
 Рисунок 1 – Архитектурный граф многослойного персептрона
Рисунок 1 – Архитектурный граф многослойного персептрона
Русский |
Українська |
English
Реферат по теме выпускной работы
- Введение
- Цель и задачи исследования
- Предполагаемая научная новизна
- Планируемые практические результаты
- 1. Обзор исследований и разработок по теме
- 1.1 Мировой уровень
- 1.2 Национальный уровень
- 1.3 Локальный уровень
- 2. Основное содержание работы
- 2.1 Структура современной системы распознавания речи
- 2.2 Подходы к распознаванию фонем
- 2.3 Нейросетевые архитектуры
- 2.4 Практический эксперимент
- Выводы
- Список использованной литературы
Введение
В настоящее время существует широкий спектр практических задач, в которых целесообразно применение систем распознавания речи. Среди них можно выделить: • системы голосового управления для Интернета вещей; • автоматизированные call-центры; • поиск по видео и звуковым файлам; • автоматизированный перевод информации между разными ее формами.
За последние шестьдесят лет системы распознавания речи прошли огромнейший путь развития от распознавания десятка слов сказанных одним диктором, до дикторонезависимых систем с возможностью распознавания сотен тысяч слов.
За это время сформировалась типичная структура системы распознавания речи. Такая система состоит из двух больших блоков: акустико-фонетического, отвечающего за представление речевого сигнала, и лингвистического, отвечающего за интерпретацию получаемой от акустической модели информации и представление конечного результата пользователю.
Если лингвистические алгоритмы (N-граммы для языковых моделей, алгоритм Витерби, Баума-Вешна, прямого-обратного хода) проработаны хорошо и не требуют улучшений, то алгоритмы акустико-фонетического блока еще пока недостаточно хороши, и имеют потенциал для дальнейшего усовершенствования, что подтверждается современными результатами дикторонезависимого распознавания фонем. Таким образом разработка новых более эффективных алгоритмов распознавания фонем является актуальной задачей. В контексте исследований последних лет представляется эффективным использовать для ее решения гибридную нейронную сеть на основе байесовских сетей доверия.
Цель и задачи исследования
Ввиду выше изложенного была поставлена цель – создать систему распознавания устной речи на базе гибридной модели, в основе которой бы находились байесовские сети доверия.
В соответствии с поставленной целью требуется решить такие задачи:
1. Изучить структуру современной системы распознавания речи. 2. Изучить подходы к распознаванию речи. 3. Проанализировать существующие методы распознавания речи. 4. Разработать новую более эффективную модель распознавания речи. 5. Применить данную модель для распознавания украинской речи. 6. Разработать приложение для распознавания речи.
Предполагаемая научная новизна
В данной магистерской работе будут использованы байесовские сети доверия в связке с КДП подходом Т. Винцюка, а не с традиционными скрытыми Марковскими моделями. Также впервые байесовские сети доверия будут использованы для распознавания устной украинской речи, и такая гибридная модель превзойдет показатели распознавания аналогичных существующих моделей.
Планируемые практические результаты
В результате данной работы планируется создание программной системы, способной осуществлять распознавание речи. Данная программная система найдет применение для широкого круга задач.
1. Обзор исследований и разработок по теме
О том, что рассматриваемая тема популярна как в отечественном, так и в мировом научном сообществе свидетельствует большое количество исследований и разработок. Чтобы лучше понять современные реалии распознавания речи, рассмотрим эти исследования и разработки в хронологическом порядке.
1.1 Мировой уровень
Первой системой распознавания речи была “Audrey” от Bell Laboratories, появившаяся в 1952 году. Она могла понимать только цифры, сказанные одним голосом. Через 10 лет IBM выпустили “Shoebox”, понимавшую уже 16 слов на английском [1]. Благодаря поддержке министерства обороны США, в семидесятых годах системы распознавания речи получили значительное развитие. Программа DARPA Speech Understanding Research с 1971 по 1976 год была одной из самой большой в истории распознавания речи. Также в то время существовала система «Harpy» Университета Карнеги Меллона, которая понимала 1011 слов, что является средним словарным запасом трехлетнего ребенка. «Harpy» была значительной вехой, так как она представила более эффективный подход к поиску, называемый Beam search, «демонстрируя сеть возможных предложений с конечным числом состояний».
В следующей декаде благодаря новым подходам и технологиям словарный запас подобных систем вырос с нескольких сотен до нескольких тысяч слов и имел потенциал распознавания неограниченного количества слов. Одной из причин был новый статистический метод, больше известный как скрытая марковская модель. С этих пор принято отсчитывать начало эры коммерческих систем распознавания речи. Начиная с девяностых годов двадцатого века, с появлением быстрых и мощных процессоров, системы автоматизированного распознавания речи стали внедряться повсеместно, но их качество оставляло желать лучшего. Тем не менее, развитие методов распознавания образов привело к тому, что к 2001 году удалось достичь 80-процентной точности распознавания, и акцент в исследованиях по данной теме сместился в сторону построения систем, которые бы могли распознавать речь не только по голосу, но и по смыслу. На сегодняшний день благодаря развитию параллельных и облачных вычислений, а также улучшению и разработке новых алгоритмов и моделей распознавания речи, появилась возможность внедрить системы голосового управления в мобильные устройства. Среди таких систем следует выделить Apple Siri и Google Voice Search, которые благодаря своему довольно высокому качеству задали моду на голосовое управление устройствами и тем самым помогли преодолеть некоторый застой, образовавшийся в данной области научных исследований в середине нулевых годов двадцать первого века.
Как видим, распознавание речи переживает в наше время свой расцвет. Это в частности означает широкий спектр методов, применяемых в данной области научных исследований. Существующие методы и алгоритмы распознавания речи можно разделить на три класса: • Динамическое программирование (Dynamic Time Warping). • Скрытые Марковские модели. • Нейронные сети.
Так как данное исследование опирается на разработки в области нейронных сетей, в частности, байесовских сетей доверия, то далее будет проведен обзор современных исследований и разработок в области нейронных байесовских сетей.
В научном сообществе большим энтузиастом байесовских сетей доверия является профессор университета Торонто Джеффри Хинтон. В своих работах [2,3], и работах его студентов[4,5] часто используются указанные сети в связке с ограниченной машиной Больцмана.
Также байесовские сети доверия при разработке своих систем используют такие американские корпорации, как Microsoft (для своего переводчика устного текста в режиме реального времени), Google (для голосового поиска) и российская компания Yandex (для своей библиотеки распознавания речи Yandex SpeechKit [6]).
1.2 Национальный уровень
В распознавании образов Украина имеет некоторые значительные достижения, в основном связанные с именем Тараса Климовича Винцюка. Лидер в области речевых технологий в Украине — отдел распознавания звуковых образов Международного научно-учебного центра информационных технологий и систем. С конца 1960х годов в отделе (тогда при Институте Кибернетики им. Глушкова) под руководством Т.К. Винцюка (с 1988 по 2012) ведутся работы по распознаванию речи. Именно Тарасу Климовичу Винцюку принадлежит авторство генеративной модели распознавания образов, известной как Dynamic Time Wraping (DTW). При Международном научно-учебном центре информационных технологий и систем проводится конференции «УкрОбраз», посвященная распознаванию образов, а также ежегодные летние школы-семинары, посвященные речевым технологиям.
1.3 Локальный уровень
В Донецком национальном техническом университете исследования, связанные с распознаванием устной речи, ведутся на кафедре прикладной математики и информатики под руководством Олега Ивановича Федяева. Отдельно стоит отметить работы аспиранта этой кафедры Ивана Юрьевича Бондаренко [7]. Также данной проблемой занимаются студенты и аспиранты кафедры систем искусственного интеллекта под руководством Владислава Юрьевича Шелепова. С наиболее значительными работами магистров ДонНТУ по данной теме можно ознакомиться в библиотеке.
2. Основное содержание работы
2.1 Структура современной системы распознавания речи
Архитектура современной системы автоматического распознавания речи состоит из типичных блоков [8]:
• Модуль шумоочистки и отделение полезного сигнала. • Акустико-фонетическая модель, которая позволяет оценить распознавание речевого сегмента с точки зрения схожести на звуковом уровне. Для каждого звука изначально строится сложная статистическая модель, которая описывает произнесение этого звука в речи. • Лингвистическая модель — позволяет определить наиболее вероятные словные последовательности. Сложность построения языковой модели во многом зависит от конкретного языка. Так, для английского языка, достаточно использовать статистические модели (так называемые N-граммы). Для высокофлективных языков (языков, в которых существует много форм одного и того же слова), к которым относится и украинский, языковые модели, построенные только с использованием статистики, уже не дают такого эффекта — слишком много нужно данных, чтобы достоверно оценить статистические связи между словами. Поэтому применяют гибридные языковые модели, использующие правила русского языка, информацию о части речи и форме слова и классическую статистическую модель. • Декодер — программный компонент системы распознавания, который совмещает данные, получаемые в ходе распознавания от акустических и языковых моделей, и на основании их объединения определяет наиболее вероятную последовательность слов, которая и является конечным результатом распознавания слитной речи.
Процесс работы описанной системы состоит из нескольких этапов [9]. Сначала оценивается качество речевого сигнала. На этом этапе определяется уровень помех и искажений. Далее результат оценки поступает в модуль акустической адаптации, который управляет модулем расчета параметров речи, необходимых для распознавания. В сигнале выделяются участки, содержащие речь, и происходит оценка параметров речи. Происходит выделение фонетических вероятностных характеристик для синтаксического, семантического и прагматического анализа, осуществляемого лингвистическим блоком. Далее параметры речи поступают в последний блок системы распознавания — декодер. И результат работы системы представляется пользователю.
Как было указано выше, главный интерес представляют методы повышения эффективности акустико-фонетической модели, так как лингвистический блок окажется бесполезен, если не будет достигнута необходимая точность акустического распознавания речи. Далее подробнее остановимся на алгоритмах акустико-фонетического блока.
2.2 Подходы к распознаванию фонем
Существует два подхода к распознаванию фонем: генеративный (скрытые марковские модели, Гауссовы смеси и КПД-подход Винцюка) и дискриминативный (нейронные сети, метод опорных векторов). Принцип работы генеративных алгоритмов заключается в генерации максимально правдоподобных эталонных сигналов на основе некоторой автоматной грамматики и сопоставление полученных эталонов с распознаваемым речевым сигналом. Такой подход позволяет очень эффективно моделировать нелинейно изменяющиеся во времени процессы. Но в тоже время дикриминативная способность алгоритмов данного класса не высока, в отличии от алгоритмов второго описываемого здесь класса.
Дискриминативные алгоритмы с помощью разделяющих плоскостей разбивают образцы по классам в пространстве признаков [10]. Рассматривая наиболее популярный математический аппарат для разработки дискриминативных алгоритмов, нейронные сети, следует также сказать о том, что нейронные сети обладают высокой степенью параллелизма, а поэтому имеют хорошие скоростные характеристики. В качестве недостатка дискриминативных алгоритмов следует отметить их низкую эффективность в распознавании меняющихся во времени образов. Но так как фонемы во времени стационарны и не так сильно изменяются как целые слова, то данный недостаток можно опустить в рамках решаемой задачи.
2.3 Нейросетевые архитектуры
Рассмотрим один из возможных вариантов в рамках дискриминативного подхода – нейросетевую архитектуру многослойный персептрон. Отметим особенности данной архитектуры. Многослойный персептрон является одной из самых распространённых на сегодняшний день нейронной сетью. Она представляет собой полносвязную слоистую нейронную сеть [11]. В качестве параметров слои получают вектор выходных значений предыдущего слоя, а их выходные сигналы формируют вектор входных сигналов следующего слоя. Функциональный сигнал y на выходе нейрона j на итерации n равен. Архитектурный граф многослойного персептрона с одним скрытым слоем представлен на рисунке 1 [13].
Рисунок 1 – Архитектурный граф многослойного персептрона
Задача обучения многослойного персептрона сводится к эквилибровке весов синаптических соединений таким способом, чтобы на выходе получить нужное отображение входных сигналов [12]. В качестве алгоритма используют метод обратного распространения ошибки. Данный метод представляет собой итеративный градиентный алгоритм обучения с учителем, проводящий сигнал ошибки, вычисленный выходами персептрона, к его входам, слой за слоем.
Обозначим желаемый отклик нейрона j на итерации n как j(n). Тогда сигнал ошибки выходного нейрона j при обработке n-го примера можно записать как
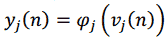
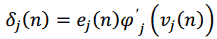
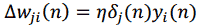
Описанный выше алгоритм позволяет обучить все слои нейронной сети, тем самым позволяя решать с помощью нейронных сетей очень сложные задачи (например такие как распознавание устной и письменной речи). Но c ростом количества слоев сети экспоненциально растет сложность требуемых вычислений, а значит и ресурсов, требуемых для обучения.
Решение данной проблемы видится в нахождении более эффективных нейросетевых архитектур и алгоритмов их обучения. Есть несколько вариантов решения этой проблемы: использование алгоритмов обучения, позволяющих выходить из локальных минимумов, использование неполносвязных нейронных сетей (Сверточные нейронные сети, нейронные сети с временной задержкой), использование специальных алгоритмов инициализации многослойных сетей, основанных на байесовских алгоритмах. Такие алгоритмы обучают сеть послойно и последовательно без учителя. Алгоритм заключается в том, чтобы рассматривать сначала сеть как байесовскую сеть доверия и предобучить ее без учителя. А когда значения весов будут близки к значениям функции правдоподобия, то доучить такую сеть как многослойный персептрон алгоритмом обратного распространения ошибки [14]. Работа алгоритма представлена на рисунке 2.
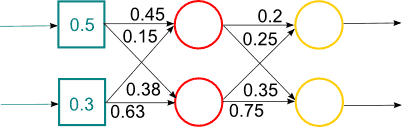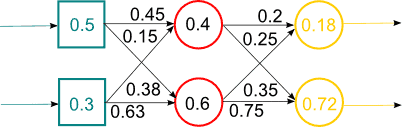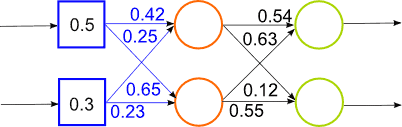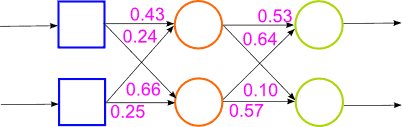 Рисунок 2 – Работа гибридной нейронной сети (анимация, 14 кадров, 15 повторений, 65,8 Кбайт)
Рисунок 2 – Работа гибридной нейронной сети (анимация, 14 кадров, 15 повторений, 65,8 Кбайт)
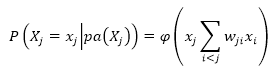
Алгоритм обучения сетей доверия основан на методе градиентного спуска в пространстве вероятностей с использованием только локально доступной информации. Спуск осуществляется с помощью определения пошагового изменения синаптических весов w_ji.
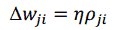
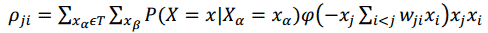
2.4 Практический эксперимент
В качестве эксперимента были написаны две программы для обучения многослойного персептрона и сигмоидальной сети доверия задаче XOR. Обе программы базируются на одном и том же интерфейсе сети. Программа работает по описанным выше алгоритмам обучения сетей. В качестве желаемого коэффициента ошибки было выбрано число 0,01. Обучение в обоих случаях происходило онлайн режиме – веса корректировались после каждой эпохи обучения. Во второй подпрограмме сигмоидальная сеть доверия используется как механизм переобучения сети решению задачи XOR. В этой программе сеть сначала обучалась без учителя, а затем до обучалась с учителем уже как многослойный персептрон методом обратного распространения ошибки. На первом этапе обучения веса сети приводились в квазиоптимальное положение, что способствовало более быстрому обучению на следующем этапе.
В результате эксперимента было выяснено, что для обучения многослойному персептрону понадобилось 228 эпох обучения. В тоже время как сигмоидальной сети доверия с постобучением понадобилось 106 эпох. Графики изменения средней ошибки по эпохам представлены на рисунке 2.
 Рисунок 3 — Результаты эксперимента
Рисунок 3 — Результаты эксперимента
Выводы
По результатам анализа существующих на сегодняшний день разработок можно сделать вывод, что гибридный подход использования сетей доверия и многослойного персептрона является эффективным инструментом для решения задачи классификации в целом и задачи распознавания устной речи в частности. Такой вывод сделан по результатам практического эксперимента, где было наглядно показано, что при использовании многослойного персептрона в связке с байесовскими сетями доверия, время обучения сети ускоряется в 2 раза. Это означает, что данный поход требует дальнейшего изучения и усовершенствования алгоритмов обучения, чтобы использовать данную нейросетевую архитектуру максимально эффективно для распознавания речи.
Направление дальнейших исследований должно касаться поиска подхода в применении байесовских сетей доверия для построения акустико-фонетической модели распознавания речи и применении данной модели для распознавания украинской речи.
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: декабрь 2014 года. Полный текст работы и материалы по теме могут быть получены у автора после указанной даты.
Список использованной литературы
[1] Александр Пасечник История развития систем распознавания речи: как мы пришли к Siri [Электронный ресурс] – [Режим доступа:] http://habrahabr.ru/post/131945/ [2] Geoffrey Hinton. NISP tutorial on deep belief nets. – Canadian Institute for Advanced Research, 2007. – 100 p. [3] Geoffrey Hinton. To recognize shapes, first learn to generate images. — In P. Cisek, T. Drew and J. Kalaska (Eds.) Computational Neuroscience: Theoretical Insights into Brain Function. Elsevier., 2006. — pp. 17-34. [4] Deng, L., Hinton, G. E. and Kingsbury, B. New types of deep neural network learning for speech recognition and related applications: An overview – IEEE International Conference on Acoustic Speech and Signal Processing (ICASSP 2013) – Vancouver, 2013. – pp. 8599-8603. [5] Abdel-rahman Mohamed, Geoffrey Hinton, Gerald Penn. Understanding how Deep Belief Nets perform acoustic modeling. – ICASSP, 2012 – pp. 4273-4276. [6] Распознавание речи от Яндекса. Под капотом у Yandex.SpeechKit. [Электронный ресурс] [Режим доступа:] http://habrahabr.ru/company/yandex/blog/198556/ [7] О.І.Федяєв, І.Ю.Бондаренко. Розробка і дослідження нейромережевого алгоритму дикторонезалежного розпізнавання фонем в усному мовленні // Праці Одинадцятої всеукраїнської міжнародної конференції з оброблення сигналів і зображень та розпізнавання образів УкрОБРАЗ'2012. — К.: МННЦ ІТ та С, 2012. — С.71-74. [8] А.Л. Ронжин, А.А. Карпов, И.В. Ли Система автоматического распознавания русской речи SIRIUS — Искусственный интеллект выпуск 3, 2010. – C. 590-601. [9] T. Dutoit Reconnaissance automatique de la parole — Techniques de l’Ingénieur, 2010. – pp. 401-404. [10] С. Хайкин. Нейронные сети: полный курс, 2-е издание, : Пер. с англ. — М.: Издательский дом «Вильямс», 2006. — 1104 с. [11] Hinton, G., Deng, L., Yu, D., Dahl, G. E. et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. – Signal Processing Magazine, IEEE, 2012. – pp. 82-97. [12] Rasmus Berg Palm. Prediction as a candidate for learning deep hierarchical models of data. – Technical University of Denmark, 2012. – 80 p. [13] Брынза Т.А, Бондаренко И.Ю. Сигмоидальные сети доверия в решении задач классификации – Труды IV международной конференции «Информационно-управляющие системы и компьютерный мониторинг», 2013. – C. 422-427. [14] Брынза Т.А., Бондаренко И.Ю., Губенко Н.Е. Представление байесовских сетей доверия для решения задачи распознавания образов. – Труды IX международной научно-технической конференции студентов, аспирантов, молодых ученых «Информатика и компьютерные технологии», 2013. – C. 304-308. [15] Linda Otmani, Abdelkader Benyettou. Les réseaux neuro-bayésiens appliqués à la reconnaissance de la parole. – Université des sciences et de technologie d’ORAN -Mohamed Boudiaf- faculté des sciences, département d’informatique, 2007. – 7 p. [16] Gregoire Montavon. Deep learning for spoken language identification. – Machine Learning Group, Berlin Institute of Technology Germany, 2005. – 4 p. [17] Hinton, G.E., Dayan, P., Frey, B.J. & Neal, R. The wake-sleep algorithm for self-organizing neural network. — Science, 1995. — P. 1158-1161.