
Computer systems and networks
The aim is to improving the quality of information retrieval on the Web through the use modifications of the thematically oriented classification of text documents.
Development of network technologies led to significant increase in number of available information resources and volumes of transferred information. The need of effective use of this huge and dynamically changing amount of information causes an urgency and the importance of researches in the field of information search. According to poll of Internet users more than 63 % from total number of users use search systems in World Wide Web almost every day [1].
In the field of information search the problem of thematic search, that is purposeful search of the documents relating to some relevance to a certain subject, declared by the user is separately allocated. At carrying out researches, training and professional activity, in connection with high speed of emergence of new information there is a need not only for finding of the data corresponding to one or several subjects, but also for continuous obtaining new data. One of possible options of satisfaction of this requirement is periodic updating of earlier received data, by analogy to a subscription to thematic editions, such as specialized newspapers and magazines. For ensuring such delivery of information from Web it is necessary to solve a problem of periodic thematic search, that is such search which is conducted systematically, through certain periods. And are looked for not only updatings on already known Web sites, but also new sites [2].
To shortcomings of methods of the search using inquiries on keywords, refer weak expressiveness of language of inquiries and high labor input of drawing up of optimum inquiry that results in poor quality of thematic search in Web [3]. On the other hand, there is a set of successfully applied methods of definition of thematic accessory of documents, including with use of algorithms of the classification using training collections of documents. However, the high computing complexity of problems of training and classification limits practical applicability of such methods for Web [4].
In these conditions development of a method of thematic search in Web in the conditions of the sustainability information user needs and dynamic search space increasing quality of search in comparison with traditional methods, is represented actual.
In work the effective method and algorithms of the solution of a problem of thematic search in Web differing from existing by a combination of search in keywords and a thematic filtration on the basis of qualifiers of texts for limited-volume collection of documents is offered.
On the basis of the developed algorithms can be implemented software tools for creating and updating thematic collections of documents for computer-based training systems and information systems research.
Now in Internet two main types of services of information search are presented: thematic catalogs of resources and car of search (MT). These universal remedies possess a number of shortcomings from the point of view of search of scientific information.
Process of reference of the document to one of sections of the thematic catalog does not give in completely to automation therefore catalogs cover limited quantity of resources and are not in time
behind network growth.
Search engines are currently implementing two types of results: the traditional keyword search and relatively new - semantic search
Machines keyword search covers more resources and more updated. However quite often they appear ineffective from the point of view of search of scientific information because of big noise level (references to irrelevant documents), limited possibilities of languages of inquiries and a form of representation of search results.
Semantic technology internet search differ from traditional keyword search that allows search engines to read the user's query in natural language and to give a direct answer to this question. Such type of search does not justify itself by search of thematic information in separate or several subject domains.
For increase of relevance of the keyword search various methods which can be divided into two main classes are used.
In the first class of methods is the refinement and query expansion to improve the relevance of search service, either automatically or with the participation of the user. Methods for solving this problem are divided on global and local. Global methods provide expansion or the fresh wording of inquiry irrespective of inquiry and returned results so changes in the formulation of inquiry lead to emergence of the new inquiry corresponding to another semantic close terms.
The following methods belong to the global:
Local methods change request based on the documents found by the original query. The following methods belong to the local:
In the second class two groups of methods are used: classification of web pages based on machine learning algorithms using universal classification and methods of appointment of certain categories or topics of documents and search results to improve their presentation. In the first group of methods problem are big вычислительны costs of classification, complexity of creation of universal qualifiers and large volumes of data in a web [13].
In the second group of methods the mechanisms using the cluster analysis (data clustering, clustering) which provide the better presentation of search results because they organize the structure. A condition of success is preliminary definition of groups, and also categories, subjects or layers which, in turn, are defined by keywords and professional concepts. In order that the document could be appointed to group, it should be correctly classified. Realization of this intention not always appears rather simple. That it to make, the search engine reads, then investigates data and document metadata. Also analyzes contents of the document on the basis of statistical calculations (takes into consideration frequency of emergence of letters, syllables and words, an order of phrases, and also lengths of words and offers), or uses algorithms of the linguistic analysis. The more accurate the data, the more accurate you can select the document in a particular group [14].
The carried-out analysis of existing approaches shows that in a case when relevant search results on the set subject can be provided not at once, and through certain periods, it is expedient to combine search in keywords with the subsequent classification of results of delivery of search servers. In this case, removed strict limitations on the computational complexity of classification algorithms and reduces the volume of classified documents. Such campaign is planned to realize in this work.
The information need of the user is represented in the form of pair {q, D}, where q – inquiry on keywords (inquiry on KS), being used for primary selection of documents from Web, D = {D+, D-} – the training sample describing a subject, the interesting user. This training sample contains examples relevant to a subject of documents (D+) and irrelevant documents (D-).
The search process is divided into two stages:
To implement the labeling of search results the user needs in the training sample set of relevant documents D+ split into subsets that describe the user is interested in subtopics. In this case training sample will represent a set
D={D1+, D2+, D3+,…, Dn+, D-},
where Di+ - training sample sample i-th sub-themes, n - the total number of sub-topics.
Thus, in this case the qualifier will solve two problems: a problem of a thematic filtration (binary classification) and a problem of partition of the set of relevant documents relating to the sub-themes (the classification problem with a lot of classes in the training set).
Consider in more detail the second stage of the method - the task of refinement.
A formal statement of the problem text classification is as follows.
It is supposed that the classification algorithm works at some set of documents
D={di}.
The whole set of documents is partitioned into disjoint classes
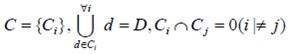
Classification problem is to determine the class to which this document relates.
Requirements for the classification algorithm for the problem are as follows:
For ensuring scalability and acceptable computing complexity it is possible to use as base Bayes's algorithms and the dividing hyper planes with linear (O (N)) complexity of training.
Bayes's method is the simple qualifier based on probabilistic model, independence having the strong assumption a component of a vector of signs [9]. The simple Bayes's classifier refers object of the X-th to the class Ci in only case when when the condition is satisfied:
P(Ci|X)>P(Cj|X),
where P(Ci|X) – the posterior probability that an object X to the class Ci, P(Cj|X) – the posterior probability that an object X to an arbitrary class Cj, different from Ci.
In Bayes's algorithm it is possible to present a rule of definition of a class for the document as follows:
 ,
,
where fw - number of occurrences of feature w in document,

For combating incorrect definition of a priori conditional probability characteristics in case cardinality of training samples used paradigm class additions, ie instead of the token probability of belonging to the class is estimated probability that a token-class complement C’ (it should be noted that p(w|C) ~ 1-p(w|C’)). Using the principle of smoothing parameter Laplace transform, we obtain the following rule:
 ,
,
where NCw - the number of occurrences of the attribute in all classes except this, NC - the total number of occurrences of all the attributes in the class-addition, |V| - dimension dictionary of attributes.
It should be noted that this heuristics works only if quantity of classes |С| >> 2.
For partial compensation of use of a principle of independence of signs, normalization of scales of signs is made:
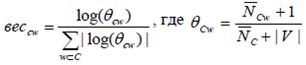
For binary classification problems discussed modifications do not allow to approach Bayes's method on quality to better indicators (the paradigm of classes additions does not bring any changes) so in this case are encouraged to use an algorithm based on Fisher's linear discriminant. The algorithm is based search in the multidimensional feature space such direction w, the mean values of the projection of objects at him training sample of the most varied classes.
Projection of any vector of the X-th to the direction w is the relation 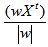 . As a measure of distinctions of projections of classes on w the functional - Fischer's index is used:
. As a measure of distinctions of projections of classes on w the functional - Fischer's index is used:
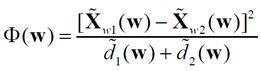 , (1)
, (1)
where 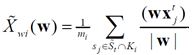 - the average value of the projection vectors describing objects of class
- the average value of the projection vectors describing objects of class  ,
,  - selective dispersion of projections of the vectors describing objects from a class.
- selective dispersion of projections of the vectors describing objects from a class.
Fisher's linear discriminant is defined as a linear function of separating maximizing the functional wtx(1).
For more complete division of classes in algorithm some directions corresponding to Fischer's discriminant are under construction. Along one direction can effectively share some of the training instances. Cutting off points for positive and negative copies along each direction are remembered when training algorithm.
Classification instance using the following algorithm:
loop i = 1... L (number of referrals)
Analyze i-th direction:
end of loop
Task pretreatment document is a document feature extraction and matching them weights.
In the simplest case the document is a set of features contained therein set of tokens, and the weights being the number of occurrences of tokens in the document. The disadvantage of this approach is that virtually ignores the features of natural language, as well as structuring and document links between documents in the case of Web-pages.
When processing a document produced weight gain tokens included in headlines, titles, keywords, text links, etc.
Further improvement of preparation of documents for use machine learning methods by selecting more effective forms of assessment scales signs the document, taking into account the links. Conducting experiments to improve Bayes's classifier documents for those with lots of cardinality subtopics. Development of criteria for assessing the quality of the search using the proposed algorithms.
The analysis of existing approaches to improve the relevance of the thematic search by classifying the results of search engines. Algorithms filtering and classification with low computational complexity. Classification of search results can significantly reduce the time to find specific information. Thus, the introduction of an additional classification for documents received by the user can improve usability and search engine allows you to quickly navigate to the results obtained.
In writing this essay master's work is not yet complete. Final completion: December 2014. Full text of the work and materials on the topic can be obtained from the author or his manager after that date.