
Abstract of the Graduation Thesis
Table of Contents
- Introduction
- 1. Relevance of the Topic
- 2. Research Objective, Tasks, and Expected Results
- 3. Review of Research and Developments
- 3.1 Review of International Sources
- 3.2 Review of National Sources
- 3.3 Review of Local Sources
- 4. Application of machine learning algorithms to determine the tone of the text of reviews in online stores
- Conclusions
- List of Sources
Introduction
In today's world, online stores have become an integral part of everyday life, providing consumers with unprecedented freedom of choice when it comes to products and services. However, in this vast digital environment, feedback from consumers plays a critical role. Reviews, comments, and ratings of products left by customers can significantly impact the reputation and success of an online store.
In this context, sentiment analysis of review text becomes a key tool for understanding customer opinions and evaluating the quality of offered products and services. Machine learning algorithms provide a powerful toolkit for the automatic processing and classification of text based on sentiment. They not only allow the identification of positive and negative reviews but also enable the analysis of their content, highlighting key aspects that consumers pay attention to.
1. Relevance of the Topic
In the modern world, online stores have become an integral part of our daily lives, offering a vast array of products and services. However, with the increasing number of internet users, customer feedback has become not only important but also voluminous. Customer reviews and comments on products and services have a significant influence on a brand's reputation and the decision-making of potential customers.
This is where machine learning algorithms come into play, providing an efficient tool for analyzing the sentiment of review text. This technology is becoming relevant for several key reasons.
Firstly, the volume of data in online stores is constantly growing. Customer reviews and comments generate a vast amount of textual information that needs analysis. Machine learning algorithms help automate this process and identify important trends and patterns.
Secondly, the impact of reputation is more crucial than ever. Ratings and reviews of products and services can have a decisive impact on customer decisions. Internet stores aim to maintain a high reputation, and to do so, they need to quickly and accurately analyze numerous reviews.
Thirdly, sentiment analysis of text helps improve customer service quality. This analysis allows for the identification of weaknesses in service and prompt responses to negative feedback. This contributes to the improvement of the quality of services and products provided.
Fourthly, competition in the e-commerce sector is fierce, and it is important to know what your customers think and which aspects of their experience require improvement. Machine learning algorithms enable the detection of trends and patterns in reviews, helping to stay one step ahead of competitors.
Fifthly, efficiency and resource-saving are becoming increasingly important in business. Automated analysis of textual reviews using machine learning algorithms helps save resources and time that were previously required for manual review processing and analysis.
Finally, the development of artificial intelligence makes the application of machine learning algorithms for text analysis increasingly accessible and effective. This technology continues to evolve and find new applications in the field of online stores.
All of these factors make sentiment analysis of review text an extremely relevant topic for online stores and e-commerce enterprises that seek to improve their business and meet consumer needs in a rapidly changing digital environment.
2. Research Objective, Tasks, and Expected Results
The objective of this research is to study and analyze the application of machine learning algorithms for sentiment analysis of reviews in online stores with the aim of improving customer service quality, enhancing brand reputation, and increasing competitiveness.
The main research tasks are as follows:
- Literature Review: conduct a review of existing literature and research in the field of sentiment analysis of text and its application in online stores.
- Data Collection: gather and prepare datasets containing textual reviews from various online stores.
- Data Preprocessing: perform preprocessing of textual data, including tokenization, stop-word removal, lemmatization, and cleaning from specific symbols.
- Model Development: create machine learning models, including classifiers for determining the sentiment of text (positive, negative, neutral).
- Testing and Evaluation: test the developed models on test data using quality metrics such as accuracy, recall, F1-score, and others.
- Integration into Practice: explore the possibilities of integrating the developed models into real online stores and assess their effectiveness in real-world conditions.
- Analysis of Results: analyze the research results, identify the advantages and limitations of applying machine learning algorithms for sentiment analysis of text in online stores.
Expected Results:
- Development and optimization of machine learning models for sentiment analysis of text.
- Effective methods for preprocessing textual data.
- Improved customer service quality in online stores through rapid analysis and response to reviews.
- Enhanced brand reputation and increased customer satisfaction levels.
- Practical recommendations for implementing research results into the business processes of online stores.
Research Object: processes of sentiment analysis of reviews in online stores.
Research Subject: machine learning algorithms used for determining the sentiment of reviews in online stores.
Within the framework of the master's thesis, it is planned to obtain relevant scientific results in the following directions:
- Development and Comparative Analysis of Machine Learning Algorithms: research and development of various machine learning models for determining the sentiment of reviews, such as methods based on neural networks, statistical methods, and ensemble methods. Comparative analysis of their effectiveness on different types of data and scenarios.
- Integration into Business Processes: investigation of methods for integrating the developed algorithms into the practices of online stores. Development of a prototype sentiment analysis system capable of automatically processing and classifying reviews, and its testing on real data.
- Optimization of Data Preprocessing Processes: research on methods to optimize the preprocessing of textual data to reduce noise and improve the quality of analysis. This includes identifying best practices for cleaning and structuring text.
- Specialized Adaptations for Online Stores: development of specialized adaptations of algorithms to account for the unique characteristics of reviews and comments in online stores, such as specific terms, expressive language, and synonyms.
- Evaluation of Impact on Business Metrics: analysis of the impact of implementing sentiment analysis systems on key business metrics of online stores, such as customer satisfaction, sales volumes, conversion rates, and brand reputation.
- Ethical and Legal Analysis: examination of ethical and legal issues related to automatic analysis of customer reviews and comments, including data privacy concerns and compliance with consumer protection legislation.
- Future Development and Prospects: development of recommendations for the future development of sentiment analysis systems and exploration of the prospects for applying new methods and technologies in this field.
For the experimental evaluation of the obtained theoretical results and the formation of a foundation for further research, the practical results are planned as follows:
- Development and Training of Machine Learning Models: creating and training various machine learning models for sentiment analysis of reviews on real datasets from online stores. These models will include both classical algorithms (e.g., logistic regression, support vector machines) and modern methods based on neural networks.
- Software Prototype of Sentiment Analysis System: developing a software prototype of a system capable of automatically processing and classifying customer reviews and comments from online stores. The prototype will include an interface for data input, text preprocessing, application of machine learning models, and result output.
- Testing and Validation: conducting testing and validation of the developed models and the software prototype on real data from online stores. Evaluating the effectiveness of algorithms based on quality metrics such as accuracy, recall, and F1-score.
- Integration into Real Environment: practical implementation of the developed software prototype in one or more online stores to assess its performance in real conditions. Collecting feedback and data on the system's impact on business metrics.
- Analysis of Impact on Business Metrics: evaluating the impact of implementing the sentiment analysis system on key business metrics of online stores, such as customer satisfaction, sales volumes, conversion rates, and brand reputation.
- Documentation and Recommendations: preparing documentation, including technical descriptions of the developed models and the software prototype, data processing methodologies, and recommendations for integration and use of the sentiment analysis system.
- Publication of Research Papers and Reports: publishing the research results in scientific journals, conferences, and seminars to share knowledge and experience with the scientific community.
3. Review of Research and Developments
Reviewing research and developments in the field of sentiment analysis of reviews is an important component in understanding the current state of this research area. Here is a brief overview of some key aspects of research and developments in this field:
Sentiment Analysis Methods: researchers are developing various methods for analyzing the sentiment of text, including rule-based approaches, machine learning, and deep learning. Machine learning methods, such as neural network-based models, have become popular tools for sentiment analysis.
Sentiment Analysis in Social Media: with the increasing activity of users on social media, sentiment analysis has become relevant in monitoring public opinion and reactions in social media.
Aspect-Based Analysis: instead of analyzing the overall sentiment of text, researchers have also started to analyze sentiment with respect to specific aspects or characteristics of a product or service. This aspect-oriented analysis allows for a deeper understanding of customer opinions.
Application in Business: sentiment analysis of reviews is actively used in the business environment to assess customer satisfaction levels and manage brand reputation. Companies use sentiment analysis to make decisions about improving products and services.
Neural Networks and Deep Learning: the advancement of deep learning has led to the development of powerful models for sentiment analysis, such as recurrent neural networks (RNNs) and transformers. These models demonstrate high accuracy in detecting sentiment in text.
Multi-Lingual Analysis: researchers are also working on adapting sentiment analysis methods to different languages, enabling sentiment analysis in many different languages.
Ethical Issues: as sentiment analysis technology advances, ethical questions arise concerning data privacy and potential influence on public opinion.
3.1 Review of International Sources
In contemporary research on sentiment analysis of reviews, authors investigate various aspects of this important task. For example, in the work "Mining and Summarizing Customer Reviews" (M. Hu, B. Liu, and E. Lim, 2004), a methodology for extracting and summarizing reviews based on their sentiment is presented. This approach involves sentiment analysis and the extraction of key phrases, allowing users to quickly get an overview of customer opinions.
The book "Sentiment Analysis and Opinion Mining" (Liu, B., 2012) provides an extensive overview of sentiment analysis and opinion mining methods. It covers both fundamental concepts and practical algorithms, offering readers a detailed understanding of modern approaches to text sentiment analysis.
In the paper "Aspect-Based Sentiment Analysis of Reviews" (L. Zhang, S. Liu, and M. Zhang, 2015), the authors investigate aspect-oriented sentiment analysis of reviews. They develop methods to determine sentiment not only for the entire review but also for specific aspects or characteristics of a product, allowing for a deeper understanding of customer opinions.
This is only a small part of the extensive research and development landscape in the field of review sentiment analysis. Researchers also explore the application of deep learning in sentiment analysis (see "Deep Learning for Sentiment Analysis: A Survey" by X. Zhang, L. Zhao, and H. Leung, 2018), as well as the adaptation of methods to specific industries (see "Opinion Mining and Sentiment Analysis" by C. H. Hsu and M.-C. Ku, 2018).
The book "Sentiment Analysis in Social Media" (M. M. Rahman and D. I. Inoue, 2019) focuses on sentiment analysis in social media, where user opinions and reviews are often expressed in informal and abbreviated forms.
These works underscore the importance and relevance of sentiment analysis of reviews and serve as a foundation for further research and developments in this field.
3.2 Review of National Sources
In the field of sentiment analysis of reviews, researchers from CIS countries are actively conducting research covering the following aspects:
In the monograph (A. Soshnikov, 2017), methods for analyzing text sentiment in Russian, including sentiment analysis and review summarization, are presented.
The article (S. I. Selegaev et al., 2018) discusses the specific challenges of sentiment analysis of Russian texts and methods for addressing this task.
The work (A. Brilevskiy and E. Shimova, 2019) presents methods for analyzing text sentiment and their application in various domains, including the analysis of user reviews and opinions.
In the article (V. V. Abramov and M. V. Potapov, 2020), sentiment analysis methods in social media are explored, focusing on Russian-language texts.
The article (I. V. Shcherbakov and M. V. Degtyarev, 2021) discusses the application of machine learning methods in sentiment analysis of Russian texts.
These sources serve as important resources for researchers and practitioners involved in text sentiment analysis in the context of CIS countries.
3.3 Review of Local Sources
In the paper by E.V. Tatsiy and I.Yu. Anokhina, (Application of Software Tools for Natural Language Text Processing), approaches to representing the meaning of words in digital form are described. A comparative analysis of Python programming language libraries for obtaining word vectors, which can be used to assess semantic similarity between words, is conducted.
A.S. Pilipenko also touched upon this topic in his research on methods and algorithms for determining the sentiment of natural language text. He provided a comparison of popular tools that assess text uniqueness but noted that these tools (such as Text.ru, Antiplagiat.ru, Advego Plagiatus, Etxt ) highlight certain characteristics of uploaded text but do not determine its sentiment as intended in the research task.
4. Application of machine learning algorithms to determine the tone of the text of reviews in online stores
The architecture of the CNN discussed in my master's thesis is based on the approaches [1] and [2]. Approach [1], which utilizes an ensemble of convolutional and recurrent networks, achieved top rankings [3] in five categories in the sentiment analysis Task 4 of the largest annual competition in computational linguistics, SemEval-2017.
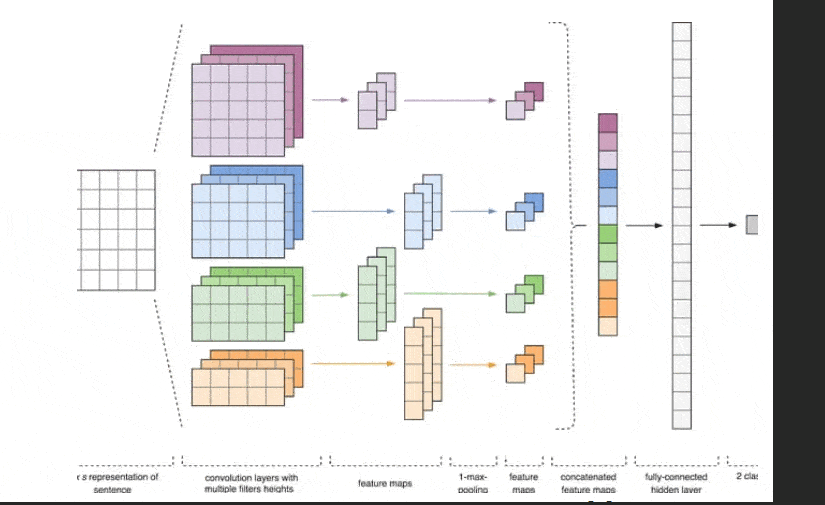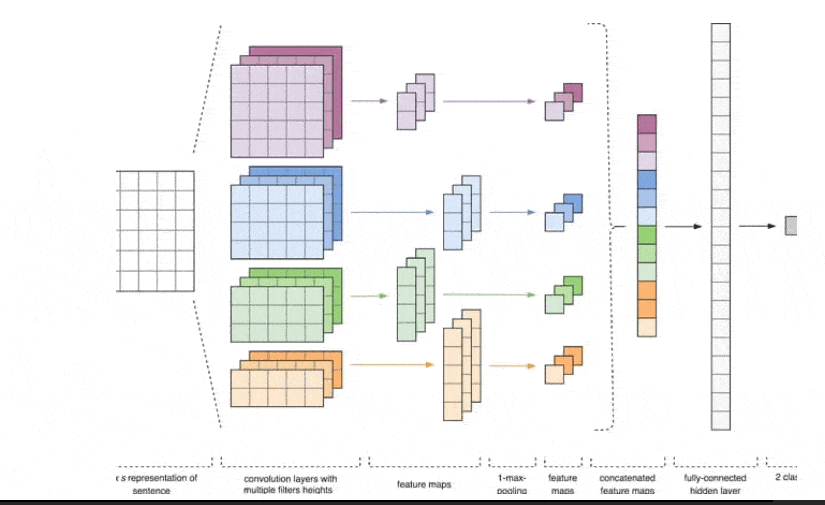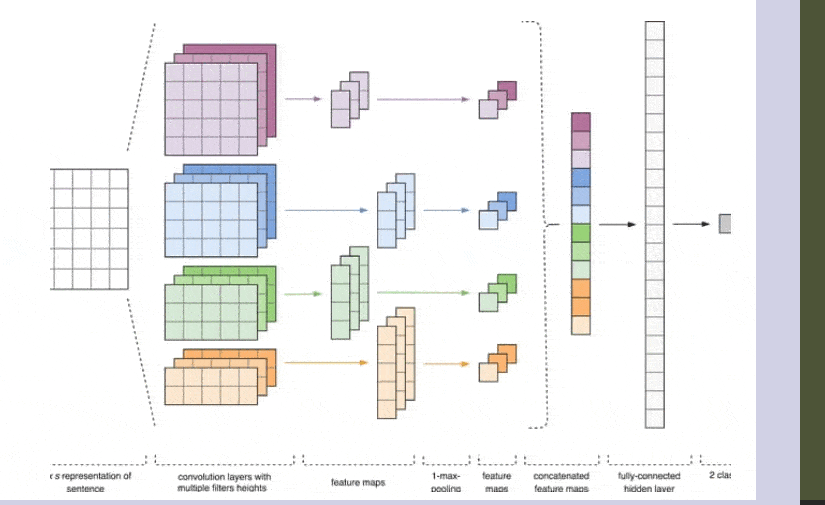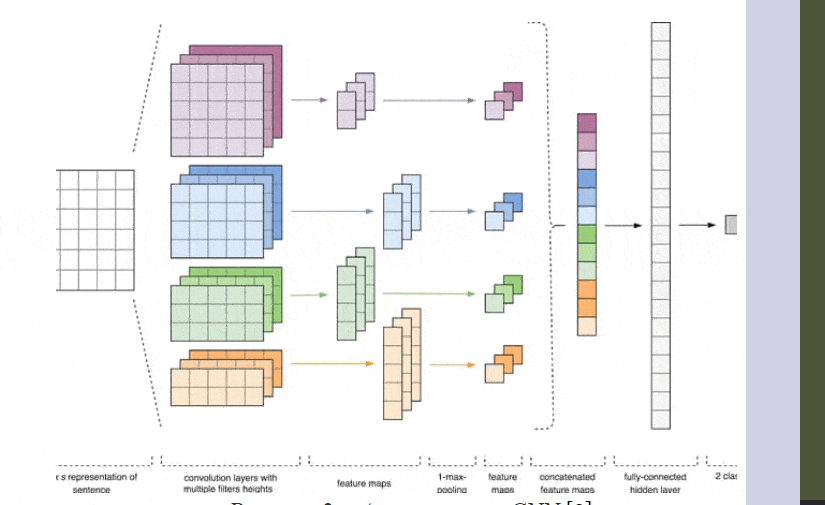
Figure 1 - CNN Architecture [2].
The input data for the CNN (Fig. 1) is a matrix with a fixed height of n, where each row represents a vector mapping of a token to a feature space of dimension k. To create a feature space, tools of distributional semantics are often used, such as Word2Vec, Glove, FastText, and others.
At the first stage, the input matrix is processed by convolutional layers. Filters usually have a fixed width equal to the dimension of the feature space, and only one parameter, the height h, is adjusted to select the filter sizes. Thus, h is the height of adjacent rows jointly considered by the filter. Accordingly, the dimension of the output feature matrix for each filter varies depending on the height of that filter h and the height of the original matrix n.
Next, the feature map obtained at the output of each filter is processed by a subsampling layer with a specific compression function (1-max pooling in the image), i.e., it reduces the dimensionality of the formed feature map. This way, the most important information is extracted for each convolution, regardless of its position in the text. In other words, the combination of convolutional layers and subsampling layers using the vector mapping allows the extraction of the most significant n-grams from the text.
Afterward, the feature maps calculated at the output of each subsampling layer are combined into a single common feature vector. It is fed to a hidden fully connected layer, and then it goes to the output layer of the neural network, where the final class labels are calculated.
Training Data
For training, I selected a corpus of short texts by Yulia Rubtsova, compiled based on Russian-language Twitter messages [4]. It contains 114,991 positive, 111,923 negative tweets, as well as an unlabeled tweet database with 17,639,674 messages.
Before training, the texts underwent preprocessing:
- converted to lowercase;
- replaced "?" with "?";
- replaced links with the "URL" token;
- replaced user mentions with the "USER" token;
- removed punctuation.
Next, I split the dataset into a training and a test set in a 4:1 ratio.
Word Embedding
The input data for the convolutional neural network is a matrix with a fixed height of n, where each row represents a vector mapping of a word to a feature space of dimension k. To create the embedding layer of the neural network, I used the Word2Vec distributional semantics utility [5], designed to map the semantic meaning of words into a vector space. Word2Vec finds relationships between words based on the assumption that semantically similar words appear in similar contexts. You can read more about Word2Vec in the original paper, as well as here and here. Since tweets often contain author-specific punctuation and emojis, sentence boundary detection becomes a challenging task. In this work, I assumed that each tweet contains only one sentence.
The unlabeled tweet database is stored in SQL format and contains over 17.5 million records. For convenience, I converted it to SQLite using this script.
Next, I trained a Word2Vec model using the Gensim library with the following parameters:
- size = 200 — dimensionality of the feature space;
- window = 5 — the number of words from the context that the algorithm analyzes;
- min_count = 3 — a word must occur at least three times to be considered by the model.
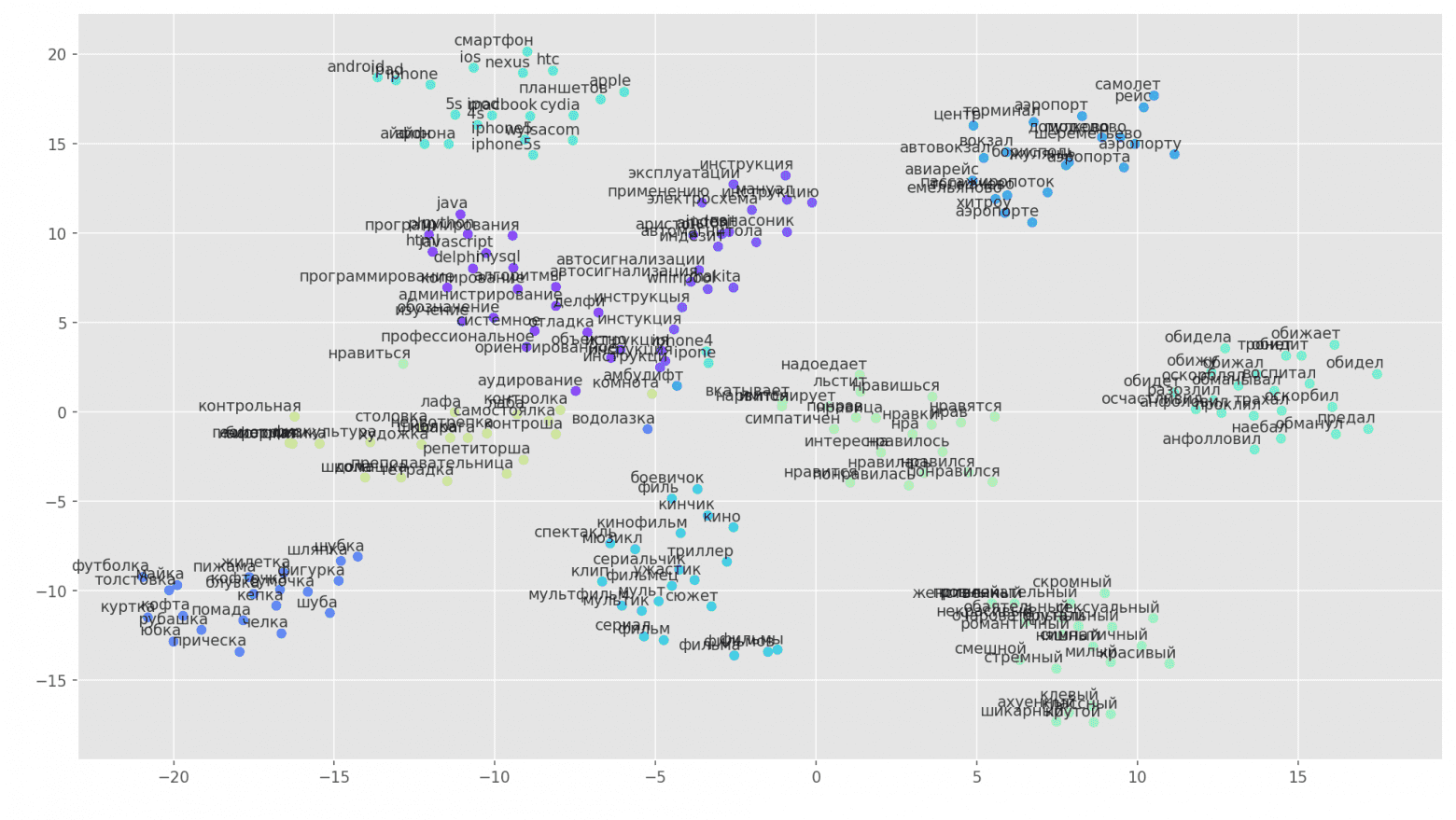
Figure 2. Visualization of clusters of similar words using t-SNE.
For a more detailed understanding of how Word2Vec works, Figure 2 shows a visualization of several clusters of similar words from the trained model, displayed in two-dimensional space using the t-SNE visualization algorithm.
Word Embedding
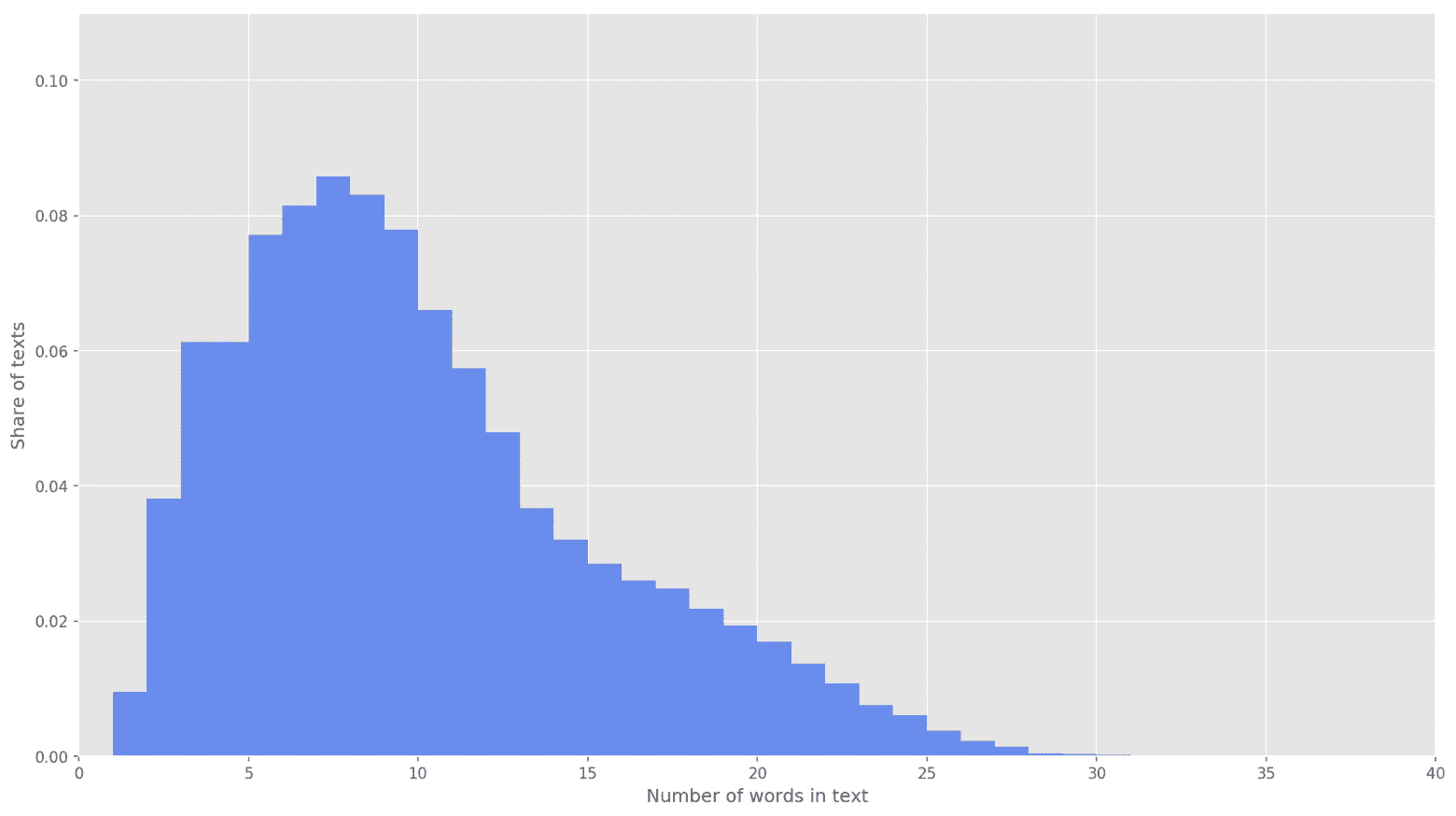
Figure 3. Distribution of text lengths.
In the next stage, each text was mapped to an array of token identifiers. I chose the dimensionality of the text vector to be s=26, as at this value, it fully covers 99.71% of all texts in the formed corpus (Figure 3). If the number of words in a tweet exceeded the matrix height, the remaining words were discarded and not considered in the classification. The resulting dimension of the sentence matrix was s?d=26?200.
Convolutional Neural Network
To build the neural network, I used the Keras library, which serves as a high-level wrapper for TensorFlow, CNTK, and Theano. Keras has excellent documentation and a blog that covers many machine learning tasks, such as initializing the embedding layer. In our case, the embedding layer was initialized with weights obtained during Word2Vec training. To minimize changes in the embedding layer, I froze it in the initial training stage.
In the developed architecture, filters with a height of h=(2, 3, 4, 5) are used, which are intended for parallel processing of bigrams, trigrams, 4-grams, and 5-grams, respectively. I added 10 convolutional layers for each filter height to the neural network, with ReLU activation function. Recommendations for finding the optimal filter height and count can be found in [2].
After being processed by convolutional layers, feature maps were passed to subsampling layers, where the 1-max-pooling operation was applied to extract the most significant n-grams from the text. In the next stage, these feature maps were merged into a common feature vector (a pooling layer), which was then fed into a hidden fully connected layer with 30 neurons. In the final stage, the resulting feature map was passed to the output layer of the neural network with a sigmoid activation function.
Since neural networks are prone to overfitting, I added dropout regularization with a dropout probability of p=0.2 after the embedding layer and before the hidden fully connected layer.
I configured the final model with the Adam optimization function and binary cross-entropy as the loss function. The performance of the classifier was evaluated in terms of macro-averaged precision, recall, and F1-score.
In the initial training stage, I froze the embedding layer, and all other layers were trained for 10 epochs:
- Batch size for training examples: 32.
- Validation set size: 25%.
Train on 134307 samples, validate on 44769 samples
Epoch 1/10134307/134307 [==============================] - 221s 2ms/step - loss: 0.5703 - precision: 0.7006 - recall: 0.6854 - f1: 0.6839 - val_loss: 0.5014 - val_precision: 0.7538 - val_recall: 0.7493 - val_f1: 0.7452
Epoch 2/10134307/134307 [==============================] - 218s 2ms/step - loss: 0.5157 - precision: 0.7422 - recall: 0.7258 - f1: 0.7263 - val_loss: 0.4911 - val_precision: 0.7413 - val_recall: 0.7924 - val_f1: 0.7602
Epoch 3/10134307/134307 [==============================] - 213s 2ms/step - loss: 0.5023 - precision: 0.7502 - recall: 0.7337 - f1: 0.7346 - val_loss: 0.4825 - val_precision: 0.7750 - val_recall: 0.7411 - val_f1: 0.7512
Epoch 4/10134307/134307 [==============================] - 215s 2ms/step - loss: 0.4956 - precision: 0.7545 - recall: 0.7412 - f1: 0.7407 - val_loss: 0.4747 - val_precision: 0.7696 - val_recall: 0.7590 - val_f1: 0.7584
Epoch 5/10134307/134307 [==============================] - 229s 2ms/step - loss: 0.4891 - precision: 0.7587 - recall: 0.7492 - f1: 0.7473 - val_loss: 0.4781 - val_precision: 0.8014 - val_recall: 0.7004 - val_f1: 0.7409
Epoch 6/10134307/134307 [==============================] - 217s 2ms/step - loss: 0.4830 - precision: 0.7620 - recall: 0.7566 - f1: 0.7525 - val_loss: 0.4749 - val_precision: 0.7877 - val_recall: 0.7411 - val_f1: 0.7576
Epoch 7/10134307/134307 [==============================] - 219s 2ms/step - loss: 0.4802 - precision: 0.7632 - recall: 0.7568 - f1: 0.7532 - val_loss: 0.4730 - val_precision: 0.7969 - val_recall: 0.7241 - val_f1: 0.7522
Epoch 8/10134307/134307 [==============================] - 215s 2ms/step - loss: 0.4769 - precision: 0.7644 - recall: 0.7605 - f1: 0.7558 - val_loss: 0.4680 - val_precision: 0.7829 - val_recall: 0.7542 - val_f1: 0.7619
Epoch 9/10134307/134307 [==============================] - 227s 2ms/step - loss: 0.4741 - precision: 0.7657 - recall: 0.7663 - f1: 0.7598 - val_loss: 0.4672 - val_precision: 0.7695 - val_recall: 0.7784 - val_f1: 0.7682
Epoch 10/10134307/134307 [==============================] - 221s 2ms/step - loss: 0.4727 - precision: 0.7670 - recall: 0.7647 - f1: 0.7590 - val_loss: 0.4673 - val_precision: 0.7833 - val_recall: 0.7561 - val_f1: 0.7636
The highest F1 score of 76.80% on the validation set was achieved on the third training epoch. The performance of the trained model on the test data was F1=78.1%.
Table 1. Sentiment Analysis Quality on Test Data.
| Class label | Accuracy | Completeness | F1 | Number of objects |
|---|---|---|---|---|
| Negative | 0.78194 | 0.78243 | 0.78218 | 22457 |
| Positive | 0.78089 | 0.78040 | 0.78064 | 22313 |
| avg / total | 0.78142 | 0.78142 | 0.78142 | 44770 |
Results
As a baseline solution, I trained a naive Bayes classifier with a multinomial distribution model. The comparison of results is presented in Table 2.
Table 2. Sentiment Analysis Quality Comparison.
| Classifier | Precision | Recall | F1 |
|---|---|---|---|
| MNB | 0.78194 | 0.7564 | 0.7560 |
| CNN | 0.78142 | 0.78142 | 0.78142 |
Conclusions
As you can see, the classification quality of CNN exceeded that of MNB by several percentage points. Metric values can be further improved by optimizing hyperparameters and network architecture. For example, you can change the number of training epochs, test the effectiveness of using different word embeddings and their combinations, adjust the number and height of filters, implement more effective text preprocessing (typo correction, normalization, stemming), configure the number of hidden fully connected layers and neurons in them.
Further research is aimed at the following aspects:
- Improving algorithm accuracy: Enhancing the accuracy of sentiment analysis of text reviews using more advanced machine learning algorithms and improved text preprocessing methods.
- Multi-language analysis: Expanding analysis capabilities to multilingual data, including the development of models capable of working with different languages and dialects.
- Adapting known methods of building Moore automaton logic circuits to FPGA base.
- Adaptation to specific industries: Researching methods to adapt sentiment analysis algorithms to specific industries such as technical support, healthcare, or the hotel business.
- Multidimensional sentiment analysis: Developing methods that allow considering multiple aspects and sentiments in a single text, as reviews can be more complex and contain different aspects.
- Contextual analysis: Enhancing sentiment analysis with context in mind, including determining how changes in a product or service affect the sentiment of reviews.
- Emotion and mood analysis: Expanding review analysis to identify emotions and moods, which can provide additional insights into the customer experience.
- Automatic response to reviews: Developing systems capable of automatically responding to reviews, including generating personalized responses.
- Integration with intelligent assistants: Exploring the possibility of integrating sentiment analysis algorithms with intelligent assistants for automatic processing and analysis of customer comments.
- Combating fake reviews: Developing methods for detecting and filtering fake reviews that can distort analysis results.
- Comparative analysis of platforms and tools: Comparing different platforms and tools for sentiment analysis and selecting the most suitable ones for specific tasks and industries.
When writing this thesis, the master's work has not yet been completed. The final completion date is December 2011. The full text of the work and materials on the topic can be obtained from the author or his supervisor after the specified date.
List of Sources
- Cliche M. BB_twtr at SemEval-2017 Task 4: Twitter Sentiment Analysis with CNNs and LSTMs //Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017). - 2017. - Pp. 573-580.
- Zhang Y., Wallace B. A Sensitivity Analysis of (and Practitioners' Guide to) Convolutional Neural Networks for Sentence Classification //arXiv preprint arXiv:1510.03820. - 2015.
- Rosenthal S., Farra N., Nakov P. SemEval-2017 task 4: Sentiment Analysis in Twitter //Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017). - 2017. - pp. 502-518.
- Yu. V. Rubtsova. Building a corpus of texts for tuning the tone classifier // Software products and systems, 2015, ?1(109), - Pp.72-78.
- Mikolov T. et al. Distributed Representations of Words and Phrases and Their Compositionality //Advances in Neural Information Processing Systems. - 2013. - pp. 3111-3119.
- Sentiment Analysis: A Practitioner's Guide to NLP by Delip Rao and Brian McMahan - Ebook - URL: https://booksdrive.org/wp-content/uploads/2022/04/Natural-Language-Processing-with-PyTorch-by-Delip-Rao-pdf-free-download.pdf (accessed 23.10.2023). - Access mode: free
- Python Machine Learning by Sebastian Raschka - Ebook - URL: https://booksdrive.org/wp-content/uploads/2022/04/Python-Machine-Learning-pdf-free-download.pdf (accessed 23.10.2023). - Access mode: free
- Opinion Mining and Sentiment Analysis by Bo Pang and Lillian Lee - Ebook - URL: https://www.cse.iitb.ac.in/~pb/cs626-449-2009/prev-years-other-things-nlp/sentiment-analysis-opinion-mining-pang-lee-omsa-published. pdf (accessed 10/23/2023). - Access mode: free
- Sentiment Analysis and Opinion Mining by Bing Liu - Ebook - URL: https://www.cs.uic.edu /~liub/FBS/SentimentAnalysis-and-OpinionMining.pdf (accessed 23.10.2023). - Access mode: free
- Mining the Social Web: Analyzing Data from Facebook, Twitter, LinkedIn, and Other Social Media Sites by Matthew A. Russell - Ebook - URL: https://books.google.ru/books?id=SYM1lrQdrdsC&printsec=frontcover&hl=ru&source=gbs_ge_summary_r&cad=0#v=onepage&q&f =false (accessed 23.10.2023). - Access mode: free
- Sentiment Analysis: Mining Opinions, Sentiments, and Emotions by Bing Liu - Ebook - URL: https://aclanthology.org/J16-3008.pdf (accessed 23.10.2023). - Access mode: free