
Реферат по теме выпускной работы
Содержание
- Цели и задачи
- Актуальность темы
- Предполагаемая научная новизна
- Планируемые практические результаты
- Обзор исследований и разработок по теме. Глобальный уровень
- Обзор исследований и разработок по теме. Национальный уровень
- Обзор исследований и разработок по теме. Локальный уровень
- Краткое изложение собственных результатов
- Выводы
- Список источников
Цели и задачи
Основной целью данной
магистерской работы является разработка семантической модели
распознавания
естественно-языковых предложений в системах тестирования.
Для выполнения поставленной цели выделены
следующие
задачи:
- изучение семантического анализа
естественно-языкового текста;
- анализ существующих семантических моделей;
- анализ принципов естественно-языкового
общения в
системах тестирования;
- разработка компонентной модели вопросов и
ответов;
- разработка алгоритмов и программного
обеспечения для
системы тестирования знаний в заданной предметной области;
- проведение опытной проверки полученных
результатов
Актуальность темы исследования
В конце 60-х годов
в исследованиях по искусственному интеллекту сформировалось
самостоятельное
направление, получившее название «обработка естественного
языка» (Natural Language
Processing) [1].
Задачей данного направления является исследование
методов и разработка систем, обеспечивающих реализацию процесса общения
с
компьютерными системами на естественном языке (систем ЕЯ – общения или
ЕЯ-систем).
Проблема взаимодействия человека с
компьютером
существует с момента появления вычислительной техники. На начальном
этапе
непосредственное взаимодействие с ЭВМ осуществляли только программисты,
а
специалисты других областей – потребители
результатов, полученных на
компьютере, выступали в роли косвенных конечных пользователей, т. е.
общались с
компьютером через программистов [2]. По мере
расширения сферы использования компьютера
и увеличения масштабов их применения конечные пользователи стали
вовлекаться в процесс
непосредственного взаимодействия с компьютером, что привело к появлению
массовой
категории пользователей – прямых
конечных пользователей, работающих в диалоговом
режиме.
Сложность создания средств общения,
предназначенных
для конечных пользователей, обусловлена в значительной степени
отсутствием единой
теории языкового общения, охватывающей все аспекты взаимодействия коммуникантов. Поэтому при разработке средств
общения конечных
пользователей на процесс взаимодействия часто налагаются различные
«
спонтанные» ограничения, последствия которых не до конца
осознаются
разработчиками. Эти ограничения приводят к тому, что многие
человеко-машинные
системы, на разработку которых тратятся огромные средства, не
удовлетворяют
требованиям конечных пользователей.
Естественно-языковые системы используются для
поиска в
текстах, распознавания речи, голосового управления и обработки данных.
Примечательно, что функция поиска в тексте
может быть
использована в довольно широкой области.
Одной из сфер применения являются системы
тестирования. Подобные системы применяются в
дистанционном
обучении, перекладывая обязанность проверки ответов на тесны на ЭВМ.
Однако следует заметить, что развитие подобных систем наблюдается лишь
в сфере
тестовых заданий, где уже определены готовые ответы. Средства
естественно-языкового
поиска в текстах способна осуществлять по
запросам пользователей
поиск, фильтрацию и сканирование текстовой информации. При этом
средства данной
категории осуществляют поиск в неструктурированных текстах, оформленных
в
соответствии с правилами грамматики того или иного естественного языка.
Другими словами, применение системы анализа
естественного языка в системах тестирования позволило бы пользователю
вводить
свой ответ, а не выбирать один из предложенных, имея возможность
угадать
правильный. Прямой ввод текста предоставил бы более точное оценивание
знаний,
при этом позволял бы пользователю более гибко отвечать на вопросы
– в мерах
своего понимания. Дальность ответа от его истинного значения и
определяет его
правильность. А потому применение систем естественно-языкового анализа
текста
имеет прямое практическое применение в этой области.
Предполагаемая
научная новизна
Предполагается, что данная магистерская
работа позволит
расширить существующие модели семантического анализа, увеличив их
гибкость и
восприимчивость в пределах некоторой предметной области.
Планируемые практические результаты
В качестве
основных планируемых результатов предполагается достижение поставленной
цели:
разработка алгоритма новой семантической модели распознавания
естественно-языковых выражений, которая может быть использована в
системах
тестирования знаний.
Другими словами, предполагается создание
алгоритма,
позволяющего осуществлять не прямой поиск смысла в тексте. Кроме того,
алгоритм
должен обеспечивать сравнение шаблона с найденными результатами для
определения
степени соответствия. Степень соответствия, в данном случае, может
играть роль
оценки знаний.
Обзор
исследований и разработок по теме. Глобальный уровень
На данный момент разработано множество
моделей лингвистического
анализатора, которые способны в той или иной степени выполнять анализ
естественно-языкового
текста, определять смысл и генерировать высказывания. При этом подходы
к моделированию
процесса общения весьма разнообразны. Основные отличия этих подходов
заключаются
в методах реализации компонента понимания смысла, используемых
средствах анализа,
а также в объеме и способах представления знаний, поскольку именно
знания,
представленные в различной форме, являются базой, от которой зависит
процесс общения,
глубина проникновения в смысл и, соответственно, качество самой модели
лингвистического
анализатора. От выполнения отдельных функциональных компонент зависит
практическая
реализация моделей в различных системах общения (системы общения с
базами данных,
системы машинного перевода и др.). Некоторые из них легли в основу
конкретных
систем формирования семантического представления на основе обработки
текстов (например,
модель Смысл-текст в системе «Поэт»).
Проанализируем наиболее проработанные модели
лингвистического
процессора с точки зрения реализации анализа и интерпретации входного
высказывания
и синтеза выходного высказывания.
В задачу анализа входит выделение смысла
входного текста
(под смыслом будем понимать семантику – информацию, которую
пользователь хотел передать
системе) и выражения этого смысла на внутреннем языке системы.
Интерпретация заключается
в отображении входного текста на знания системы. Одним из основных
параметров анализа
текста является понимание смысла входного предложения, включающее в
себя описание
сущностей входного текста, определение их свойств и отношений между
ними. От этого
параметра часто зависит глубина проникновения в смысл входного текста.
В существующих моделях лингвистического
анализатора можно
выделить следующие способы выделения и представления смысла:
компонентный анализ;
сеть концептуализаций; идентификация
смысла по
образцу; интегральный подход (см. рис. 1).
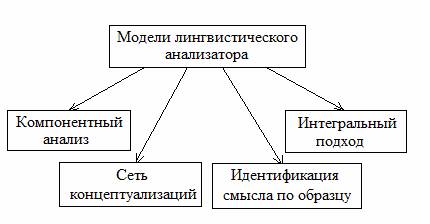
Рисунок 1 – Виды
лингвистических моделей.
Модель компонентного анализа
Одна из первых попыток формализации входного
текста
принадлежит компонентному анализу, который исходит из предпосылки, что
семантика естественных языков может быть выражена в терминах конечного
неструктурированного
набора семантических множителей (атомов смысла). В процессе
рассмотрения слов выделяются
признаки (одушевленность, неодушевленность и т.п.), которые разбивают
слова на
отдельные группы. При кажущейся естественности данный метод связан с
существенными
трудностями при реализации и не лишен слабостей. Он становится сложным
при выражении
смысла целого предложения и громоздким при анализе многозначных слов,
при этом
нет достаточного объяснения слова, что может привести к неправильному
его
употреблению.
В дальнейшем идея описания входного текста с
помощью компонентного
анализа нашла свое продолжение в модели «Семантические падежи
(роли)» Ч. Филмора [3].
Но в отличие от предыдущей модели в предикатах
указывается не только аргументная
структура и количество,
но и их семантическое содержание (роли). Филмор выделяет
следующие семантические роли: агент, контрагент, объект, адресат,
пациенс, результат, инструмент, источник.
В
модели предложена более детальная концепция смысла высказывания. Каждое
понятие
расщепляется на две сущности: значение и пресуппозицию.
Различия между пресуппозицией и значением
в собственном
смысле слова проявляются, например, в различном влиянии на них
отрицания. В область
действия отрицания попадает только значение, а не пресуппозиция.
В результате исследований была разработана классификация семантических
элементов,
что привело к пересмотру обычной схемы словарной статьи в толковом
словаре
(словарь стал основным средством задания семантических структур и
правил их
перевода в поверхностные структуры).
Продолжением данной теории явился методы
падежной
грамматики других исследователей. При этом для записи содержания
входного
высказывания используются специальный синтаксический язык, словари и
правила, устанавливающие
соответствие между естественно-языковыми выражениями и их семантическим
представлением.
Модель сети концептуализаций
Ко второму классу относятся модели, в которых
смысл
текста представляется в виде сети концептуализаций.
В
таких моделях явления рассматриваются только на одном уровне
детальности, что не
позволяет описывать сложные события в терминах более простых подсобытий, и дробить при необходимости
примитивные
действия (атомы). Чаще всего эти модели являются моделью языка, а не
моделью общения,
что приводит к нечеткому выделению языковых средств и средств
для описания моделируемого окружения. Среди моделей данного
класса наибольший
интерес представляет модель « Концептуальной зависимости».
Основой семантического представления модели
«Концептуальной зависимости» (Р. Шенк
[4]) является
сеть концептуализаций. Сеть концептуализаций
есть квазиграф, подобный размеченному
ориентированному
графу, в котором, кроме бинарных отношений, есть тернарные и кварнарные, а дуги связывают не только вершины,
но и другие
дуги.
Концептуализация в модели концептуальной
зависимости определяется
как основная единица семантического уровня, из таких единиц
конструируются мысли.
Концептуализация включает в себя действие, множество его концептуальных
падежей
и участников действия (их состояний).
Будучи моделью языка, она не учитывает модели
пользователя,
что приводит к полному перебору при построении умозаключений. Наличие
модели
пользователя позволило бы определить его цели (намерения) в диалоге и
использовать
их для направления процедуры построения умозаключений.
Модель идентификации смысла
Другая модель –
«Семантик предпочтения» относится к
классу моделей, идентификация смысла в которых осуществляется по
образцам. Отличительной
чертой таких моделей является то, что в них отсутствуют блоки
морфологического и
синтаксического анализов, что является принципиальным их недостатком,
так как не
обеспечивается глубина анализа значений слов, необходимая для точного
установления семантической связности текста.
В этой модели (Уилкс) текст характеризуется
следующими
сущностями: смыслами слов, сообщениями, фрагментами текста и
семантической совместимостью.
Сообщение рассматривается как теоретический конструкт, посредством
которого для
каждого слова, входящего во фрагмент текста, может быть выбран один из
смыслов
слова, посредством чего снимается многозначность. Слову назначается тот
из его
многих смыслов, который образует «сообщение»,
согласующееся, в конце концов, с
рассматриваемым фрагментом текста. Если слово может подойти к
нескольким
сообщениям, то выбирается такое, которое согласуется с рассматриваемым
текстом.
Анализ фрагмента текста протекает по
следующей схеме. С
помощью специальных слов-маркеров выполняется фрагментация текста,
затем словам
приписывают из словаря все их значения. Далее на анализируемый фрагмент
текста
поочередно накладываются простые шаблоны, известные системе. С помощью
специальных правил расширения простой образец преобразуется в полный
образец путем
добавления слов из текста, которые не вошли в образец. Указанная
процедура
осложнена тем, что может подойти не один простой образец. Используя
процедуры установления
семантической близости полученных образцов, формируется окончательное
представление обрабатываемого текста. К недостаткам анализа следует
отнести то,
что анализ текста осуществляется с помощью словаря шаблонов, которые
способны
различать только класс событий, а не сами конкретные события.
Другой подход к способу анализа по образцу
представлен
в моделях, использующих табличный метод. Он основан на анализе ключевых
слов,
встречающихся в предложениях. Суть табличного метода состоит в
идентификации
смысла всего предложения на основании нескольких ключевых слов или их
групп.
После процесса идентификации слова предложения заменяются
на
их каноническую форму – коды.
Замена осуществляется с помощью словаря
словоформ. При этом также выделяются некоторые группы слов, несущие
тематическую
нагрузку. Далее производится распознавание и замена стандартных
словосочетаний.
Данный метод обладает рядом недостатков, преимуществом является его
простота
для однозначных естественно-языковых предложений, в которых не
требуется полного
понимания смысла предложения (например, запросы к базе данных).
Модель интегрального подхода
Модели, в которых достаточно глубоко
продуманы процедуры
морфологического, синтаксического и проблемного анализов, можно отнести
к моделям,
основанным на интегральном подходе описания языка. Это модель
«Смысл-текст» и
модель контекстного фрагментирования.
Модель «Смысл-текст» (И.А.
Мельчук) представляет собой
многоуровневый транслятор текстов в смыслы и наоборот. Выделяются
четыре основных
уровня – фонетический, морфологический, синтаксический и
проблемный. Каждый из них,
за исключением проблемного, подразделяется на два других уровня –
поверхностный
и глубинный.
Данная модель может быть применима в
системах, где
необходимо понимание текста в полном смысле (например,
вопросно-ответные
системы, системы принятия решений). Но для реализации полной схемы
анализа и синтеза
модели « Смысл-текст» придется учесть индивидуальные
свойства сотен тысяч
словарных, морфологических и лексических единиц и индивидуальные
свойства громадного
числа пар единиц. Их полное формальное описание представляет собой
громадную и объемную
теоретическую работу, поставленную в лингвистике в последнее время и
еще
далекую от решения.
Модель контекстного фрагментирования
разрабатывалась для анализа и синтеза естественно-языкового
предложения, но ее
проработка касается в основном анализа. Задача лингвистической
трансляции естественно-языкового
текста рассматривается отдельно от других задач общения на естественном
языке и
от задач самой вычислительной системы. Анализ и трансляция текста
осуществляются
при наличии достаточно мощных средств описания и фрагментации
лингвистических знаний.
Основу модели контекстного фрагментирования
составляет трехуровневая система: лингвистическая модель, базовые
механизмы
обработки предложений и ассоциированные процедуры. Лингвистическая
модель
содержит информацию о морфологии, синтаксисе и семантике подмножества
естественного языка. В модели выполняется очень глубокий синтаксический
анализ
с одновременным преобразованием распознаваемых синтаксических отношений
в семантические. Достоинством данного метода
является то, что
существует возможность динамически изменять стратегию обработки
естественно-языкового текста в зависимости от необходимой глубины и
последовательности этапов трансляции и расширять метод при включении
новых
конструкций естественного языка и редуцировать его для упрощенных
подмножеств
естественного языка и проблемных областей.
Обзор
исследований и разработок по теме. Национальный уровень
Среди работ Украинских
ученых,
направленных в эту сферу, важный вклад был произведен Святогором
Л. А. и Гладуном В. П. В их работе «Сематтический анализ текстов естественного языка: цели и средства» предлагается
расширенное толкование
понятия «текст естественного языка» [5]
и предлагается схема полного освоения его
семантического ресурса за счёт «компьютерного понимания» и
диалога. Указываются
средства достижения указанной цели в процессе
семантической обработки текстов – использование трёхуровневой
онтологии для извлечения
из текста онтологического смысла, а также ввод обратной связи для
дополнительного
уточнения в диалоге содержания дискурса.
В начале и в конце семантического анализа
естественно-языковых
текстов стоит Слово. Методы анализа разнообразны и зависят от решаемой
в
прикладной области задачи, и существует не одно направление обработки
текстовой
информации. В условном разделении можно выделить методы семантической
обработки
текстов, которые нацелены на «лингвистические
преобразования» – методы
концептуального анализа. При этом можно заметить оформление двух
проблем:
синтез систем представления знаний – онтологий и разработка
систем
семантического анализа и машинного «понимания» текстов при
помощи онтологий.
Проблема синтеза решается широким фронтом; из
последних, практически успешных работ можно указать на исследование [6], где из
корпуса профессиональных текстов автоматически извлекается подструктура
знаний
в одном из разделов предметной области (ПрО)
«Материаловедение». Для синтеза онтологии используются
формально-логические и
синтаксические средства анализа.
В проблеме разработки систем семантического
анализа и
машинного понимания текстов подход состоит в следующем [7,
6]. Если описание ситуации,
изложенной в тексте, может быть достигнуто чисто лингвистическими
средствами,
то понимание ситуации возможно за рамками лингвистического ресурса
текста –
мобилизацией когнитивных усилий человека и его индивидуальных знаний.
Например,
как отмечает Г.С. Поспелов, связное восприятие текста возможно лишь при
его понимании.
Аналогично тому, как человеческое понимание
рождается
при согласовании внешней информации с его ментальной (когнитивной)
моделью мира,
«компьютерное понимание» может быть достигнуто отображением
информации на определённую
и формально-заданную систему знаний. Проще говоря, чтобы
«понимать» что-то, надо
его «узнавать». В машинной обработке текстовой информации
роль памяти человека выполняет
компьютерная система формальной репрезентации знаний – онтология:
именно она
позволяет совместить анализ текста с его компьютерным
«пониманием». Процедурно
это достигается достаточно просто: необходимо найти проекцию текста на
компьютерную онтологию.
Решению задачи полного раскрытия
семантического
ресурса текста, на наш взгляд, способствует такая Система
семантического анализа
ЕЯ текстов (Система), которая удовлетворяет следующим требованиям:
Первое. Партнёры интеллектуального общения
вместе с текстом
погружены в единую компьютерную среду онтологического знания.
Второе. Предварительная лингвистическая
обработка исходного
текста (морфологический, синтаксический и семантический анализ
предложений)
необходима для снятия «лексической оболочки» и выделения
термов, несущих
содержательную нагрузку.
Третье. Результатом компьютерного
семантического
анализа связного текста должен быть формальный или адаптированный текст
ЕЯ,
который выражает его смысловое содержание.
Четвёртое. Система должна обеспечивать
самоконтроль
авторского намерения – насколько адекватно он выражает свои
мысли.
Пятое. Система должна многократно
активизировать текст
с целью более глубокого проникновения в смысл сообщения.
В результате самого общего взгляда на
желаемые качества
Системы семантического анализа можно сделать вывод, что потенциальные
возможности
текста реализуются при помощи двух механизмов: анализа через онтологию
и
активного диалога.
Первое требование – взаимопонимание
партнёров
коммуникации – обеспечивается единой системой представления общих
и
профессиональных знаний, накопленных в социуме. В качестве контекстной
среды общения
предлагается формальная семантическая сеть – иерархическая
трёхуровневая онтология
(см. ниже), сформулированная в работе [8], которая
может быть расширена и дополнена
спектром любых предметно-ориентированных онтологий [6,
9, 10].
Второй тезис – предварительный разбор
текста –
выполняется лингвистическим процессором, ориентированным на
семантический
анализ обычной текстовой информации. В самом простом случае от
лингвистического
процессора требуются: построить дерево синтаксического разбора,
выделить
ядерные конструкции предложений, построить отношения, определить
«значимые»
лексические группы, в частности – ключевые слова текста [6].
Третье условие означает, что из текста
необходимо
извлечь его смысловое содержание. Смысл связного текста, формализуется
через
онтологию – как совокупность подграфов концептуального графа.
Задача выявления
смысла в некотором текстовом фрагменте (и в целом тексте) возлагается
на смысловой
процессор.
В четвёртом требовании предусмотрена
сервисная
возможность коррекции текста его автором. При желании он сравнивает
результат автоматического
выделения смысла со своими внутренними намерениями.
Наконец, для более глубокого раскрытия
смысла,
уточнения фактов и других данных (пятое условие) предусмотрен режим
диалога,
который реализуется на естественном языке диалоговым процессором. В
процессе
диалога смысл может существенно измениться, что, в свою очередь, может
служить
поводом для корректировки онтологии (активность текста).
Как смысловой, так и диалоговый процессоры
выполняют интеллектуальную
миссию, привлекая внелингвистические знания. К ним следует добавить
вспомогательный транслятор «смысл – текст», он (в
необходимых случаях) поможет
человеку более содержательно истолковать формальный подграф смысла.
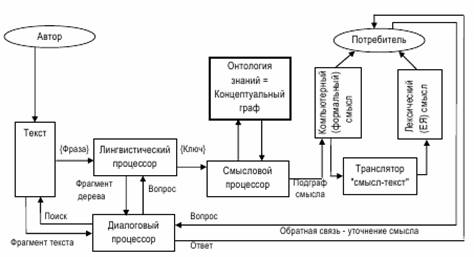
Рисунок 2 - Блок-схема Системы семантического
анализа
ЕЯ текстов
На рисунке 2 показана блок-схема Системы
семантического
анализа ЕЯ текстов, в которой взаимодействуют указанные выше
функциональные
компоненты.
Базисом Системы служит новая
иерархическая
трёхуровневая онтология – ИО*3 [8]. Она
отличается двумя особенностями: (а)
сетевая структура даёт принципиальную возможность объединить – в
рамках единой
конструкции – знания высшего уровня абстракции, общедоступные
(повседневные и
актуальные) знания среднего уровня и профессиональные знания нижнего
уровня;
(б) одновременно она ориентирована на работу с конкретными текстами.
Кроме
того, показано, что (в) результатом извлечения из текста знаний должен
быть
«онтологический смысл». Этот смысл поддаётся строгой
формализации и
компьютерной обработке [11].
Онтология ИО*3
организована
как «пирамида концептуальных знаний». Концепты обладают
разной степенью
обобщения. Наиболее абстрактные категории образуют верхний уровень
онтологии; в
соответствии с парадигмой академика В.И. Вернадского о биосфере и
ноосфере, это
– Материя, Вещество, Жизнь, Разум… Концепты среднего
уровня образуют
описательный континуум знаний. Они раскрывают значения категорий
верхнего уровня
через более употребительную в актуальной деятельности общества лексику,
например:
Время, Движение, Порядок, Человек, Общество,
Организация,
Развитие, Управление, Транспорт, Биология, Борьба за существование и
другие.
На нижнем уровне пирамиды знаний располагаются концепты двух типов:
часть из них
обозначают обиходные понятия повседневной жизни, привычные объекты и
ситуации
(комната, ложка, верх…), другие концентрируются вокруг
профессиональных знаний ПрО (концепт,
отношение, онтология…). Множество концептов ПрО
может быть пустым.
На помощь в определении понятия
«смысл» приходит
онтология ИО*3.
Идея состоит в том, что если
«пропустить» текст через
онтологию, которая является структурой знаний, то на выходе получим
концентрированное знание, которое коррелирует
с
текстом. Концептуальный фильтр онтологии даст на выходе концептуальный,
или
онтологический смысл.
Задан концептуальный онтологический граф
ИО*3.
Элементарный смысл определяется как пара
соединённых соседних
узлов онтологического графа.
Связи не обязательно именуются, они могут
лишь
фиксировать факт некоторого взаимодействия двух слов (например,
ворона–птица, пассажир–самолёт,
развитие–прогресс). Онто-граф
состоит из множества связанных
между собою элементарных смыслов, которые вступают в дозволенные
комбинации. Связная
часть онто-графа, соединяющая два
удалённых узла, образует
подграф; при изменении в нём стрелок на
противоположные (снизу – вверх) получается цепочка подграфа.
Цепочка связанных элементарных смыслов,
которая начинается
в некотором «активном» узле и заканчивается в вершине
онтологии, образует онтологическую
цепочку активного узла. Цепочка, выделяемая активным узлом на
онтологическом графе,
трактуется как смысловая траектория и называется онтологическим смыслом
активного слова.
Процесс возбуждения смысловой траектории
начинается с
того, что в предложении из ядерной конструкции выделяется некоторое
«ключевое
слово». Если оно присутствует в онтологическом графе, то активное
слово возбуждает
соседний концепт, возбуждение передаётся дальше на высшие уровни
онтологии –
вплоть до вершины пирамиды. Результатом процесса является цепочка, то
есть –
дискретная упорядоченная последовательность взаимосвязанных концептов;
она является
формальным онтологическим смыслом входного слова в заданной
«картине знаний» (см.
рис. 3).
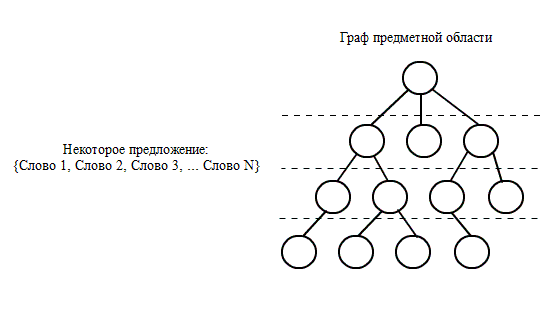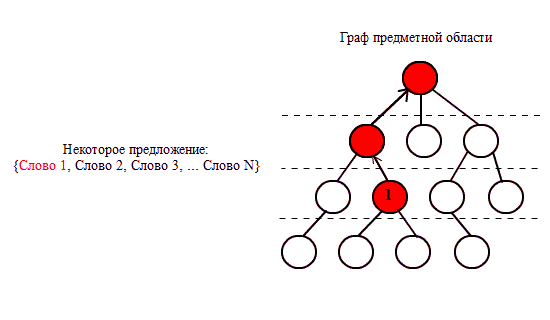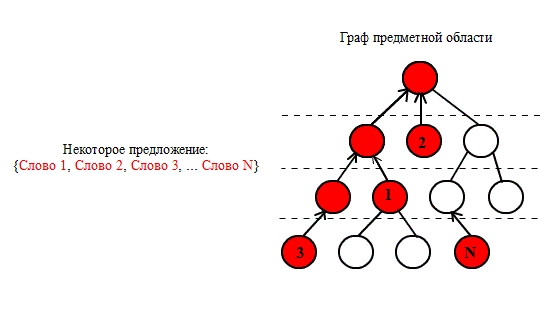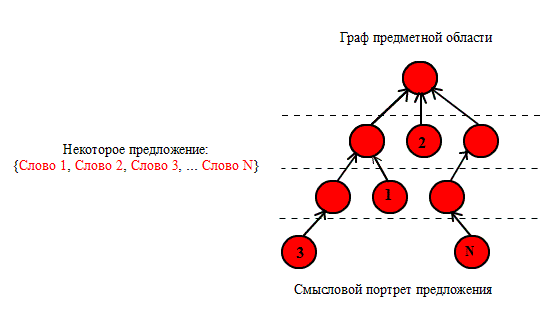
Рисунок 3 –
Построение смысловых траекторий NO3
(анимация: 10 кадров, 5
циклов повторения, 16 килобайт)
Результатом полного просмотра текста является
множество – «пучок смысловых траекторий», который
можно трактовать как
«семантический портрет текста».
Онтологический смысл может быть целью и
результатом семантического
анализа ЕЯ текста благодаря таким свойствам:
– ключевые слова в смысловой цепочке
извлекаются
непосредственно из текста;
– эти слова помещаются в контекст общих
знаний,
которые организованы как концептуальная смысловая среда (онтология);
– множество смысловых цепочек даёт
краткое, дискретное
и формализованное описание текста (фрагмента текста) –
«семантический портрет
текста» в терминах общих знаний.
Функцию выделения в тексте значимого слова
выполняет лингвистический
процессор. Функция выделения в онтологическом графе смысловой
траектории возлагается
на смысловой процессор.
Функцию адаптированного представления смысла
выполняет
транслятор «смысл – текст» (см. рис. 2).
Онтологический смысл, извлечённый из
текстового документа
компьютерной системой, становится элементом Базы знаний, которая
доступна всем
партнёрам коммуникации.
Фундаментальная ценность механизма выявления
онтологического
смысла кроется в том, что он, создавая графический портрет текста и
описывая его
метаязыком онтологии, позволяет человеку сложить хотя и самое общее и
схематичное, но вполне адекватное представление о ситуации, дать ему
концентрированную информацию, возбудить целенаправленные вопросы,
отсеять
лишние гипотезы.
В итоге
потребитель получает определённую ясность – в чём состоит суть
сообщения.
Что касается человеческого понимания
онтологического смысла,
формат которого непривычен для (современного) человека, то для его
преобразования в грамматическую языковую форму предусмотрен, как
указано выше, специальный
транслятор «смысл – текст». Принципы трансляции
разработаны в лингвистической
модели «смысл–текст» [12].
Обзор
исследований и разработок по теме. Локальный уровень
Являясь одним из весьма заметных и значимых, Донецкий национальный технический университет так же ведет свои исследования в сфере семантического анализа естественно-языковых высказываний. Одной из наиболее заметных, является работа Лукьяненко С.А., Бессоновой А.В. и Казаковой Е.И. [13].
Согласно их исследованиям, естественный язык
содержит
все средства для выражения алгоритмов и всевозможных данных при их
машинной
обработке, он может служить прекрасным средством коммуникации человека
и ЭВМ. Любая автоматизированная информационная система должна иметь в
своем
составе набор средств автоматической обработки естественно-языковых
сообщений.
Но в силу того, что естественный язык состоит из словаря и
грамматики – любая
автоматизированная система обработки естественно-языковых сообщений
должна
иметь в своем составе «средства грамматической обработки» и
«средства словарной
(семантической) обработки». Системы подобного рода принято
называть
интеллектуальным интерфейсом.
Средства грамматической обработки
естественного языка
представляют собой формализованный набор правил грамматики русского
языка. Но
так как изменение слов не всегда вкладывается в рамки регулярности, то
формализованной
может быть не вся грамматика. Формализованный набор может быть не
полным также
и из-за недостаточной научности грамматики. Таким образом, все
неучтенные
правила можно считать недопустимыми.
При формализации словаря наиболее приемлемой
является поуровневая обработка лексических
единиц. Для каждой
предметной области должен быть определен словарь исходных
(непроизводных)
лексических единиц (нижний уровень), посредством которого и с
использованием
информации об имеющихся аффиксах можно исчислять семантику любого
производного
слова, при этом, также, средствами системы можно получать новые
производные
слова, имея их семантическое отображение.
Итак, любой вид машинной обработки
естественного языка
сообщений включает в себя обработку отдельных лексических единиц. В
свою
очередь, обработка отдельных слов — обработка составляющих слово
частей: корня
и аффиксальных частей.
Структура подсистемы семантической обработки
естественно-языковых сообщений может быть представлена в виде:
1. Модель текста.
2. Модель фразы (группы слов).
3. Модель словосочетания (пары слов).
4. Модель словa:
a) модели аффиксов;
b) модель корня.
Структура системы автоматизированной
обработки
естественного языка продиктована структурой смысла текста, ибо любой
текст
расчленяет на части именно смысл. Само слово, к примеру, нерасчленимо
на части и именно смысл элементарных морфов позволяет выделить в нем
минимальные значимые единицы.
При моделировании всех уровней подсистемы
семантической обработки естественно-языковых сообщений используется
единый
подход. Это обстоятельство и позволяет создать общую модель смысла в
виде
системы алгебры конечных предикатов. Отдельная система уравнений
алгебры
конечных предикатов описывает словоизменение.
Естественный язык представлен, с точки зрения
морфологии, одноморфными и многоморфными
словами. С точки зрения словообразования одноморфные
слова это — непроизводные лексические единицы, многоморфные –
производные. Семантика производного слова опирается, как правило, на
смысл
непроизводной лексической единицы, входящей в состав этого слова, и
семантику
аффиксального окружения (префиксы, суффиксы). Иными словами, смысл
производного
слова исходит из семантики морфов, входящих в состав производного
слова,
поэтому естественной частью модели языка является модель его
словообразовательного уровня.
Модель семантики производного слова
представлена
комплексом независимых математических моделей. Это модель префикса,
модель
корня, модель суффикса. Анализ семантики любой производной лексической
единицы
начинается с разбиения ее на морфы. Поле выполнения этой операции
функционирование вышеперечисленных моделей возможно в параллельном
режиме. При
этом первоначально исчисляется смысл корня, затем с учетом его
семантики,
вследствие параллельной работы подсистем моделей аффиксов, исчисляется
смысл
производного слова. Такая организация систем семантического анализа
позволяет
существенно ускорить автоматическую обработку текстов.
Различные модели семантики производных слов
могут быть
использованы в любых автоматизированных системах обработки
естественного языка.
При этом следует иметь в виду, что каждый конкретный вариант системы
обработки
естественных языков вовсе необязательно должен содержать в себе
средства,
способные актуализировать все возможные семантические реализации того
или иного
слова. В каждом конкретном случае система может представлять собой
некую
редуцированную модель, ориентированную на конкретную предметную
область.
Остаточная неоднозначность языка, в частности явления омонимии,
устраняются за
счет соответствующих технологических мер: сочетанием данного слова с
другими
так, чтобы словосочетание в целом стало однозначным. В ряде случаев
значения
слов в словаре можно ограничить одним значением – единственно
возможным в
данном варианте системы.
Применение этих моделей возможно в различных
системах
обработки текстов русского языка. Это может быть широкий класс
диалоговых
систем; возможно применение разработанных моделей в системах
автоматического
редактирования, в системах автоматического корректирования для
обнаружения
ошибок во входных текстах, во всевозможных автоматизированных системах
информационного поиска, в автоматизированных обучающих системах. Особую
роль
предлагаемые модели сыграют в тестирования знаний. Получение ответа на
естественном языке можно свести к получению семантического эквивалента,
который
будет сравниваться с эквивалентом ответа. При этом одновременно будет
осуществляться семантический контроль как входных, так и выходных
текстовых
конструкций.
Краткое
изложение собственных результатов
На основе проведенного анализа, для
дальнейшего
развития была выбрана падежная модель Ч. Филлмора.
Глубокое рассмотрение данной модели, позволило прийти к выводу, что она
может
быть расширена и применина к сложным
предложениям на
естественном языке. При этом, она
по-прежнему должна
действовать только в рамках некоторой предметной области для
обеспечения
отсутствия двузначностей при выявлении смыслового содержания текста
ответов в
системах тестирования.
Заключение
Итак, было установлено, что в качестве основы
анализа
текста лежит выделение в нем смысловых составляющих. Выявление этих
составляющих
в тексте и оперирование с ними является основой смыслового анализа
текстов. При
этом важно отметить, что значение смысловых составляющих тесно связано
с рассматриваемой
предметной областью.
В заключение обзора
различных подходов
и направлений реализации моделей лингвистического процессора можно
сделать
вывод о том, что к настоящему времени модели способны: извлекать знания
из
заданного текста и строить правильные предложения естественного языка
по заданным
значениям смысла; перефразировать эти предложения; оценивать их с точки
зрения
связности и выполнять ряд других задач.
Список литературы
1.
Manning C.D. Foundation of ststustical nature language
processing / C.D. Manning. – 1992. – Vol.12, N 4. –
P.89-94.
2.
Воропаев
А.С. Эволюция
вычислительных машин [Электронный ресурс].
– Режим доступа: http://www.snkey.net/books/samxp/ch1-1.html
3.
Filmor C. Frames and the semantics of understanding /
C. Filmor // Quaderni di semantica.Vol 4 / 2 December 1985 – p.
222-254
4.
Shank R. Conceptual information processing / R. Shank
– Norh-
5. Святогор Л. Семантический анализ текстов естесственного языка: цели и средства / Л. Святогор, В. Гладун // XV th International Conference “Knowledge-Dialogue-Solution” KDS-2 2009, Киев, Украина, Октябрь, 2009.
6.
Палагин
А. К анализу
естественно-языковых объектов / А. Палагин, С. Крывый, В. Величко, Н.
Петренко
// International Book Series, Number 9. Intelligent Processing.
Supplement to the
International Journal “Information Technologies &
Knowledge” Volume 3 /
2009. – ITHEA,
7.
Кибрик
А.Е. Семантическая проблематика
гетерологического кодирования / А.Е. Кибрик – М.: Наука 1965.
– С. 67-83
8.
Гладун
В. Структурирование
онтологии ассоциаций для конспектирования естественно–языковых
текстов / В. Гладун,
В. Величко, Л. Святогор // International Book Series, Number 2. Advanced Research in
Artificial Intelligence. Supplement to the International Journal
“Information
Technologies & Knowledge” Volume 2 / 2008. – ITHEA,
9.
Поспелов
Г.С. Искусственный интеллект – основа новой
информационной технологии / Г.С. Поспелов – М.: Наука, 1988.
– 279 с.
10.
Гаврилова
Т.А. Базы знаний интеллектуальных
систем / Т.А. Гаврилова, В.Ф. Хорошевский – СПб.: Питер, 2001.
– 384 с.
11.
Святогор
Л.
Определение понятия «Смысл» через онтологию. Семантический
анализ текстов естественного
языка. / Л. Святогор, В. Гладун // International Book Series, Number 9. Intelligent
Processing. Supplement to the International Journal “Information
Technologies
& Knowledge” Volume 3 / 2009. – ITHEA,
12. Мельчук И.А. Опыт теории
лингвистических моделей «Смысл – Текст» / И.А.
Мельчук – М.: Школа «Языки русской
культуры», 1999. – 346 с.
13. Лукьяненко С.А., Бессонов А.В., Казакова
Е.И. Моделирование
семантики естественно языковых высказываний в автоматизированных
информационных
системах [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2006/fema/lukyanenko/library/art03.htm