
Реферат з теми випускної роботи
Структурно-алгоритмічна організація пристроїв генерації довільних дуг і секторів у 3D просторі для об'ємних дисплеїв
Вступ
Пристрої відображення інформації наразі є основними засобами спілкування та взаємодії людини і засобів обчислювальної техніки. За допомогою саме пристроїв відображення інформації після певної обробки дані надаються користувачеві. Алгоритми виводу і подання алфавітно-цифрової інформації є достатньо вивченою сферою знань. Відображення алфавітно-цифрових об'єктів є орієнтованим головним чином на підтримку мовної комутативності. У той же час основним способом доведення великих обсягів інформації до людини та її органів зору, що сприймають основний обсяг інформації, що обробляється людським мозком, є відображення даних у вигляді природніх і штучних графічних образів [1].
Розробка нових засобів побудови тривимірних пристроїв відображення [2] інформації, так званих «3D дисплеїв», дає поштовх новим дослідженням в області об'ємної візуалізації, що є спрямованими на створення алгоритмічної бази генерації, обробки виведення «вокселізованих» об'єктів і сцен. Слід зазначити, що в літературі [3] досить детально розглянуто питання створення воксельний моделей ("вокселізаціі") реальних об'єктів, наприклад, за допомогою тривимірних сканерів, у той час як методи та алгоритми генерації типових графічних примітивів не розглядаються.
Підвищення інформативності та поліпшення образотворчих можливостей візуального каналу обміну даними між комп'ютером і людиною призводить до створення тривимірних пристроїв відображення. Сучасна класифікація [2] 3D пристроїв візуалізації об'єктів та зображень виділяє як особливий клас системи, що є побудованими на базі об'ємних технологій. Такі пристрої дозволяють створювати віртуальне зображення об'єктів у тривимірному просторі. Ефект тривимірності вони забезпечують для множини точок спостереження, що є розташованими в широкому діапазоні.
Створення і використання такого роду пристроїв вимагає розробки спеціальних апаратних і програмних засобів. Особливістю пристроїв відображення на базі об'ємних технологій є наявність об'ємного воксельного запам'ятовуючого пристрою — аналога растрової пам'яті двовимірних пристроїв відображення. Під час генерації тривимірного зображення в воксельній пам'яті програмними засобами створюється «вокселізована» модель реальних об'єктів, що складається з сукупності тривимірних графічних примітивів: відрізків тривимірних прямих, тривимірних площин, дуг, кіл, сферичних трикутників, еліпсоїдів і т.п. [1]
Актуальність
З причини постійного збільшення потужності апаратної бази, призначеної для обробки та подання людині інформації, а також під час постійного збільшення інтересу до візуалізації тривимірних образів у просторі пристроїв відображення інформації, зростає і потреба розробки ефективних алгоритмів генерації графічних примітивів, на основі яких в подальшому будуть будуватися більш складні графічні об'єкти, їх композиції, а також відбуватиметься формування складних сцен, що відображаються в просторі пристрою відображення інформації.
У сфері комп'ютерної графіки розроблено достатню кількість методів, алгоритмів і підходів, що дозволяють прискорити процес відображення інформації на екрані дисплея. Алгоритми, що описують процес візуалізації є добре налагодженими і перевіреними продуктами. Але більшість наразі відомих алгоритмів та підходів є орієнтованими на вирішення проблем, що стосуються візуалізації в просторі досить звичних для середньостатистичного користувача пристроїв відображення інформації. Більш вузькою сферою є відображення графічних образів і елементів сцен за допомогою об'ємних дисплеїв. Поряд зі складністю розробки алгоритмів, що дозволяють якісно, з великою точністю і ефективно відтворювати образи в просторі 3D дисплеїв, перед розробником часто виникає проблема перевірки результатів розробленого алгоритму на тлі недоступності матеріальної бази через її дорожнечу й відсутності в достатній мірі перевірених і надійних апаратних рішень . Тому часто доводиться вдаватися до використання нетривіальних виходів із складної ситуації, пов'язаної зі складністю перевірки результатів роботи алгоритму: апаратною заміною об'ємного пристрою відображення інформації можуть виступати як вже готові програмні продукти, що відображають окрему частину тривимірного безперервного Евклідового простору (MatLab, MathCAD, SciDAVis, 3D-grapher), так і самотужки розроблені системи, що можуть замінити тривимірний пристрій візуалізації.
Поряд із проблемами, пов'язаними зі складністю перевірки результатів алгоритмів генерації графічних примітивів у просторі тривимірних дисплеїв, виникають проблеми налагодження програм, тому що математичний апарат, пов'язаний з тривимірною графікою, є досить складним інструментом у порівнянні з алгоритмами двовимірної графіки. Особлива увага приділяється оптимізації роботи алгоритмів тривимірної графіки з точки зору витраченого часу на розрахунок сцени, а також з точки зору апаратних витрат, що найчастіше є визначальним фактором під час вибору стратегії вирішення поставленого завдання.
Огляд досліджень
У глобальному сенсі дослідження застосування воксельної графіки не є новиною. У глобальній мережі Internet є значна кількість статей, в тексті яких автори розкривають ту чи іншу сферу застосування воксельної графіки, розглядають проблеми, що стоять на шляху впровадження воксельної графіки.
1. Вінсент Бретон у своїй статті розглядає застосування воксельної графіки в контексті побудови зображень, що допомагають лікарям робити своєчасну діагностику.
2. Забугорський Н. у своїх міркуваннях на тему воксельної графіки торкається аспекту створення комп'ютерних ігор на її базі.
3. Шаламов А.В. та Мазєїн П.Г. розглядають воксельну графіку як застосунок популярних CAD систем, за допомогою яких створюються і моделюються тривимірні моделі тіл.
Але спеціалізовані розробки, спрямовані саме на генерацію графічних примітивів [4, 5, 6] у просторі тривимірних дисплеїв, є в достатній мірі малодослідженою галуззю знань.
1. Башков Є.О., Авксентьєва О.О., Аль-Орайкат Анас Махмуд у своїй статті розглядають способи побудови графічних примітивів у просторі тривимірних дисплеїв.
2. Башков Є.О., Авксентьєва О.О., Аль-Орайкат Анас Махмуд, Хлопов Д.І. у своїй статті розглядають методи генерації відрізків прямих, а також методи прискорення генерації графічних примітивів.
3. Башков Є.О., Авксентьєва О.О., Аль-Орайкат Анас Махмуд, Дубровина О.Д. у своїй статті розглядають алгоритмічний базис побудови генераторів відрізків прямих для 3D дисплеїв.
Пошук на порталі магістрів дав кілька посилань на реферати студентів, магістерські роботи яких тим чи іншим чином зачіпають проблеми і методи, пов'язані з воксельної графікою.
1. Магістр Хромова Є.Н. розглядає проблему побудови сіткової моделі об'єктів складної форми за довільним набором точок для візуалізації та моделювання в тривимірному просторі.
2. Магістр Захаров С.С. розглядає проблему комп'ютерного моделювання природних явищ: візуалізації неба і хмар.
Цілі та завдання розробки й досліджень
Після того, як було прийнято рішення розробки оптимального, ефективного і в достатній мірі точного алгоритму генерації тривимірного сплайна в просторі 3D дисплея, виникло питання про те, якими методами керуватися під час його розробки, тестування і налагодження. Після того, як була визначена методична база [7] побудови функціональної сутності алгоритму, було прийнято рішення направити подальші дослідження в цій області за такими напрямками:
1. Розробка оптимального алгоритму генерації дуги як графічного примітиву в просторі тривимірного пристрою відображення інформації. Знаходження множини координат кожного вокселя, що бере участь у воксельному розкладанні заданого графічного примітиву.
2. Розробка критеріїв оцінки точності воксельного розкладання, витрат часу, а також критеріїв оптимізації отриманих показників.
3. Тестування отриманого алгоритму на критичні випадки за допомогою різної кількості запусків і поетапного порівняння показників.
4. Тестування алгоритму на різних архітектурах і платформах, а також подальше порівняння отриманих часових показників і характеристик, що вказують на точність воксельного розкладання.
5. Зробити висновок шодо доцільністі використання тієї чи іншої архітектури або платформи, обгрунтовуючи це рішення результатами, отриманими на попередніх етапах вирішення єдиного завдання.
6. Провести спробу побудови більш складного графічного примітиву на базі вже розробленого та налагодженого алгоритму генерації дуги в просторі тривимірного дисплея. Наприклад, знайти множину координат кожного вокселя, що бере участь в воксельному розкладанні кулі або еліпсоїда. На перших етапах розглядалися варіанти побудови геометричного об'єкта, що за формою нагадує «напівтрубу» з довільним кутом генерації дуги, що розповсюджується вздовж лінійної осі. На пізніх етапах дослідження були спрямовані на спробу створення воксельного розкладання частини поверхні кулі, що є заданою трьома точками, що знаходяться на її поверхні.
Заплановані практичні результати
У ході роботи над вирішенням поставленого завдання знаходження воксельного розкладання графічного примітиву планується одержати оптимальний метод вирішення подібних завдань. У кінцевому підсумку результатом магістерської роботи стане висновок, отриманий на основі аналізу програмної, програмно-апаратної і апаратної реалізації розроблюваного алгоритму, який вказує на архітектуру або платформу, що є найбільш зручною для вирішення завдань, пов'язаних з генерацією графічних примітивів у просторі тривимірних пристроїв відображення інформації.
Передбачувана наукова новизна
У ході роботи були досліджені і протестовані методи генерації графічного примітиву (дуги) у просторі тривимірного дисплея, знаходження множини координат усіх вокселів, що беруть участь в воксельному розкладанні даного графічного примітиву. Також були запропоновані методи оптимізації розробленого алгоритму з точки зору програмних поліпшень, що вносяться безпосередньо в код програми, та з точки зору програмно-апаратних рішень, що грунтувалися на застосуванні архітектури CUDA, що використовує графічний процесор і ядра GPU як обчислювальний ресурс. Поряд з програмними та програмно-апаратними підходами до оптимізації алгоритмічної реалізації запропонованого вирішення єдиного завдання було застосовано апаратний підхід, що грунтується на завантаженні алгоритму в FPGA. Усі ці фактори зумовили всебічне дослідження розробленого алгоритму з точки зору можливих шляхів оптимізації.
Експериментальна база
1. До програмних удосконалень розробленого алгоритму належать безпосередні зміни, що вносяться в код програми, яка генерує координати всієї множини вокселів, що беруть участь у воксельному розкладанні тривимірного сплайна в просторі 3D дисплея. Експерименти і виміри, які полягають в багаторазових запусках програми на виконання, і подальший аналіз отриманих часових показників і характеристик, що вказують на точність воксельного розкладання, проводилися на базі комп'ютера, що має наступні характеристики: Intel (R) Celeron CPU 2.3GHz, 1 Гб ОЗУ.
2. До програмно-апаратних поліпшень, що вносяться до структури алгоритму, належать його тестування на базі архітектури CUDA. Під час застосування архітектури CUDA малося на увазі використання графічного процесора як основи для ресурсоємних обчислень. У код програми вносилися зміни, що в першу чергу стосувалися тих блоків коду, виконання яких було можливо реалізувати паралельно, використовуючи апаратні ресурси, що надають значний потенціал розпаралелювання програми, що запускається. Експерименти, спрямовані на розпаралелювання виконання програми, проводилися на базі комп'ютера, що має наступні характеристики: Intel (R) Core (TM) 2 Duo CPU E4600 2.40GHz, 2.40ГГц, 1,99 ГБ ОЗП.
3. Апаратна реалізація алгоритму здійснювалася на основі FPGA фірми Xilinx [8, 9] шляхом завантаження розробленого алгоритму на плату. У ході роботи було проведено цикли контрольних запусків і підраховані часові показники і характеристики, що стосуються точності генерації тривимірного сплайна в просторі об'ємного дисплея. Таким чином було здійснено спробу створення спеціалізованого пристрою, спрямованого на вирішення конкретного завдання — воксельного розкладання графічного примітиву.
Рисунок 1 пояснює етапи розробки та тестування алгоритму генерації дуги в просторі 3D дисплея.

Рисунок 1 — Етапи дослідження розробленого алгоритму генерації графічного примітиву в просторі тривимірного дисплея.
5 кадрів. Затримка після останнього кадру = 2 сек. Затримка після інших кадрів = 1 сек.
Розмір анімації: 382px х 240px. Розмір файлу: 33.3 Kbytes. Створено за допомогою Adobe ImageReady.
Огляд базового алгоритму
Під час розробки концепції алгоритму генерації тривимірного сплайна (дуги, заданої довільними початковими даними) у просторі 3D дисплея було розглянуто такі двовимірні алгоритми генерації графічних примітивів:
1. Алгоритм цифрового диференційного аналізатора (DDA — Digital Differential Analyzer).
2. Двовимірний алгоритм Брезенхема, що стосується генерації кола та прямої (Bresenham's algorithm).
3. Тривимірний алгоритм Брезенхема, що стосується генерації прямої.
Після вивчення та аналізу вже існуючої алгоритмічної бази було прийнято рішення створити алгоритм, що враховує переваги і ліквідує слабкі місця вищевикладених підходів. Завдання растрового розкладання дуги формулюється як завдання визначення множини вокселів, що знаходяться в просторі 3D дисплея, до якого належать початковий і кінцевий вокселі генерації, кожен з яких (крім початкового і кінцевого) має два і тільки два сусідніх вокселі, центр кожного з яких лежить на мінімальній відстані від дуги та їх кількість у множині є мінімальною. Оскільки класичний двовимірний алгоритм Брезенхема використовує тільки цілочисельну арифметику, виключаючи обчислення, пов'язані зі значеннями, представленими у форматі з плаваючою комою, кількість обчислень в алгоритмі, пов'язаних із дробовою арифметикою, було мінімізовано настільки, наскільки це виявилося можливим. Повне виключення комплексних обчислень, пов'язаних зі значними витратами процесорного ресурсу, виявилося неможливим, тому що тривимірний випадок вирішення завдання генерації сплайна пов'язаний з підрахунком значної кількості значень і коефіцієнтів, наведених у форматі з плаваючою комою. Основна ідея алгоритму полягає в тому, що в функцію, яка є точкою входу до алгоритму, надходять значення, що задають точку центру дуги, початкову точку дуги, точку що лежить на площині генерації, яка в свою чергу забезпечує однозначність вирішення єдиного завдання і визначає площину генерації, а також значення кута генерації дуги. Етапи роботи алгоритму можна описати наступним чином:
1. Отримання і обробка початкових даних. Визначення коефіцієнтів рівняння площини, на якій буде вестися процес генерації [10]. Перехід від значень, які задають точки безперервного тривимірного простору, до значень, що позначають координати точок у дискретному просторі, частина якого відображається тривимірним дисплеєм.
2. Знаходження кінцевої точки генерації за допомогою матриці повороту.
3. Циклічне послідовне обчислення координат вокселів, що входять до воксельного розкладання дуги. Для кожного вокселя, визначеного на попередньому етапі, існує 7 вокселів-претендентів, кожен з яких може стати наступним у воксельному розкладанні. Для кожного з семи вокселів-претендентів проводиться обчислення двох кількісних показників, подальша обробка яких показує, який з вокселів-претендентів стане наступним у воксельному розкладанні.
4. На кожній ітерації алгоритму відбувається підрахунок не тільки кількісних значень, які вказують на те, який з вокселів-претендентів стане наступним у воксельному розкладанні, але й якісних показників, що вказують на точність і швидкість роботи алгоритму. Надалі кожен з якісних показників буде оцінено й проаналізовано.
Запропонований модифікований алгоритм воксельного розкладання дуги в тривимірному просторі, з урахуванням вищевикладеного, може бути записаний псевдомовою з [11] наступним чином.
Алгоритм воксельного розкладання дуги
Вхідні дані: N початкова точка дуги, C центральна точка дуги, P точка на площині, α кут дуги.
Вихідні дані: масив вокселів V
Begin
Input C, P, N, α; Визначення VC, VP, VN Обчислення координат векторів CP і CN Обчислення координат вектора нормалі n до площини Обчислення радіуса дуги Обчислення координат точки K Repeat Обчислення координат вектора дотичної k Заповнення матриці пріоритетів M Do k = 1,2 … 7 V(k)<q+1>:= VN + M(k) +0.5 Обчислення похибки E1(k)<q+1> Обчислення похибки E2(k)<q+1> End Do
MIN = MIN(E1(k)<q+1> + E2(k)<q+1>))
Do k = 1,2 … 7
If (E1(k)<q+1> = MIN)
If (Пріоритет є максимальним)
Vpoints:= VN + M(k)
points:= points + 1
End if
End if
End Do
Until VN<>VK
Output V
End
Після того, як було отримано і налагоджено модифіковану версію алгоритму, програма, що реалізує цей алгоритм, пройшла процедуру багаторазових випробувальних запусків. Кількість таких запусків варіювалася від 10 до 10 000. Ініціалізація початкових значень проводилася за допомогою генератора псевдовипадкових чисел, не виключаючи критичних значень, обробку яких було передбачено і враховано під час розробки програми. Результат чергової 1000 запусків наведено нижче:
Кількість згенерованих дуг = 1000 Кількість точок = 1949224 Сумарна E1 = 435864.58976 Сумарна E2 = 433187.11029 Сумарна E3 = 696534.57655 ============================================================== Середня похибка радіуса (E1av) = 0.22361 Середня похибка відстані до площини дуги (E2av) = 0.22224 Середня похибка відстані до функції (E3av) = 0.35734 ============================================================== MAX похибка радіуса (E1max) = 0.84506 MAX похибка відстані до площини дуги (E2max) = 0.84604 MAX похибка відстані до функції (E3max) = 0.86601 ============================================================== MIN похибка радіуса (E1min) = 0.00010 MIN похибка відстані до площини дуги (E2min) = 0.00000 MIN похибка відстані до функції (E3min) = 0.00016 Час генерації 1000 дуг = 20593 мс
Результат роботи програми наведено нижче. Координати вокселів, отримані під час виконання програми, записуються до текстового файлу, що має спеціальну структуру. Після побудови цього файлу, що містить координати усіх вокселів, що входять до воксельного розкладання тривимірного сплайна в просторі тривимірного дисплея, його можна обробляти за допомогою будь-якого тривимірного візуалізатора. Як середовище візуалізації, що моделює частину Евклідового простору, відображуваного тривимірним дисплеєм, було обрано програмний пакет MatLab версії 7.01.
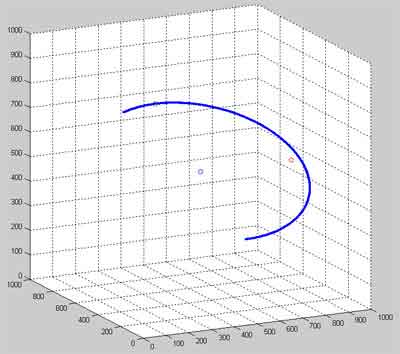
Рисунок 2 — Результат візуалізації воксельного розкладання дуги, що є заданою довільними параметрами в просторі тривимірного дисплея
(cередовище візуалізації — програмний пакет MatLab 7.01)
Подальша модифікація алгоритму. Застосування технології CUDA
«CUDA (англ. Compute Unified Device Architecture) — програмно-апаратна архітектура, що дозволяє робити обчислення за допомогою графічних процесорів NVIDIA, що підтримують технологію GPGPU (довільних обчислень на відеокартах). Архітектура CUDA вперше з'явилася на ринку після виходу NVIDIA восьмого покоління — G80 і присутня у всіх наступних серіях графічних процесорів, які використовуються в родинах прискорювачів GeForce, Quadro і Tesla.
CUDA SDK дозволяє програмістам реалізовувати на спеціальному спрощеному діалекті мови програмування С алгоритми, що можна виконати на графічних процесорах NVIDIA, і включати спеціальні функції в текст програми на C. CUDA дає розробникові можливість на свій розсуд організовувати доступ до набору інструкцій графічного прискорювача і управляти його пам'яттю, організовувати складні паралельні обчислення.» [12]
Під час програмно-апаратної оптимізації розробленого алгоритму архітектура CUDA використовувалася як обчислювальне середовище, що дозволяє виконувати паралельно деякі фрагменти програми [13]. За рахунок того, що програму на мові С можна за нетривалий проміжок часу оптимізувати та реструктурувати відповідно до вимог, що висуваються CUDA до програм, що виконуються на GPU, алгоритм з часом був успішно «перекладений» на специфічний діалект мови С, написання програм на якому є обов'язковою вимогою з боку архітектури [14, 15]. Але крім складнощів, що виникли під час перекладу програми, що реалізує алгоритм воксельного розкладання графічного примітиву, на шляху подальшої оптимізації стали проблеми пошуку блоків алгоритму, які можна було реалізувати паралельно [16, 17]. Такі блоки були знайдені і реалізовані таким чином, щоб мінімізувати кількість циклів, виконуваних у програмі.
Особливу складність, яка виникає перед програмістом, що створює програму на мові С, оптимізовану відповідно до вимог, що висуваються з боку архітектури CUDA, становить налагодження програми. Ця складність багато в чому тісно пов'язана з тим, що переглянути вміст змінних неможливо за допомогою стандартних механізмів Debugger-а Microsoft Visual Studio, тому що всі параметри, що передаються в CUDA-функцію, є недоступними через їх розташування у внутрішній пам'яті GPU. Стандартним підходом у такому випадку (під час написання найпростіших програм-тестів) є виведення вмісту змінних в консоль або у файл. Таким методом користуються в тих випадках, коли стандартні методи налагодження є недоступними. Але і цей підхід неможливо реалізувати в умовах обчислень на графічних процесорах, тому що CUDA-функція не має доступу до стандартних потоків виводу, що означає неможливість використання ані консолі, ані файлів. Ще одним методом, доступним під час розробки програми для CUDA, є поетапне копіювання результатів, оброблених GPU, з внутрішньої пам'яті графічного процесора в основну пам'ять комп'ютера. Цей метод вимагає додаткової адаптації програми та написання додаткового програмного коду. Особливістю використання такого методу є значні часові витрати, спрямовані на резервування пам'яті під змінні як на CPU, так і на GPU. Але резервування пам'яті впливає на час виконання програми не настільки критичним чином, наскільки постійне копіювання результатів роботи CUDA-функції в просторі пам'яті GPU. Оскільки однією з вимог до ефективної роботи програм, створених для виконання та тестування на графічних процесорах, є мінімізація копіювання даних між CPU і GPU (пам'ять GPU обмежена, тому варто звернути особливу увагу на копіювання та обробку великих обсягів інформації), від застосування вищеописаного методу довелося відмовитися .
Рисунок 3 — Nexus Debug Environment
Оскільки під час досліджень було потрібно розробити досить нетривіальну програму, тому довелося шукати методи вирішення проблеми налагодження. Це питання було вирішено за допомогою технології Nexus. Із появою технології, що дозволяє за допомогою інтеграції до Microsoft Visual Studio ефективно налагоджувати програми, процес розробки застосунків для графічних процесорів значно прискорився. Згідно з [18, 19] основними можливостями, наданими розробнику програм, що виконуються на GPU, з боку технології Nexus є:
Ще одним важливим завданням, яке було необхідно вирішити, став пошук методу підрахунку часу, що витрачається на виконання програми під час випробувальних циклів запуску. Стандартні методи, що підтримуються Microsoft Visual Studio (наприклад, застосування функції getTickCount () на початку програми, а потім в її кінці з подальшим підрахунком різниці цих значень) не можуть бути застосовані, тому що на практиці було з'ясовано, що застосування такого методу дає неправильний результат. Вихід із ситуації було знайдено. Застосування саме стандартних засобів, що підтримуються архітектурою CUDA, стало найбільш зручним і точним методом підрахунку часу роботи програми. Таким засобом став Compute Visual Profiler. Значення, подані в таблиці 1 отримані саме за допомогою Compute Visual Profiler.
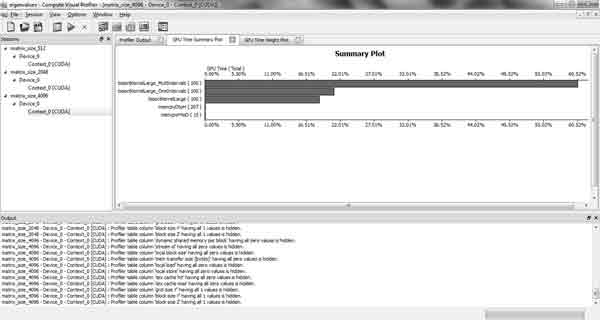
Рисунок 4 — CUDA Compute Visual Profiler
Результати, показані архітектурою CUDA перевершили всі очікування. У міру збільшення кількості пробних циклів запуску ступінь розпаралелювання алгоритму програми збільшувалася. У залежності від кількості пробних запусків прискорення, що показується GPU в порівнянні з CPU, склало від 4.5 до 8.7 разів. Такі результати були цілком передбачувані, оскільки ступінь розпаралелювання дорівнювала кількості вокселів-претендентів на потрапляння до воксельного розкладання. Таким чином, підрахунок всіх характеристик, властивих кожному вокселю-претенденту, відбувався паралельно.
Таблиця 1 — Порівняльні характеристики часових витрат під час виконання програми на CPU і GPU
| Кількість запусків | CPU (мс) | GPU (мс) | Співвідношення часу виконання на GPU та часу виконання на CPU |
| 128 | 328 | 73,559 | 4,459005696 |
| 512 | 1297 | 187,437 | 6,919658339 |
| 1024 | 2641 | 359,803 | 7,340127792 |
| 4096 | 10172 | 1254,01 | 8,111578058 |
| 10240 | 25547 | 2990,54 | 8,542604346 |
| 16384 | 41672 | 4785,61 | 8,707771841 |
Перехід від CUDA до FPGA
«Є просте інженерне правило — спеціалізовані пристрої для застосування в конкретній сфері є завжди кращими за універсальних. Воно залишається справедливим незалежно від будь-яких технічних хитрощів, адже, насправді, визначає і мету проектного процесу, і його наслідок, результат. Іншими словами, пристрій проектують спеціалізованим саме для того, щоб він в чомусь був краще універсальних». [10]
Саме ця фраза стала девізом проведених досліджень на час розробки алгоритмічної реалізації воксельного розкладання дуги, заданої довільними параметрами, в просторі тривимірного дисплея. Спробу протестувати розроблений алгоритм на FPGA було зроблено не тільки для того, щоб охопити всі області його оптимізації. Саме бажання виявити найкращий спосіб вирішення завдань, подібних до головного завдання, стало причиною переходу від програмної та програмно-апаратної реалізації алгоритму до суто апаратної його оптимізації.

Рисунок 5 — FPGA Spartan-3E фірми Xilinx
Головними цілями прошивки FPGA відповідно до алгоритму генерації графічного примітиву були:
1. Завантаження початкових довільних даних у FPGA за допомогою інтерфейсу.
2. Багаторазове тестування алгоритму з метою виявлення помилок.
3. Випробувальне тестування алгоритму на FPGA з подальшим виведенням результатів.
4. Аналіз часових характеристик і показників, що вказують на точність воксельного розкладання.
Результати
На момент написання магістерської роботи дослідження, проведені в її рамках, носили не тільки суто теоретичний характер, але й були підтверджені на програмному, програмно-апаратному, а також апаратному рівнях. Розроблений під час виконання магістерської роботи алгоритм пройшов усі стадії:
1. Формулювання єдиного завдання.
2. Дослідження накопиченого досвіду в цій сфері комп'ютерної графіки.
3. Аналіз алгоритмічної основи, що стала базисом для розробленого алгоритму.
4. Вироблення критеріїв оцінки якісних показників алгоритму.
5. Оптимізація розробленого алгоритму з точки зору мінімізації комплексних обчислень, пов'язаних з обчисленнями величин, представлених у форматі з плаваючою комою. Тестування алгоритму, виміри часових характеристик і ознак, що вказують на точність генерації графічного примітиву.
6. Модернізація та оптимізація алгоритму відповідно до вимог, що висуваються до програм з боку платформи CUDA. Перевірка працездатності алгоритму на GPU компанії nVidia з підтримкою технології CUDA. Аналіз отриманих часових характеристик, а також показників, що вказують на точність виконання алгоритму.
7. Створення модифікації алгоритму для подальшої прошивки FPGA та аналізу результатів, отриманих під час роботи з апаратною реалізацією алгоритму.
Висновок
Досвід роботи з розробленим алгоритмом на різних рівнях реалізації показав, що будь-яка ідея може бути реалізована різними способами. Кожна ідея може пройти шлях від концепції до конкретного впровадження і практичної реалізації. Алгоритм, на перших стадіях реалізований суто в формі програми, може пройти багаторазові модифікації, поліпшення і вдосконалення.
Література
1. Башков Є.О., Авксентьєва О.О., Аль-Орайкат Анас М. До побудови генератора графічних примітивів для тривимірних дисплеїв [Текст]. У сб. Наукові праці Донецького національного технічного університету, серія «Проблеми моделювання та автоматизації проектування динамічних систем». Вип. 7 (150). - Донецьк, ДонНТУ. - 2008 .- ст. 203-214
2. Favalora G.E., Volumetric 3D Displays and Application Infrastructure [Текст] // "Computer", 2005, August, pp 37- 44.
3. Роджерс Д. Алгоритмічні основи машинної графіки [Текст]. — Пер. з англ. — Москва.: «Світ», 1989. — 512 с.
4. Башков Є.О., Авксентьєва О.О., Аль-Орайкат Анас М., Хлопов Д.І. Генератор відрізків прямих підвищеної продуктивності для тривимірних дисплеів [Електронний ресурс]
http://www.nbuv.gov.ua/portal/natural/Npdntu_ikot/2010_11/3_1.pdf
5. Мілютін М.О., Башков Є.О., Авксентьєва О.О. Аль-Орайкат А. Алгоритм генерації дуги для 3-D дисплеїв [Текст]. Донецьк, ДонНТУ. - 2009.
6. Авксентьєва О.О., Аль-Орайкат Анас М., Хлопов Д.І. Покращений алгоритм генерації прямої для 3D – дисплеїв [Текст]. Матеріали 14 – 10 міжнародного молодіжного форуму «Радіоелектроніка і молодь у XXI столітті», 18 - 20 березня 2010 р., Харків 2010, сб. матеріалів 4.1. – Харків: ХНУРЕ. 2010. – 527с.
7. Дружинін А.І., Віхман В.В. Алгоритми комп'ютерної графіки [Текст]. Учб. посібник. – Новосибірськ: Вид-во НГТУ, 2003. – 47 с.
8. Spartan-3E FPGA Family: Data Sheet [Електронний ресурс]
http://www.xilinx.com/support/documentation/data_sheets/ds312.pdf
9. Spartan-3E Starter Kit Board User Guide [Електронний ресурс]
http://www.digilentinc.com/Data/Products/S3EBOARD/S3EStarter_ug230.pdf
10. Бєклємішев Д.В. Курс аналітичної геометрії і лінійної алгебри [Текст]. М.: Наука, 1980.
11. Препарата Ф., Шеймос М. Обчислювальна геометрія: Вступ [Текст]. - Пер. з англ. – М.: Світ, 1989. 478 с.
12. Стаття в Wikipedia, присвячена CUDA [Електронний ресурс]
13. Андрій Зубінський. NVIDIA Cuda: уніфікація графіки і обчислень [Електронний ресурс]
14. Antonio Tumeo. Politecnico di Milano. Massively Parallel Computing with CUDA [Електронний ресурс]
http://www.ogf.org/OGF25/materials/1605/CUDA_Programming.pdf
15. Nvidia CUDA Development Tools. Getting started [Електронний ресурс]
http://www2.engr.arizona.edu/~ece569a/Readings/NVIDIA_Resources/QuickStart%20Guide.pdf
16. Nvidia CUDA Programming Guide [Електронний ресурс]
http://developer.download.nvidia.com/compute/cuda/3_0/toolkit/docs/NVIDIA_CUDA_ProgrammingGuide.pdf
17. Nvidia CUDA Reference Manual [Електронний ресурс]
http://developer.download.nvidia.com/compute/cuda/2_3/toolkit/docs/CUDA_Reference_Manual_2.3.pdf
18. dimson3d. Знайомство з NVIDIA CUDA, паралельні обчислення за допомогою GPU в CG [Електронний ресурс]
http://www.render.ru/books/show_book.php?book_id=840&start=1
19. Nvidia Corporation. CUDA: нова архітектура для обчислень за допомогою GPU [Електронний ресурс]
http://www.nvidia.ru/content/cudazone/download/ru/CUDA_for_games.pdf