
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цели и задачи исследования
- 3. Предмет и объект исследования. Планируемые практические результаты
- 4. Обзор исследований и разработок по теме
- 4.1 Обзор международных источников
- 4.2 Обзор национальных и локальных источников
- 5. Используемые алгоритмы
- 5.1 Алгоритмы предобработки изображений
- 5.2 Основные методы обработки изображений
- 5.3 Использование 2D-цветовых гистограмм и коэффициентов корреляции
- Выводы
- Список источников
Введение
С помощью основных функций системы зрения человек способен выделять из сотен объектов нужный ему и получать характеристики этого объекта. Воссоздание человеческих способностей с помощью компьютерных систем приобрело огромные масштабы, и получило применение в различных областях деятельности: медицинской, военной, сфере образования и науки, торговле, сфере безопасности и других.
Создание искусственных систем распознавания образов остаётся сложной теоретической и технической проблемой, однако на данный момент существует множество компьютерных систем различных видов: распознавание букв, распознавание штрих-кодов, распознавание лиц, распознавание речи, распознавание изображений, распознавание автомобильных номеров.
Важную роль для систем распознавания текста играет выявление символов на картинке. Эта задача включает в себя два этапа: выделение возможных текстовых областей и проверку действительного наличия текста в выделенной области. Проблема создания универсального алгоритма поиска изображений, содержащих текст, не является новой, однако очевидно отсутствие оптимальных решений в этой области.
1. Актуальность темы
Спам в электронной почте является самым популярным способом распространения нежелательной информации. В ответ на разработку спам-фильтров, авторы нежелательных сообщений стали рассылать тексты в виде изображений, прикрепленных к письмам. В связи с этим современные спам-фильтры и антивирусное программное обеспечение должны использовать технологии, позволяющие обнаруживать текстовый спам, внедренный в изображение. Для решения этой задачи изначально идентифицировали наличие текста в изображении, а затем определяли, является ли данный текст спамом. На данный момент многие лаборатории по защите от спама ставят акцент на этап обнаружения текста, оставляя получателю право окончательного решения по поводу нежелательности письма, содержащего такие вложения.
В информационно-поисковых системах одним из способов поиска является поиск по информации, содержащейся в самом изображении. Источниками картинок являются базы торговых знаков, фотостоки, сети Интернет, где изображения могут обладать произвольным содержанием. Для создания системы всестороннего содержательного поиска в электронных коллекциях изображений необходимо совершенствовать методы обнаружения текста.
Системы распознавания текста получили широкое распространение в сфере программного обеспечения, и заняли свою нишу среди систем обработки изображений. Обнаружение и локализация текста являются одним из этапов распознавания текста на изображении. Активно создаются мобильные приложения, основной целью которых является распознавание текста, находящегося на изображении (фото), дальнейший его перевод (приложения для туристов) или получение дополнительных сведений (поисковые системы) [10].
2. Цели и задачи исследования
Целью проводимого исследования является разработка эффективного метода поиска изображений, содержащих текст. К основным задачам магистерской работы относятся:
- проанализировать существующие методы обнаружения текста на изображениях, выявить их преимущества и недостатки;
- выявить основные факторы, влияющие на эффективность алгоритмов;
- разработать эффективный метод поиска изображений, содержащих текст;
- доказать эффективность экспериментально с помощью компьютерной программы.
3. Предмет и объект исследования. Планируемые практические результаты.
Объектом исследования данной работы является изображение, полученное из коллекции. В качестве предмета исследования выступает метод поиска изображений, содержащих текст.
В рамках магистерской работы планируется получение следующих научных и практических результатов:
- разработка метода поиска изображений, содержащих текст;
- создание компьютерной программы, которая поможет получить оценку разработанного метода.
4. Обзор исследований и разработок по теме
4.1 Обзор международных источников
Проблема обнаружения текста на изображениях является достаточно актуальной международной темой, о чем свидетельствует большое количество публикаций иностранных университетов. Англоязычные научные работы описывают множество комбинированных методов выявления текста на изображениях, используя разные характеристики.
Афинский университет в своей электронной библиотеке содержит работы "Text detection in video frames" [16], "Text Detection in Images and Videos" [17].
Рочестерский институт технологий содержит в своей электронной базе статью "Detection of Text in Video" [15].
Выделяются также российские университеты, такие как Санкт-Петербургский Государственный университет (Васильева Н., Дольник А., Марков И.) [1], Московский институт прикладной математики имени М.В. Келдыша РАН (Байгарова Н.С, Бухштаб Н.А., Евтеева Н.Н.) [2].
4.2 Обзор национальных и локальных источников
В Донецком национальном техническом университете исследования по вопросам обработки изображений и методов поиска изображений, базируемых на семантическом содержании изображения, осуществляются Башковым Е.А, Костюковой Н.С и Вовк О.Л. С результатами исследований можно познакомиться в источниках [5], [6], [7], [8], [9].
Одесский политехнический университет представляет кандидат технических наук, доцент Николенко А.А. Им представлено множество работ, в число которых входит «Обнаружение текстовых областей и выделение символов на изображениях с неоднородным фоном» [3], «Обнаружение текстовых областей в видеопоследовательностях» [4].
Винницкий национальный технический университет содержит в своем электронном архиве работу по обработке изображений: "Оцінка параметрів відеозображення в телекомунікаційних системах" [14].
5. Используемые алгоритмы
Очевидно, что использование традиционных методов, которые используются для сопоставления содержимого изображений, например, методов, ориентированных на использование гистограммных признаков, точечных оценок, кластеризации и сегментации, не решит рассматриваемую проблему из-за специфики рассматриваемого класса изображений. Однако традиционные методы могут быть использованы как основа, в качестве отдельных этапов при решении рассматриваемой задачи.
Задача обнаружения текста на изображениях включает в себя такие подзадачи: выделение возможных текстовых областей, определение угла поворота текста и определение порядка чтения для определения логической структуры страницы. Для выделения текстовых областей существуют две группы методов: методы, использующие гистограммы, и методы, использующие сегментацию [10].
5.1 Алгоритмы предобработки изображений
Для распознавания объектов можно использовать как цветные, так и черно-белые изображения. В первом подходе мы можем получить больше информации об объекте, в то время как второй – может облегчить обработку изображений по времени и скорости.
Для предобработки изображений в рамках магистерской работы будут использоваться алгоритм преобразования изображения из цветного в шкалу серых тонов (Grayscale) и бинаризация изображений.
Greyscale
Grayscale — цветовой режим изображений, которые отображаются в оттенках серого цвета. Данный алгоритм позволяет перевести цветное изображение в шкалу серых тонов. Алгоритм проходит изображение по ширине и высоте, где каждый пиксель конвертируется из RGB в HLS цветовую модель. Затем насыщенность (Saturation) понижается с 100 до 1 и опять переводим назад. Перевод происходит по следующим формулам:
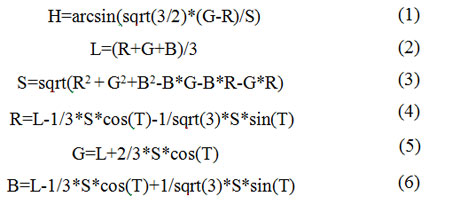
где H – тон (Hue), L – яркость (Lightness), S – насыщенность (Saturation), R – красный (Red), G – зеленый (Green), B – синий (Blue) [11].
Бинаризация
Процесс бинаризации изображения основан на сравнении яркости каждого пикселя B(x,y) с пороговым значением яркости BT(x,y); если значение яркости пикселя выше значения яркости порога, то на бинарном изображении соответствующий пиксель будет «белым», или «черным» в противном случае. Необходимость устранения большого числа ошибок процесса бинаризации, повлекла за собой появление большого числа методов бинаризации: бинаризация с нижним порогом, бинаризации с верхним порогом, бинаризация с двойным ограничением, метод Отса (Оцу), метод Янни (Яни), метод среднего, метод Бернсена, метод Эйквила, метод Ниблэка и другие.
Бинаризация с нижним порогом является наиболее простой операцией, в которой используется только одно значение порога:
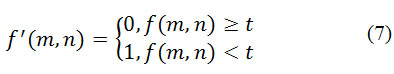
Все значения вместо критерия становятся 1, в данном случае 255 (белый) и все значения (амплитуды) пикселей, которые больше порога t — 0 (черный) [12]. Пример работы алгоритма показан на рисунке 1.

Рисунок 1 – Бинаризация с нижним порогом
5.2 Основные методы обработки изображений
Гистограммы используются в основном для выделения текста на изображениях формата «документ». На таких картинках текст структурирован, выровнен по странице и горизонтален, имеет схожий шрифт и, если присутствует наклон, то одинаковый для всех строк. Существует два способа создания гистограмм: сверху-вниз, в котором при поиске оценивается вся страница целиком, и снизу-вверх, где для определения текстовых областей выделяются компоненты связности – символы [10].
К первому способу относится метод проекций страницы (Projection profiles and XY cuts). Основной идеей метода является подсчет черных пикселей в выделенной строке и создание гистограммы вертикальной или горизонтальной проекций. Затем происходит «разрезание» областей по светлым долинам гистограммы. Горизонтальные и вертикальные проекции могут накладываться друг на друга. После построения проекции страницы строится проекция для строки, где строятся проекции для отдельных слов. Метод дает хорошие результаты, если исходный документ не содержит изображений [10].
Представителями метода «снизу-вверх» являются алгоритм Docstrum и алгоритм с использованием диаграмм Вороного. Гистограммы для этих алгоритмов строятся на основании расстояния между компонентами связности: символами, словами, строками, разделами [10].
Для выделения текста на произвольных изображениях существует большее количество методов, чем для изображений типа документ. Их можно разделить на методы, использующие текстуры (texture-based) и методы использующие области выделения (region-based) [10].
Текстура текста явно отличается от текстуры обычного изображения. Для определения признаков текстуры строится «пирамида» изображений, уменьшенных или увеличенных по размеру (рис. 2). Затем происходит проход по пикселям всей группы изображений и с помощью косинус- или вейвлет-преобразований определяются признаки текстуры. Этот метод хорош для однонаправленных текстов с одинаковым размером шрифта [10].
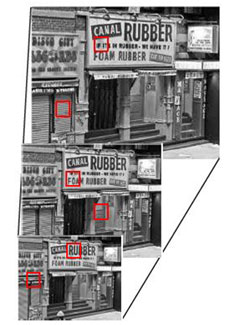
Рисунок 2 – Пирамида изображений [18]
Методы выделения краев объектов (Edge detection), анализа связных компонент (CCA - Connected Component Analysis), выделения углов (Corner detection), использование постоянства ширины штриха (Stroke Width Transform) используют большое количество эвристик, помимо основных своих показателей. Данные алгоритмы относительно просты в реализации, и справляются с произвольным направлением и шрифтом текста [10].
Для нахождения угла и поворота текста используют нахождение центра масс, выделение краев с помощью матричных фильтров Собеля, Хафа, Кэнни [10].
5.3 Использование 2D-цветовых гистограмм и коэффициентов корреляции.
Для представления цветового содержимого изображения предлагается строить гистограмму, учитывать соотношение цветов пар пикселей (а не только яркостную составляющую). Построенную таким образом характеристику содержимого изображения называют двумерной цветовой гистограммой (2D-цветовой гистограммой). Использование такой характеристики будет особенно эффективным для цветных изображений, обладающих следующими свойствами: с одной стороны, их содержимое можно назвать произвольным, с другой стороны, рисунок характеризуется определенной повторяемостью. Примером таких изображений являются образцы тканей, обоев и т.п., а также изображения цветных текстур, текста. Очевидно, что для сравнения таких изображений следует в равной мере учитывать как пространственное распределение цветов, так и информацию о локальном распределении цветов пикселей [13].
С учетом пространственной природы содержимого рассматриваемых изображений 2D-цветовая гистограмма строится как двумерный массив Cmax*Cmax, где Cmax – число цветов базового набора, использовавшегося на этапе квантования цветов. Каждый элемент такой гистограммы равен количеству пар пикселей с заданным соотношением цветов в окрестности точки (для заданного шаблона) [13].
Рассмотрим более подробно алгоритм построения 2D-цветовой гистограммы. Каждая из M*N точек изображения сравнивается с k точками шаблона, и в процессе этого сравнения увеличиваются на единицу k элементов 2D-цветовой гистограммы. Таким образом, после обработки всего изображения сумма элементов 2D-цветовой гистограммы будет равна k*M*N, а каждый ее элемент будет равен количеству пар точек с заданным соотношением цветов. Далее, выполним нормирование элементов, разделив значение каждого на количество пар точек изображения, что позволит нам сравнивать 2D-цветовые гистограммы, построенные для изображений различных размеров. Построение 2D-цветовой гистограммы по такому алгоритму означает, что каждый ее элемент H[i,j] представляет собой вероятность присутствия в изображении пары точек с цветами c[i] и c[j]. Если цветовое пространство, для которого выполнялось построение базового набора цветов c[1..Cmax], обладает свойством полноты, то формула (8) очевидна,
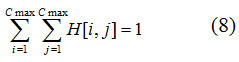
Данная характеристика представляет собой матрицу, каждый элемент которой хранит нормированное количество пар пикселей с цветами, соответствующими индексам элемента, в окрестности каждой точки. Для сравнения 2D-цветовых гистограмм изображений предлагается вычислять коэффициент их корреляции, так как 2D-цветовая гистограмма, построенная по алгоритму, описанному выше, является случайным вектором размерности Cmax2 (или, другими словами, многомерной случайной величиной). Учитывая свойства коэффициента корреляции, при формировании набора результирующих изображений их следует размещать в порядке убывания коэффициента [13].
Механизм работы системы поиска изображений по содержанию с использованием 2D-цветовых гистограмм показан на рисунке 3.

Рисунок 3 – Система поиска изображений
(анимация: 5 кадров, 5 циклов повторения, 128 килобайт)
Коэффициент корреляции (КК) – важный показатель показывающий взаимосвязь между двумя наборами данных. КК может принимать значения от -1 до 1. Отрицательный КК показывает, что данные взаимосвязанно расходятся, при возрастании значений одних из них значения другой убывают, положительный – что данные взаимосвязанно растут, 0 и близкие значения говорят о том, что данные не связаны друг с другом.
Формула, по которой вычисляется коэффициент линейной корреляции:
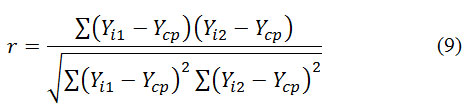
Выводы
В рамках данного реферата по теме магистерской работы был проведен обзор существующих методов обнаружения текста на изображениях, методов предобработки изображений, а также рассмотрен метод поиска изображений по образцу с использованием 2D-цветовых гистограмм. В дальнейшем предполагается модифицировать и использовать метод 2D-цветовых гистограмм для поиска изображений, содержащих текст, в больших коллекциях изображений.
Реферат написан по магистерской работе, которая еще находится в стадии написания. Конечная готовность магистерской работы – декабрь 2013 года.
Список источников
- Васильева Н., Дольник А., Марков И. Поиск изображений. Синтез различных методов поиска при формировании результатов.//15th IEEE International Conference on Image Processing, 2008. ICIP 2008, 12-15 Oct. 2008, P. 969-972.
- Байгарова Н.С., Бухштаб Н.А., Евтеева Н.Н. Современная технология содержательного поиска в электронных коллекциях изображений.//Российский научный электронный журнал, 2001 – Том 4 – Выпуск 4.
- Николенко А.А., Тьен Т.К. Нгуен. Обнаружение текстовых областей и выделение символов на изображениях с неоднородным фоном.//Праці Одеського політехнічного університету, 2013. Вип. 1(40), с. 55-60.
- Николенко А.А., Тьен Т.К. Нгуен. Обнаружение текстовых областей в видеопоследовательностях.//«Искусственный интеллект» 4’2012, с. 227-234.
- Башков Е.А., Костюкова Н.С. К оценке эффективности поиска изображений с использованием 2d-цветовых гистограмм.//Проблемы управления и информатики, №6, 2006. с. 84-89.
- Костюкова Н.С. Применение контекстного поиска изображений при поиске графических файлов, похожих по содержанию.//7-я международная конференция «Интеллектуальный анализ информации ИАИ-2007», г.Киев, 15-18 мая 2007 г., сборник трудов. – С. 178-186.
- Башков Є.О., Вовк О.Л., Костюкова Н.С. Ефективні методи і алгоритми пошуку зображень в цифрових колекціях.//Прогресивні інформаційні технології в науці, освіті та економіці. Збірка наукових праць. – Вінниця: Вінницький кооперативний інститут, 2009. – с. 101-109.
- Башков Є.О., Вовк О.Л., Костюкова Н.С. Методи покращення результатів пошуку зображень в цифрових колекціях.//Наукові праці Донецького національного технічного університету. Серія "Інформатика, кібернетика і обчислювальна техніка" (ІКОТ-2010). Випуск 12 (165) – Донецьк: ДонНТУ. – 2010. – С. 77-81.
- Bashkov Ye.E.,Kostyukova N.S., Vovk O.L. Image retrieval in databases.//Proceedings of Donetsk National Technical University/ No1, 2010. p. 28-33.
- Сысоева Д.А. Современные подходы к поиску изображений, содержащих текст.//Інформаційні управляючі системи та комп’ютерний моніторинг (ІУС КМ – 2013) – 2013 / Матерiали IV мiжнародної науково-технiчної конференцiї студентiв, аспiрантiв та молодих вчених. – Донецьк, ДонНТУ – 2013, Том 1, с. 387-391.
- Основные алгоритмы распознавания образов/ Интернет-ресурс. – Режим доступа: http://shkolnie.ru/informatika/1879/index.html?page=2
- Сегментация изображений/Интернет-ресурс. – Режим доступа: http://habrahabr.ru/post/128768/
- Расчет коэффициента линейной корреляции /Интернет-ресурс. – Режим доступа: http://gis-lab.info/qa/correlation.html
- Михалевський Д.В., Наугольних Є.С., Мельник В.М. Оцінка параметрів відеозображення в телекомунікаційних системах.//Вимірювальна та обчислювальна техніка в технологічних процесах № 1’ 2013, с. 201-205.
- RIT Department of Computer Science Pattern Recognition/Интернет-ресурс. – Режим доступа: http://www.cs.rit.edu/~rlaz/prec2010/Snyder.pdf
- Anthimopoulos M., Gatos B., Pratikakis I. Text detection in video frames.//11th Panhellenic Conference on Informatics (PCI 2007), Patras, Greece, May 2007, pp. 361-370.
- Text Detection in Images and Videos/Интернет-ресурс. – Режим доступа: http://cgi.di.uoa.gr/~phdsbook/files/Anthimopoulos.pdf
- Обнаружение текста на изображениях/Интернет-ресурс. – Режим доступа: http://compscicenter.ru/sites/default/files/materials/2012-11-23_ImageVideoAnalysis_Lecture09.pdf