и g(xj) соответственно [2].
Функциональная схема декодера Файра для несистематического кода строится подобно, как и для кода Хэмминга.
Циклические коды БЧХ (Боуза – Чоудхури – Хоквингема)
Кодирующие устройства для кодов БЧХ строятся аналогично кодирующим устройствам для циклических кодов Хэмминга. Отличия заключаются в реализации декодера.
Рассмотрим реализацию декодера на примере кода БЧХ (15, 7), исправляющего две ошибки: порождающий полином В(х) = х8 + х7 + х6 + х4 + 1, длина кода n=15, количество проверочных символов p = deg B(x) = 8, количество информационных символов k = 7.
Декодер имеет вид:
 Рисунок 7 — Функциональная схема декодера БЧХ для систематического (15, 7) кода
Рисунок 7 — Функциональная схема декодера БЧХ для систематического (15, 7) кода
Декодер работает 3n тактов. Первые n тактов: формируется синдром, кодовое слово заносится в буферный регистр. Вторые n тактов: исправляется одна из существующих ошибок и кодовое слово вновь записывается в буферный регистр (ключ К – замкнут), третьи n тактов: исправляется вторая ошибка. Модификация синдрома для данного кода обязательна.
Недостатком данной схемной реализации является несогласованность работы кодера и декодера. Кодер должен ждать 2n тактов, пока декодер выполнит исправление.
Для устранения этого недостатка используется конвейерный вариант реализации декодера [2].
Метод посимвольного перемежения степени j для декодера кода БЧХ строится аналогично, как и для кодов Файра. А функциональная схема декодера БЧХ для несистематического кода строится подобно, как и для кода Хэмминга.
Циклические коды Рида-Соломона
Коды Рида-Соломона являются частным случаем кодов БЧХ. Главное отличие кодов Рида-Соломона заключается в том, что в качестве символа выступает не двоичный символ (один бит), а элемент поля Галуа (несколько битов).
Порождающий полином кода Рида-Соломона, исправляющего s ошибок, должен содержать 2s корней:
{aj0, aj0+1, aj0+2,…, aj0+2s-1},
где j0 – конструктивный параметр. Как правило, j0 выбирают равным 1. Тогда множество корней полинома принимает вид {a, a2, a3… a2s}.
Для кода Рида-Соломона, исправляющего s ошибок, порождающий полином имеет следующий вид:
RS(X) = (X-a)(X-a2)(X-a3)…(X-a2s).
При таком представлении порождающий полином имеет множество корней {a, a2, a3… a2s}.
Сущность помехоустойчивого кодирования заключается во введении в первичные коды избыточности. Поэтому помехоустойчивые коды называют избыточными. Задача помехоустойчивого кодирования заключается в таком добавлении к информационным символам первичных кодов дополнительных символов, чтобы в приемнике информации могли быть найдены и исправлены ошибки, возникающие под действием помех при передаче кодов по каналам связи. Формула вычисления избыточности имеет вид: R=p/n, где p — количество проверочных символов, n-длина кода. Значение p вычисляется по следующей формуле p=degRS(X)=2*s.
Длина исправляемого пакета ошибок для последовательного кода без каких-либо ограничений равна t=j*b-(b-1) для посимвольно перемеженного кода Рида-Соломона поля Галуа GF(2b) с параметром перемежения j [8].
Схему посимвольно перемеженного кода Рида-Соломона можно получить из схемы исходного кода, вставив дополнительно к каждому элементу памяти j-1 элементов. Например, для поля GF(23) при перемежении с параметром j=2 каждую триаду элементов памяти нужно заменить двумя последовательно включенными триадами [10].
Чтобы из (n, k)-кода получить (jn, jk)-код, выберем из исходного кода j произвольных кодовых слов и укрупним кодовые слова, чередуя их символы. Если исходный код исправлял произвольный пакет ошибок длины d, то, очевидно, результирующий код будет исправлять все пакеты ошибок длины jd. Например, применяя метод перемежения к четырём копиям (31, 25)-кода, исправляющего пакет ошибок длины 2, получаем (124, 100)-код, который может исправлять пакет ошибок длины 8[3].
Предположим, что исходный код порождается полиномом g(X). Тогда порождающий полином получаемого перемежением кода равен g(Xj). Заметим, что перемежение символов нескольких информационных полиномов с последующим умножением на g(Xj) даёт то же самое кодовое слово, что и умножение каждого из исходных информационных полиномов на g(X) с последующим перемежением этих слов (n, k)-кода [4].
На рисунках 8-9 представлены примеры схемной реализации декодеров кодов Рида-Соломона с полем Галуа GF(8) и GF(16), исправляющих одиночные ошибки.
![Функциональная схема декодера кода Рида-Соломона для поля Галуа GF(8) при s=1 [9]](../diss/decoderr.gif) Рисунок 8 — Функциональная схема декодера кода Рида-Соломона для поля Галуа GF(8) при s=1 [9]
Рисунок 8 — Функциональная схема декодера кода Рида-Соломона для поля Галуа GF(8) при s=1 [9]
 Рисунок 9 — Функциональная схема декодера кода Рида-Соломона для поля Галуа GF(16) при s=1
Рисунок 9 — Функциональная схема декодера кода Рида-Соломона для поля Галуа GF(16) при s=1
На рисунке 10 представлен пример схемной реализации декодера кода Рида-Соломона с полем Галуа GF(16), исправляющий двойные ошибки.
 Рисунок 10 — Функциональная схема декодера кода Рида-Соломона для поля Галуа GF(16) при s=2
Рисунок 10 — Функциональная схема декодера кода Рида-Соломона для поля Галуа GF(16) при s=2
На рисунке 11 представлен пример схемной реализации декодера кода Рида-Соломона с полем Галуа GF(8) и перемежением j=2, исправляющий одиночные ошибки.
![Функциональная схема декодера кода Рида-Соломона для поля Галуа GF(8) и j=2 [9]](../diss/decoderr3.gif) Рисунок 11 — Функциональная схема декодера кода Рида-Соломона для поля Галуа GF(8) и j=2 [9]
Рисунок 11 — Функциональная схема декодера кода Рида-Соломона для поля Галуа GF(8) и j=2 [9]
Устройство компактного анализа
Устройство компактного анализа (УКА) с локализацией пакетов ошибок длиной b может быть построено на основе декодера выбранного кода. Если (УКА) построено на основе циклического n, k-кода (n - длина кода, k - число информационных символов кода, n-k - число проверочных символов кода), то в качестве компактной оценки выступает остаток от деления анализируемой последовательности, представленной в полиномиальной форме и умноженной на полином xn-k, на порождающий полином g(x) кода. Если УКА построено на основе укороченного n-i, k-i-кода, компактной оценкой является остаток от деления анализируемой последовательности, представленной в полиномиальной форме и умноженной на полином xn-k+i, на порождающий полином g(x) кода. Операции умножения и деления полиномов в УКА реализуются на регистрах сдвига с линейными обратными связями [3,5,6]. Достоинствами применения укороченных циклических кодов для целей компактного анализа являются сокращения времени локализации пакета ошибок, возможность применения УКА для различных длин анализируемой последовательности, обеспечение принципиальной возможности применения кодов Файра для локализации больших пакетов ошибок [1,7].
Прежде чем перейти к сравнительному анализу кодов, сформулируем критерии эффективности их применения для целей компактного тестирования. Эти критерии и показатели, их характеризующие, следуют из требований, предъявляемых к устройствам компактного анализа: длина сигнатуры и аппаратные затраты должны быть минимальными; длина анализируемой последовательности должна быть приемлемой (не меньше требуемой длины, но не слишком большой); быстродействие должно быть максимальным [1,7].
Методика проектирования устройств компактного тестирования (УКТ) подразумевает следующие этапы:
–анализ объекта диагностики (тип устройства (комбинационный, последовательностнный, одновыводной или многовыводной), тип тестирования (зондовое, устройство встроенного контроля), исправный или заведомо неисправный, ошибки вызванные перемежающимися неисправностями, постоянными неисправностями, случайными сбоями, характер распределения ошибок различной кратности);
–анализ тестовых воздействий (исчерпывающее тестирование (комбинационные схемы), псевдослучайное тестирование, синтезированные тесты, случайные тесты и др.). Для синтезируемых тестов вероятность ошибки малой кратности максимальна. Для перемежающихся неисправностей вероятность одиночных ошибок максимальна. Для заведомо исправных объектов вероятность одиночного сбоя максимальна, при этом при повторном тестировании выявление может быть разным;
–выбор кода для реализации компактного тестирования.
Для случайных сбоев и перемежающихся неисправностей достаточно выбрать код Хэмминга. Для постоянных неисправностей целесообразно использовать коды исправляющие пакеты ошибок (коды Файра или коды Рида-Соломона). Все эти коды относятся к блоковым кодам. Древовидные коды для этих целей неприменимы. Кроме того, неприменимы для этих целей такие коды, как например турбо-коды, которые хотя и являются блоковыми, для них используются методы кодирования, разработанные для древовидных кодов;
–разработка УКТ на основе циклических блоковых кодах.
Основа УКТ — декодер выбранного кода без буферного регистра не конвейерной реализации. Для локализации ошибок используется счётчик. Перед сжатием тестовых реакций эталонная сигнатура загружается в генератор синдрома. В некоторых случаях не для укороченных кодов целесообразна альтернативная реализация генератора синдрома (схема деления полинома с внешними сумматорами в цепях обратной связи). В зависимости от длины теста используются декодеры для укороченных или не укороченных кодов;
–получение эталонных компактных оценок.
Эталонные компактные оценки рассчитываются либо аналитически, либо формируются с помощью заведомо исправного устройства и кодера выбранного кода. Загрузка эталонной последовательности УКТ может производиться либо параллельным, либо последовательным способом, как до начала тестирования, так и после, главное чтобы выполнялся принцип суперпозиции, то есть при совпадении компактных оценок результат посимвольного сложения ноль, а при несовпадении отличен от нуля.
- анализ характеристик различных реализаций кодов.
К примеру, коды Рида-Соломона. Описание характеристик можно посмотреть по следующим ссылкам [4,,
8,
10].
 Рисунок 12 — Функциональная схема УКТ основанная на декодере кода Рида-Соломона для поля Галуа GF(8)
Рисунок 12 — Функциональная схема УКТ основанная на декодере кода Рида-Соломона для поля Галуа GF(8)
Описание работы функциональной схемы УКТ приведённой на рисунке 12
Работа схемы начинается с ввода эталонной сигнатуры в элементы памяти генератора синдрома Рида-Соломона, затем по сигналу Start запускается генератор тестов и тестируемая схема. Генератор тестов посылает тестовую последовательность на тестируемую схему. Реакция тестируемой схемы подаётся на генератор синдрома Рида-Соломона, где происходит деление на порождающий полином и посимвольное сложение с эталонной сигнатурой. Затем происходит проверка битов с генератора синдрома Рида-Соломона на ноль, если да (все нули), то выдаётся сигнал нет ошибок. Иначе при обнаружении в одном блоке элементов памяти нулевое значение, а в другом не нулевое значение в таком порядке, как показано на схеме, то выдаётся сигнал об ошибке и счётчик прекращает свою работу на номере того такта, когда произошла ошибка.
Заключение
Таким образом, используя терминологию помехоустойчивого кодирования, эффективность применения кодов для целей компактного тестирования следует сравнивать по следующим показателям. Во-первых, число проверочных символов n-k кода должно быть минимальным, в этом случае длина сигнатуры и аппаратные затраты также будут минимальными. Во-вторых, длина кода n, соответствующая длине анализируемой последовательности, должна быть достаточно большой [1].
Список литературы
1. Дяченко О.Н. Компактное тестирование запоминающих устройств с локализацией пакетов ощибок // Электрон. моделирование.- 1996.- 18, №6.- С.43-48.
2. Дяченко О.Н. Теория информации и кодирования // Электронный конспект лекций.-2008.
3. Блейхут Р. Теория и практика кодов, контролирующих ошибки / Пер. с англ. - М.: Мир, 1986. - 576 с.
4. Юрьев И.В., Дяченко О.Н. Определение оптимальных параметров кодов Рида-Соломона // Інформатика та комп'ютерні технології / Матеріали V міжнародної науково-технічної конференції студентів, аспірантів та молодих науковців - 24-26 листопада 2009 р., Донецьк, ДонНТУ. - 2009. - С. 82-88.
5. Питерсон У., Уэлдон Э. Коды, исправляющие ошибки / Пер. с англ. - М.:Мир, 1976. - 575 с.
6. Касами Т., Токура Н., Ивадари Е., Инагаки Я. Теория кодирования / Пер. с яп. - М.: Мир, 1978.-576 с.
7. Dyachenko O.N. Memory Compact Testing with Error Burst Localization// Engineering Simulation.- 1997.- Vol.14.- pp.907-915. (0,63 др. арк.)
8. Дяченко О.Н. Аппаратная реализация и корректирующие возможности кодов Рида-Соломона// Наукові праці Донецького національного технічного університету. Серія "Проблеми моделювання та автоматизації проектування динамічних систем" (МАП-2007). Випуск: 6 (127) — Донецьк: ДонНТУ. — 2007. — С.113-121. [Электронный ресурс] — Режим доступа: http://www.nbuv.gov.ua/portal/natural/Npdntu/Pm/2007/07donrsc.pdf
9. Дяченко О.Н. Компактный анализ над полем GF(3) // Наукові праці Донецького національного технічного університету. Серія: Проблеми моделювання та автоматизації проектування динамічних систем (МАП-2002). Випуск: 52.- Донецьк: ДонНТУ.- 2002.-С.162-167. (0,38 др. арк.)
10. Юрьев И.В., Дяченко О.Н. Влияние параметров поля Галуа и перемежения на избыточность кода Рида-Соломона // Інформаційні управляючі системи та комп'ютерний моніторинг (ІУС та КМ-2010) / Матеріали I всеукраїнської науково-технічної конференції студентів, аспірантів та молодих вчених - 19-21 травня 2010 р., Донецьк, ДонНТУ. - 2010. - С. 164-168.
Примечание
При написании данного автореферата магистерская работа еще не завершена. Дата окончательного завершения работы: декабрь 2010 г. Полный текст работы и материалы по теме могут быть получены у автора или его научного руководителя после указанной даты.
| 


