
Abstract
Navigation
- Introduction
- 1. Actuality
- 2. Goal and tasks of the research
- 3.The subject and object of research. Planned practical results
- 4.Used algorithms
- 4.1 Image pre-processing algorithms
- 4.2 Use of 2D-color histograms and correlation coefficients
- Conclusion
- References
Introduction
People can allocate hundreds objects and receive its characteristics with vision system. Creation of human abilities with the help of computer systems has grown tremendously. It is used in various areas: medical, military, education and science, trade, security and others.
Creation of artificial recognition systems still is a theoretical and technical problem. But currently there are many different types of computer systems: letters recognition, barcode recognition, face recognition, speech recognition, image recognition, license plate recognition.
It’s important part to identify characters in image in text recognition systems. This task involves two stages: the selection of possible text areas and check the actual availability of the text in the selected area.It is not new problem to create a universal algorithm for detecting text on images. However, there are not optimum solution in this area.
1. Actuality
Spam email is the most popular way of distributing unwanted information. In response to development of spam filters, the unwanted messages authors began to send out spam texts in the form of images attached to emails. In this connection modern spam-filters and anti-virus software should use technology to detect spam text embedded in an image. To solve this problem, initially identified the existence of the text in the image, and then determines whether the text spam. Currently, many anti-spam laboratories put the focus on the step of text detection.
Content-base retrieval is the one from the search methods in information retrieval systems. Sources of pictures are trademarks base, photostocks, the Internet, where images can have an arbitrary content. It's necessary to improve text detection methods to create a system of comprehensive content-based retrieval in digital collections of images .
Text recognition systems widely used in the software industry, and have found their niche among image processing systems. Detection and localization of text is one of the stages of text recognition in the image. Actively created mobile applications whose primary purpose is to recognize the text on the image (photo), the further its translation (applications for tourists) or to obtain additional information (search engines) [10].
2. Goal and tasks of the research
Goal of the research is development of an effective method image retrieval containing text. The main tasks of the master's work are:
- analyze existing methods text detection in images, to identify their strengths and limitations;
- identify the main factors affecting the efficiency of the algorithms;
- develop an efficient method image retrieval containing text;
- experimentally prove the effectiveness of method using a computer program.
3. The subject and object of research. Planned practical results
The object of this work is research the picture obtained from the collection. The subject of the research is the retrieval method for images that contain text. Within the master's work is planned to receive the following scientific and practical results:
- development of a retrieval method for containing text images;
- creation of a computer program that will help to provide an estimate of the developed method.
4. Used algorithms
The task of text detection includes the following sub-tasks: allocation of possible text areas, determine the angle of text rotation and the definition of the reading order to determine the logical structure of the page. There are two groups of methods to allocate the text: methods that use histograms, and methods using segmentation [10].
4.1 Image pre-processing algorithms
Object recognition can be used both color and black-and-white images. In the first approach, we can get more information about an object while the second approach image processing can facilitate time and speed.
To preprocess the image within the master's work will be used algorithm for image conversion from color to gray scale (Grayscale) and image binarization.
Greyscale
Grayscale is color mode which are displayed images in shades of gray. This algorithm allows to convert a color image to gray scale. The algorithm passes the width and height of image where each pixel is converted from RGB to HLS color model. Then saturation is reduced from 100 to 1 and convert color model back.
Transformation occurs by the following equations:
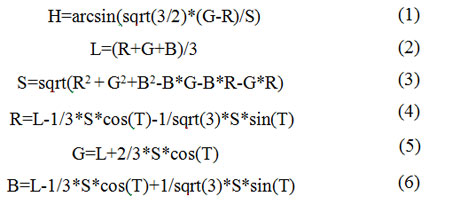
where H – Hue, L – Lightness, S – Saturation, R – Red, G – Green, B – Blue [11].
Binarization
Image binarization process based on the comparison of the brightness of each pixel B (x, y) with a threshold brightness BT (x, y). If the brightness value of the pixel above luminance values the threshold, appropriate pixel of the binary image will be "white" or "black". Necessity to obviate a large number of binarization process errors led to appearance of a large number of binarization methods: the lower threshold binarization, the upper threshold binarization, double limitation binarization, Ots method, Yanni method, average method, Burns method, Eykvil method, Niblek method and other.
The lower threshold binarization is the most simple operation, which uses only one threshold value:
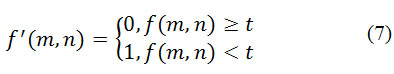
All values are 1 instead of the criterion, in this case 255 (white), and all the values (amplitude) of pixels which is more than the threshold t – 0 (black) [12]. An example of algorithm results shown in Figure 1.

Figure 1 – The lower threshold binarization
4.2 Use of 2D-color histograms and correlation coefficients
To represent the color image content was proposed to build a histogram, consider the correlation of color pixels pairs. The constructed characteristic of image content was called a two-dimensional color histogram (2D-color histogram). Use of such characteristics is particularly effective for color images [13].
2D-color histogram takes into account the spatial content of the image. 2D-color histogram is constructed as a two-dimensional array Cmax*Cmax where Cmax – the number of colors of basic set that was used in the color quantization step. Every histogram element is the number of pixel pairs with a predetermined color correlation in the neighborhood [13].
Consider the 2D-color histogram construction algorithm. Each image point M*N is compared with the k template points incremented k elements of 2D-color histogram. After image processing the sum of 2D-color histogram elements is equal to k*M*N. Each element will be equal to the number of point pairs with predetermined correlation of colors. Then performed normalization of elements by dividing of every value on the number pixel pairs that will allow us to compare the 2D-color histograms constructed for images of different sizes. Construction of 2D-color histogram by this algorithm means that each element of H [i, j] is the probability of presence of a pair points in the image with colors c [i] and c [j]. If the color space has the property of completeness, it is obvious that
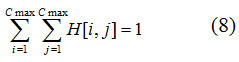
This characteristic is a matrix in which each element stores the normalized number of pixel pairs with colors corresponding to the index of the element in the neighborhood of each point. For comparison 2D-color histograms is proposed to calculate the correlation coefficient. Considering properties of the correlation coefficient they must be placed in order of coefficient decreasing [13].
The mechanism of image retrieval system using 2D-color histograms shown in Figure 3.

Figure 3 – Image retrieval system
(animation: 5 frames, 5 cycles, 148 KB)
The correlation coefficient (CC) is an important indicator showing the relationship between the two sets of data. CC can take values from -1 to 1. Negative CC indicates that the data is interconnected diverge with increasing values of some of these other values decrease, the positive – that these interconnected grow, 0, and similar values indicate that the data are not related to each other. Formula that calculates the linear correlation coefficient:
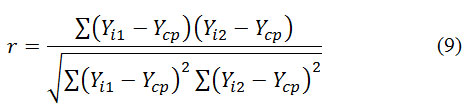
Conclusion
Within of this essay was reviewed existing methods for the detection of text in images, image pre-processing methods, and presents a method of image search on the model using the 2D-color histograms.
This master's work is not completed yet. Final completion: December 2013. The full text of the work and materials on the topic can be obtained from the author or his head after this date.
References
- Васильева Н., Дольник А., Марков И. Поиск изображений. Синтез различных методов поиска при формировании результатов.//15th IEEE International Conference on Image Processing, 2008. ICIP 2008, 12-15 Oct. 2008, P. 969-972.
- Байгарова Н.С., Бухштаб Н.А., Евтеева Н.Н. Современная технология содержательного поиска в электронных коллекциях изображений.//Российский научный электронный журнал, 2001 – Том 4 – Выпуск 4.
- Николенко А.А., Тьен Т.К. Нгуен. Обнаружение текстовых областей и выделение символов на изображениях с неоднородным фоном.//Праці Одеського політехнічного університету, 2013. Вип. 1(40), с. 55-60.
- Николенко А.А., Тьен Т.К. Нгуен. Обнаружение текстовых областей в видеопоследовательностях.//«Искусственный интеллект» 4’2012, с. 227-234.
- Башков Е.А., Костюкова Н.С. К оценке эффективности поиска изображений с использованием 2d-цветовых гистограмм.//Проблемы управления и информатики, №6, 2006. с. 84-89.
- Костюкова Н.С. Применение контекстного поиска изображений при поиске графических файлов, похожих по содержанию.//7-я международная конференция «Интеллектуальный анализ информации ИАИ-2007», г.Киев, 15-18 мая 2007 г., сборник трудов. – С. 178-186.
- Башков Є.О., Вовк О.Л., Костюкова Н.С. Ефективні методи і алгоритми пошуку зображень в цифрових колекціях.//Прогресивні інформаційні технології в науці, освіті та економіці. Збірка наукових праць. – Вінниця: Вінницький кооперативний інститут, 2009. – с. 101-109.
- Башков Є.О., Вовк О.Л., Костюкова Н.С. Методи покращення результатів пошуку зображень в цифрових колекціях.//Наукові праці Донецького національного технічного університету. Серія "Інформатика, кібернетика і обчислювальна техніка" (ІКОТ-2010). Випуск 12 (165) – Донецьк: ДонНТУ. – 2010. – С. 77-81.
- Bashkov Ye.E.,Kostyukova N.S., Vovk O.L. Image retrieval in databases.//Proceedings of Donetsk National Technical University/ No1, 2010. p. 28-33.
- Сысоева Д.А. Современные подходы к поиску изображений, содержащих текст.//Інформаційні управляючі системи та комп’ютерний моніторинг (ІУС КМ – 2013) – 2013 / Матерiали IV мiжнародної науково-технiчної конференцiї студентiв, аспiрантiв та молодих вчених. – Донецьк, ДонНТУ – 2013, Том 1, с. 387-391.
- Основные алгоритмы распознавания образов/ Интернет-ресурс. – Режим доступа: http://shkolnie.ru/informatika/1879/index.html?page=2
- Сегментация изображений/Интернет-ресурс. – Режим доступа: http://habrahabr.ru/post/128768/
- Расчет коэффициента линейной корреляции /Интернет-ресурс. – Режим доступа: http://gis-lab.info/qa/correlation.html
- Михалевський Д.В., Наугольних Є.С., Мельник В.М. Оцінка параметрів відеозображення в телекомунікаційних системах.//Вимірювальна та обчислювальна техніка в технологічних процесах № 1’ 2013, с. 201-205.
- RIT Department of Computer Science Pattern Recognition/Интернет-ресурс. – Режим доступа: http://www.cs.rit.edu/~rlaz/prec2010/Snyder.pdf
- Anthimopoulos M., Gatos B., Pratikakis I. Text detection in video frames.//11th Panhellenic Conference on Informatics (PCI 2007), Patras, Greece, May 2007, pp. 361-370.
- Text Detection in Images and Videos/ Интернет-ресурс. – Режим доступа: http://cgi.di.uoa.gr/~phdsbook/files/Anthimopoulos.pdf
- Обнаружение текста на изображениях/Интернет-ресурс. – Режим доступа: http://compscicenter.ru/sites/default/files/materials/2012-11-23_ImageVideoAnalysis_Lecture09.pdf