
Реферат за темою випускної роботи
Зміст
- Вступ
- 1. Актуальність теми
- 2. Цілі та задачі дослідження
- 3. Предмет і об'єкт дослідження. Плановані практичні результати
- 4. Огляд досліджень та розробок
- 4.1 Огляд міжнародних джерел
- 4.2 Огляд національних і локальних джерел
- 5. Алгоритми, що використовуваються
- 5.1 Алгоритми попередньої обробки зображень
- 5.2 Основні методи обробки зображень
- 5.3 Використання 2D-колірних гістограм і коефіцієнтів кореляції.
- Висновки
- Перелік посилань
Вступ
За допомогою основних функцій системи зору людина здатна виділяти з сотень об'єктів потрібний йому і отримувати характеристики цього об'єкта. Відтворення людських здібностей за допомогою комп'ютерних систем набуло величезних масштабів, і отримало застосування в різних сферах діяльності: медичної, військової, сфері освіти і науки, торгівлі, сфері безпеки та інших.
Створення штучних систем розпізнавання образів залишається складною теоретичної та технічною проблемою, проте на даний момент існує безліч комп'ютерних систем різних видів: розпізнавання букв, розпізнавання штрих-кодів, розпізнавання облич, розпізнавання мови, розпізнавання зображень, розпізнавання автомобільних номерів та інші.
Важливу роль для систем розпізнавання тексту грає виявлення символів на картинці. Це завдання включає в себе два етапи: виділення можливих текстових областей та перевірку дійсної наявності тексту у виділеній області. Проблема створення універсального алгоритму пошуку зображень, які містять текст, не є новою, проте очевидна відсутність оптимальних рішень у цій області.
1. Актуальність теми
Спам в електронній пошті є найпопулярнішим шляхом розповсюдження небажаної інформації. У відповідь на розробку спам-фільтрів, автори небажаних повідомлень стали розсилати тексти у вигляді зображень, прикріплених до листів. У зв'язку з цим сучасні спам-фільтри та антивірусне програмне забезпечення повинні використовувати технології, що дозволяють виявляти текстовий спам, впроваджений в зображення. Для вирішення цього завдання спочатку ідентифікували наявність тексту в зображенні, а потім визначали, чи є даний текст спамом. На даний момент багато лабораторії по захисту від спаму ставлять акцент на етап виявлення тексту, залишаючи одержувачу право остаточного рішення з приводу небажаності листа, що містить такі вкладення.
В інформаційно-пошукових системах одним з методів пошуку є пошук за інформацією, що міститься в самому зображенні. Джерелами картинок є бази торгових знаків, фотостоки, мережі Інтернет, де зображення можуть володіти довільним змістом. Для створення системи всебічного змістовного пошуку в електронних колекціях зображень необхідно вдосконалювати методи виявлення тексту.
Системи розпізнавання тексту отримали широке поширення в сфері програмного забезпечення, і зайняли свою нішу серед систем обробки зображень. Виявлення та локалізація тексту є одним з етапів розпізнавання тексту на зображенні. Активно створюються мобільні програми, основною метою яких є розпізнавання тексту, що знаходиться на зображенні (фото), подальший його переклад (програми для туристів) або отримання додаткових відомостей (пошукові системи) [10].
2. Цілі та задачі дослідження
Метою дослідження, що проводиться, є розробка ефективного методу пошуку зображень, що містять текст. До основних завдань магістерської роботи входять:
- проаналізувати існуючі методи виявлення тексту на зображеннях, виявити їх переваги та недоліки;
- виявити основні фактори, що впливають на ефективність алгоритмів;
- розробити ефективний метод пошуку зображень, які містять текст;
- довести ефективність експериментально за допомогою комп'ютерної програми.
3. Предмет і об'єкт дослідження. Плановані практичні результати
Об'єктом дослідження даної роботи є зображення, отримане з колекції. В якості предмета дослідження виступає метод пошуку зображень, що містять текст.
У рамках магістерської роботи планується отримання наступних наукових і практичних результатів:
- розробка методу пошуку зображень, які містять текст;
- створення комп'ютерної програми, яка допоможе надати оцінку розробленого методу.
4 Огляд досліджень і розробок за темі
4.1 Огляд міжнародних джерел
Проблема виявлення тексту на зображеннях є досить актуальною міжнародною темою, про що свідчить велика кількість публікацій іноземних університетів. Англомовні наукові роботи описують безліч комбінованих методів виявлення тексту на зображеннях, використовуючи різні характеристики.
Афінський університет в своїй електронній бібліотеці містить роботи "Text detection in video frames" [16], "Text Detection in Images and Videos" [17].
Рочестерський інститут технологій містить у своїй електронній базі статтю "Detection of Text in Video" [15].
Виділяються також російські університети, такі як Санкт-Петербурзький Державний університет (Васильєва Н., Дольник А., Марков І.) [1], Московський інститут прикладної математики імені М.В. Келдиша РАН (Байгарова М.С, Бухштаб Н.А., Евтеева М.М.) [2].
4.2 Огляд національних і локальних джерел.
У Донецькому національному технічному університеті дослідження з питань обробки зображень і методів пошуку зображень, що базуються на семантичному змісті зображення, здійснюються Башковим Е.А, Костюкової Н.С і Вовк О.Л. З результати досліджень можна познайомитися в джерелах [5], [6], [7], [8], [9].
Одеський політехнічний університет представляє кандидат технічних наук, доцент Ніколенко А.А. Їм представлено безліч робіт, до числа яких входить «Обнаружение текстовых областей и выделение символов на изображениях с неоднородным фоном» [3], «Обнаружение текстовых областей в видеопоследовательностях» [4].
Вінницький національний технічний університет містить у своєму електронному архіві роботи з обробки зображень: "Оцінка параметрів відеозображення в телекомунікаційних системах" [14].
5. Алгоритми, що використовуються
Очевидно, що використання традиційних методів, які використовуються для порівняння вмісту зображень, наприклад, методів, орієнтованих на використання гістограмного ознак, точкових оцінок, кластеризації та сегментації, не вирішить проблему, яка розглядається через специфіку розглянутого класу зображень. Однак традиційні методи можуть бути використані як основа, в якості окремих етапів при вирішенні даної задачі.
Задача виявлення тексту на зображеннях включає в себе такі підзадачі: виділення можливих текстових областей, визначення кута повороту тексту і визначення порядку читання для визначення логічної структури сторінки. Для виділення текстових областей існують дві групи методів: методи, які використовують гістограми, і методи, які використовують сегментацію [10].
5.1 Алгоритми попередньої обробки зображень
Для розпізнавання об'єктів можна використовувати як кольорові, так і чорно-білі зображення. У першому підході ми можемо отримати більше інформації про об'єкт, у той час як другий - може полегшити обробку зображень за часом і швидкості.
Для попередньої обробки зображень в рамках магістерської роботи будуть використовуватися алгоритм перетворення зображення з кольорового в шкалу сірих тонів (Grayscale) та бінаризація зображень.
Grayscale
Grayscale - кольоровий режим зображень, які відображаються у відтінках сірого кольору. Даний алгоритм дозволяє перевести кольорове зображення у шкалу сірих тонів. Алгоритм проходить зображення по ширині і висоті, де кожен піксель конвертується з RGB в HLS колірну модель. Потім насиченість (Saturation) знижується з 100 до 1 і знову переводимо тому. Переклад відбувається за такими рівняннями:
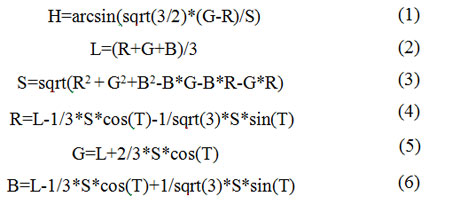
де H - тон (Hue), L - яскравість (Lightness), S - насиченість (Saturation), R - червоний (Red), G - зелений (Green), B - синій (Blue) [11].
Бінаризація
Процес бінаризації зображення заснований на порівнянні яскравості кожного пікселя B (x, y) з пороговим значенням яскравості BT (x, y); якщо значення яскравості пікселя вище значення яскравості порога, то на бінарному зображенні відповідний піксель буде «білим», або «чорним» в іншому випадку. Необхідність усунення великого числа помилок процесу бінаризації, спричинила появу великої кількості методів бінаризації: бінаризація з нижнім порогом, бінаризації з верхнім порогом, бінаризація з подвійним обмеженням, метод Отса (Оцу), метод Янні (Яні), метод середнього, метод Бернса, метод Ейквіла, метод Ніблека та інші.
Бінаризація з нижнім порогом є найбільш простою операцією, в якій використовується тільки одне значення порога:
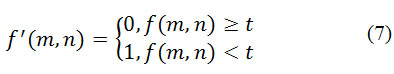
Всі значення замість критерію стають 1, в даному випадку 255 (білий) і всі значення (амплітуди) пікселів, які більше порога t – 0 (чорний) [12]. Приклад роботи алгоритму показаний на малюнку 1.

Рисунок 1 – Бінаризація з нижнім порогом
5.2 Основні методи обробки зображень
Гістограми використовуються здебільшого для виділення тексту на зображеннях формату «документ». На таких картинках текст структурований, вирівняний по сторінці і горизонтален, має схожий шрифт і, якщо присутній нахил, то однаковий для всіх рядків. Існує два способи створення гістограм: зверху - вниз, у якому при пошуку оцінюється вся сторінка цілком, і знизу - вгору, де для визначення текстових областей виділяються компоненти зв'язності - символи [10].
До першого способу відноситься метод проекцій сторінки (Projection profiles and XY cuts). Основною ідеєю методу є підрахунок чорних пікселів у виділеній рядку і створення гістограми вертикальної або горизонтальної проекцій. Потім відбувається «розрізання» областей по світлих долинах гістограми. Горизонтальні і вертикальні проекції можуть накладатися одна на одну. Після побудови проекції сторінки будується проекція для рядка, де будуються проекції для окремих слів. Метод дає добрі результати, якщо вихідний документ не містить зображень [10].
Представниками методу «знизу - вгору» є алгоритм Docstrum і алгоритм з використанням діаграм Вороного. Гістограми для цих алгоритмів будуються на підставі відстані між компонентами зв'язності: символами, словами, рядками, розділами [10].
Для виділення тексту на довільних зображеннях існує більша кількість методів, ніж для зображень типу документ. Їх можна розділити на методи, які використовують текстури (texture - based) і методи використовують області виділення (region - based) [10].
Текстура тексту явно відрізняється від текстури звичайного зображення. Для визначення ознак текстури будується «піраміда» зображень, зменшених або збільшених за розміром (рис. 2). Потім відбувається прохід по пікселям всієї групи зображень і за допомогою косинус-або вейвлет-перетворень визначаються ознаки текстури. Цей метод хороший для односпрямованих текстів з однаковим розміром шрифту [10].
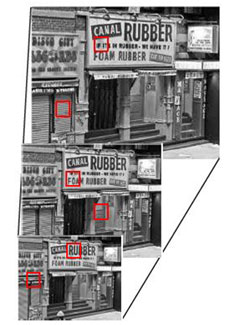
Рисунок 2 – Пірамида зображень [18]
Методи виділення країв об'єктів (Edge detection), аналізу зв'язкових компонент (CCA - Connected Component Analysis), виділення кутів (Corner detection), використання сталості ширини штриха (Stroke Width Transform) використовують велику кількість евристик , крім основних своїх показників. Дані алгоритми відносно прості в реалізації, і справляються з довільним напрямком і шрифтом тексту [10].
Для знаходження кута і повороту тексту використовують знаходження центру мас, виділення країв за допомогою матричних фільтрів Собеля, Хафа, Кенні [10].
5.3 Використання 2D-колірних гістограм і коефіцієнтів кореляції.
Для подання колірного вмісту зображення пропонується будувати гістограму, враховувати співвідношення кольорів пар пікселів (а не тільки яркостную складову). Побудовану таким чином характеристику вмісту зображення називають двовимірною колірною гістограмою (2D-колірною гістограмою). Використання такої характеристики буде особливо ефективним для кольорових зображень, що володіють такими властивостями: з одного боку, їх вміст можна назвати довільним, з іншого боку, малюнок характеризується певною повторюваністю. Прикладом таких зображень є зразки тканин, шпалер і т.п., а також зображення кольорових текстур, тексту. Очевидно, що для порівняння таких зображень слід однаковою мірою враховувати як просторовий розподіл кольорів, так і інформацію про локальному розподілі кольорів пікселів [13].
З урахуванням просторової природи вмісту розглянутих зображень 2D-колірна гістограма будується як двовимірний масив Cmax * Cmax, де Cmax – число кольорів базового набору, що використовувався на етапі квантування кольорів. Кожен елемент такої гістограми дорівнює кількості пар пікселів із заданим співвідношенням кольорів в околиці точки (для заданого шаблону) [13].
Розглянемо більш докладно алгоритм побудови 2D-колірної гістограми. Кожна з M*N точок зображення порівнюється з k точками шаблону, і в процесі цього порівняння збільшуються на одиницю k елементів 2D-колірної гістограми. Таким чином, після обробки всього зображення сума елементів 2D-колірної гістограми буде дорівнює k*M*N, а кожен її елемент буде дорівнювати кількості пар точок з заданим співвідношенням кольорів. Далі, виконаємо нормування елементів, розділивши значення кожного на кількість пар точок зображення, що дозволить нам порівнювати 2D-колірні гістограми, побудовані для зображень різних розмірів. Побудова 2D-колірної гістограми по такому алгоритму означає, що кожен її елемент H [i, j] представляє собою ймовірність присутності в зображенні пари точок з кольорами c[i] і c[j]. Якщо колірний простір, для якого виконувалося побудова базового набору кольорів c [1 .. Cmax], має властивість повноти, то, очевидно
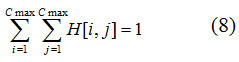
Ця характеристика являє собою матрицю, кожний елемент якої зберігає нормовану кількість пар пікселів з кольорами, відповідними індексами елемента, в околиці кожної точки. Для порівняння 2D-колірних гістограм зображень пропонується обчислювати коефіцієнт їх кореляції, так як 2D-колірна гістограма, побудована за алгоритмом, описаним вище, є випадковим вектором розмірності Cmax2 (або, іншими словами, багатовимірної випадкової величиною). Враховуючи властивості коефіцієнта кореляції, при формуванні набору результуючих зображень їх слід розміщувати в порядку зменшення коефіцієнта [13].
Механізм роботи системи пошуку зображень за змістом з використанням 2D-колірних гістограм зображений на рисунку 3.

Рисунок 3 – Система поиска изображений
(анимація: 5 кадрів, 5 циклів повторення, 150 килобайт)
Коефіцієнт кореляції (КК) - важливий показник, що показує взаємозв'язок між двома наборами даних. КК може приймати значення від -1 до +1. Негативний КК показує, що дані взаємопов'язано розходяться, при зростанні значень одних з них значення інших зменшуються, позитивний - що дані взаємопов'язано ростуть, 0 і близькі значення говорять про те, що дані не пов'язані один з одним. Формула, за якою обчислюється коефіцієнт лінійної кореляції:
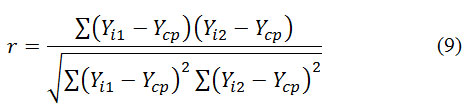
Висновки
У рамках даного реферату по темі магістерської роботи був проведений огляд існуючих методів виявлення тексту на зображеннях, методів попередньої обробки зображень, а також розглянуто метод пошуку зображень за зразком з використанням 2D-колірних гістограм. Надалі передбачається модифікувати і використовувати метод 2D-колірних гістограм для пошуку зображень, які містять текст, у великих колекціях зображень.
Реферат написаний за темою магістерської роботи, яка ще перебуває в стадії написання. Кінцева готовність магістерської роботи – грудень 2013 року.
Перелік посилань
- Васильева Н., Дольник А., Марков И. Поиск изображений. Синтез различных методов поиска при формировании результатов.//15th IEEE International Conference on Image Processing, 2008. ICIP 2008, 12-15 Oct. 2008, P. 969-972.
- Байгарова Н.С., Бухштаб Н.А., Евтеева Н.Н. Современная технология содержательного поиска в электронных коллекциях изображений.//Российский научный электронный журнал, 2001 – Том 4 – Выпуск 4.
- Николенко А.А., Тьен Т.К. Нгуен. Обнаружение текстовых областей и выделение символов на изображениях с неоднородным фоном.//Праці Одеського політехнічного університету, 2013. Вип. 1(40), с. 55-60.
- Николенко А.А., Тьен Т.К. Нгуен. Обнаружение текстовых областей в видеопоследовательностях.//«Искусственный интеллект» 4’2012, с. 227-234.
- Башков Е.А., Костюкова Н.С. К оценке эффективности поиска изображений с использованием 2d-цветовых гистограмм.//Проблемы управления и информатики, №6, 2006. с. 84-89.
- Костюкова Н.С. Применение контекстного поиска изображений при поиске графических файлов, похожих по содержанию.//7-я международная конференция «Интеллектуальный анализ информации ИАИ-2007», г.Киев, 15-18 мая 2007 г., сборник трудов. – С. 178-186.
- Башков Є.О., Вовк О.Л., Костюкова Н.С. Ефективні методи і алгоритми пошуку зображень в цифрових колекціях.//Прогресивні інформаційні технології в науці, освіті та економіці. Збірка наукових праць. – Вінниця: Вінницький кооперативний інститут, 2009. – с. 101-109.
- Башков Є.О., Вовк О.Л., Костюкова Н.С. Методи покращення результатів пошуку зображень в цифрових колекціях.//Наукові праці Донецького національного технічного університету. Серія "Інформатика, кібернетика і обчислювальна техніка" (ІКОТ-2010). Випуск 12 (165) – Донецьк: ДонНТУ. – 2010. – С. 77-81.
- Bashkov Ye.E.,Kostyukova N.S., Vovk O.L. Image retrieval in databases.//Proceedings of Donetsk National Technical University/ No1, 2010. p. 28-33.
- Сысоева Д.А. Современные подходы к поиску изображений, содержащих текст.//Інформаційні управляючі системи та комп’ютерний моніторинг (ІУС КМ – 2013) – 2013 / Матерiали IV мiжнародної науково-технiчної конференцiї студентiв, аспiрантiв та молодих вчених. – Донецьк, ДонНТУ – 2013, Том 1, с. 387-391.
- Основные алгоритмы распознавания образов/ Интернет-ресурс. – Режим доступа: http://shkolnie.ru/informatika/1879/index.html?page=2
- Сегментация изображений/Интернет-ресурс. – Режим доступа: http://habrahabr.ru/post/128768/
- Расчет коэффициента линейной корреляции /Интернет-ресурс. – Режим доступа: http://gis-lab.info/qa/correlation.html
- Михалевський Д.В., Наугольних Є.С., Мельник В.М. Оцінка параметрів відеозображення в телекомунікаційних системах.//Вимірювальна та обчислювальна техніка в технологічних процесах № 1’ 2013, с. 201-205.
- RIT Department of Computer Science Pattern Recognition/Интернет-ресурс. – Режим доступа: http://www.cs.rit.edu/~rlaz/prec2010/Snyder.pdf
- Anthimopoulos M., Gatos B., Pratikakis I. Text detection in video frames.//11th Panhellenic Conference on Informatics (PCI 2007), Patras, Greece, May 2007, pp. 361-370.
- Text Detection in Images and Videos/Интернет-ресурс. – Режим доступа: http://cgi.di.uoa.gr/~phdsbook/files/Anthimopoulos.pdf
- Обнаружение текста на изображениях/Интернет-ресурс. – Режим доступа: http://compscicenter.ru/sites/default/files/materials/2012-11-23_ImageVideoAnalysis_Lecture09.pdf