
Системи штучного інтелекту
Метою роботи є підвищення якості пошуку інформації в Web шляхом застосування модифікації методу тематично-орієнтованої класифікації текстових документів.
Розвиток мережевих технологій привело до значного збільшення числа доступних інформаційних ресурсів та обсягів переданої інформації. Необхідність ефективного використання цього величезного і динамічно мінливого обсягу інформації обумовлює актуальність і значимість досліджень в області інформаційного пошуку. Згідно з опитуванням користувачів Інтернет більше 63% від загального числа користувачів використовують системи пошуку в World Wide Web практично кожен день [1].
В області інформаційного пошуку окремо виділяється завдання тематичного пошуку, тобто цілеспрямованого пошуку документів, що відносяться з тим або іншим ступенем релевантності до певної теми, заявленої користувачем. При проведенні досліджень, навчанні та професійній діяльності, у зв'язку з високою швидкістю появи нової інформації виникає потреба не тільки в знаходженні відомостей, відповідних одній або декільком темам, але і в постійному отриманні нових даних. Одним з можливих варіантів задоволення цієї потреби є періодичне оновлення раніше отриманих відомостей, за аналогією з підпискою на тематичні видання, такі як спеціалізовані газети і журнали. Для забезпечення такого роду доставки інформації з Web необхідно вирішити завдання періодичного тематичного пошуку, тобто такого пошуку, який ведеться систематично, через певні проміжки часу. Причому шукаються не тільки поновлення на вже відомих Web-сайтах, але й нові сайти [2].
До недоліків методів пошуку, що використовують запити за ключовими словами, відносять слабку виразність мови запитів і високу трудомісткість складання оптимального запиту, що призводить до низької якості тематичного пошуку в Web [3]. З іншого боку, існує безліч успішно застосовуваних методів визначення тематичної приналежності документів, у тому числі і з використанням алгоритмів класифікації, що використовують навчальні колекції документів. Однак висока обчислювальна складність завдань навчання і класифікації обмежує практичну застосовність таких методів для Web [4].
У цих умовах розробка методу тематичного пошуку в Web в умовах довготривалості інформаційної потреби користувача і динамічності простору пошуку, підвищує якість пошуку в порівнянні з традиційними методами, представляється актуальною.
У роботі запропоновано ефективний метод та алгоритми розв'язання задачі тематичного пошуку в Web, що відрізняються від існуючих комбінацією пошуку за ключовими словами і тематичної фільтрації на основі класифікаторів текстів для обмежених за обсягом колекцій документів.
На базі розроблених алгоритмів можуть бути реалізовані програмні засоби для створення та оновлення тематичних колекцій документів для систем комп'ютерного навчання та інформаційного забезпечення наукових досліджень.
Методи класифікації текстів лежать на стику двох областей - машинного навчання (machine learning, ML) та інформаційного пошуку (information retrieval, IR) [5, 6]. Відповідно автоматична класифікація може здійснюватися:
Розробці методів класифікації текстів і пов'язаним з ними алгоритмам подання текстів присвячені праці таких авторів як Krishnapuram R., Keller J., Zhang C., DD Lewis, R.E. Schapire, H. Schutze, F. Sebastiani, Y. Yang, ST Dumais М. С., Агєєв, І. Є. Кураленок, І. С. некрестьянам.
У статті [7] досліджуються різні методи усікання простору ознак, і проводиться порівняння методів машинного навчання на завданні класифікації текстів колекції Reuters. Порівнюються наступні методи: FindSimilar (аналог k-найближчих сусідів), метод Байеса, Байесови мережі, дерева рішень, SVM. Як стверджують автори метод SVM має перевагу над іншими досліджуваними методами машинного навчання.
У роботі [8] запропоновано метод автоматичної класифікації документів з безлічі заданих тематик. Метод використовує латентно-семантичний аналіз для вилучення семантичних взаємозв'язків між словами. Відносно низька обчислювальна трудомісткість методу робить можливим його застосування для класифікації документів, що надходять в систему динамічно.
У статті [9] представлені результати досліджень проблеми автоматичної класифікації документів як одного з аспектів систем управління знаннями , областю застосування яких може розглядатися задача підтримки інноваційної діяльності . В якості інструменту для вирішення цього завдання пропонується надбудова, що розробляється, над повнотекстовими базами знань, що включаються до складу інтелектуальних інформаційних систем, що забезпечує автоматичну класифікацію документів і представляє витягнуті з документів знання у вигляді, ефективному для проведення аналізу технічних систем.
В роботі [10] Для того щоб підвищити релевантність пошуку інформації в Інтернеті, пропонується використовувати знання користувача про Предметну Область, яка його цікавить, представлені у вигляді онтології. На основі безлічі термінів онтології Предметної Області будується тезаурус користувача, який використовується для оцінки того, наскільки цікавий цей ІР користувачеві.
В роботі [11] розглянуто підхід до вирішення завдання Text Mining з вилучення інформації про об'єкти з текстових документів і переносу в базу даних для подальшого вилучення знань на основі стандартних методів Data Mining. Сформульовано вимоги до системи витягання і структурування даних. Запропоновано структурну організацію системи та обрані алгоритми вилучення.
Автором роботи [12] розглянуто методику вимірювання характеристик класифікатора і обрані метрики для підвищення ефективності класифікації. Розроблено модель подання документів з урахуванням гіперпосилань і алгоритми політематичної класифікації на основі бінарного методу і ранжування.
В даний час в Internet представлені два основних види служб пошуку інформації: тематичні каталоги ресурсів і машини пошуку (МП). Ці універсальні засоби мають цілу низку недоліків з точки зору пошуку наукової інформації.
Процес віднесення документа до одного з розділів тематичного каталогу не піддається повністю автоматизації, тому каталоги охоплюють обмежену кількість ресурсів і не встигають
за зростанням мережі.
Машини пошуку в даний час реалізують два види пошуку: традиційний пошук за ключовими словами і відносно новий - семантичний пошук.
Машини пошуку за ключовими словами охоплюють більше ресурсів і частіше оновлюються. Однак нерідко вони виявляються малоефективними з точки зору пошуку наукової інформації через велику рівня шуму (посилань на нерелевантні документи), обмежених можливостей мов запитів та форми подання результатів пошуку.
Технології семантичного інтернет-пошуку відрізняються від традиційного пошуку за ключовими словами тим, що дозволяють пошуковій системі зчитувати запит користувача на природній мові і давати пряму відповідь на поставлене питання. Такий вид пошуку не виправдовує себе при пошуку тематичної інформації в окремій або кількох предметних областях.
Для підвищення релевантності пошуку за ключовими словами використовуються різні методи, які можна розділити на два основні класи.
У першому класі методів проводиться уточнення і розширення пошукового запиту для підвищення релевантності видачі пошукового сервісу або автоматично, або за участю користувача. Методи вирішення цього завдання поділяються на глобальні та локальні. Глобальні методи передбачають розширення або нове формулювання запиту незалежно від запиту і результатів, що повертаються, так що зміни у формулюванні запиту призводять до появи нового запиту, відповідного іншим семантично близьким термінам.
До глобальних належать такі методи:
Локальні методи змінюють запит з урахуванням документів, знайдених за вихідним запитом. До локальних відносяться наступні методи:
У другому класі використовується дві групи методів: класифікація веб-сторінок на основі алгоритмів машинного навчання з використанням універсальних класифікаторів і методи призначення певних категорій або тематик документам і результатами пошуку для поліпшення їх презентації. У першій групі методів проблемою є великі обчислювальні витрати на класифікацію, складність побудови універсальних класифікаторів і великі обсяги даних у веб [13].
У другій групі методів застосовуються механізми, які використовують кластерний аналіз (data clustering, кластеризація), які забезпечують кращу презентацію результатів пошуку, тому що організують їх в структуру. Цей метод полягає в призначенні певних категорій або тематик документам і результатів пошуку. Поняття кластер означає безліч, сукупність, в'язку або просто групу. Кластеризація спрямована на сортування результатів пошуку в одну або кілька таких груп, і таким чином витягує групи з усіх результатів. Умовою успіху є попереднє визначення груп, а також категорій, тематик або шарів, які, в свою чергу, визначаються ключовими словами і професійними поняттями. Для того, щоб документ міг бути призначений групі, він повинен бути правильно класифікований. Реалізація цього наміру не завжди виявляється досить простою. Щоб її зробити, пошукова система читає, після чого досліджує дані та метадані документа. Також аналізує зміст документа на основі статистичних розрахунків (бере до уваги частоту появи букв, складів і слів, порядок фраз, а також довжини слів і пропозицій), або використовує алгоритми лінгвістичного аналізу. Чим більше точні ці дані, тим точніше можна виділити документ в певній групі [14].
Проведений аналіз існуючих підходів показує, що у випадку, коли релевантні результати пошуку по заданій темі можуть надаватися не відразу, а через певні проміжки часу, доцільно поєднувати пошук за ключовими словами з подальшою класифікацією результатів видачі пошукових серверів. У цьому випадку знімаються жорсткі обмеження на обчислювальну складність алгоритмів класифікації і зменшується обсяг що класифікуються документів. Такий підхід планується реалізувати в даній роботі.
У науковій діяльності, навчанні та інших сферах існує необхідність у постійному пошуку публікацій по ряду тематик. Для вирішення цього завдання в роботі пропонується метод тематичного пошуку в Web, заснований на комбінації пошуку за ключовими словами і тематичної фільтрації з використанням класифікаторів текстів, застосовуваної в обмежених за обсягом колекціях документів. Відбір документів за допомогою пошуку за ключовими словами дозволяє значно скоротити безліч аналізованих класифікатором документів, що призводить до зменшення обчислювальної складності методу в цілому в порівнянні з методом тематичної фільтрації і, як наслідок, застосовності отриманого методу на великих обсягах даних, характерних для Web.
Інформаційна потреба користувача представляється у вигляді пари {q, D}, де q – запит за ключовими словами (запит за КС), що використовується для первинного відбору документів з Web, D = {D+, D-} – навчальна вибірка, що описує тему, цікаву для користувача. Дана навчальна вибірка містить приклади релевантних темі документів (D+) і нерелевантних документів (D-).
Процес пошуку розділяється на два етапи:
Для реалізації класифікації результатів пошуку користувачу необхідно в навчальній вибірці безліч релевантних документів D+розбити на підмножини, що описують цікаві користувача підтеми. У цьому випадку навчальна вибірка буде представляти собою множину
D={D1+, D2+, D3+,…, Dn+, D-},
де Di+ - навчальна вибірка i-ой підтеми, n – загальна кількість підтем.
Таким чином, в цьому випадку класифікатор буде вирішувати два завдання: завдання тематичної фільтрації (бінарної класифікації) і задачу розбиття множини релевантних темі документів на підтеми (задачу класифікації з великою кількістю класів у навчальній вибірці). Загальний вид технології тематичного пошуку на основі пропонованого методу представлений на рис. 1

Рис. 1. Основні етапи тематичного пошуку
(анімація: 8 кадрів, 10 циклів повтору, 113Kb)
Розглянемо більш детально другий етап методу - задачу уточнення результатів пошуку.
Формальна постановка задачі класифікації текстів виглядає наступним чином.
Передбачається, що алгоритм класифікації працює на деякій множині документів
D={di}.
Всі безліч документів розбивається на непересічні підмножини класів
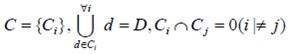
Завданням класифікації є визначення класу, до якого відноситься даний документ.
Аналіз публікацій у порівнянні існуючих методів підтверджують перевагу алгоритму класифікації за методом опорних векторів – SVM[6] над іншими алгоритмами. Для вирішення завдання класифікації результатів пошуку даний алгоритм не застосовується через низьку швидкість навчання (O(|D|a, де a>1,2 [5])) і великих витрат пам'яті. Проте його можна використовувати як еталон при порівнянні алгоритмів класифікації.
Виходячи зі сказаного, вимоги до алгоритму класифікації для розв'язуваної задачі формулюються таким чином:
Для забезпечення масштабованості і прийнятною обчислювальної складності можна використовувати в якості базових алгоритми Байеса і розділяють гіперплоскостей з лінійною (O (N)) складністю навчання.
Метод Байєса це простий класифікатор, заснований на ймовірнісної моделі, що має сильне припущення незалежності компонент вектора ознак [9]. Зазвичай це допущення не відповідає дійсності і тому одна з назв методу - Na?ve Bayes (Наївний Байес). Простий байесовский класифікатор відносить об'єкт X до класу Ci тоді і тільки тоді, коли виконується умова:
P(Ci|X)>P(Cj|X),
де P(Ci|X) – апостериорная ймовірність приналежності об'єкта X до класу Ci, P(Cj|X) – апостеріорна ймовірність приналежності об'єкта X до довільного класу Cj, відмінному від Ci.
Іншими словами, апостеріорна ймовірність приналежності об'єкта до класу Ci більше апостеріорної ймовірності приналежності об'єкта до будь-якого іншого класу.
Алгоритм Байеса в даний час оцінюється як порівняно низькоякісний алгоритм. Основними причинами є проблеми, пов'язані з принципом незалежності ознак і некоректною оцінкою апріорної ймовірності у випадку істотно нерівно потужних навчальних вибірок.
Правило визначення класу для документа в алгоритмі Байеса можна представити таким чином:
 ,
,
де fw - кількість входжень ознаки w в документ,

Для боротьби з некоректним визначенням апріорної умовної ймовірності ознак у разі нерівно потужних навчальних вибірок, використовується парадигма класу-доповнення, тобто замість ймовірності приналежності лексеми класу оцінюється ймовірність приналежності лексеми класу-доповненню C '(слід врахувати, що p (w | C) ~ 1 -p (w | C ')). Використовуючи принцип згладжування параметрів по Лапласа, отримуємо наступне правило:
 ,
,
де NCw - кількість входжень ознаки в усі класи крім даного, NC - загальна кількість входжень всіх ознак в клас-доповнення, |V| - розмірність словника ознак.
Слід зазначити, що дана евристика працює тільки в тому випадку, якщо кількість класів |С| >> 2.
Для часткової компенсації використання принципу незалежності ознак, виробляється нормалізація ваг ознак:
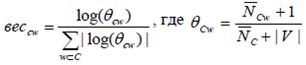
Для завдання бінарної класифікації розглянуті модифікації не дозволяють наблизити метод Байеса за якістю до кращих показників (парадигма класів-доповнень не вносить ніяких змін), тому для даного випадку пропонується використовувати алгоритм, заснований на лінійному дискримінант Фішера. В основі алгоритму лежить пошук в багатовимірному просторі ознак такого напрямку w, щоб середні значення проекції на нього об'єктів навчальної вибірки з класів максимально розрізнялися. На рис.2 показаний вибір двох різних значень w для двовимірного випадку. Мірою поділу спроектованих точок служить різниця середніх значень вибірки. Бажано, щоб проекції на прямий були добре розділені і не дуже перемішані.
Проекцією довільного вектора X на напрям w є відношення 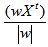 . В якості міри відмінностей проекцій класів на w використовується функціонал - індекс Фішера:
. В якості міри відмінностей проекцій класів на w використовується функціонал - індекс Фішера:
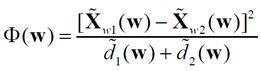 , (1)
, (1)
де 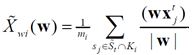 - середнє значення проекції векторів, що описують об'єкти з класу
- середнє значення проекції векторів, що описують об'єкти з класу  ,
,  - вибіркова дисперсія проекцій векторів, що описують об'єкти з класу.
- вибіркова дисперсія проекцій векторів, що описують об'єкти з класу.
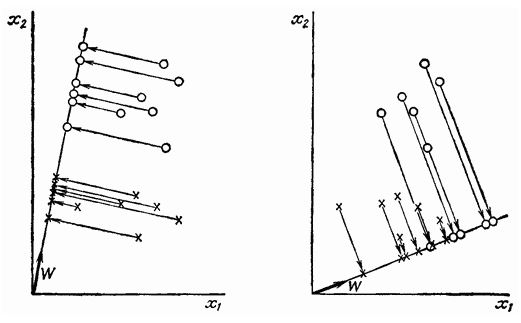
Рис. 2. Проекція вибірок на пряму
Лінійний дискриминант Фішера визначається як лінійна розділяє функція, максимизирующая функціонал (1).
Для більш повного поділу класів в алгоритмі будується кілька напрямків відповідних дискримінанту Фішера. Вздовж одного напрямку можна ефективно розділити частину навчальних примірників. Точки відсікання для позитивних і негативних примірників уздовж кожного напрямку запам'ятовуються при навчанні алгоритму.
Схема навчання алгоритму представлена на рис. 3.
Класифікація примірника проводиться за наступним алгоритмом:
цикл i = 1... L (кількість напрямів)
Аналізуємо i-oe напрям:
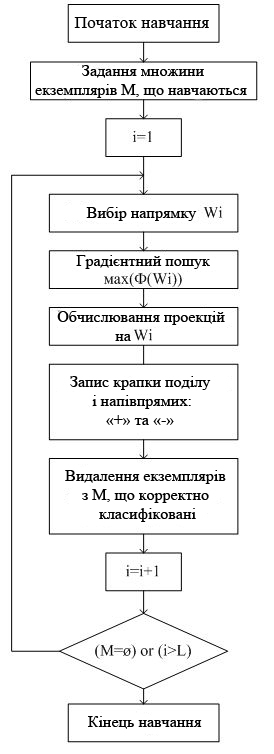
Рис. 3. Блок-схема навчання алгоритму бінарної класифікації
Завданням етапу попередньої обробки документів є виділення ознак документа і зіставлення їм ваг.
У простому випадку набором ознак документа буде міститься в ньому набір лексем, а в якості ваги використовується кількість входжень лексеми в документ. Недоліком такого підходу є те, що практично не враховуються особливості природної мови, а також структурованість документа і зв'язки між документами в разі Web-сторінок. При обробці Web-сторінок необхідно передбачити автоматичне визначення кодування, оскільки явно вона вказується не в усіх документах. Для вирішення цього завдання проводиться аналіз частоти входження найбільш часто використовуваних літер або, у разі коли частотний аналіз не дозволяє зробити певний висновок, проводиться перевірка наявності частини виділених лексем в морфологічному словнику. У разі, якщо частотний або словниковий аналіз показали невідповідність кодування, текст документа конвертується в інше кодування.
При обробці документа проводиться збільшення ваги лексем, що входять в заголовки, назви, ключові слова, текст посилання і т.п.
Надалі передбачається удосконалення підготовки документів до застосування методів машинного навчання шляхом вибору більш ефективної форми оцінки ваг ознак документа, що враховує посилання. Проведення експериментів з удосконалення байєсівського класифікатора документів для тем з більшою кількістю неравномощних підтем. Розробка критеріїв оцінки якості пошуку із застосуванням запропонованих алгоритмів.
Проведено аналіз існуючих підходів до підвищення релевантності тематичного пошуку шляхом класифікації результатів видачі пошукових систем . Розроблено алгоритми фільтрації та класифікації з малою обчислювальною складністю . Класифікація результатів пошуку дозволяє істотно скоротити час пошуку потрібної інформації. Таким чином, введення додаткової класифікації на одержувані користувачем документи дозволяє підвищити зручність використання пошукової системи і дозволяє швидше орієнтуватися в отриманих результатах.
При написанні даного реферату магістерська робота ще не завершена. Остаточне завершення: грудень 2014 року. Повний текст роботи та матеріали по темі можуть бути отримані у автора або його керівника після зазначеної дати.