
В современном стремительно развивающемся информационном обществе достаточно остро стоит вопрос хранения и передачи информации. Несмотря на непрерывно возрастающий накопительный объём информационных носителей, порой требуется сохранить большое количество данных на хранилище небольшой ёмкости.
Избыточность данных зачастую связана с качеством информации. Она улучшает понятность и восприятие информации. Однако, при хранении и передаче информации средствами компьютерной техники, избыточность может привести к возрастанию стоимости хранения и передачи информации. Особенно актуальной эта проблема встаёт в случае обработки огромных объёмов информации при незначительных объёмах носителей данных. В связи с этим, постоянно возникает проблема уменьшения избыточности или сжатия данных.
Сжатый (упакованный) файл называется архивом. Процесс записи файла в архивный файл называется архивированием (упаковкой, сжатием), а извлечение файла из архива – разархивированием (распаковкой). Архивация информации – это такое преобразование информации, при котором объём информации уменьшается, а количество информации остается прежним [1].
Сегодня архиваторы используются преимущественно для выкладывания данных в Сеть. Большинство драйверов на сайтах производителей выкладываются именно в архивах, и большая часть программ на различных ресурсах также заархивированы. Кстати, и сам пользователь прежде чем выложить какие-либо данные в Сеть (например, на файлообменные ресурсы), запаковывает данные в архив [2]
Большинство цифровых данных хранятся в двоичных (бинарных) файлах. Чистые текстовые файлы встречаются довольно редко (вероятно, менее 2% данных в мире). Есть несколько причин, по которым используются бинарные файлы:
1. Ввод и вывод намного быстрее при использовании двоичных данных. Преобразование 32-разрядного целого числа в символы занимает время. Не так много времени, но если файл (например, файл изображения) содержит миллионы чисел, накопленное время преобразования является значительным. Компьютерные игры замедлялись бы, если бы их данные хранились в виде символов.
2. Двоичный файл обычно намного меньше текстового файла, который содержит эквивалентное количество данных. Для изображений, видео и аудио данных это важно. Небольшие файлы экономят место на диске, они могут быстрее передаваться и обрабатываться быстрее. Ввод и вывод с меньшими файлами также происходит быстрее, поскольку требуется меньше байтов для перемещения.
3. Почти никогда человек не собирается смотреть на отдельные образцы данных, поэтому нет никаких оснований делать их удобочитаемыми. Например, люди смотрят на всю картинку GIF-файла и мало интересуются просмотром отдельных пикселей в виде чисел. Иногда программист или учёный должен сделать это, возможно, для отладки или научных измерений. Но в этих особых случаях можно использовать шестнадцатеричные дампы или другие специализированные программы [3].
Поэтому именно бинарные данные были выбраны для работы в разрабатываемом программном средстве.
При эксплуатации ПК возможна потеря информации по самым разным причинам: из-за физической порчи диска, неправильной корректировки или случайного удаления файла, разрушения информации вирусом и т.д. Чтобы уменьшить вредные последствия таких ситуаций, нужно иметь копии файлов. Средства резервного копирования, предоставляемые операционной системой и программами-оболочками для хранения информации, требуют больших объемов внешней памяти. Более удобно для создания архивных файлов использовать специальные программы, сжимающие информацию [4].
Сжатие – это способ кодирования цифровых данных так, чтобы они занимали меньший объём памяти. Для сжатия данных используются методы двух типов – с потерей и без потери данных. Методики с потерей данных позволяют сжать файл, но некоторые данные при этом теряются безвозвратно. А методы сжатия без потери данных сжимают информацию, не искажая её и ничего не теряя во время этого процесса. После восстановления оригинальный документ идентичен исходному с точностью до бита [5]. Поэтому при работе с бинарными данными нужно использовать именно методы сжатия без потери данных. Одними из таких являются алгоритмы сжатия изображений, которые будут использоваться в данной работе.
Целью работы является разработка метода сжатия бинарных данных на основе методов сжатия изображений.
В процессе работы необходимо выполнить следующие задачи:
Результатом работы являются разработанные метод и программное средство для архивации данных на основе известных алгоритмов сжатия изображений.
Вследствие растущих объёмов обрабатываемой и хранимой информации особое значение приобретает архивация данных с их сжатием.
Задача эффективного сжатия данных всегда была одной из самых актуальных в информатике, а с развитием компьютерной, цифровой техники и Интернет она приобрела еще большее значение.
Методы сжатия данных имеют достаточно длинную историю развития, которая началась задолго до появления первого компьютера [6]. Уже существует немало стандартизированных методов сжатия [7], но необходимость в появлении новых и улучшенных методах остаётся до сих пор.
В статье [8] Салауддин М. предложил новый метод сжатия для общих данных, основанный на логической таблице истинности. Последовательность входных данных проверяется там, где она чётная или нечётная. Если последовательность нечётная, тогда добавляется бит, 0 или 1, в зависимости от последнего бита, а если чётная, тогда этот шаг пропускается. Если последний бит входной последовательности равен 0, тогда добавляется 0, а если равен 1, то добавляется 1. Затем бинарные данные представляются одним битом на основании предложенной таблице истинности. Таким образом, осуществляется сжатые данных.
Нестандартно к сжатию информации подошли Сатеш Р., Мохан Р., Партасарати P. в статье [9], в которой описано алгоритм скрытие одного изображения в другом, в результате чего, уменьшается в два раза количество места занимаемого изображениями.
Павлов И.В. в своей работе [10] представляет разработанные различные варианты алгоритмов поиска совпадающих последовательностей символов, что является предварительной процедурой для сжатия данных с помощью алгоритма Лемпела–Зива. Предложенные алгоритмы, в отличие от известных, основаны на использовании деревьев цифрового поиска, что приводит к невысокой критичности временных затрат на поиск к длине исходной последовательности символов. Кроме того, предложенные алгоритмы позволяют выбирать оптимальный вариант алгоритма поиска в зависимости от располагаемых вычислительных ресурсов. Разработанная модификация алгоритма Лемпела–Зива обеспечивает увеличение степени сжатия по сравнению с известными его вариантами на 10-40 % в зависимости от данных.
В работах магистров Донецкого национального технического университета также рассматривалась тема архивации и сжатия данных:
Разработки программных средств архивации бинарных данных на основе алгоритмов сжатия изображений в работах магистров не было выявлено.
Архивация бинарных данных должна быть основана на алгоритмах сжатия изображений, поэтому для этого двоичные файлы, перед сжатием должны быть представлены в виде растровых изображений. Особенностью растрового изображения является то, что оно как мозаика состоит из маленьких частей называемых пикселами. Именно на такие части нужно разбить двоичный файл. Каждый пиксел описывается тройкой чисел, соответствующих яркостям базовых составляющих в модели представления цвета RGB.
Цвет в модели RGВ представляется как сумма трёх базовых цветов – красного (Red), зелёного (Green) и синего (Blue). Из первых букв английских названий этих цветов составлено название модели. На рис. 1 показано, какие цвета получаются при сложении трёх базовых.
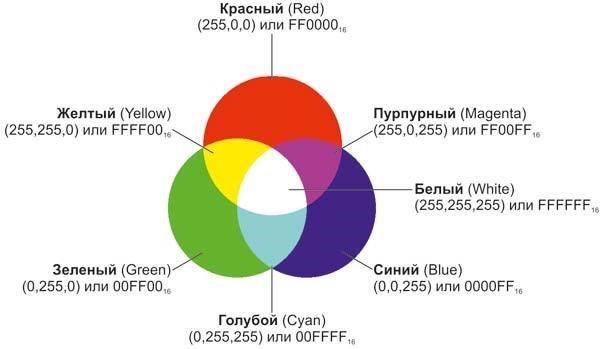
Рисунок 1 – Комбинации базовых цветов модели RGB [14]
Поскольку яркость каждой из базовых составляющих цвета может принимать только 256 целочисленных значений, каждое значение можно представить 8-разрядным двоичным числом (последовательностью из 8 нулей и единиц) или, другими словами, одним байтом. Таким образом, в модели RGB информация о каждом цвете требует 3 байта [14].
Преобразованные из двоичного файла пиксели необходимо сохранить в файле, который использует установленный формат файла растрового изображения и которому присвоено имя с трехбуквенным расширением .bmp. Установленный формат файла растрового изображения состоит из структуры bitmapfileheader, за которой следует структура bitmapinfoheader и массив структур rgbquad (также называемый таблицей цветов). Таблица цветов сопровождается вторым массивом индексов в таблицу цветов (фактические данные растрового изображения).
В структуре bitmapfileheader идентифицируется файл, указывается размер файла в байтах и смещение от первого байта в заголовке до первого байта данных растрового изображения. В структуре bitmapinfoheader определяется ширина и высота растрового изображения в пикселях; формат цвета (количество цветовых плоскостей и цветовых битов на пиксель) устройства отображения, на котором была создана битовая карта; были ли данные растрового изображения сжаты перед хранением и тип используемого сжатия; количество байтов растровых данных; разрешение устройства отображения, на котором было создано растровое изображение; и количество цветов, представленных в данных. Структуры RGBQUAD задают яркостные значения RGB для каждого из цветов в палитре устройства [15]
Чтобы полностью превратить преобразованные из бинарного файла пиксели в растровое изображение, его прежде нужно дополнить в начале заполненными структурами bitmapfileheader и bitmapinfoheader, которые являются необходимыми для идентификации растрового изображения в формате .bmp.
После создания растрового изображение в формате .bmp, оно конвертируется в формат .png, использующий метод сжатия Deflate, или в формат .pcx, в котором используется RLE сжатие.
Процесс архивации бинарных данных на основе алгоритмов сжатия изображений представлен на рис. 2.

Рисунок 2 – Процесс архивации/разархивации бинарных данных на основе алгоритмов сжатия изображений (анимация: 10 кадров, 7 циклов, 52 килобайта)
С не угасающей скоростью увеличения количества информации задача архивации и сжатия данных остаётся актуальной и ей интересуются по всему миру. Разработчики предлагают свои новые решения. Тем не менее исследование и разработка улучшенных методов сжатия продолжается.
В ходе выполнения работы были определены задачи, которые должны быть решены для успешной разработки программного средства для архивации, реализация которого должна предоставить улучшенный способ сжатия бинарных данных.
На момент написания данного реферата магистерская работа еще не завершена. Окончательное завершение: май 2019 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.