
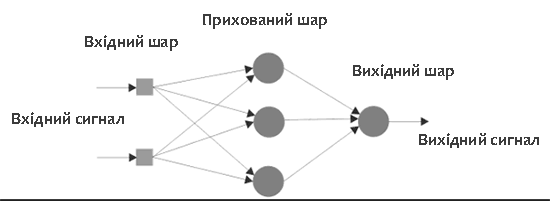
 Рисунок 1 – Архітектурний граф багатошарового персептрона
Рисунок 1 – Архітектурний граф багатошарового персептрона
Реферат за темою випускної роботи
- Вступ
- Мета і задачі дослідження
- Передбачувана наукова новизна
- Заплановані практичні результати
- 1. Огляд досліджень і розробок по темі
- 1.1 Світовий рівень
- 1.2 Національний рівень
- 1.3 Локальний рівень
- 2. Основний зміст роботи
- 2.1 Структура сучасної системи розпізнавання мови
- 2.2 Підходи до розпізнавання фонем
- 2.3 Нейромережеві архітектури
- 2.4 Практичний експеримент
- Висновки
- Список використаної літератури
Вступ
В даний час існує широкий спектр практичних завдань, в яких є доцільним застосування систем розпізнавання мови. Серед них можна виділити: • системи голосового управління для Інтернету речей; • автоматизовані call-центри; • пошук по відео і звуковим файлам; • автоматизований переклад інформації між різними її формами.
За останні шістдесят років системи розпізнавання мови пройшли величезний шлях розвитку від розпізнавання десятка слів сказаних одним диктором, до дикторонезалежних систем з можливістю розпізнавання сотень тисяч слів.
За останні шістдесят років системи розпізнавання мови пройшли величезний шлях розвитку від розпізнавання десятка слів сказаних одним диктором, до дикторонезалежних систем з можливістю розпізнавання сотень тисяч слів.
За цей час сформувалася типова структура системи розпізнавання мови. Така система складається з двох великих блоків: акустико-фонетичного, відповідального за подання мовного сигналу, і лінгвістичного, що відповідає за інтерпретацію одержуваної від акустичної моделі інформації та представлення кінцевого результату користувачеві.
Якщо лінгвістичні алгоритми (N-грами для мовних моделей , алгоритм Вітербі, Баума-Вешна, прямого-зворотнього ходу) опрацьовані добре і не вимагають поліпшень, то алгоритми акустико-фонетичного блоку ще поки недостатньо ефективні, і мають потенціал для подальшого удосконалення, що підтверджується сучасними результатами дикторонезалежного розпізнавання фонем. Таким чином розробка нових більш ефективних алгоритмів розпізнавання фонем є актуальним завданням. У контексті досліджень останніх років представляється ефективним використовувати для її вирішення гібридну нейронну мережу на основі байєсівських мереж довіри.
Мета і задачі дослідження
Зважаючи на написане вище, була поставлена мета — створити систему розпізнавання усного мовлення на базі гібридної моделі, в основі якої б знаходилися байєсовські мережі довіри.
У відповідності з поставленою метою потрібно вирішити такі завдання:
1. Вивчити структуру сучасної системи розпізнавання мови. 2. Вивчити підходи до розпізнавання мови. 3. Проаналізувати існуючі методи розпізнавання мови. 4. Розробити нову більш ефективну модель розпізнавання мови. 5. Застосувати дану модель для розпізнавання української мови. 6. Розробити додаток для розпізнавання мови.
Передбачувана наукова новизна
У даній магістерській роботі будуть використані байєсовські мережі довіри в зв'язці з КДП підходом Т. Вінцюка, а не з традиційними прихованими марківськими моделями. Також вперше байєсовські мережі довіри будуть використані для розпізнавання усної української мови, і така гібридна модель перевершить показники розпізнавання аналогічних існуючих моделей.
Заплановані практичні результати
В результаті даної роботи планується створення програмної системи, здатної здійснювати розпізнавання мови. Дана програмна система знайде застосування для широкого кола завдань.
1. Огляд досліджень і розробок по темі
Про те, що розглянута тема популярна як у вітчизняному, так і в світовому науковому співтоваристві свідчить велика кількість досліджень і розробок. Щоб краще зрозуміти сучасні реалії розпізнавання мови, розглянемо ці дослідження і розробки в хронологічному порядку.
1.1 Світовий рівень
Першої системою розпізнавання мови була "Audrey" від Bell Laboratories, що з'явилася в 1952 році. Вона могла розуміти тільки цифри, сказані одним голосом. Через 10 років IBM випустили " Shoebox ", яка розуміла вже 16 слів англійською [ 1 ]. Завдяки підтримці міністерства оборони США, в сімдесятих роках системи розпізнавання мови отримали значний розвиток. Програма DARPA Speech Understanding Research з 1971 по 1976 рік була однією з найбільшої в історії розпізнавання мови. Також у той час існувала система «Harpy» Університету Карнегі Меллона, яка розуміла 1011 слів, що є середнім словниковим запасом трирічної дитини. «Harpy» була значною віхою, так як вона представила більш ефективний підхід до пошуку званий Beam search, «демонструючи мережу можливих пропозицій з кінцевим числом станів».
У наступній декаді завдяки новим підходам і технологіям словниковий запас подібних систем виріс з декількох сотень до декількох тисяч слів і мав потенціал розпізнавання необмеженої кількості слів. Однією з причин був новий статистичний метод, більше відомий як прихована марківських модель. З цих пір прийнято відраховувати початок ери комерційних систем розпізнавання мови. Починаючи з дев'яностих років двадцятого століття, з появою швидких і потужних процесорів, системи автоматизованого розпізнавання мови стали впроваджуватися повсюдно, але їх якість залишала бажати кращого. Проте, розвиток методів розпізнавання образів призвів до того, що до 2001 року вдалося досягти 80-відсоткової точності розпізнавання, і акцент у дослідженнях з даної теми змістився в бік побудови систем, які б могли розпізнавати мову не тільки по голосу, а й по змісту. На сьогоднішній день завдяки розвитку паралельних і хмарних обчислень, а також поліпшенню і розробці нових алгоритмів і моделей розпізнавання мови, з'явилася можливість впровадити системи голосового управління в мобільні пристрої. Серед таких систем слід виділити Apple Siri і Google Voice Search, які завдяки своїй досить високій якості задали моду на голосове управління пристроями і тим самим допомогли подолати деякий застій, що утворився в даній галузі наукових досліджень в середині нульових років двадцять першого століття.
Як бачимо, розпізнавання мови переживає в наш час свій розквіт. Це зокрема означає широкий спектр методів, застосовуваних у даній галузі наукових досліджень. Існуючі методи та алгоритми розпізнавання мови можна розділити на три класи: • Динамічне програмування (Dynamic Time Warping). • Приховані марківські моделі. • Нейронні мережі.
Оскільки дане дослідження спирається на розробки в області нейронних мереж, зокрема, байєсівських мереж довіри, то далі буде проведено огляд сучасних досліджень і розробок в області нейронних байєсівських мереж.
У науковому співтоваристві великим ентузіастом байєсівських мереж довіри є професор університету Торонто Джеффрі Хінтон. У своїх роботах [2,3], і роботах його студентів [4,5] часто використовуються зазначені мережі в зв'язці з обмеженою машиною Больцмана.
Також байєсовські мережі довіри при розробці своїх систем використовують такі американські корпорації, як Microsoft (для свого перекладача усного тексту в режимі реального часу), Google ( для голосового пошуку) і російська компанія Yandex ( для своєї бібліотеки розпізнавання мови Yandex SpeechKit [ 6 ]).
1.2 Національний рівень
У розпізнаванні образів Україна має деякі значні досягнення, в основному пов'язані з ім'ям Тараса Климовича Вінцюка. Лідер в області мовних технологій в Україні -відділ розпізнавання звукових образів Міжнародного науково-навчального центру інформаційних технологій і систем. З кінця 1960х років у відділі (тоді при Інституті кібернетики ім. Глушкова) під керівництвом Т.К. Вінцюка (з 1988 по 2012) ведуться роботи з розпізнавання мови. Саме Тарасу Климович Вінцюк належить авторство генеративної моделі розпізнавання образів, відомої як Dynamic Time Wraping (DTW). При Міжнародному науков-навчальному центрі інформаційних технологій та систем проводиться конференції «УкрОбраз», присвячена розпізнаванню образів, а також щорічні літні школи-семінари, присвячені мовним технологіям.
1.3 Локальний рівень
У Донецькому національному технічному університеті дослідження, пов'язані з розпізнаванням усного мовлення, ведуться на кафедрі прикладної математики та інформатики під керівництвом Олега Івановича Федяєва. Окремо варто відзначити роботи аспіранта цієї кафедри Івана Юрійовича Бондаренко [ 7 ]. Також даною проблемою займаються студенти та аспіранти кафедри систем штучного інтелекту під керівництвом Владислава Юрійовича Шелепова. З найбільш значними роботами магістрів ДонНТУ з даної теми можна ознайомитися в бібліотеці.
2. Основний зміст роботи
2.1 Структура сучасної системи розпізнавання мови
Архітектура сучасної системи автоматичного розпізнавання мови складається з типових блоків [8]:
• Модуль шумоочистки і відділення корисного сигналу. • Акустико-фонетична модель, яка дозволяє оцінити розпізнавання мовного сегмента з точки зору схожості на звуковому рівні. Для кожного звуку спочатку будується складна статистична модель, яка описує проголошення цього звуку. • Лінгвістична модель — дозволяє визначити найбільш ймовірні немов послідовності. Складність побудови мовної моделі багато в чому залежить від конкретної мови. Так, для англійської мови, досить використовувати статистичні моделі (так звані N- грами). Для високофлектівних мов (мов, в яких існує багато форм одного і того ж слова), до яких належить і українська, мовні моделі, побудовані тільки з використанням статистики, вже не дають такого ефекту — занадто багато треба даних, щоб достовірно оцінити статистичні зв'язки між словами. Тому застосовують гібридні мовні моделі, що використовують правила російської мови, інформацію про частини мови і формі слова і класичну статистичну модель. • Декодер — програмний компонент системи розпізнавання, який поєднує дані, одержувані в ході розпізнавання від акустичних та лінгвістичних моделей, і на підставі їх об'єднання визначає найбільш ймовірну послідовність слів, яка і є кінцевим результатом розпізнавання злитого мовлення.
Процес роботи описаної системи складається з декількох етапів [9]. Спочатку оцінюється якість мовного сигналу. На цьому етапі визначається рівень перешкод і спотворень. Далі результат оцінки надходить в модуль акустичної адаптації, який управляє модулем розрахунку параметрів мови, необхідних для розпізнавання. У сигналі виділяються ділянки, що містять мову, і відбувається оцінка параметрів мови. Відбувається виділення фонетичних імовірнісних характеристик для синтаксичного, семантичного та прагматичного аналізу, здійснюваного лінгвістичним блоком. Далі параметри мовлення надходять в останній блок системи розпізнавання — декодер. І результат роботи системи представляється користувачеві.
Як було зазначено вище, головний інтерес представляють методи підвищення ефективності акустико- фонетичної моделі, так як лінгвістичний блок виявиться марний, якщо не буде досягнута необхідна точність акустичного розпізнавання мови. Далі докладніше зупинимося на алгоритмах акустико-фонетичного блоку.
2.2 Підходи до розпізнавання фонем
Існують два підходи до розпізнавання фонем: генеративний (приховані марковские моделі, гаусові суміші і КДП-підхід Вінцюка) і дискримінативний (нейронні мережі, метод опорних векторів). Принцип роботи генеративних алгоритмів полягає в генерації максимально правдоподібних еталонних сигналів на основі деякої автоматної граматики і зіставлення отриманих еталонів з розпізнаваним мовним сигналом. Такий підхід дозволяє дуже ефективно моделювати нелінійно змінюються в часі процеси. Але в теж час дікрімінативна здатність алгоритмів даного класу не висока, на відміну від алгоритмів другого описуваного тут класу.
Діскрімінативні алгоритми за допомогою розділячих площин розбивають зразки по класах в просторі ознак [10]. Розглядаючи найбільш популярний математичний апарат для розробки діскримінативних алгоритмів, нейронні мережі, слід також сказати про те, що нейронні мережі мають високий ступінь паралелізму, а тому мають хороші швидкісні характеристики. Як недолік діскрімінатівних алгоритмів слід відзначити їх низьку ефективність в розпізнаванні мінливих в часі образів. Але так як фонеми в часі стаціонарні і не так сильно змінюються як цілі слова, то даний недолік можна опустити в рамках розв'язуваної задачі.
2.3 Нейромережеві архітектури
Розглянемо один з можливих варіантів в рамках дискримінативного підходу — нейромережеву архітектуру багатошаровий персептрон. Відзначимо особливості даної архітектури. Багатошаровий персептрон є однією з найпоширеніших на сьогоднішній день нейронною мережею. Вона являє собою повнозв'язну шарову нейронну мережу [11]. У якості параметрів шари отримують вектор вихідних значень попереднього шару, а їх вихідні сигнали формують вектор вхідних сигналів наступного шару. Функціональний сигнал на виході нейрона j на ітерації n дорівнює. Архітектурний граф багатошарового персептрона з одним прихованим шаром представлений на рисунку 1 [13].
Рисунок 1 – Архітектурний граф багатошарового персептрона
Задача навчання багатошарового персептрона зводиться до еквілібровки ваг зв'язків синаптичних з'єднань таким способом, щоб на виході отримати потрібне відображення вхідних сигналів [12]. Як алгоритм навчання використовують метод зворотного поширення помилки. Даний метод являє собою ітеративний градієнтний алгоритм навчання з вчителем, який проводить сигнал помилки, обчислений виходами персептрона, до його входів, шар за шаром.
Позначимо бажаний відгук нейрона j на ітерації n як j ( n ). Тоді сигнал помилки вихідного нейрона j при обробці n -го прикладу можна записати як
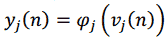
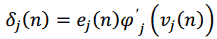
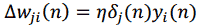
Описаний вище алгоритм дозволяє навчити всі шари нейронної мережі, тим самим дозволяючи вирішувати за допомогою нейронних мереж дуже складні завдання (наприклад такі як розпізнавання усної і письмової мові). Але із зростанням кількості шарів мережі експоненціально зростає складність необхідних обчислень, а значить і ресурсів, необхідних для навчання.
Рішення даної проблеми вбачається в знаходженні більш ефективних нейромережевих архітектур і алгоритмів їх навчання. Є кілька варіантів вирішення цієї проблеми: використання алгоритмів навчання, що дозволяють виходити з локальних мінімумів, використання неповнозв'язних нейронних мереж (згортальні нейронні мережі, нейронні мережі з тимчасовою затримкою), використання спеціальних алгоритмів ініціалізації багатошарових мереж, заснованих на байєсівських алгоритмах. Такі алгоритми навчають мережу пошарово і послідовно без вчителя. Алгоритм полягає в тому, щоб розглядати спочатку мережу як байєсівську мережу довіри і преднавчають її без вчителя. А коли значення ваг будуть близькі до значень функції правдоподібності, то довчити таку мережу як багатошаровий персептрон алгоритмом зворотного поширення помилки [14]. Робота алгоритму представлена на рисунку 2.
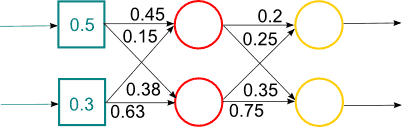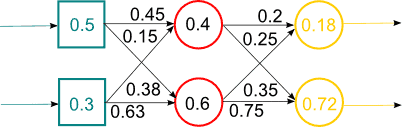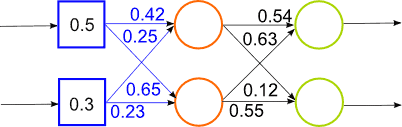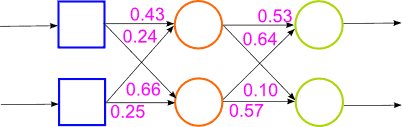 Рисунок 2 — Робота гібридної нейронної мережі (анімація, 14 кадрів, 15 повторень, 65,8 Кбайт)
Рисунок 2 — Робота гібридної нейронної мережі (анімація, 14 кадрів, 15 повторень, 65,8 Кбайт)
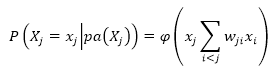
Алгоритм навчання мереж довіри заснований на методі градієнтного спуску в простір ймовірностей з використанням тільки локально доступної інформації. Спуск здійснюється за допомогою визначення покрокової зміни синаптичних ваг w_ji.
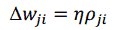
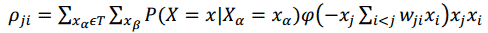
2.4 Практичний експеримент
В якості експерименту були написані дві програми для навчання багатошарового персептрона і сигмоїдальної мережі довіри задачі XOR. Обидві програми базуються на одному і тому ж інтерфейсі мережі. Програма працює за описаним вище алгоритмом навчання мереж. В якості бажаного коефіцієнта помилки було вибрано число 0,01. Навчання в обох випадках відбувалося в онлайн режимі — ваги коригувалися після кожної епохи навчання. У другій підпрограмі сигмоїдальна мережа довіри використовується як механізм перенавчання мережі вирішення задачі XOR. У цій програмі мережу спочатку навчали без вчителя, а потім до навчали з учителем вже як багатошаровий персептрон методом зворотнього поширення помилки. На першому етапі навчання ваги мережі виводилися в квазіоптимальне положення, що сприяло більш швидкому навчанню на наступному етапі.
В результаті експерименту було з'ясовано, що для навчання багатошаровому персептрону знадобилося 228 епох навчання. У тей час як сигмоїдальній мережі довіри з постнавчанням знадобилося 106 епох. Графіки зміни середньої помилки по епохам представлені на рисунку 2.
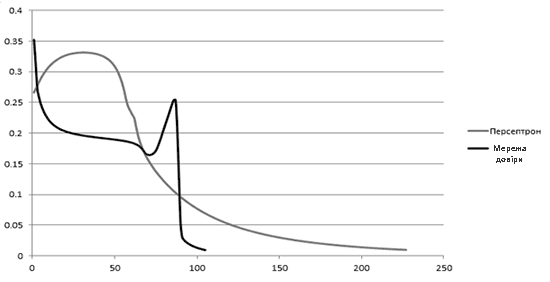 Рисунок 3 — Результати експерименту
Рисунок 3 — Результати експерименту
Висновки
За результатами аналізу існуючих на сьогоднішній день розробок можна зробити висновок, що гібридний підхід використання мереж довіри і багатошарового персептрона є ефективним інструментом для вирішення задачі класифікації в цілому і завдання розпізнавання усного мовлення зокрема. Такий висновок зроблено за результатами практичного експерименту, де було наочно показано, що при використанні багатошарового персептрона в зв`язці з байесовськими мережами довіри, час навчання мережі прискорюється в 2 рази. Це означає, що даний підхід вимагає подальшого вивчення та удосконалення алгоритмів навчання, щоб використовувати дану нейромережеву архітектуру максимально ефективно для розпізнавання мови.
Напрямок подальших досліджень має стосуватися пошуку підходу в застосуванні байєсівських мереж довіри для побудови акустико-фонетичної моделі розпізнавання мови і застосуванні даної моделі для розпізнавання української мови.
При написанні даного реферату магістерська робота ще не завершена. Остаточне завершення: грудень 2014 року. Повний текст роботи та матеріали по темі можуть бути отримані у автора після зазначеної дати.
Список використаної літератури
[1] Александр Пасечник История развития систем распознавания речи: как мы пришли к Siri [Электронный ресурс] – [Режим доступа:] http://habrahabr.ru/post/131945/ [2] Geoffrey Hinton. NISP tutorial on deep belief nets. – Canadian Institute for Advanced Research, 2007. – 100 p. [3] Geoffrey Hinton. To recognize shapes, first learn to generate images. — In P. Cisek, T. Drew and J. Kalaska (Eds.) Computational Neuroscience: Theoretical Insights into Brain Function. Elsevier., 2006. — pp. 17-34. [4] Deng, L., Hinton, G. E. and Kingsbury, B. New types of deep neural network learning for speech recognition and related applications: An overview – IEEE International Conference on Acoustic Speech and Signal Processing (ICASSP 2013) – Vancouver, 2013. – pp. 8599-8603. [5] Abdel-rahman Mohamed, Geoffrey Hinton, Gerald Penn. Understanding how Deep Belief Nets perform acoustic modeling. – ICASSP, 2012 – pp. 4273-4276. [6] Распознавание речи от Яндекса. Под капотом у Yandex.SpeechKit. [Электронный ресурс] [Режим доступа:] http://habrahabr.ru/company/yandex/blog/198556/ [7] О.І.Федяєв, І.Ю.Бондаренко. Розробка і дослідження нейромережевого алгоритму дикторонезалежного розпізнавання фонем в усному мовленні // Праці Одинадцятої всеукраїнської міжнародної конференції з оброблення сигналів і зображень та розпізнавання образів УкрОБРАЗ'2012. — К.: МННЦ ІТ та С, 2012. — С.71-74. [8] А.Л. Ронжин, А.А. Карпов, И.В. Ли Система автоматического распознавания русской речи SIRIUS — Искусственный интеллект выпуск 3, 2010. – C. 590-601. [9] T. Dutoit Reconnaissance automatique de la parole — Techniques de l’Ingénieur, 2010. – pp. 401-404. [10] С. Хайкин. Нейронные сети: полный курс, 2-е издание, : Пер. с англ. — М.: Издательский дом «Вильямс», 2006. — 1104 с. [11] Hinton, G., Deng, L., Yu, D., Dahl, G. E. et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. – Signal Processing Magazine, IEEE, 2012. – pp. 82-97. [12] Rasmus Berg Palm. Prediction as a candidate for learning deep hierarchical models of data. – Technical University of Denmark, 2012. – 80 p. [13] Брынза Т.А, Бондаренко И.Ю. Сигмоидальные сети доверия в решении задач классификации – Труды IV международной конференции «Информационно-управляющие системы и компьютерный мониторинг», 2013. – C. 422-427. [14] Брынза Т.А., Бондаренко И.Ю., Губенко Н.Е. Представление байесовских сетей доверия для решения задачи распознавания образов. – Труды IX международной научно-технической конференции студентов, аспирантов, молодых ученых «Информатика и компьютерные технологии», 2013. – C. 304-308. [15] Linda Otmani, Abdelkader Benyettou. Les réseaux neuro-bayésiens appliqués à la reconnaissance de la parole. – Université des sciences et de technologie d’ORAN -Mohamed Boudiaf- faculté des sciences, département d’informatique, 2007. – 7 p. [16] Gregoire Montavon. Deep learning for spoken language identification. – Machine Learning Group, Berlin Institute of Technology Germany, 2005. – 4 p. [17] Hinton, G.E., Dayan, P., Frey, B.J. & Neal, R. The wake-sleep algorithm for self-organizing neural network. — Science, 1995. — P. 1158-1161.