
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования, планируемые результаты
- 3. Обзор исследований и разработок
- 3.1 Обзор международных источников
- 3.2 Обзор национальных источников
- 3.3 Обзор локальных источников
- 4. Применение алгоритмов машинного обучения для определения тональности текста отзывов в интернет магазинах
- Выводы
- Список источников
Введение
В наше время интернет-магазины стали неотъемлемой частью повседневной жизни, предоставляя потребителям беспрецедентную свободу выбора товаров и услуг. Однако в этой огромной цифровой среде обратная связь от потребителей играет критическую роль. Отзывы, комментарии и оценки товаров, оставленные покупателями, могут существенно повлиять на репутацию и успех интернет-магазина.
В этом контексте, анализ тональности текста отзывов становится ключевым инструментом для понимания мнения клиентов и оценки качества предлагаемых товаров и услуг. Алгоритмы машинного обучения предоставляют мощный инструментарий для автоматической обработки и классификации текстов по тональности. Они позволяют выявлять не только положительные и отрицательные отзывы, но и анализировать их содержание, выделяя ключевые аспекты, на которые обращают внимание потребители.
1. Актуальность темы
В современном мире интернет-магазины стали неотъемлемой частью нашей повседневной жизни, предоставляя огромный выбор товаров и услуг. Однако, с ростом числа интернет-пользователей, обратная связь от клиентов стала не только важной, но и огромной по объему. Отзывы и комментарии клиентов о товарах и услугах оказывают огромное влияние на репутацию бренда и решение других потенциальных покупателей.
Здесь на сцену выходят алгоритмы машинного обучения, предоставляя эффективный инструмент для анализа тональности текста отзывов. Эта технология становится актуальной по нескольким ключевым причинам.
Во-первых, объем данных в интернет-магазинах постоянно растет. Отзывы и комментарии клиентов формируют огромное количество текстовой информации, которую нужно анализировать. Алгоритмы машинного обучения помогают автоматизировать этот процесс и выявлять важные тенденции и закономерности.
Во-вторых, влияние репутации важнее, чем когда-либо. Рейтинги и отзывы о товарах и услугах могут оказать решающее воздействие на принятие решения покупателями. Интернет-магазины стремятся поддерживать высокую репутацию, и для этого им необходимо быстро и точно анализировать множество отзывов.
В-третьих, анализ тональности текста помогает улучшить качество обслуживания клиентов. Этот анализ позволяет выявлять слабые места в обслуживании и оперативно реагировать на негативные отзывы. Это способствует улучшению качества предоставляемых услуг и товаров.
В-четвертых, конкуренция в сфере интернет-торговли жесткая, и важно знать, что думают о вас ваши клиенты и какие аспекты их опыта требуют улучшения. Алгоритмы машинного обучения позволяют выявлять тренды и паттерны в отзывах, что помогает оставаться на шаг впереди конкурентов.
В-пятых, эффективность и экономия ресурсов становятся все более важными в бизнесе. Автоматизированный анализ текстовых отзывов при помощи алгоритмов машинного обучения позволяет сэкономить ресурсы и время, которые ранее требовались для ручной обработки и анализа отзывов.
И, наконец, развитие искусственного интеллекта делает применение алгоритмов машинного обучения для анализа текстовой информации все более доступным и эффективным. Эта технология продолжает совершенствоваться и находить новые применения в сфере интернет-магазинов. Все эти факторы делают анализ тональности текста отзывов крайне актуальной темой для интернет-магазинов и предприятий электронной коммерции, которые стремятся улучшить свой бизнес и удовлетворить потребительские потребности в быстро меняющейся цифровой среде.
2. Цель и задачи исследования, планируемые результаты
Целью данного исследования является изучение и анализ применения алгоритмов машинного обучения для определения тональности текста отзывов в интернет-магазинах с целью улучшения качества обслуживания клиентов, повышения репутации бренда и повышения конкурентоспособности.
Основные задачи исследования:
- Обзор литературы: провести обзор существующей литературы и исследований в области анализа тональности текста и его применения в интернет-магазинах.
- Сбор данных: собрать и подготовить наборы данных, содержащие текстовые отзывы из различных интернет-магазинов.
- Предобработка данных: произвести предобработку текстовых данных, включая токенизацию, удаление стоп-слов, лемматизацию и очистку от специфичных символов.
- Разработка моделей: создать модели машинного обучения, включая классификаторы для определения тональности текста (положительная, отрицательная, нейтральная).
- Тестирование и оценка: провести тестирование разработанных моделей на тестовых данных, используя метрики качества, такие как точность, полнота, F1-мера и др.
- Интеграция в практику: исследовать возможности интеграции разработанных моделей в реальные интернет-магазины и оценить их эффективность в реальных условиях.
- Анализ результатов: проанализировать результаты исследования, выявить преимущества и ограничения применения алгоритмов машинного обучения для анализа тональности текста в интернет-магазинах.
Планируемые результаты:
- Разработка и оптимизация моделей машинного обучения для анализа тональности текста.
- Эффективные методы предобработки текстовых данных.
- Повышение качества обслуживания клиентов интернет-магазинов через быстрый анализ и реакцию на отзывы.
- Улучшение репутации бренда и повышение уровня удовлетворенности клиентов.
- Практические рекомендации по внедрению результатов исследования в бизнес-процессы интернет-магазинов.
Объект исследования: процессы анализа тональности текста отзывов в интернет-магазинах.
Предмет исследования: алгоритмы машинного обучения, применяемые для определения тональности текста отзывов в интернет-магазинах.
В рамках магистерской работы планируется получение актуальных научных результатов по следующим направлениям:
- Разработка и сравнительный анализ алгоритмов машинного обучения: исследование и разработка различных моделей машинного обучения для определения тональности текста отзывов, таких как методы на основе нейронных сетей, методы на основе статистики и ансамблирования. Сравнительный анализ эффективности их работы на различных типах данных и сценариях.
- Интеграция в бизнес-процессы: исследование методов интеграции разработанных алгоритмов в практику интернет-магазинов. Разработка прототипа системы анализа тональности, способной автоматически обрабатывать и классифицировать отзывы, и его тестирование на реальных данных.
- Оптимизация процессов предобработки данных: исследование методов оптимизации предобработки текстовых данных, чтобы снизить влияние шума и улучшить качество анализа. Это включает в себя определение наилучших практик для очистки и структурирования текстов.
- Специализированные адаптации для интернет-магазинов: разработка специализированных адаптаций алгоритмов для учета уникальных особенностей отзывов и комментариев в интернет-магазинах, таких как специфичные термины, выразительные средства и синонимы.
- Оценка влияния на бизнес-показатели: анализ влияния внедрения системы анализа тональности на ключевые бизнес-показатели интернет-магазинов, такие как уровень удовлетворенности клиентов, объемы продаж, конверсия и репутация бренда.
- Анализ этических и юридических аспектов: рассмотрение этических и юридических вопросов, связанных с автоматическим анализом отзывов и комментариев клиентов, включая вопросы конфиденциальности данных и соблюдение законодательства о защите потребителей.
- Дальнейшее развитие и перспективы: разработка рекомендаций для дальнейшего развития систем анализа тональности и исследование перспектив применения новых методов и технологий в данной области.
Для экспериментальной оценки полученных теоретических результатов и формирования фундамента последующих исследований, в качестве практических результатов планируется:
- Разработка и обучение моделей машинного обучения: создание и обучение различных моделей машинного обучения для определения тональности текста отзывов на реальных наборах данных из интернет-магазинов. Эти модели будут включать в себя как классические алгоритмы (например, логистическая регрессия, метод опорных векторов), так и современные методы на основе нейронных сетей.
- Программный прототип системы анализа тональности: разработка программного прототипа системы, способной автоматически обрабатывать и классифицировать отзывы и комментарии клиентов интернет-магазинов. Прототип будет включать в себя интерфейс для загрузки данных, предобработку текстов, применение моделей машинного обучения и вывод результатов.
- Тестирование и валидация: проведение тестирования и валидации разработанных моделей и программного прототипа на реальных данных от интернет-магазинов. Оценка эффективности алгоритмов на основе метрик качества, таких как точность, полнота и F1-мера.
- Интеграция в реальное окружение: практическое внедрение разработанного программного прототипа в один или несколько интернет-магазинов с целью оценки его работы в реальных условиях. Сбор обратной связи и данных о влиянии системы на бизнес-показатели.
- Анализ влияния на бизнес-показатели: оценка влияния внедрения системы анализа тональности на ключевые бизнес-показатели интернет-магазинов, такие как уровень удовлетворенности клиентов, объемы продаж, конверсия и репутация бренда.
- Документация и рекомендации: подготовка документации, включая техническое описание разработанных моделей и программного прототипа, методологии обработки данных и рекомендации по интеграции и использованию системы анализа тональности.
- Публикация научных статей и докладов: публикация результатов исследования в научных журналах, конференциях и семинарах для обмена знаний и опытом с научным сообществом.
3. Обзор исследований и разработок
Обзор исследований и разработок в области анализа тональности отзывов представляет собой важную составляющую понимания текущего состояния этой области исследований. Вот краткий обзор некоторых основных аспектов исследований и разработок в данной области:
Методы анализа тональности: исследователи разрабатывают различные методы анализа тональности текста, включая правила на основе словарей, машинное обучение и глубокое обучение. Методы машинного обучения, такие как модели на основе нейронных сетей, стали популярными инструментами для определения тональности.
Анализ сентимента в социальных медиа: с увеличением активности пользователей в социальных медиа, анализ тональности стал актуальным в контексте мониторинга общественного мнения и реакций в социальных медиа.
Анализ аспектов: вместо общей тональности текста исследователи также начали анализировать тональность относительно конкретных аспектов или характеристик продукта или услуги. Этот аспектно-ориентированный анализ позволяет более глубоко понимать мнение клиентов.
Применение в бизнесе: анализ тональности отзывов активно используется в бизнес-среде для оценки уровня удовлетворенности клиентов и управления репутацией бренда. Компании используют анализ сентимента для принятия решений по улучшению продуктов и услуг.
Нейронные сети и глубокое обучение: продвижение глубокого обучения привело к созданию мощных моделей для анализа тональности, таких как рекуррентные нейронные сети (RNN) и трансформеры. Эти модели демонстрируют высокую точность при определении сентимента в тексте.
Мультиязычный анализ: исследователи также работают над адаптацией методов анализа тональности к разным языкам, что позволяет проводить анализ мнений в многих различных языках.
Этические вопросы: с развитием технологий анализа тональности возникают этические вопросы, связанные с конфиденциальностью данных и потенциальным влиянием на общественное мнение.
3.1 Обзор международных источников
В современных исследованиях в области анализа тональности отзывов, авторы исследуют различные аспекты этой важной задачи. Например, в работе "Mining and Summarizing Customer Reviews" (M. Hu, B. Liu, и E. Lim, 2004), представлена методика для извлечения и суммирования отзывов на основе их тональности. Этот подход включает в себя анализ сентимента и выделение ключевых фраз, что позволяет пользователям быстро получать общее представление о мнениях клиентов.
Книга "Sentiment Analysis and Opinion Mining" (Liu, B., 2012) представляет обширный обзор методов анализа тональности и майнинга мнений. Она охватывает как основные концепции, так и практические алгоритмы, предоставляя читателям подробное понимание современных подходов к анализу тональности текста.
В работе "Aspect-Based Sentiment Analysis of Reviews" (L. Zhang, S. Liu, и M. Zhang, 2015), авторы исследуют аспектно-ориентированный анализ тональности отзывов. Они разрабатывают методы для определения тональности не только всего отзыва, но и для конкретных аспектов или характеристик продукта, что позволяет более глубоко понимать мнение клиентов.
Эта лишь малая часть обширной области исследований и разработок в анализе тональности отзывов. Исследователи также исследуют применение глубокого обучения в анализе тональности (см. "Deep Learning for Sentiment Analysis: A Survey" (X. Zhang, L. Zhao, и H. Leung, 2018)), а также адаптацию методов к специфическим отраслям (см. "Opinion Mining and Sentiment Analysis" (C. H. Hsu и M.-C. Ku, 2018)).
Книга "Sentiment Analysis in Social Media" (M. M. Rahman и D. I. Inoue, 2019) фокусируется на анализе тональности в социальных медиа, где мнения и отзывы пользователей часто выражаются в неформальной и сокращенной форме.
Эти работы подчеркивают важность и актуальность анализа тональности отзывов и служат основой для дальнейших исследований и разработок в этой области.
3.2 Обзор национальных источников
В области анализа тональности отзывов от авторов из стран СНГ проводятся активные исследования, охватывающие следующие аспекты:
В монографии "Анализ тональности текстовых данных" (А. Сошников, 2017) представлены методы анализа тональности текстов на русском языке, включая анализ сентимента и суммирование отзывов.
В статье "Анализ тональности текстов на русском языке: опыт и задачи" (С. И. Селегаев и др., 2018) рассматриваются особенности анализа тональности текстов на русском языке и методы для решения данной задачи.
Работа "Методы анализа тональности текстов и их применение" (А. Брилевский и Е. Шимова, 2019) представляет методы анализа тональности текстов и их применение в различных областях, включая анализ отзывов и мнений пользователей.
В статье "Сентимент-анализ: анализ тональности и настроений в социальных медиа" (В. В. Абрамов и М. В. Потапов, 2020) исследуются методы сентимент-анализа в социальных медиа на примере русскоязычных текстов.
Статья "Анализ тональности текста с помощью методов машинного обучения" (И. В. Щербаков и М. В. Дегтярев, 2021) обсуждает применение методов машинного обучения в задаче анализа тональности текста на русском языке.
Эти источники представляют собой важные ресурсы для исследователей и практиков, занимающихся анализом тональности текстов на русском языке в контексте стран СНГ.
3.3 Обзор локальных источников
Таций Е.В. Анохина И.Ю. Применение программных средств для обработки текстов на естественном языке. В статье описаны подходы представления смысла слова в цифровом виде. Проведён сравнительный анализ библиотек языка программирования python для получения вектора из слова, по которому можно оценить семантическую близость слов.
Пилипенко А.С. тоже касался этой темы в своей работе по исследованию методов и алгоритмов определения тональности естественно-языкового текста: он привел сравнение популярных средств, определяющих уникальность текста, а также отметил, что данные средства (сервисы Text.ru, Antiplagiat.ru, Advego Plagiatus, Etxt Антиплагиат), хоть и выделяют некоторые характеристики загруженного текста, но не определяют его тональность в том виде, в котором это предполагается в рамках поставленной задачи.
4. Применение алгоритмов машинного обучения для определения тональности текста отзывов в интернет магазинах
Рассматриваемая в моей магистрской работе архитектура CNN основана на подходах [1] и [2]. Подход [1], в котором используется ансамбль сверточных и рекуррентных сетей, на крупнейшем ежегодном соревновании по компьютерной лингвистике SemEval-2017 занял первые места [3] в пяти номинациях в задаче по анализу тональности Task 4.
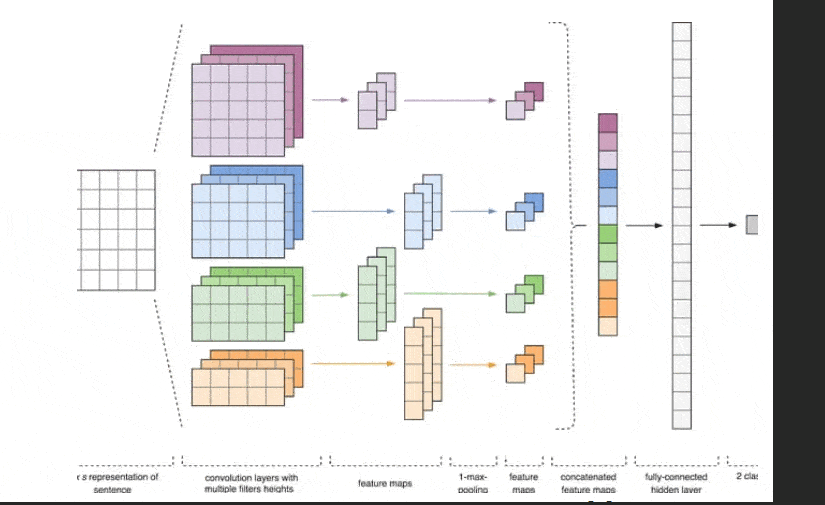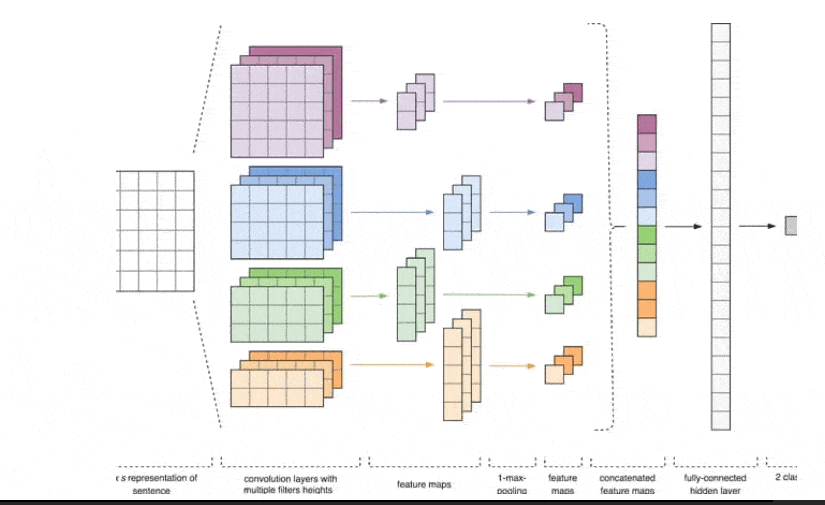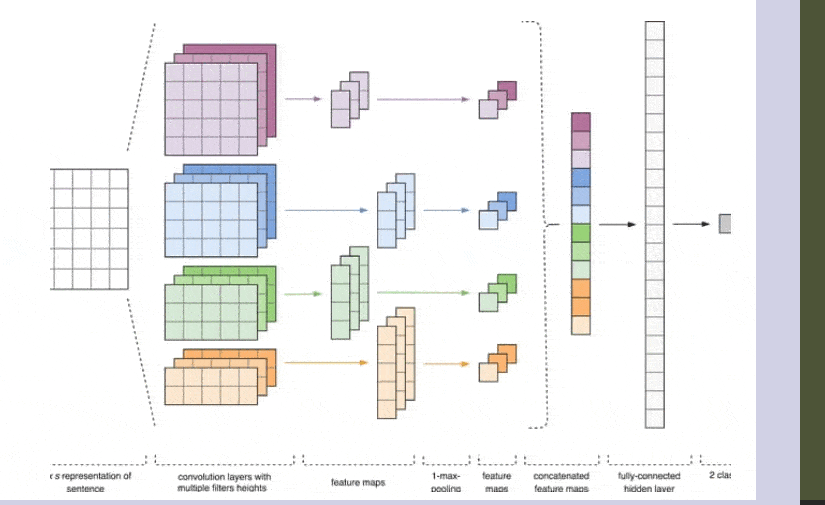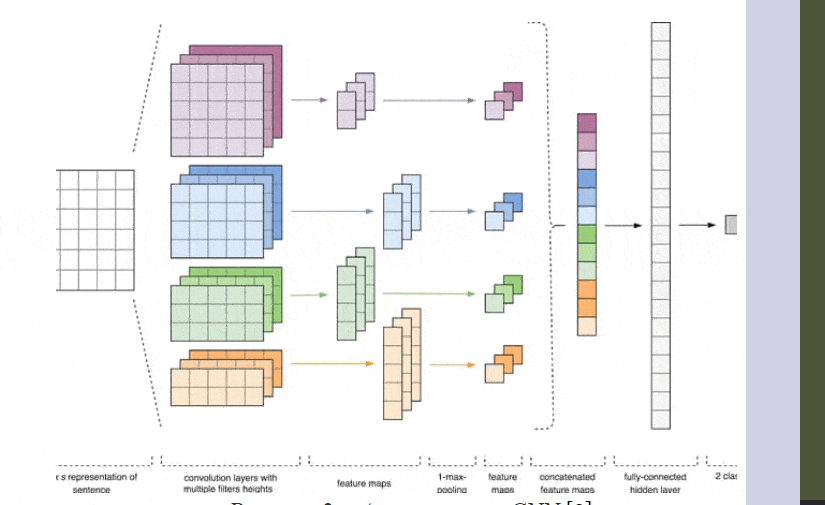
Рисунок 2 – Архитектура CNN [2].
Входными данными CNN (рис. 1) является матрица с фиксированной высотой n, где каждая строка представляет собой векторное отображение токена в признаковое пространство размерности k. Для формирования признакового пространства часто используют инструменты дистрибутивной семантики, такие как Word2Vec, Glove, FastText и т.д.
На первом этапе входная матрица обрабатывается слоями свертки. Как правило, фильтры имеют фиксированную ширину, равную размерности признакового пространства, а для подбора размеров у фильтров настраивается только один параметр — высота h. Получается, что h — это высота смежных строк, рассматриваемых фильтром совместно. Соответственно, размерность выходной матрицы признаков для каждого фильтра варьируется в зависимости от высоты этого фильтра h и высоты исходной матрицы n.[6]
Далее карта признаков, полученная на выходе каждого фильтра, обрабатывается слоем субдискретизации с определенной функцией уплотнения (на изображении — 1-max pooling), т.е. уменьшает размерность сформированной карты признаков. Таким образом извлекается наиболее важная информация для каждой свертки независимо от её положения в тексте. Другими словами, для используемого векторного отображения комбинация слоев свёртки и слоев субдискретизации позволяет извлекать из текста наиболее значимые n-граммы.
После этого карты признаков, рассчитанные на выходе каждого слоя субдискретизации, объединяются в один общий вектор признаков. Он подаётся на вход скрытому полносвязному слою, а потом поступает на выходной слой нейронной сети, где и рассчитываются итоговые метки классов.
Данные для обучения
Для обучения я выбрал корпус коротких текстов Юлии Рубцовой, сформированный на основе русскоязычных сообщений из Twitter [4]. Он содержит 114 991 положительных, 111 923 отрицательных твитов, а также базу неразмеченных твитов объемом 17 639 674 сообщений [7].
Перед началом обучения тексты прошли процедуру предварительной обработки:
- приведение к нижнему регистру;
- замена «ё» на «е»;
- замена ссылок на токен «URL»;
- замена упоминания пользователя на токен «USER»;
- удаление знаков пунктуации.
Далее я разбил набор данных на обучающую и тестовую выборку в соотношении 4:1.
Векторное отображение слов
Входными данными сверточной нейронной сети является матрица с фиксированной высотой n, где каждая строка представляет собой векторное отображение слова в признаковое пространство размерности k. Для формирования embedding-слоя нейронной сети я использовал утилиту дистрибутивной семантики Word2Vec [5], предназначенную для отображения семантического значения слов в векторное пространство. Word2Vec находит взаимосвязи между словами согласно предположению, что в похожих контекстах встречаются семантически близкие слова. Подробнее о Word2Vec можно прочитать в оригинальной статье, а также тут и тут. Поскольку твитам характерна авторская пунктуация и эмотиконы, определение границ предложений становится достаточно трудоемкой задачей. В этой работе я допустил, что каждый твит содержит лишь одно предложение.
База неразмеченных твитов хранится в SQL-формате и содержит более 17,5 млн. записей. Для удобства работы я конвертировал её в SQLite с помощью этого скрипта.
Далее с помощью библиотеки Gensim обучил Word2Vec-модель со следующими параметрами:
- size = 200 — размерность признакового пространства;
- window = 5 — количество слов из контекста, которое анализирует алгоритм;
- min_count = 3 — слово должно встречаться минимум три раза, чтобы модель его учитывала.
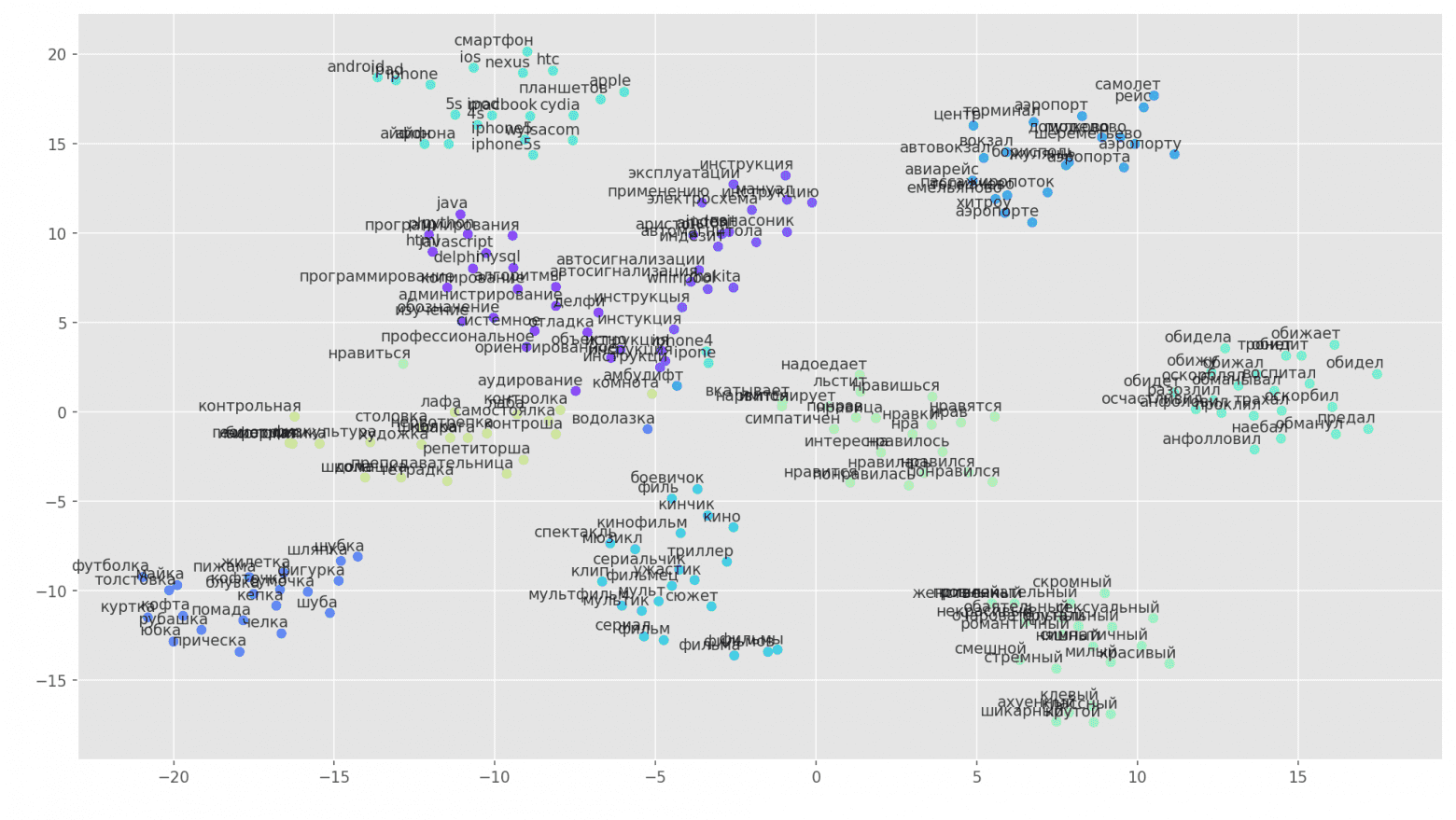
Рисунок 3. Визуализация кластеров похожих слов с использование t-SNE.
Для более детального понимания работы Word2Vec на рис. 2 представлена визуализация нескольких кластеров похожих слов из обученной модели, отображенных в двухмерное пространство с помощью алгоритма визуализации t-SNE [8].
Векторное отображение текстов
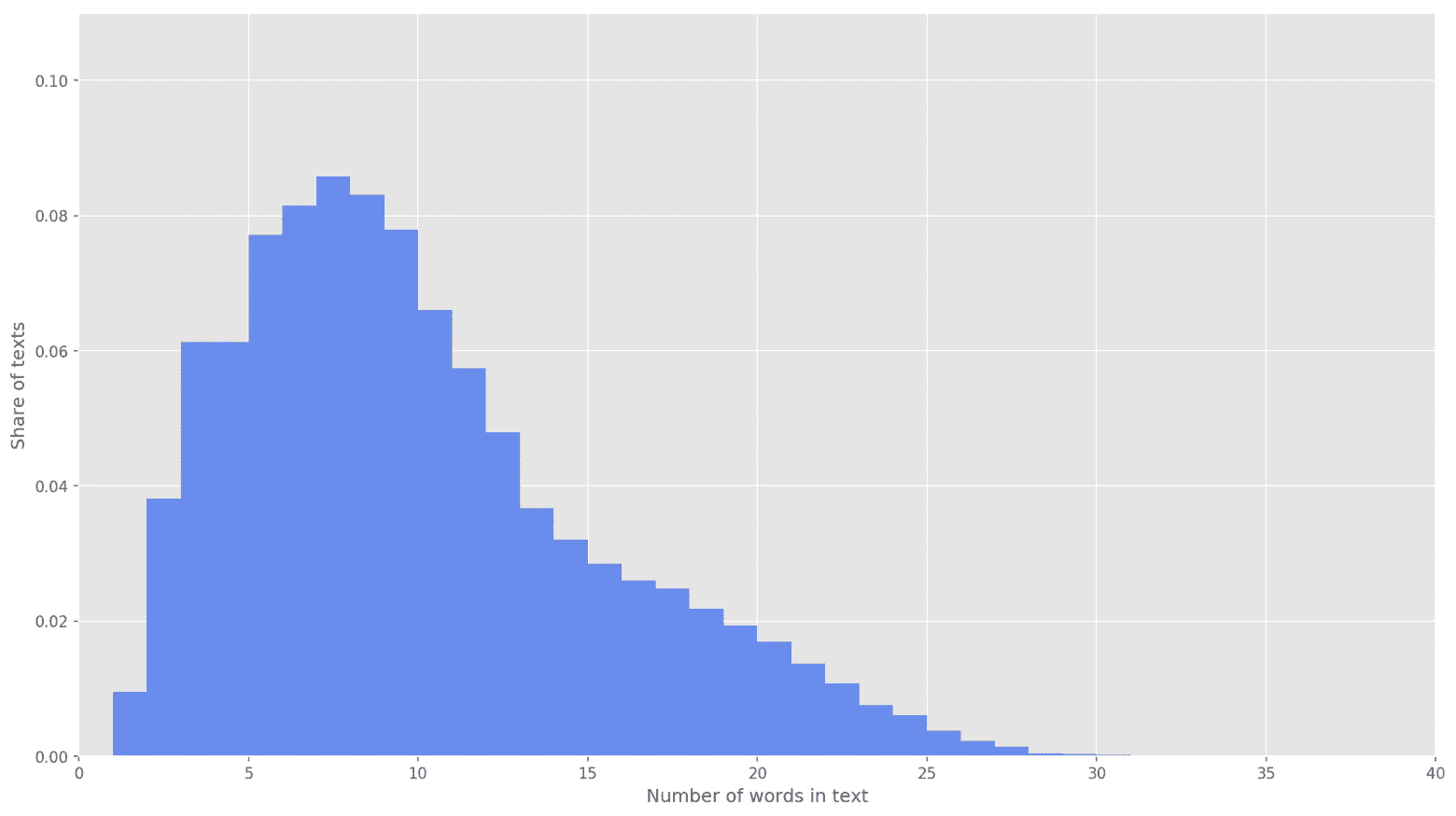
Рис 4. Распределение длины текстов.
На следующем этапе каждый текст был отображен в массив идентификаторов токенов. Я выбрал размерность вектора текста s=26, поскольку при данном значении полностью покрываются 99,71% всех текстов в сформированном корпусе (рис. 3). Если при анализе количество слов в твите превышало высоту матрицы, оставшиеся слова отбрасывались и не учитывались в классификации. Итоговая размерность матрицы предложения составила s?d=26?200.
Свёрточная нейронная сеть
Для построения нейронной сети я использовал библиотеку Keras, которая выступает высокоуровневой надстройкой над TensorFlow, CNTK и Theano. У Keras есть отличная документация, а также блог, который освещает многие задачи машинного обучения, к примеру, инициализацию embedding-слоя. В нашем случае embedding-слой был инициирован весами, полученными при обучении Word2Vec. Чтобы минимизировать изменения в embedding-слое, я заморозил его на первом этапе обучения.[9]
В разработанной архитектуре использованы фильтры с высотой h=(2, 3, 4, 5), которые предназначены для параллельной обработки биграмм, триграмм, 4-грамм и 5-грамм соответственно. Добавил в нейронную сеть по 10 свёрточных слоев для каждой высоты фильтра, функция активации — ReLU. С рекомендациями по поиску оптимальной высоты и количества фильтров можно ознакомиться в работе [10].
После обработки слоями свертки, карты признаков поступали на слои субдискретизации, где к ним применялась операция 1-max-pooling, тем самым извлекая наиболее значимые n-граммы из текста. На следующем этапе происходило объединение в общий вектор признаков (слой объединения), который подавался в скрытый полносвязный слой с 30 нейронами. На последнем этапе итоговая карта признаков подавалась на выходной слой нейронной сети с сигмоидальной функцией активации.
Поскольку нейронные сети склонны к переобучению, после embedding-слоя и перед скрытым полносвязным слоем я добавил dropout-регуляризацию c вероятностью выброса вершины p=0.2.
Итоговую модель сконфигурировал с функцией оптимизации Adam (Adaptive Moment Estimation) и бинарной кросс-энтропией в качестве функции ошибок. Качество работы классификатора оценивал в критериях макро-усредненных точности, полноты и f-меры.
На первом этапе обучения заморозил embedding-слой, все остальные слои обучались в течение 10 эпох:
- Размер группы примеров, используемых для обучения: 32.
- Размер валидационной выборки: 25%.
Train on 134307 samples, validate on 44769 samples
Epoch 1/10134307/134307 [==============================] - 221s 2ms/step - loss: 0.5703 - precision: 0.7006 - recall: 0.6854 - f1: 0.6839 - val_loss: 0.5014 - val_precision: 0.7538 - val_recall: 0.7493 - val_f1: 0.7452
Epoch 2/10134307/134307 [==============================] - 218s 2ms/step - loss: 0.5157 - precision: 0.7422 - recall: 0.7258 - f1: 0.7263 - val_loss: 0.4911 - val_precision: 0.7413 - val_recall: 0.7924 - val_f1: 0.7602
Epoch 3/10134307/134307 [==============================] - 213s 2ms/step - loss: 0.5023 - precision: 0.7502 - recall: 0.7337 - f1: 0.7346 - val_loss: 0.4825 - val_precision: 0.7750 - val_recall: 0.7411 - val_f1: 0.7512
Epoch 4/10134307/134307 [==============================] - 215s 2ms/step - loss: 0.4956 - precision: 0.7545 - recall: 0.7412 - f1: 0.7407 - val_loss: 0.4747 - val_precision: 0.7696 - val_recall: 0.7590 - val_f1: 0.7584
Epoch 5/10134307/134307 [==============================] - 229s 2ms/step - loss: 0.4891 - precision: 0.7587 - recall: 0.7492 - f1: 0.7473 - val_loss: 0.4781 - val_precision: 0.8014 - val_recall: 0.7004 - val_f1: 0.7409
Epoch 6/10134307/134307 [==============================] - 217s 2ms/step - loss: 0.4830 - precision: 0.7620 - recall: 0.7566 - f1: 0.7525 - val_loss: 0.4749 - val_precision: 0.7877 - val_recall: 0.7411 - val_f1: 0.7576
p> Epoch 7/10134307/134307 [==============================] - 219s 2ms/step - loss: 0.4802 - precision: 0.7632 - recall: 0.7568 - f1: 0.7532 - val_loss: 0.4730 - val_precision: 0.7969 - val_recall: 0.7241 - val_f1: 0.7522
Epoch 8/10134307/134307 [==============================] - 215s 2ms/step - loss: 0.4769 - precision: 0.7644 - recall: 0.7605 - f1: 0.7558 - val_loss: 0.4680 - val_precision: 0.7829 - val_recall: 0.7542 - val_f1: 0.7619
p> Epoch 9/10134307/134307 [==============================] - 227s 2ms/step - loss: 0.4741 - precision: 0.7657 - recall: 0.7663 - f1: 0.7598 - val_loss: 0.4672 - val_precision: 0.7695 - val_recall: 0.7784 - val_f1: 0.7682
p> Epoch 10/10134307/134307 [==============================] - 221s 2ms/step - loss: 0.4727 - precision: 0.7670 - recall: 0.7647 - f1: 0.7590 - val_loss: 0.4673 - val_precision: 0.7833 - val_recall: 0.7561 - val_f1: 0.7636
p>Наивысший показатель F1=76.80% на валидационной выборке был достигнут на третьей эпохе обучения. Качество работы обученной модели на тестовых данных составило F1=78.1%.
Таблица 1. Качество анализа тональности на тестовых данных.
| Метка класса | Точность | Полнота | F1 | Количество объектов |
|---|---|---|---|---|
| Negative | 0.78194 | 0.78243 | 0.78218 | 22457 |
| Positive | 0.78089 | 0.78040 | 0.78064 | 22313 |
| avg / total | 0.78142 | 0.78142 | 0.78142 | 44770 |
Результат
В качестве baseline-решения я обучил наивный байесовский классификатор с мультиномиальной моделью распределения, результаты сравнения представлены в табл. 2. [11]
Таблица 2. Сравнение качества анализа тональности.
| Классификатор | Precision | Recall | F1 |
|---|---|---|---|
| MNB | 0.78194 | 0.7564 | 0.7560 |
| CNN | 0.78142 | 0.78142 | 0.78142 |
Выводы
Как видите, качество классификации CNN превысило MNB на несколько процентов. Значения метрик можно увеличить еще больше, если поработать над оптимизацией гиперпараметров и архитектуры сети. К примеру, можно изменить количество эпох обучения, проверить эффективность использования различных векторных представлений слов и их комбинаций, подобрать количество фильтров и их высоту, реализовать более эффективную предобработку текстов (исправление опечаток, нормализация, стемминг), настроить количество скрытых полносвязных слоев и нейронов в них.
Дальнейшие исследования направлены на следующие аспекты:
- Улучшение точности алгоритмов: Повышение точности определения тональности текста отзывов с использованием более сложных алгоритмов машинного обучения и усовершенствованных методов предобработки текста.
- Мультиязыковый анализ: Расширение возможностей анализа до мультиязычных данных, включая разработку моделей, способных работать с разными языками и диалектами.
- Адаптация известных методов построения логических схем автоматов Мура к базису FPGA.
- Адаптация к специфическим отраслям: Исследование методов, позволяющих адаптировать алгоритмы анализа тональности к специфическим отраслям, таким как техническая поддержка, медицина или гостиничный бизнес.
- Анализ многомерных тональностей: Развитие методов, которые позволят учитывать множество аспектов и тональностей в одном тексте, так как отзывы могут быть более сложными и содержать разные аспекты.
- Учет контекста: Улучшение анализа тональности с учетом контекста, включая определение, как изменения в продукте или обслуживании влияют на тональность отзывов.
- Анализ эмоций и настроений: Расширение анализа отзывов до определения эмоций и настроений, что может предоставить дополнительную информацию о клиентском опыте.
- Автоматический отклик на отзывы: Разработка систем, способных автоматически реагировать на отзывы, включая генерацию персонализированных ответов.
- Интеграция с интеллектуальными ассистентами: Исследование возможности интеграции алгоритмов анализа тональности с интеллектуальными ассистентами для автоматической обработки и анализа клиентских комментариев.
- Борьба с фейковыми отзывами: Разработка методов для выявления и фильтрации фейковых отзывов, которые могут исказить результаты анализа.
- Сравнительный анализ платформ и инструментов: Сравнение различных платформ и инструментов для анализа тональности и выбор наиболее подходящих для конкретных задач и отраслей.
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: декабрь 2011 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Список источников
- Cliche M. BB_twtr at SemEval-2017 Task 4: Twitter Sentiment Analysis with CNNs and LSTMs //Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017). — 2017. — С. 573-580.
- Zhang Y., Wallace B. A Sensitivity Analysis of (and Practitioners' Guide to) Convolutional Neural Networks for Sentence Classification //arXiv preprint arXiv:1510.03820. — 2015.
- Rosenthal S., Farra N., Nakov P. SemEval-2017 task 4: Sentiment Analysis in Twitter //Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017). — 2017. — С. 502-518.
- Ю. В. Рубцова. Построение корпуса текстов для настройки тонового классификатора // Программные продукты и системы, 2015, №1(109), —С.72-78.
- Mikolov T. et al. Distributed Representations of Words and Phrases and Their Compositionality //Advances in Neural Information Processing Systems. — 2013. — С. 3111-3119.
- Sentiment Analysis: A Practitioner's Guide to NLP by Delip Rao and Brian McMahan – Электронная книга – URL: https://booksdrive.org/wp-content/uploads/2022/04/Natural-Language-Processing-with-PyTorch-by-Delip-Rao-pdf-free-download.pdf (дата обращения 23.10.2023). – Режим доступа: свободный
- Python Machine Learning by Sebastian Raschka – Электронная книга – URL: https://booksdrive.org/wp-content/uploads/2022/04/Python-Machine-Learning-pdf-free-download.pdf (дата обращения 23.10.2023). – Режим доступа: свободный
- Opinion Mining and Sentiment Analysis by Bo Pang and Lillian Lee – Электронная книга – URL: https://www.cse.iitb.ac.in/~pb/cs626-449-2009/prev-years-other-things-nlp/sentiment-analysis-opinion-mining-pang-lee-omsa-published.pdf (дата обращения 23.10.2023). – Режим доступа: свободный
- Sentiment Analysis and Opinion Mining by Bing Liu – Электронная книга – URL: https://www.cs.uic.edu/~liub/FBS/SentimentAnalysis-and-OpinionMining.pdf (дата обращения 23.10.2023). – Режим доступа: свободный
- Mining the Social Web: Analyzing Data from Facebook, Twitter, LinkedIn, and Other Social Media Sites by Matthew A. Russell – Электронная книга – URL: https://books.google.ru/books?id=SYM1lrQdrdsC&printsec=frontcover&hl=ru&source=gbs_ge_summary_r&cad=0#v=onepage&q&f =false (дата обращения 23.10.2023). – Режим доступа: свободный
- Sentiment Analysis: Mining Opinions, Sentiments, and Emotions by Bing Liu – Электронная книга – URL: https://aclanthology.org/J16-3008.pdf (дата обращения 23.10.2023). – Режим доступа: свободный